Before Flink 1.20, if the JobMaster (JM) experienced a failure and was terminated, two situations would occur:
To address this issue, we introduced a progress recovery feature for batch jobs after JM failover in Flink 1.20. This feature aims to enable batch jobs to recover as much progress as possible after a JM failover, thus avoiding the need to re-run finished tasks.
To achive this goal, Flink needs to persist the state of the JM to external storage. This way, after a JM failover, Flink can use the persisted state to restore the job to its previous execution progress.
We introduced an event-based JM state recovery mechanism to Flink. In the period of job execution, JM's state change events are written to external persistent storage to ensure that job execution progress can still be retrieved after a JM failover. However, inconsistency may exist between the recorded progress and recoverable progress. For instance, if certain TaskManagers (TMs) are unexpectedly lost during execution, this may render intermediate data results inaccessible. Therefore, Flink also needs to obtain information about the intermediate result data from TMs and the Remote Shuffle Service (RSS) to recalibrate the job execution progress recovery results.
The overall process of this functionality consists of the following stages:
(1)During Job Execution
A JobEventStore will receive and write the JM's state change events to an external file system during job execution. The state change events that need to be recorded can be categorized as follows:
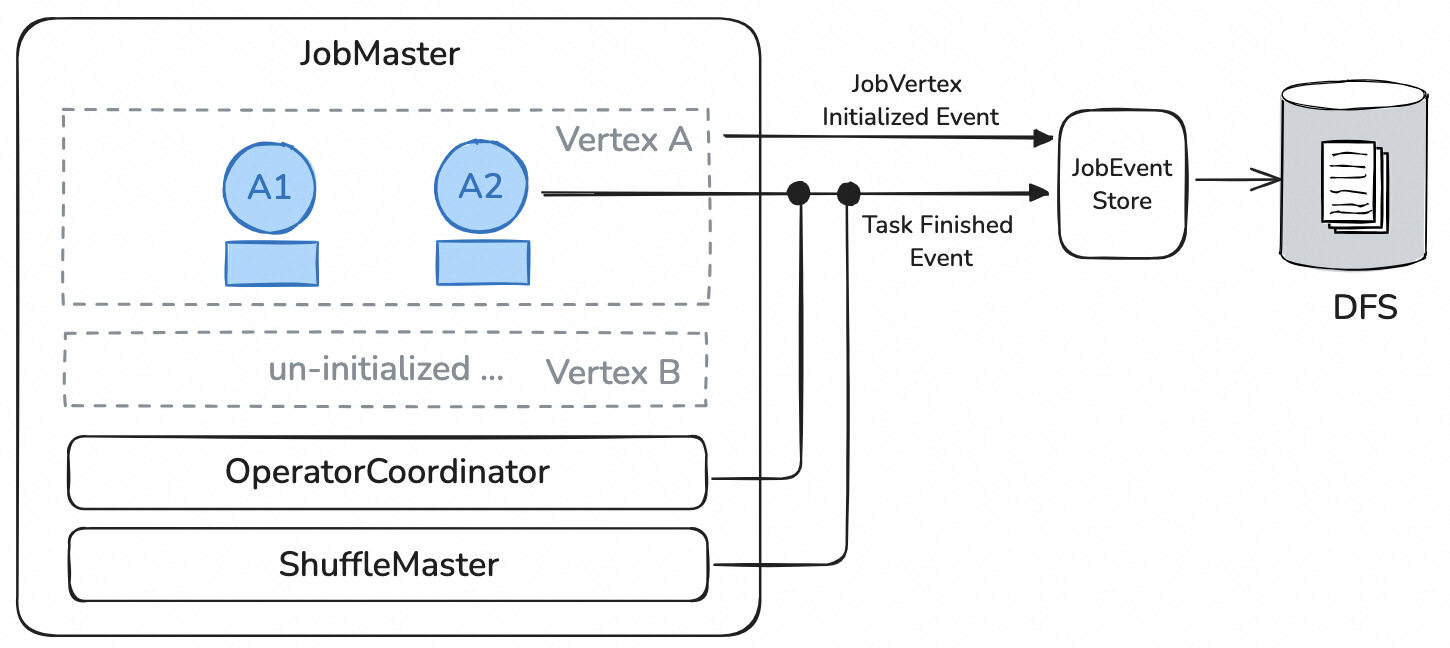
(2)During JM Failover
In Flink batch jobs, intermediate results are stored on TM and RSS during execution. When a JM failover occurs, both TM and RSS will retain the intermediate results associated with the job and continuously attempt to reconnect to the JM. Once a new JM is set up, TM and RSS will reestablish their connections with the JM, and then they will report the intermediate result data they hold.
