This article briefly introduces how to use Zipkin to perform service analysis on Spring Cloud applications. In practical application, Zipkin can be used in combination with stress testing tools to analyze the availability and performance of systems under high stress.

Imagine the following scenario: if your microservices grow gradually and the dependencies between services become increasingly complicated, how can you analyze the call relations and mutual influences between them?
An application comprised of microservices divides the problem domain through services and completes the operation through REST API to connect services. An entry service call may require the coordination of multiple background services. Any call timeout or error on the link may lead to the failure of the front-end requests. The call chain of the service will become longer and longer, and form a tree-shaped call chain.
Although it doesn't match the source, I think this should be 'service call'... a service call may require the coordination of multiple background services. 
With the increasing services, the analysis on the call chain will become more and more detail-oriented. Suppose you are in charge of the system below, and every small point in it is a microservice. The call relations between the microservices constitute the complicated network.

In view of the full-chain tracing issues for service-oriented applications, Google published the Dapper paper, introducing how they conducted service tracing analysis. The basic idea is to add an ID to the service calling requests and responses to indicate the relationships of upstream and downstream requests. With this information, the service calling chains and dependencies between services can be analyzed in a visualized way.
The open-source implementation corresponding to Dapper is Zipkin. It supports multiple languages including JavaScript, Python, Java, Scala, Ruby, C# and Go. Among them, Java supports different databases.
In this example, we prepare to develop two Spring Cloud-based applications and use Spring Cloud Sleuth to integrate with Zipkin. Spring Cloud Sleuth is a kind of encapsulation of Zipkin and automates span and trace information generation, access of HTTP requests and sending collection information to the Zipkin Server.
This is a concept map of Spring Cloud Sleuth.

There are two demo services in this example: tracedemo, acting as the frontend service to receive requests from users; and tracebackend, acting as the backend service. The tracedemo calls the backend service through the HTTP protocol.
@RequestMapping("/")
public String callHome(){
LOG.log(Level.INFO, "calling trace demo backend");
return restTemplate.getForObject("http://backend:8090", String.class);
}The tracedemo application calls the backend tracebackend service through RestTemplate. Attention: the tracedemo address is specified in the URL as backend.
@RequestMapping("/")
public String callHome(){
LOG.log(Level.INFO, "calling trace demo backend");
return restTemplate.getForObject("http://backend:8090", String.class);
}The backend service responds to the HTTP request, and the output log shows that it returns the classic “hello world”.
@RequestMapping("/")
public String home(){
LOG.log(Level.INFO, "trace demo backend is being called");
return "Hello World.";
}We can see that this is a typical access from two Spring applications through RestTemplate. So which one of them injects the tracing information in the HTTP request and sends the information to Zipkin Server? The answer lies in the JAR packages loaded by the two applications.
In this example, Gradle is used to build applications. JAR packages related to Sleuth and Zipkin are loaded in build.gradle:
dependencies {
compile('org.springframework.cloud:spring-cloud-starter-sleuth')
compile('org.springframework.cloud:spring-cloud-sleuth-zipkin')
testCompile('org.springframework.boot:spring-boot-starter-test')
}After the Spring application detects Sleuth and Zipkin in Java dependent packages, it will automatically inject tracing information to the HTTP request during RestTemplate calls, and send the information to the Zipkin Server.
So where can we specify the address of the Zipkin Server? The answer is: in application.properties:
spring.zipkin.base-url=http://zipkin-server:9411Note: The Zipkin Server address is: zipkin-server.
Create two identical Dockerfiles for these two services to generate the Docker image:
FROM java:8-jre-alpine
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/' /etc/apk/repositories
VOLUME /tmp
ADD build/libs/*.jar app.jar
RUN sh -c 'touch /app.jar'
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]The procedure for building a Docker image is as follows:
cd tracedemo
./gradlew build
docker build -t zipkin-demo-frontend .
cd ../tracebackend
./gradlew build
docker build -t zipkin-demo-backend .
After the image is ready, upload the image to your image repository with the `docker push` command.Create Zipkin using annotation declarations
Introduce Zipkin dependent package in build.gradle.
dependencies {
compile('org.springframework.boot:spring-boot-starter')
compile('io.zipkin.java:zipkin-server')
runtime('io.zipkin.java:zipkin-autoconfigure-ui')
testCompile('org.springframework.boot:spring-boot-starter-test')
}Add an annotation @EnableZipkinServer in the main program class
@SpringBootApplication
@EnableZipkinServer
public class ZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinApplication.class, args);
}
}Specify the port as 9411 in application.properties.
server.port=9411The Dockerfile here is the same as with the previous two services, so I won't repeat the procedure here.
