本文介绍MaxCompute查询加速MCQA(MaxCompute Query Acceleration)功能的系统架构、关键特性和应用场景。
MaxCompute计划于北京时间2025年11月24日(星期一)、北京时间2025年11月27日(星期四)分别在中国站和国际站上线查询加速MaxQA(MaxCompute Query Accelerator 2.0),届时该文档查询加速MCQA功能将不再对新客户开放。
功能介绍
MaxCompute MCQA功能提供如下能力。
支持中、小数据量查询作业的加速优化,将执行时间为分钟级的查询作业缩减至秒级,同时完全兼容原MaxCompute的查询功能。
支持主流BI工具,开展即席查询(Ad Hoc)或商业智能(BI)分析。
支持使用独立的资源池,不占用离线计算资源,可以自动识别查询作业,缓解排队压力,优化使用体验。
支持将MCQA(MaxCompute Query Acceleration)查询作业的运行结果写入临时缓存中。当用户后续执行相同的查询作业时,MaxCompute会优先返回缓存中的结果,加快执行速度。
查询流程
下图展示MaxCompute的查询处理架构,所有查询在接入后会被智能路由到不同的计算路径:查询加速(MCQA)、普通SQL执行或多引擎计算。

上图中MCQA(MaxCompute Query Acceleration)将查询作业的运行结果写入临时缓存中。当后续执行相同的查询作业时,MaxCompute会优先返回缓存中的结果,加快执行速度。对缓存机制的详细介绍请参考缓存机制。
应用场景
场景 | 说明 | 场景特点 |
即席查询(Ad Hoc) | 可以通过MCQA优化中小规模数据集(百GB规模内)的查询性能,直接对MaxCompute表开展低时延的查询操作,以便快速完成数据开发及数据分析。 |
|
商业智能(BI) | 利用MaxCompute搭建企业级数据仓库时,ETL会将数据加工处理为面向业务可消费的聚合数据。借助MCQA的低延时、弹性并发、数据缓存等特性,结合MaxCompute表分区、分桶等优化设计,可以低成本满足多并发、快速响应的报告生成、统计分析及固定报表分析需求。 |
|
海量数据明细查询分析 | MCQA可以自动识别查询作业特征,既能快速响应,处理小规模作业,同时还可以自动匹配大规模作业资源需求,满足分析人员分析不同规模和复杂度的查询作业的需求。 |
|
适用范围
版本要求:
MaxCompute客户端(odpscmd)要求v0.40.8及以上版本。
ODPS-JDBC要求v3.3.0及以上版本。
ODPS-SDK要求v0.40.8-public及以上版本。
仅支持数据查询(SELECT开头)语句。如果提交了MCQA不支持的语句,MaxCompute客户端、JDBC和SDK可通过配置回退到普通离线模式执行,其他工具暂不支持回退到普通离线模式执行。查询作业回退为普通SQL作业后,按原SQL作业计费模式计费。
数据行数限制:默认最大查询100W行数据,可通过在SQL语句中增加Limit关键字突破此限制。
功能使用限制:
限制项
说明
功能
支持标准版、按量计费的MaxCompute服务。
支持包年包月计费模式。
不支持开发者版的MaxCompute服务,需要升级为标准版。
查询
单次执行的作业支持并发的Worker数上限为2000个。
通过客户端提交的MCQA作业默认30s超时,通过DataWorks临时查询提交的MCQA作业默认20s超时,超时后MCQA作业将默认回退为普通查询作业。
仅存储格式为ALIORC的表的数据才可能被缓存至内存中加速。
查询并发
包年包月模式。
免费版(未划分MCQA交互式资源组)。
每天每个项目并发限制5个,每天每个项目最多运行500个作业,超过部分默认设置自动回退为普通作业,如果设置了不回退,系统会报如下错误:
ODPS-1800001: Session exception - Failed to submit sub-query in session because:Prepaid project run outoffree query quota.MCQA交互式资源组。
每个项目的MCQA作业最大并发数为120,超过后提交作业会回退到普通作业模式运行。
配置交互式资源类型的配额组,用以MCQA作业的预留CU最小配额需和预留CU最大配额值需一致,否则不生效。
交互式资源类型需要满足以下要求,否则不能提交。
