多元索引基于倒排索引和列式存储,可以解决大数据的多维查询和统计分析难题。您可以按需为数据表创建一个或多元索引用于加速数据查询。创建多元索引时,您需要将要查询的字段添加到多元索引中,您还可以配置多元索引的路由键、数据生命周期和预排序的高级选项。
注意事项
推荐将所有需要查询的字段创建在一个多元索引中,不建议为每个字段单独创建多元索引。
创建多元索引后需等待几秒钟才能使用,期间不影响数据写入,只影响索引元信息的查询和索引查询。
多元索引的行数、总大小、字段数量等限制请参见多元索引使用限制。
操作步骤
进入索引管理页签。
登录表格存储控制台。
在页面上方,选择资源组和地域。
在概览页面,单击实例名称或在操作列单击实例管理。
在实例详情页签的数据表列表区域,单击数据表名称或在操作列单击索引管理。
在索引管理页签,单击创建多元索引。
在创建索引对话框,创建多元索引。
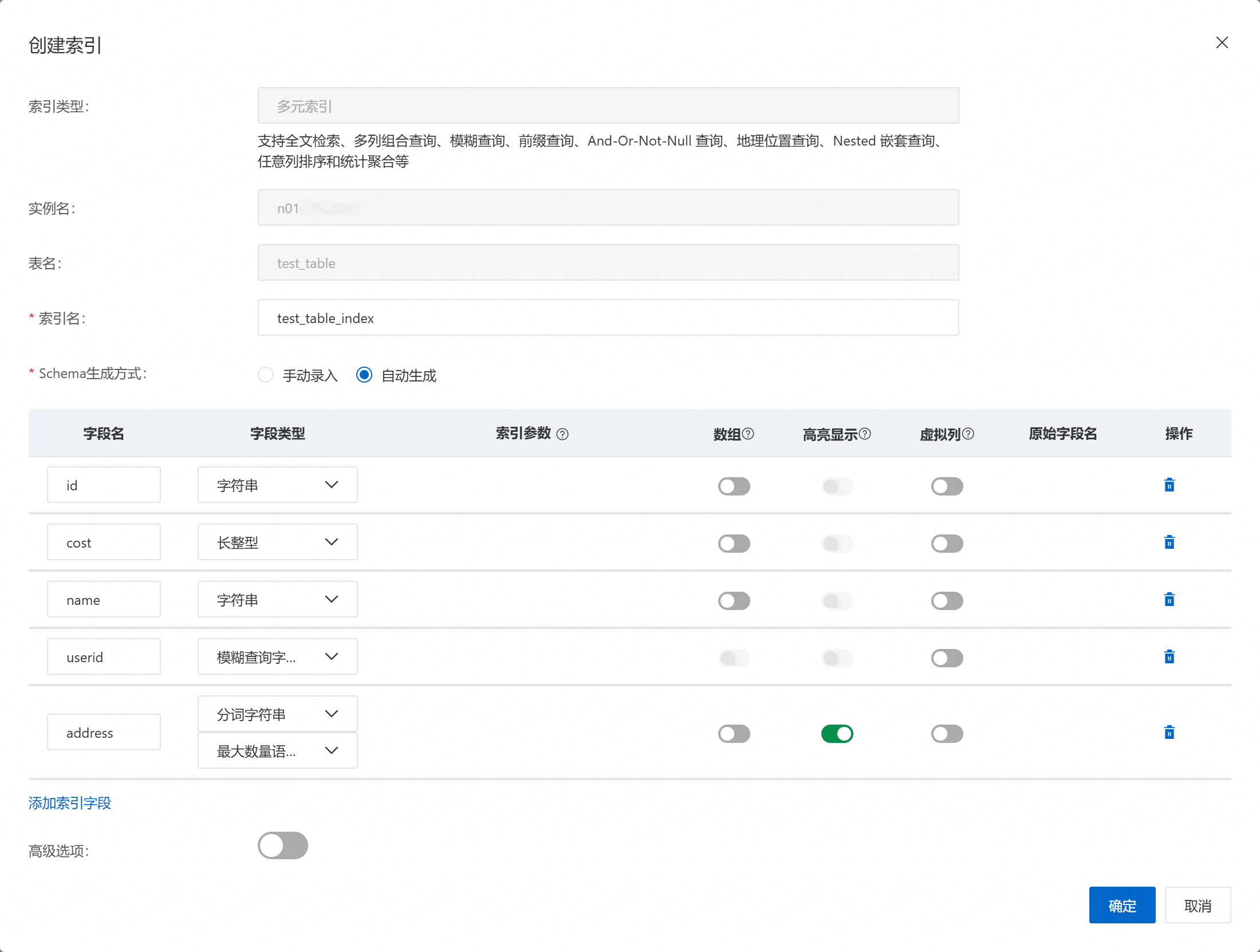
系统默认会自动生成索引名,可根据需要设置索引名。
选择Schema生成方式。
如果需要配置数据生命周期、路由键、索引预排序等选项,请打开高级选项开关,并根据下表说明配置参数。
参数
说明
路由键
自定义路由字段。可以选择部分主键列作为路由字段,一般情况下只需要设置一个。如果设置多个路由键,系统会将多个路由键的值拼接成一个值。
在进行索引数据写入时,系统会根据路由字段的值计算索引数据的分布位置,路由字段的值相同的记录会被索引到相同的数据分区中。
数据生命周期
多元索引中数据的保存时间,单位为秒。默认值为-1,表示数据永不过期。
数据生命周期的取值最低为86400秒(一天),也可设置为-1(永不过期)。同时多元索引的TTL值必须小于或等于数据表的TTL值。
如果需要系统自动清理多元索引中的历史数据,您可以配置数据生命周期为指定时间。当数据的保存时间超过设置的数据生命周期时,系统会自动清理超过数据生命周期的数据。
预排序
多元索引默认按照设置的索引预排序方式进行排序,用于确定数据的默认返回顺序。
索引预排序只支持按照主键排序和按照字段值排序两种方式。如果未自定义预排序,则默认为主键排序,您可以根据实际查询场景指定预排序方式。
重要含有Nested类型字段的多元索引不支持索引预排序。
单击确定。
多元索引创建完成后,在索引列表的操作列,单击索引详情,可查看索引表的索引基本信息、索引计量、路由键、索引字段和预排序等信息。
开发集成
您可以使用SDK或命令行工具创建多元索引。