Create the docker-compose.yml file with the following content:
version: "2"
services:
zipkin-server:
image: registry.cn-hangzhou.aliyuncs.com/jingshanlb/zipkin-demo-server
labels:
aliyun.routing.port_9411: http://zipkin
restart: always
frontend:
image: registry.cn-hangzhou.aliyuncs.com/jingshanlb/zipkin-demo-frontend
labels:
aliyun.routing.port_8080: http://frontend
links:
- zipkin-server
- backend
restart: always
backend:
image: registry.cn-hangzhou.aliyuncs.com/jingshanlb/zipkin-demo-backend
links:
- zipkin-server
restart: alwaysUsing the orchestration templateOn Alibaba Cloud Docker, and visit the Zipkin endpoint, then you will see the effect of service analysis.
Visit the front-end application three times, and the page displays three service calls.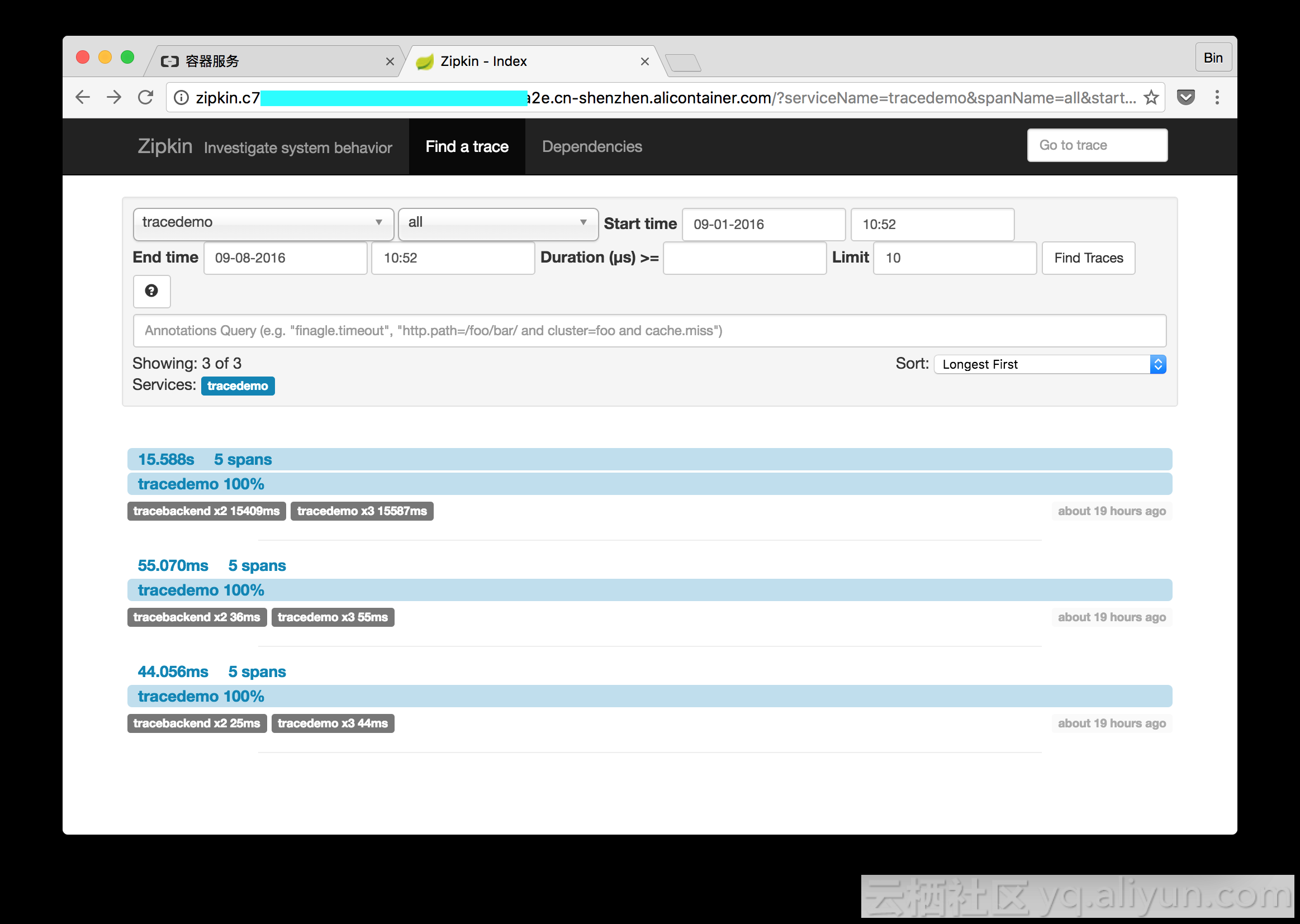
Click any trace, and you will see the duration of different spans on the request link.