预留CU量[minCU]=预留CU量[maxCU]。预留CU量需大于等于
50CU。
配置了交互式资源配额组后,所有Project仅支持可识别为加速的作业提交到交互式资源配额组,且查询加速功能不再享有免费体验。
交互式资源类型的配额组不支持作为Project的默认Quota使用,使用查询加速功能时交互式配额组无需绑定Project即对所有Project生效。
按量付费模式。
单个MaxCompute项目的MCQA作业最大并发数为120,超过部分会回退到普通作业模式运行。
缓存机制
对于每个MCQA查询作业,MaxCompute都会在内部创建临时数据集来缓存查询结果,临时数据集的缓存大小限制为10 GB。
临时数据集的所有者即当前运行查询作业生成缓存结果的用户;
该临时数据集对用户不可见,不支持查看临时数据集内容;
MaxCompute会自动为运行查询作业的用户授予对临时数据集的访问权限。
如果希望从缓存的查询结果中检索数据,执行的查询作业以及查询的上下文配置必须与原始查询作业完全相同。当运行重复的查询作业时,MaxCompute会重复使用缓存结果。
缓存计费规则
缓存的查询结果不会产生任何存储及计算费用,可以有效降低资源使用费用。
删除缓存结果
出现如下情况时,MaxCompute会删除缓存结果:
MaxCompute项目的资源使用率较高时,MaxCompute会提前删除缓存结果。
缓存结果所引用的表或视图变更后,缓存结果立即失效,MaxCompute会删除失效的缓存结果,此时再次执行相同的查询作业,不会检索到缓存数据。
缓存结果已过期。
缓存验证
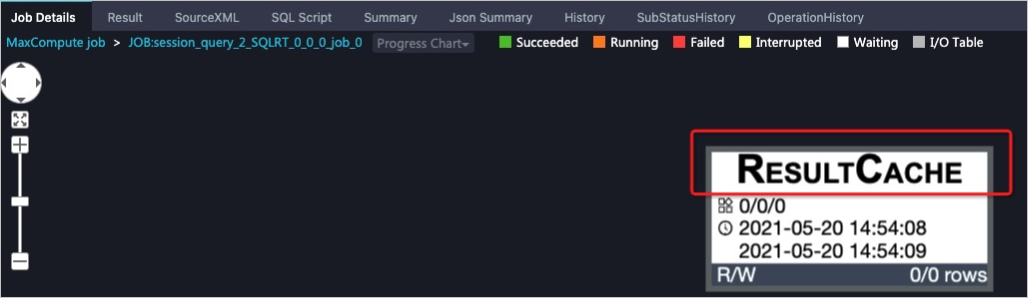
使用Logview 2.0可以获取查询作业的Logview信息。如下图所示,在Job Details页签,可以看到查询作业运行结果已写入缓存中:
包年包月规格开通MCQA
操作步骤
使用查询加速功能加速包年包月MaxCompute实例的项目步骤如下。
包年包月MCQA Quota决定了查询时的扫描并发度,进而影响扫描目标表的数据量,大概比例是1 CU可以扫描0.6 GB数据。例如购买50 CU的MCQA Quota,正常同时扫描数据量在30 GB左右,目前MCQA最大扫描数量可以支持扫描300 GB。
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择 。
在Quota管理页面,单击目标Quota对应操作列的Quota配置。
Quota基础配置
在Quota配置页面,选择基础配置页签,单击编辑基础配置。
单击新增二级Quota或为现有的二级Quota配置基础参数。
Quota名称自定义输入,类型选择交互式。详细参数参考配置Quota。
Quota伸缩配置
在Quota配置页面,选择伸缩配置页签。
在伸缩配置页签,单击新增配置方案或单击已有的配置方案对应的操作列的编辑,更新配置方案。
在新增配置方案或编辑配置方案对话框的MCQA资源组上配置预留CU量[minCU,maxCU]。
最小CU数(minCU)需要等于最大CU数(maxCU)。
最小CU数要大于等于
50CU。如果不需要交互式资源,设置为0。交互式类型的Quota不支持弹性预留CU。
单击确定,完成Quota配置录入。
在伸缩配置页签,单击目标配置方案对应的操作列的立即生效,可使该配置方案立即生效。也可在分时管理配置时使用已有方案。
配置时间计划。
配置时间计划设置每日不同时间点启用不同的Quota计划,以此实现对Quota配置的分时逻辑。
调度策略
交互式配额组不支持显式指定,由服务端根据规则自动进行调度,具体调度策略取决于租户下的交互式配额组数量:
只有一个交互式配额组,则租户下的所有查询加速作业都会调度到这个配额组上。
如果租户开通了多个交互式配额组,自动路由规则根据用户配置进行选择,详情请参见Quota规则。
回退策略
如果因使用限制发生查询加速作业回退为普通查询作业,包年包月规格下专用于跑MCQA的配额回退为当前Project绑定的配额资源(Quota)。
可通过SDK(版本高于0.40.7)指定回退作业的执行配额资源(Quota)。
SQLExecutorBuilder builder = SQLExecutorBuilder.builder(); builder.quotaName("<OfflineQuotaName>");通过JDBC连接串参数
