添加Spark SQL数据源用于连通Spark SQL数据库与Quick BI,连接成功后,您可以在Quick BI上进行数据的分析与展示。Quick BI支持以公网或阿里云VPC的方式连接Spark SQL数据库(3.1.2版本),本文为您介绍如何添加Spark SQL自建数据源。
前提条件
确保您的网络已连通:
您通过公网连接Quick BI与Spark SQL数据库(3.1.2版本),请添加Quick BI的IP地址至数据库白名单,请参见添加安全组规则。
您通过内网连接Quick BI与Spark SQL数据库(3.1.2版本),请通过以下任意一种方式,实现数据源与Quick BI网络连通:
当Spark SQL数据库搭建在阿里云的ECS上,您可以通过阿里云VPC连接。
您也可以搭建跳板机,并通过SSH隧道访问登录并访问数据库。
已获取自建Spark SQL数据库(3.1.2版本)的用户名和密码。
使用限制
Spark SQL数据库支持3.1.2版本,且底层存储Hive MetaStore为Hive 2.0及以上版本。
操作步骤
登录Quick BI控制台。
请按照下述步骤添加数据源。
从创建数据源入口进入创建数据源界面。
在自建数据源页签下,选择Spark SQL数据源。

在配置连接对话框,您可以根据业务场景,完成以下配置。

名称
描述
显示名称
数据源配置列表的显示名称。
请输入规范的名称,不要使用特殊字符,前后不能包含空格。
数据库地址
部署Spark SQL数据库的地址,包括IP或域名。
端口
数据库的对应的端口号。
数据库
部署Spark SQL数据库时自定义的数据库名称。
用户名和密码
登录Spark SQL数据库的用户名和密码。 请确保该用户名具备数据库中表的create、insert、update和delete权限。
VPC数据源
若数据库使用的是阿里云VPC网络,请开启VPC数据源。
当数据库部署在阿里云ECS上,请选择“实例”;当通过传统型负载均衡CLB接入时,请选择“CLB”。
实例
购买者AccessId:购买此实例的AccessKey ID。