Enter the Dependencies page, and you will see the dependency relationships between services.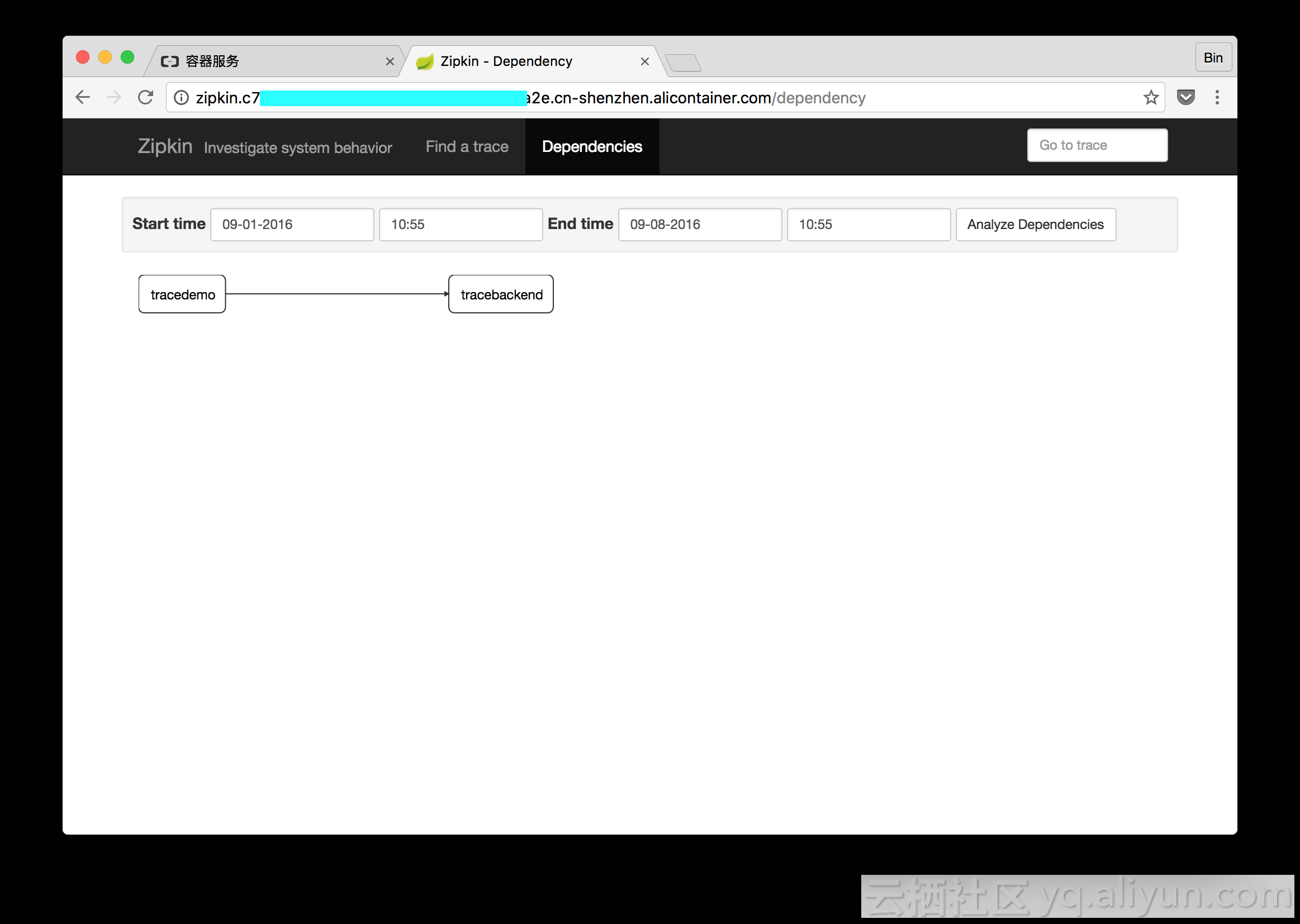
From this process, we can see that Zipkin and Spring Cloud integration is successful. The visualization of service tracing analysis is also intuitive.
It is worth noting that you also need to configure databases for Zipkin in a production environment. I will not go into the details here.
The demo code of this article can be found here: https://github.com/binblee/zipkin-demo.

2,593 posts | 793 followers
FollowAlibaba Clouder - November 7, 2019
Alibaba Cloud Native Community - September 12, 2023
Alibaba Cloud Native Community - December 19, 2023
Alibaba Cloud Native Community - January 26, 2024
Alibaba Cloud Community - May 6, 2024
Alibaba Clouder - January 28, 2019
2,593 posts | 793 followers
Follow Cloud-Native Applications Management Solution
Cloud-Native Applications Management Solution
Accelerate and secure the development, deployment, and management of containerized applications cost-effectively.
Learn More Global Application Acceleration Solution
Global Application Acceleration Solution
This solution helps you improve and secure network and application access performance.
Learn More ADAM(Advanced Database & Application Migration)
ADAM(Advanced Database & Application Migration)
An easy transformation for heterogeneous database.
Learn More Compute Nest
Compute Nest
Cloud Engine for Enterprise Applications
Learn MoreMore Posts by Alibaba Clouder