fallbackQuota=XXX指定回退作业的执行配额资源(Quota)。不允许指定回退作业运行配额为交互式配额组,否则会报错。
MCQA渠道接入说明
MCQA功能支持的接入方式如下:
方式一:基于MaxCompute客户端启用MCQA功能
下载最新版MaxCompute客户端(odpscmd)。
安装并配置客户端,详情请参见安装并配置MaxCompute客户端。
修改客户端安装目录conf下的配置文件odps_config.ini,在配置文件增加如下命令:
enable_interactive_mode=true -- 打开MCQA interactive_auto_rerun=true -- 代表MCQA失败后自动回退到普通作业执行运行客户端安装目录bin下的MaxCompute客户端(Linux系统下运行./bin/odpscmd,Windows下运行./bin/odpscmd.bat)。出现如下信息,表示运行成功。
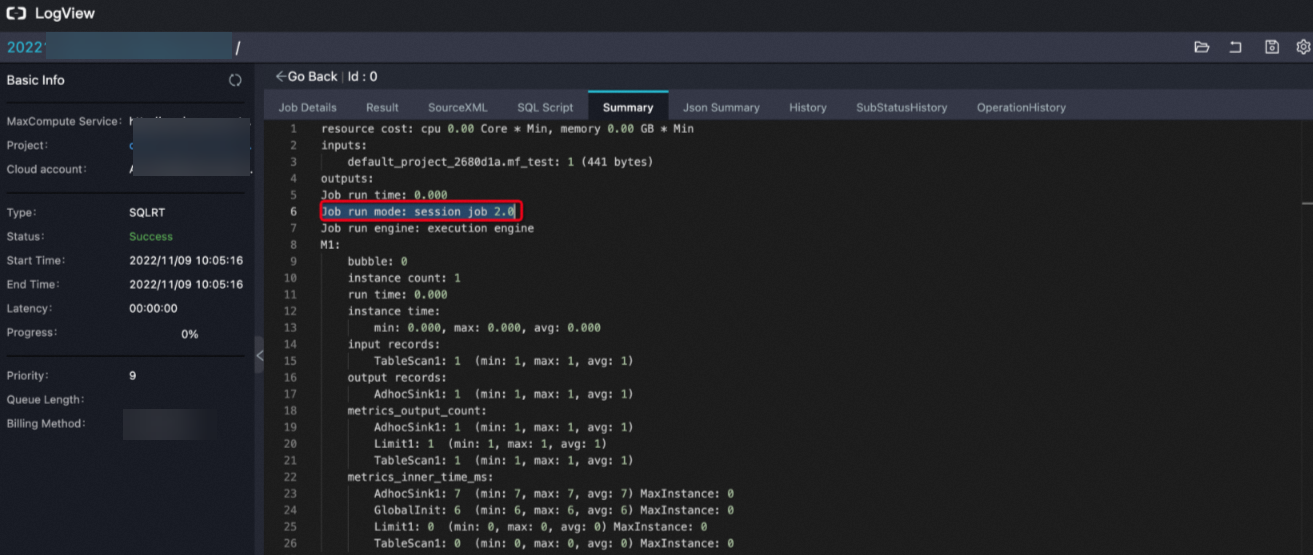
执行查询作业后,客户端界面返回结果中的Logview如果包含如下信息表明MCQA功能已开启。
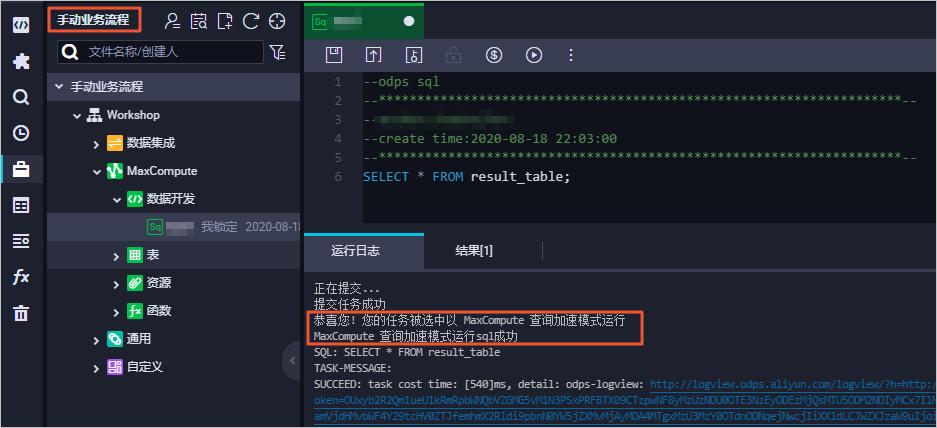
方式二:基于DataWorks临时查询或数据开发启用MCQA功能
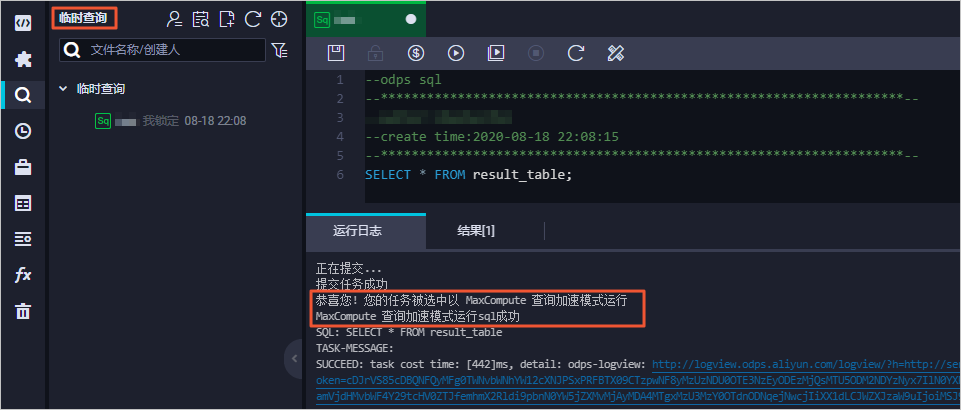
DataWorks的临时查询及手动业务流程模块默认开启MCQA功能,无需手动开启。
方式三:基于JDBC启用MCQA功能
使用JDBC连接MaxCompute,可以通过执行如下操作开启MCQA功能。使用JDBC连接MaxCompute的操作详情请参见JDBC使用说明。
通过Maven方式配置Pom依赖。
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-jdbc</artifactId> <version>3.3.0</version> <classifier>jar-with-dependencies</classifier> </dependency>基于源代码创建Java程序,适配实际信息,详情请参见MaxCompute JDBC,示例如下。
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户 // 此处以把AccessKey 和 AccessKeySecret 保存在环境变量为例说明。您也可以根据业务需要,保存到配置文件里 // 强烈建议不要把 AccessKey 和 AccessKeySecret 保存到代码里,会存在密钥泄漏风险 private static String accessId = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"); private static String accessKey = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"); //your_project_name为需要使用MCQA功能的项目名称。 String conn = "jdbc:odps:http://service.<regionid>.maxcompute.aliyun.com/api?project=<YOUR_PROJECT_NAME>"&accessId&accessKey&charset=UTF-8&interactiveMode=true&alwaysFallback=false&autoSelectLimit=1000000000"; Statement stmt = conn.createStatement(); Connection conn = DriverManager.getConnection(conn, accessId, accessKey); Statement stmt = conn.createStatement(); String tableName = "testOdpsDriverTable"; stmt.execute("DROP TABLE IF EXISTS " + tableName); stmt.execute("CREATE TABLE " + tableName + " (key int, value string)");可以选择在连接串中配置如下参数,完善处理逻辑。