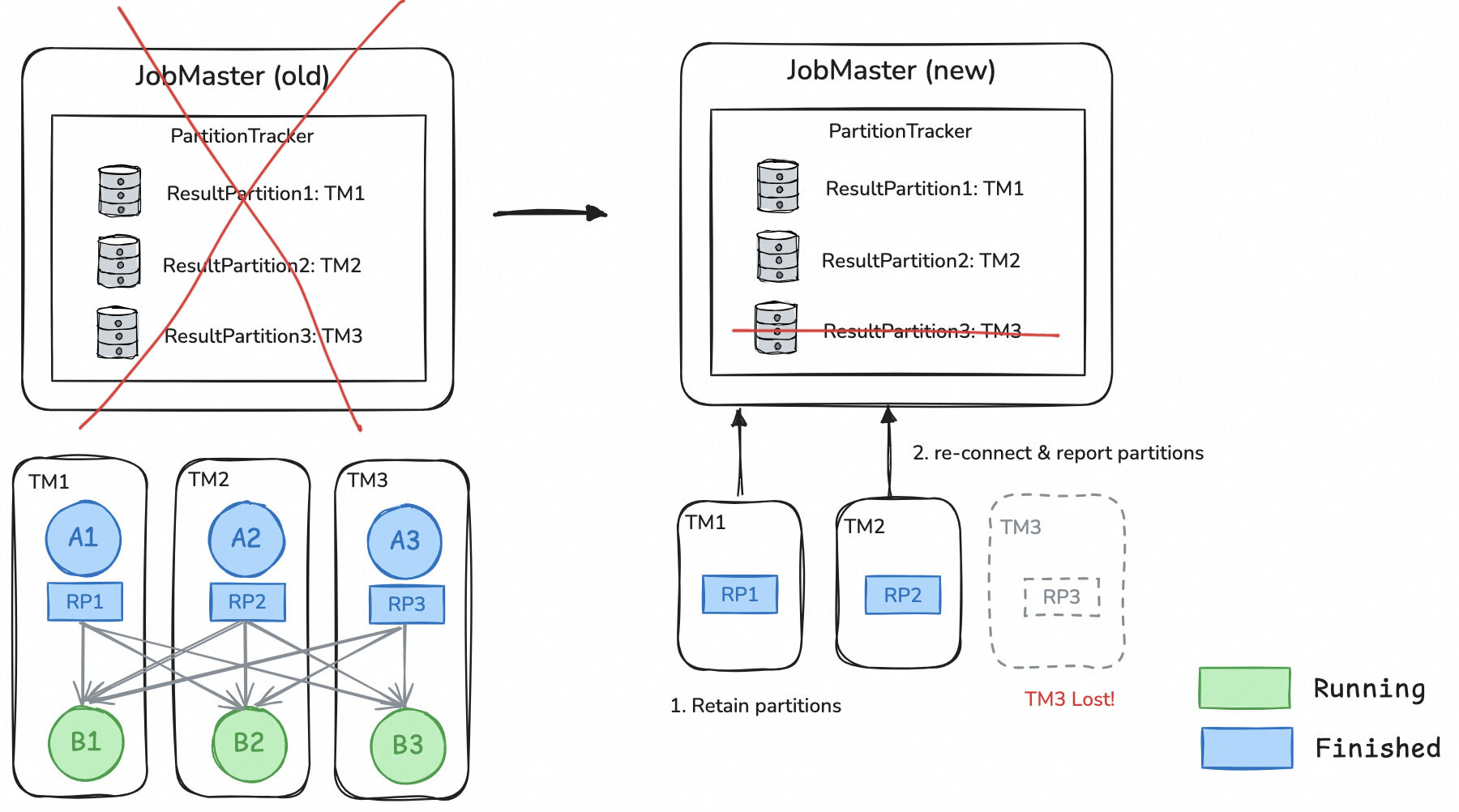
(3)Job Execution Progress Recovery After JM Failover
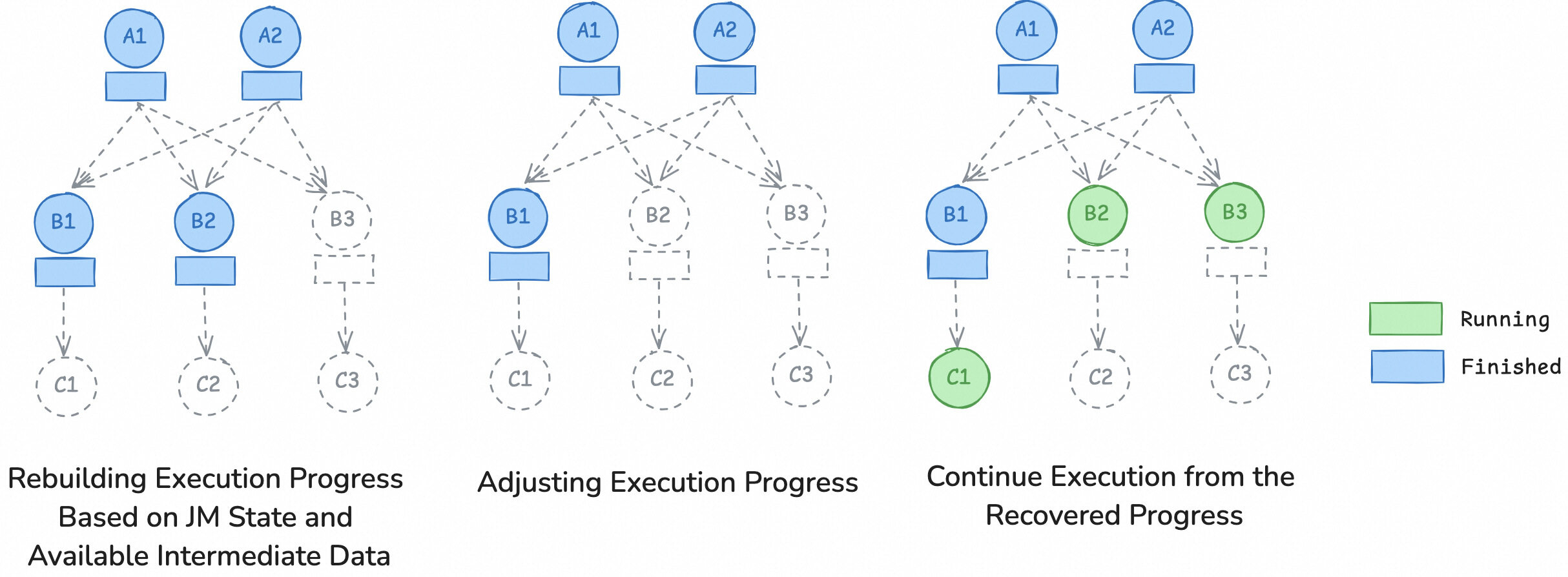
Once the JM restarts, it will reestablish connections with TM and RSS, using the events recorded in the JobEventStore and the intermediate results retained by TM and RSS to rebuild the execution progress of the job.
First, the JM will utilize the events stored in the JobEventStore to restore the execution states of each job vertex in the job. Then, based on the state of the OperatorCoordinator, the JobMaster will recover the unprocessed source data splits to avoid data loss or duplication.
Subsequently, the JM will further adjust the execution progress based on the available intermediate results reported by TM and RSS. If any intermediate result partition is lost but is still needed by downstream tasks, the producer task will be reset and re-executed.
Finally, the job will continue executing from the recovered progress.
