如果您想通过可视化的界面,更直观地查看和分析模型训练过程及结果,可以在训练代码中使用Tensorboard存储训练过程中的日志,然后使用分布式训练(DLC)的Tensorboard功能进行可视化的查看。本文为您介绍如何创建和管理Tensorboard实例。
前提条件
DLC任务必须配置数据集才可以使用Tensorboard查看分析报告。您可以在DLC任务列表页单击任务名称,进入概览页面查看任务是否配置了数据集。
在训练代码中使用Tensorboard存储了Summary日志。您可以参考下文案例中的示例代码,存储Summary日志文件。
使用Tensorboard的DLC任务案例
本文提供如下DLC任务案例,数据集和Tensorboard具体配置如下:
配置OSS类型数据集:
OSS地址:
oss://w*********.oss-cn-hangzhou-internal.aliyuncs.com/dlc_dataset_1/挂载地址:
/mnt/data/
通过Tensorboard的SummaryWriter设置Summary日志文件存储地址:
SummaryWriter('/mnt/data/output/runs/mnist_experiment')。完整训练代码示例如下:
创建Tensorboard实例
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入任务。
在目标任务操作列下,单击Tensorboard,在弹出的Tensorboard面板中,单击新建Tensorboard。
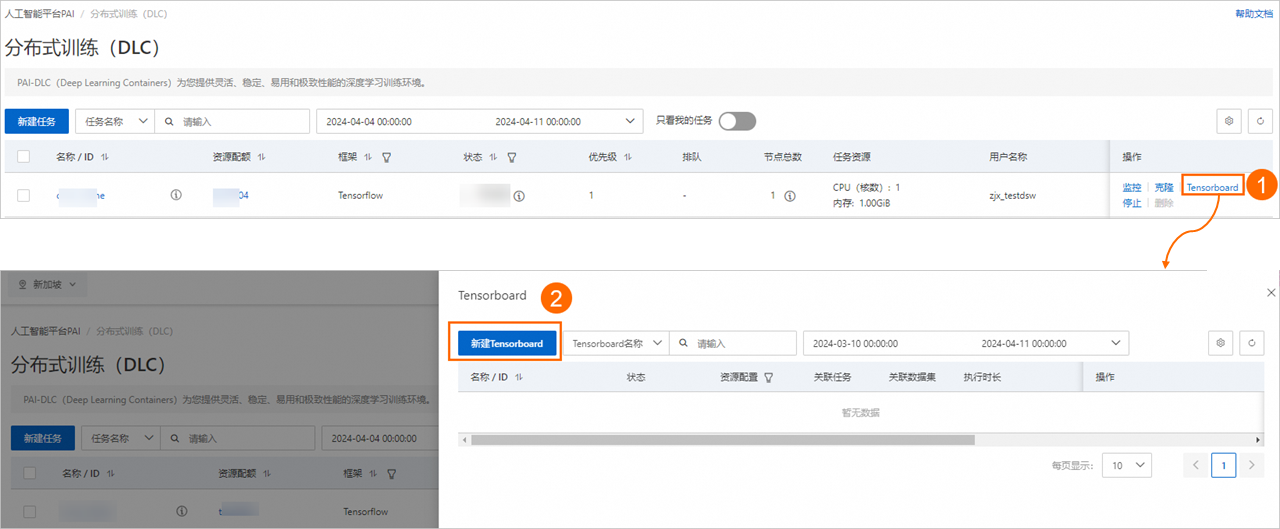
在新建Tensorboard页面中,配置以下参数,然后单击确定。
基本信息
参数
描述
名称
自定义Tensorboard实例名称。
数据集配置
配置类型:支持的类型包括:按数据集 (推荐)、按对象存储(OSS)、按任务。
Summary目录:即训练代码中您指定的Tensorboard Summary日志文件存储位置,您可以查找代码中的SummaryWriter获取Summary的完整路径。
上文任务案例的三种填写示例如下:
按数据集:选择任务配置的数据集,Summary目录只需填写日志文件在数据集中的相对路径

按对象存储(OSS):填写相应OSS路径,Summary目录只需填写日志文件在OSS中的相对路径

按任务:选择目标DLC任务,Summary目录需填写日志文件在容器中的完整路径

资源配置
支持配置以下几种资源类型:
资源类型
描述
免费资源
系统为您提供一定额度的免费资源,每个实例支持使用的资源上限为2vCPU,4 GiB内存。当免费额度不能满足您的需求时,您可以关闭运行中的其他免费实例,释放额度,以继续创建新的Tensorboard实例。
灵骏智算
通用计算
专有网络配置
当使用公共资源创建Tensorboard实例时,支持配置该参数。
不配置专有网络,将使用公网连接。由于公网连接的带宽有限,在Tensorboard实例启动过程或查看报告时,可能会出现卡顿或无法正常进行的情况。
配置专有网络,以确保充足的网络带宽和更稳定的性能。
选择当前地域可用的专有网络,并选择对应的交换机与安全组。配置完成后,Tensorboard实例运行的集群将能够直接访问此专有网络内的服务,并使用此处选择的安全组进行安全访问限制。
重要如果Tensorboard实例使用了需要配置专有网络的数据集(例如CPFS类型的数据集,或挂载点在专有网络内的NAS类型数据集等),则必须设置专有网络。
前往Tensorboard页面查看分析报告。
在工作空间页面的左侧导航栏选择。
切换到Tensorboard页签,当目标Tensorboard实例的状态为运行中时,单击操作列下的查看Tensorboard。页面自动跳转到TensorBoard页面。
管理Tensorboard实例
您可以按照以下操作步骤,对已创建的Tensorboard实例进行管理操作。
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入任务。
在Tensorboard页签,管理Tensorboard实例。

启动Tensorboard实例
单击启动,可启动已停止的Tensorboard实例。
查看Tensorboard实例详情
单击目标实例名称,查看基本信息和配置信息。
查看关联任务
在关联任务列下,将鼠标悬浮在图标
 上,查看已关联的DLC任务ID,并支持单击跳转到相关任务详情页面。
上,查看已关联的DLC任务ID,并支持单击跳转到相关任务详情页面。查看关联数据集
在关联数据集列下,将鼠标悬浮在图标
上,查看已关联的数据集ID,并支持单击跳转到相关数据集详情页面。查看执行时长
在执行时长列下,查看目标实例的运行时长。停止实例后,该时间将重置。
停止Tensorboard实例:
单击目标实例操作列下的停止,直接停止实例。
单击目标实例操作列下的自动停止设置,设置自动停止时间。
相关文档
您也可以在页面,为分布式训练(DLC)任务创建Tensorboard实例。具体操作,请参见创建及管理Tensorboard实例。