参数
说明
enableOdpsLogger
用于打印日志。未配置SLF4J时,建议您配置此参数为True。
fallbackForUnknownError
默认值为False,设置为True时,表示发生未知错误时回退到离线模式。
fallbackForResourceNotEnough
默认值为False,设置为True时,表示发生资源不足问题时回退到离线模式。
fallbackForUpgrading
默认值为False,设置为True时,表示升级期间回退到离线模式。
fallbackForRunningTimeout
默认值为False,设置为True时,表示执行超时时回退到离线模式。
fallbackForUnsupportedFeature
默认值为False,设置为True时,表示遇到MCQA不支持的场景时回退到离线模式。
alwaysFallback
默认值为False,设置为True时,表示在以上几种场景下全部回退到离线模式,仅在JDBC 3.2.3及以上版本支持。
使用示例
示例1:Tableau上使用MCQA:
服务器增加
interactiveMode=true属性,用于开启MCQA功能。建议您同步增加enableOdpsLogger=true属性,用于打印日志。配置操作详情请参见配置JDBC使用Tableau。完整的服务器配置示例如下。
http://service.cn-beijing.maxcompute.aliyun.com/api? project=****_beijing&interactiveMode=true&enableOdpsLogger=true&autoSelectLimit=1000000000"如果只对项目空间中的部分表进行Tableau操作,您可以在服务器参数中增加
table_list=table_name1, table_name2属性选择需要的表,表之间用半角逗号(,)分隔。如果表过多,会导致Tableau打开缓慢,强烈建议使用此方式只载入需要的表。示例如下,对于有大量分区的表不建议把所有分区的数据都设置成数据源,可以筛选需要的分区或通过自定义SQL获取需要的数据。http://service.cn-beijing.maxcompute.aliyun.com/api?project=****_beijing &interactiveMode=true&alwaysFallback=true&enableOdpsLogger=true&autoSelectLimit=1000000000" &table_list=orders,customers示例2:SQLWorkBench使用MCQA。
完成JDBC驱动配置后,在Profile配置界面修改已填写的JDBC URL,支持SQLWorkbench使用MCQA功能。Profile配置操作详情请参见配置JDBC使用SQL Workbench/J。
需要配置的URL格式如下所示:
jdbc:odps:<MaxCompute_endpoint>? project=<MaxCompute_project_name>&accessId=<AccessKey ID>&accessKey=<AccessKey Secret> &charset=UTF-8&interactiveMode=true&autoSelectLimit=1000000000"参数说明如下。
参数
说明
MaxCompute_endpoint
MaxCompute服务所在区域的Endpoint,详情请参见Endpoint。
MaxCompute_project_name
MaxCompute项目空间名称。
AccessKey ID
有访问指定项目空间权限的AccessKey ID。
您可以进入AccessKey管理页面获取AccessKey ID。
AccessKey Secret
AccessKey ID对应的AccessKey Secret。
您可以进入AccessKey管理页面获取AccessKey Secret。
charset=UTF-8
字符集编码格式。
interactiveMode
MCQA功能开关,
true表示开启MCQA功能。autoSelectLimit
数据量超过100万限制时,需要配置此参数。
方式四:基于Java SDK启用MCQA功能
Java SDK详情请参见Java SDK介绍。需要通过Maven配置Pom依赖,配置示例如下。