请参见获取AccessKey。
说明请确保该AccessKey ID具备目标实例的Read权限。此外,若具有对应安全组的Write权限,系统将自动添加白名单,否则需要您手动添加。相关操作说明请参见创建自定义权限策略。
购买者AccessKey:购买此实例的AccessKey Secret。
请参见获取AccessKey。
实例ID:ECS实例ID。请登录ECS管理控制台,在实例页签下获取实例ID。
请参见查看实例信息。
区域:ECS实例所在区域。请登录ECS管理控制台,在左上角获取实例所在的区域。
请参见查看实例信息。
CLB
购买者AccessId:CLB购买者的AccessKey ID。请确保该账号拥有CLB的Read权限。请登录RAM访问控制台,获取AccessKey ID。
购买者AccessKey:AccessKey ID对应的AccessKey Secret。请登录RAM访问控制台,获取AccessKey Secret。
实例ID:CLB的实例ID,请登录负载均衡管理控制台,并在实例管理列表中获取实例ID。
区域:实例所在区域,请登录负载均衡管理控制台,在实例管理页左上角获取区域。
SSH
如果您选中SSH,则需要配置如下参数:
您可以搭建跳板机,并通过SSH隧道访问登录并访问数据库。跳板机的信息请找运维或系统管理员获取。
SSH Host:输入跳板机IP地址。
SSH 用户名:登录跳板机的用户名。
SSH 密码:登录跳板机的用户名对应密码。
SSH 端口:跳板机的端口。默认为22。
请参见通过密码认证登录Linux实例。
初始化SQL
开启后,可配置数据源连接后初始化执行的SQL语句。
每次数据源连接后初始化执行的SQL语句,只允许SET语句,语句之间以分号分割。
单击连接测试,进行数据源连通性测试。
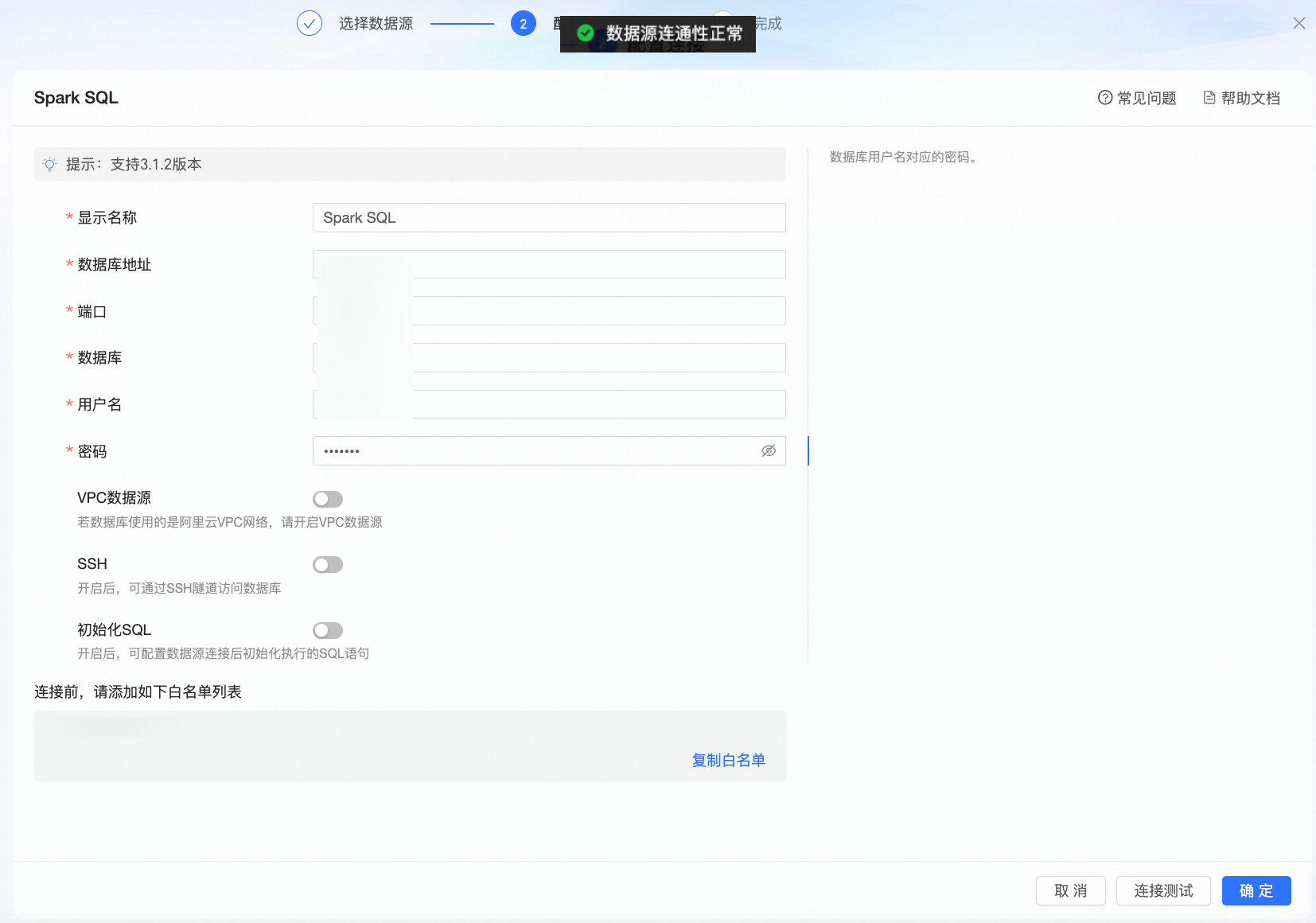
测试成功后单击确定,完成数据源添加。
此时您可以在数据列表中,看到您创建的数据源。
后续步骤
创建数据源后,您还可以创建数据集并分析数据。