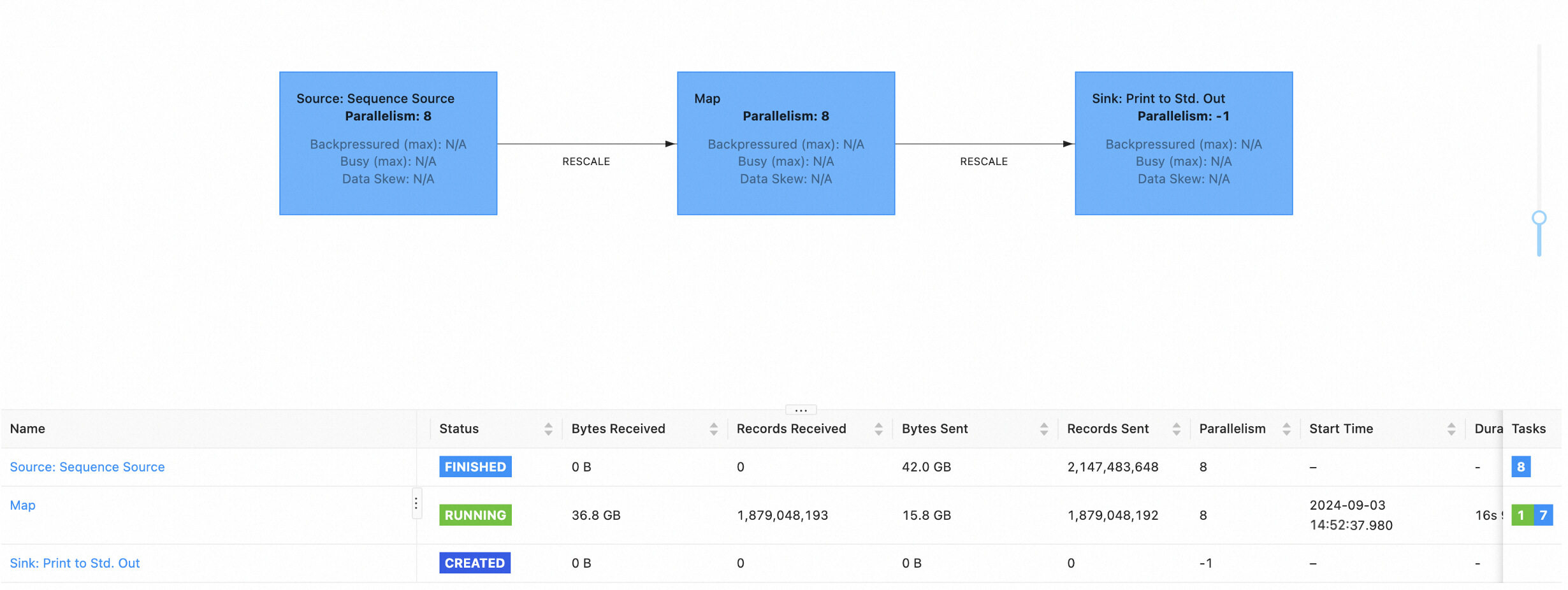
Here is an example of progress recovery after a JM failover.
The topology of this batch job is Source -> Map -> Sink. When the job progress reaches the Map vertex, the machine hosting the JM goes offline due to maintenance, resulting in a JM failover.
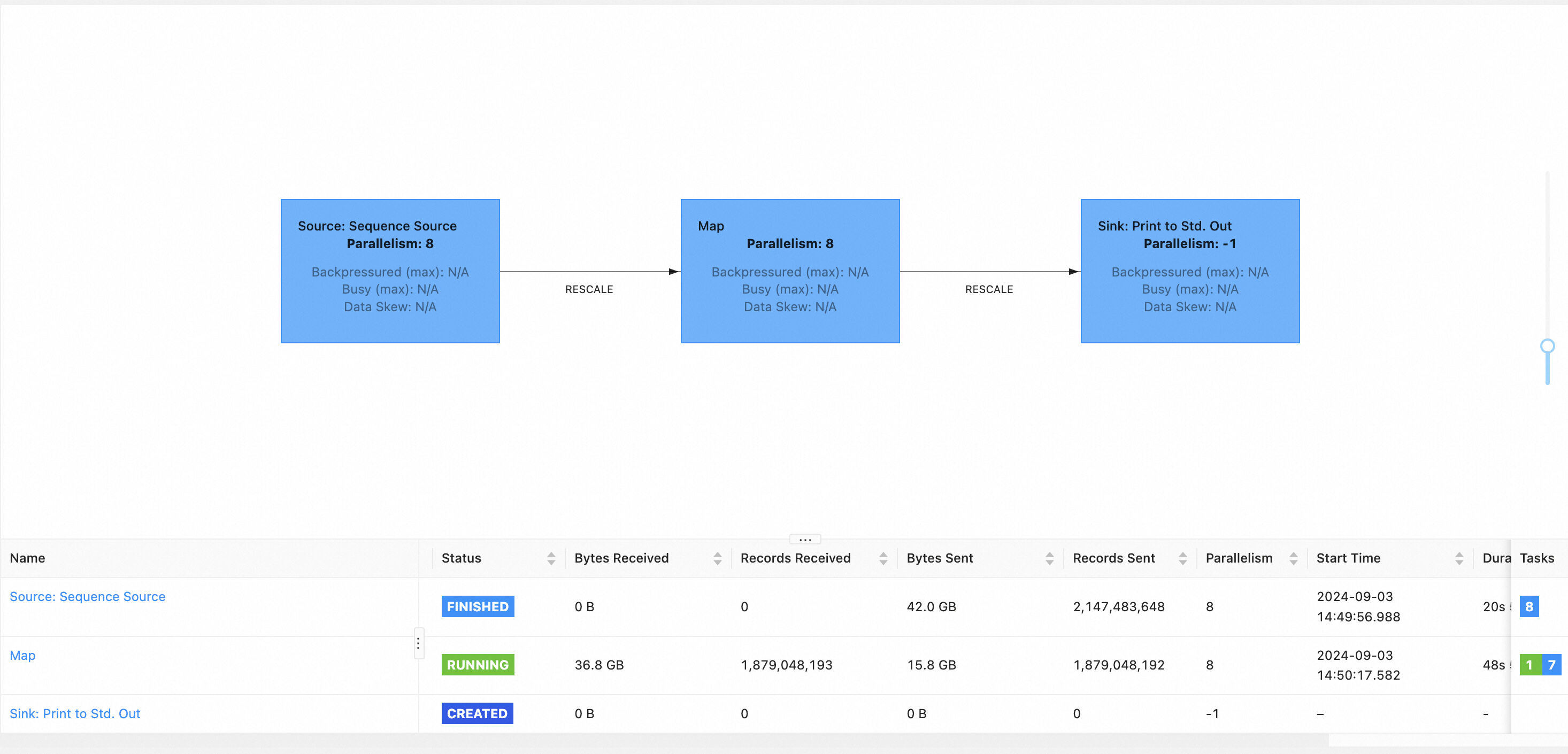
Subsequently, the HA service will automatically start a new JM process, and the job will enter the RECONCILING state, indicating that the job is in the process of recovering its execution progress.

Once the job recovery is complete, it will enter the RUNNING state.

After accessing the job details page, you can see that the job has recovered to the progress it was at before the JM failover.
To use the state recovery feature for Flink batch jobs, users need to:
Additionally, all new sources support progress recovery for batch jobs. To achieve the best recovery results, the Source SplitEnumerator needs to implement the SupportsBatchSnapshot interface. Otherwise, tasks of that source will have to restart after a JM failure unless the entire source stage have finished. Currently, FileSource and HiveSource have already implemented this interface. For more details, please refer to this documentation.
Considering the differences between various clusters and jobs, users can refer to this document to do advanced configuration tuning.
Introduction to Unified Batch and Stream Processing of Apache Flink

206 posts | 56 followers
FollowApache Flink Community China - April 23, 2020
Apache Flink Community - March 13, 2025
Apache Flink Community China - September 27, 2019
Apache Flink Community China - August 6, 2021
Apache Flink Community China - December 25, 2019
Apache Flink Community - October 12, 2024
206 posts | 56 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Message Queue for Apache Kafka
Message Queue for Apache Kafka
A fully-managed Apache Kafka service to help you quickly build data pipelines for your big data analytics.
Learn More ApsaraDB for SelectDB
ApsaraDB for SelectDB
A cloud-native real-time data warehouse based on Apache Doris, providing high-performance and easy-to-use data analysis services.
Learn More ApsaraMQ for RocketMQ
ApsaraMQ for RocketMQ
ApsaraMQ for RocketMQ is a distributed message queue service that supports reliable message-based asynchronous communication among microservices, distributed systems, and serverless applications.
Learn MoreMore Posts by Apache Flink Community