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-core</artifactId>
<version>3.3.0</version>
</dependency>创建Java程序,命令示例如下。
import com.aliyun.odps.Odps;
import com.aliyun.odps.OdpsException;
import com.aliyun.odps.OdpsType;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.data.ResultSet;
import com.aliyun.odps.sqa.*;
import java.io.IOException;
import java.util.*;
public class SQLExecutorExample {
public static void SimpleExample() {
// 设置账号和项目信息。
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户
// 此处以把AccessKey 和 AccessKeySecret 保存在环境变量为例说明。您也可以根据业务需要,保存到配置文件里
// 强烈建议不要把 AccessKey 和 AccessKeySecret 保存到代码里,会存在密钥泄漏风险
Account account = new AliyunAccount(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"));
Odps odps = new Odps(account);
odps.setDefaultProject("<YOUR_PROJECT_NAME>");
odps.setEndpoint("http://service.<regionid>.maxcompute.aliyun.com/api");
// 准备构建SQLExecutor。
SQLExecutorBuilder builder = SQLExecutorBuilder.builder();
SQLExecutor sqlExecutor = null;
try {
// run in offline mode or run in interactive mode
if (false) {
// 创建一个默认执行离线SQL的Executor。
sqlExecutor = builder.odps(odps).executeMode(ExecuteMode.OFFLINE).build();
} else {
// 创建一个默认执行查询加速SQL的Executor,并且在查询加速模式失败后,自动回退到离线查询。
sqlExecutor = builder.odps(odps).executeMode(ExecuteMode.INTERACTIVE).fallbackPolicy(FallbackPolicy.alwaysFallbackPolicy()).build();
}
// 如果需要的话可以传入查询的特殊设置。
Map<String, String> queryHint = new HashMap<>();
queryHint.put("odps.sql.mapper.split.size", "128");
// 提交一个查询作业,支持传入Hint。
sqlExecutor.run("select count(1) from test_table;", queryHint);
// 列举一些支持的常用获取信息的接口。
// UUID
System.out.println("ExecutorId:" + sqlExecutor.getId());
// 当前查询作业的logview。
System.out.println("Logview:" + sqlExecutor.getLogView());
// 当前查询作业的Instance对象(Interactive模式多个查询作业可能为同一个Instance)。
System.out.println("InstanceId:" + sqlExecutor.getInstance().getId());
// 当前查询作业的阶段进度(Console的进度条)。
System.out.println("QueryStageProgress:" + sqlExecutor.getProgress());
// 当前查询作业的执行状态变化日志,例如回退信息。
System.out.println("QueryExecutionLog:" + sqlExecutor.getExecutionLog());
// 提供两种获取结果的接口。
if(false) {
// 直接获取全部查询作业结果,同步接口,可能会占用本线程直到查询成功或失败。
// 一次性读取全部结果数据到内存中,当数据量较大时不建议使用,可能会有内存问题。
List<Record> records = sqlExecutor.getResult();
printRecords(records);
} else {
// 获取查询结果的迭代器ResultSet,同步接口,可能会占用本线程直到查询成功或失败。
// 获取大量结果数据时推荐使用,分次读取查询结果。
ResultSet resultSet = sqlExecutor.getResultSet();
while (resultSet.hasNext()) {
printRecord(resultSet.next());
}
}
// run another query
sqlExecutor.run("select * from test_table;", new HashMap<>());
if(false) {
// 直接获取全部查询结果,同步接口,可能会占用本线程直到查询成功或失败。
// 一次性读取全部结果数据到内存中,当数据量较大时不建议使用,可能会有内存问题。
List<Record> records = sqlExecutor.getResult();
printRecords(records);
} else {
// 获取查询结果的迭代器ResultSet,同步接口,可能会占用本线程直到查询成功或失败。
// 获取大量结果数据时推荐使用,分次读取查询结果。
ResultSet resultSet = sqlExecutor.getResultSet();
while (resultSet.hasNext()) {
printRecord(resultSet.next());
}
}
} catch (OdpsException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (sqlExecutor != null) {
// 关闭Executor释放相关资源。
sqlExecutor.close();
}
}
}
// SQLExecutor can be reused by pool mode
public static void ExampleWithPool() {
// 设置账号和项目信息。
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户
// 此处以把AccessKey 和 AccessKeySecret 保存在环境变量为例说明。您也可以根据业务需要,保存到配置文件里
// 强烈建议不要把 AccessKey 和 AccessKeySecret 保存到代码里,会存在密钥泄漏风险
Account account = new AliyunAccount(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"));
Odps odps = new Odps(account);
odps.setDefaultProject("your_project_name");
odps.setEndpoint("http://service.<regionid>.maxcompute.aliyun.com/api");
// 通过连接池方式执行查询。
SQLExecutorPool sqlExecutorPool = null;
SQLExecutor sqlExecutor = null;
try {
// 准备连接池,设置连接池大小和默认执行模式。
SQLExecutorPoolBuilder builder = SQLExecutorPoolBuilder.builder();
builder.odps(odps)
.initPoolSize(1) // init pool executor number
.maxPoolSize(5) // max executors in pool
.executeMode(ExecuteMode.INTERACTIVE); // run in interactive mode
sqlExecutorPool = builder.build();
// 从连接池中获取一个Executor,如果不够将会在Max限制内新增Executor。
sqlExecutor = sqlExecutorPool.getExecutor();
// Executor具体用法和上一示例一致。
sqlExecutor.run("select count(1) from test_table;", new HashMap<>());
System.out.println("InstanceId:" + sqlExecutor.getId());
System.out.println("Logview:" + sqlExecutor.getLogView());
List<Record> records = sqlExecutor.getResult();
printRecords(records);
} catch (OdpsException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
sqlExecutor.close();
}
sqlExecutorPool.close();
}
private static void printRecord(Record record) {
for (int k = 0; k < record.getColumnCount(); k++) {
if (k != 0) {
System.out.print("\t");
}
if (record.getColumns()[k].getType().equals(OdpsType.STRING)) {
System.out.print(record.getString(k));
} else if (record.getColumns()[k].getType().equals(OdpsType.BIGINT)) {
System.out.print(record.getBigint(k));
} else {
System.out.print(record.get(k));
}
}
}
private static void printRecords(List<Record> records) {
for (Record record : records) {
printRecord(record);
System.out.println();
}
}
public static void main(String args[]) {
SimpleExample();
ExampleWithPool();
}
}方式五:基于PyODPS,使用SQLAlchemy或其他支持SQLAlchemy接口的第三方工具实现查询加速
PyODPS集成了SQLAlchemy,可以使用SQLAlchemy查询MaxCompute数据。需要在连接串中指定如下参数实现查询加速:
interactive_mode=true:必填。查询加速功能总开关。reuse_odps=true:可选。打开强制复用连接,对于部分第三方工具(例如Apache Superset),打开此选项可提高性能。
可以在连接串中配置fallback_policy=<policy1>,<policy2>,...参数,完善处理逻辑。与JDBC的配置项类似,控制加速失败的回退行为。
generic:默认为False,设置为True时,表示发生未知错误时回退到离线模式。noresource:默认为False,设置为True时,表示发生资源不足问题时回退到离线模式。upgrading:默认为False,设置为True时,表示升级期间回退到离线模式。timeout:默认为False,设置为True时,表示执行超时时回退到离线模式。unsupported:默认为False,设置为True时,表示遇到MCQA不支持的场景时回退到离线模式。default:等同于同时指定unsupported、upgrading、noresource和timeout。如果连接串中未指定fallback_policy,则此项为默认值。all:默认为False,设置为True时,表示在以上几种场景下全部回退到离线模式。
使用示例
打开查询加速,打开强制复用链接,在查询加速功能尚未支持、升级中和资源不足时回退到离线模式的连接串如下。
odps://<access_id>:<ACCESS_KEY>@<project>/?endpoint=<endpoint>&interactive_mode=true&reuse_odps=true&fallback_policy=unsupported,upgrading,noresource常见问题
问题一:使用JDBC链接MaxCompute,执行包年包月资源的SQL任务时报错(ODPS-1800001),详细报错信息如下。
sError:com.aliyun.odps.OdpsException: ODPS-1800001: Session exception - Failed to submit sub-query in session because:Prepaid project run out of free query quota.可能原因:
当前查询加速功能正在公测中,如果已购买包年包月套餐,公测期间,无需进行额外操作,即可免费体验查询加速功能。免费体验查询加速时,单个MaxCompute项目支持的最大作业并发数为5,日免费加速作业数累计为500个。如果作业数超过500个时,会出现上述报错。
解决方法:
需要在配置JDBC启用MCQA功能的配置过程中,设置alwaysFallback参数值为true,设置完成后,没有超过500个作业数时,能正常使用MCQA进行查询加速,超过500个的作业会退回至离线模式。配置的详细操作及参数解释请参见MCQA渠道接入说明。
问题二:基于PyODPS发送请求并获取结果的时长比DataWorks长。
可能原因:
使用了
wait_for_xxx方法,延长了时间。轮询间隔时间长。
解决方法:
请求本身运行很快的情况下,不使用
wait_for_xxx方法,发出请求后直接使用Tunnel下载结果。调低轮询间隔:
instance.wait_for_success(interval=0.1)。命令示例如下。from odps import ODPS, errors max_retry_times = 3 def run_sql(odps, stmt): retry = 0 while retry < max_retry_times: try: inst = odps.run_sql_interactive(stmt) print(inst.get_logview_address()) inst.wait_for_success(interval=0.1) records = [] for each_record in inst.open_reader(tunnel=True): records.append(each_record) return records except errors.ODPSError as e: retry = retry + 1 print("Error: " + str(e) + " retry: " + str(retry) + "/" + str(max_retry_times)) if retry >= max_retry_times: raise e odps = ODPS(...) run_sql(odps, 'SELECT 1')
问题三:基于SDK如何使用Logview排查Java SDK报错?
解决方法:MaxCompute Java SDK提供了Logview接口,请使用如下命令调用Logview接口获取日志。
String logview = sqlExecutor.getLogView();问题四:基于JDBC如何获取MaxCompute Logview URL?
解决方法:MaxCompute JDBC Driver是基于MaxCompute Java SDK的封装。因此使用时和MaxCompute客户端、MaxCompute Studio以及DataWorks一样,通过MaxCompute JDBC Driver执行SQL时,会生成Logview URL。您可以通过Logview查看任务执行状态、追踪任务进度、获取任务执行结果。Logview URL可以通过配置日志输出(properties.log4j),默认以标准输出打印到终端屏幕。