本文为您介绍Logview 2.0的功能及使用,本文简称Logview。您可以通过Logview URL查看作业运行信息。
概述
Logview是MaxCompute作业运行状态信息记录与展现的一个工具,目前支持如下功能:
支持以交互式DAG图展示作业处理逻辑架构,您还可以查看相应的Operation层级。
支持回放作业运行过程。
支持通过Fuxi Sensor查看内存及CPU使用情况。
Logview入口
当您提交运行MaxCompute作业时,系统会自动生成一个以https://logview.aliyun.com/logview开头的URL地址。
使用MaxCompute客户端(odpscmd)提交作业后,您需要手工复制该地址到浏览器中访问。
使用DataWorks提交作业后,您直接点击链接就可以打开Logview界面。
Logview界面如下。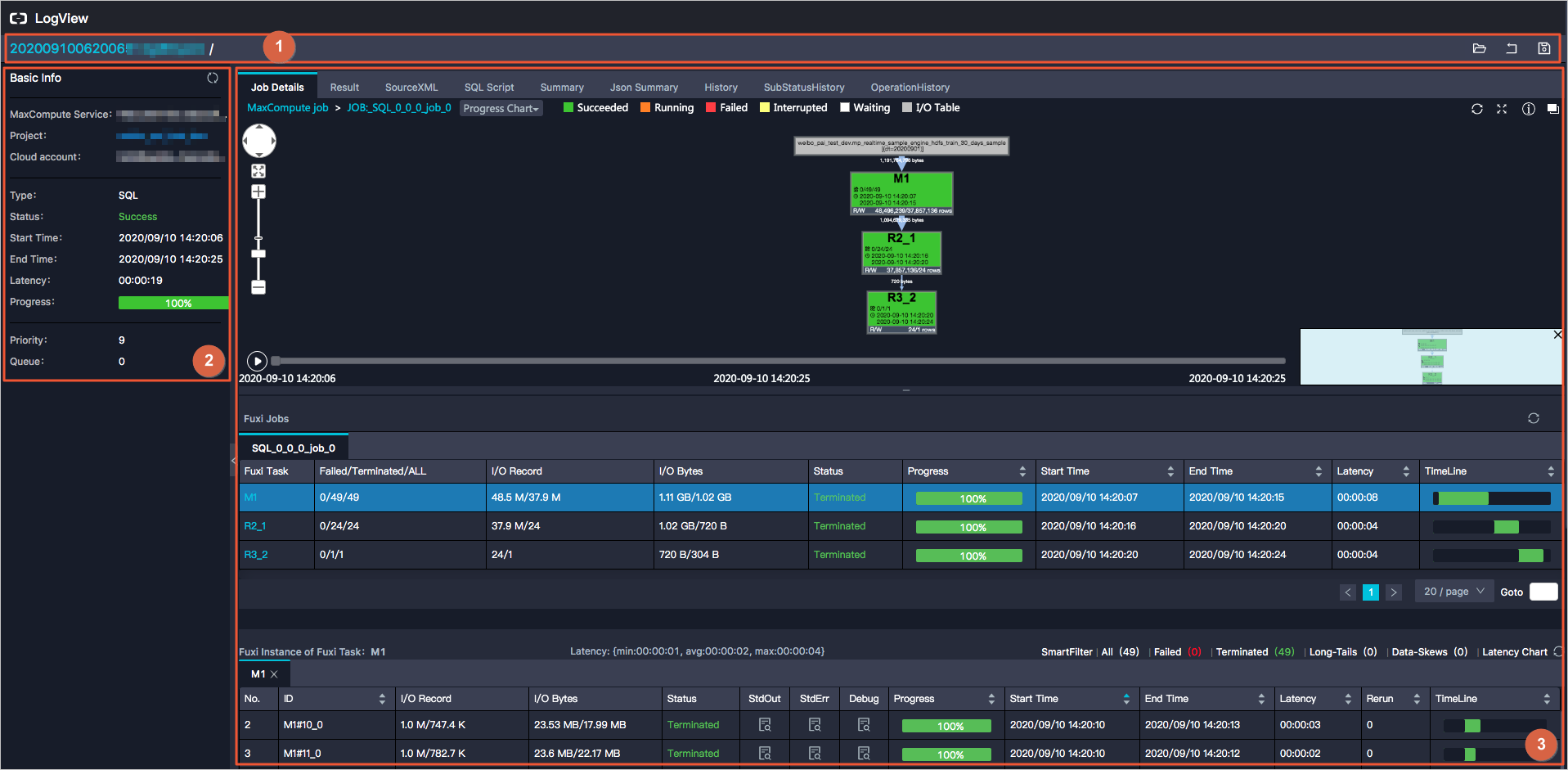
序号 | 区域 |
① | 标题与功能区,详情请参见标题和功能区。 |
② | Basic Info,详情请参见Basic Info。 |
③ | 作业详情,详情请参见作业详情。 |
标题和功能区
标题与功能区包含您提交MaxCompute作业时生成的唯一作业ID及您自定义的作业名称(通过SDK方式提交的作业包含作业名称信息)。您还可以执行如下操作。
图标 | 功能 |
| 打开本地保存的作业详情文件Logview_detail.txt。 |
| 返回Logview 1.0版界面。 |
| 将作业详情文件保存至本地设备。 |
Basic Info
Basic Info区域展示的作业基本信息如下。
参数名 | 描述 |
MaxCompute Service | 作业使用的MaxCompute服务的Endpoint。Endpoint详情请参见Endpoint。 |
Project | 作业所属的MaxCompute项目名称。 |
Cloud account | 提交作业的阿里云账号信息。 |
Type | 作业的类型。例如SQL、SQLRT、LOT、XLib、CUPID、AlgoTask和Graph。 |
Status | 作业的状态。状态取值如下:
|
Start Time | 作业提交时间。 |
End Time | 作业执行结束时间。 |
Latency | 作业执行消耗的时长。 |
Progress | 作业执行进度。 |
Priority | 作业优先级。 |
Queue | 作业在资源配额组内的排队位置。 |
作业详情
您可以通过作业详情区域全方位了解作业,作业详情区域包含如下功能区:
Job Details
作业执行图
Job Detail页签的上半部分为作业执行图。执行图以可视化方式展示三个维度的子任务依赖关系:Fuxi Job层、Fuxi Task层和Operation层,同时提供一系列辅助工具,为排查问题提供帮助。界面构成如下。
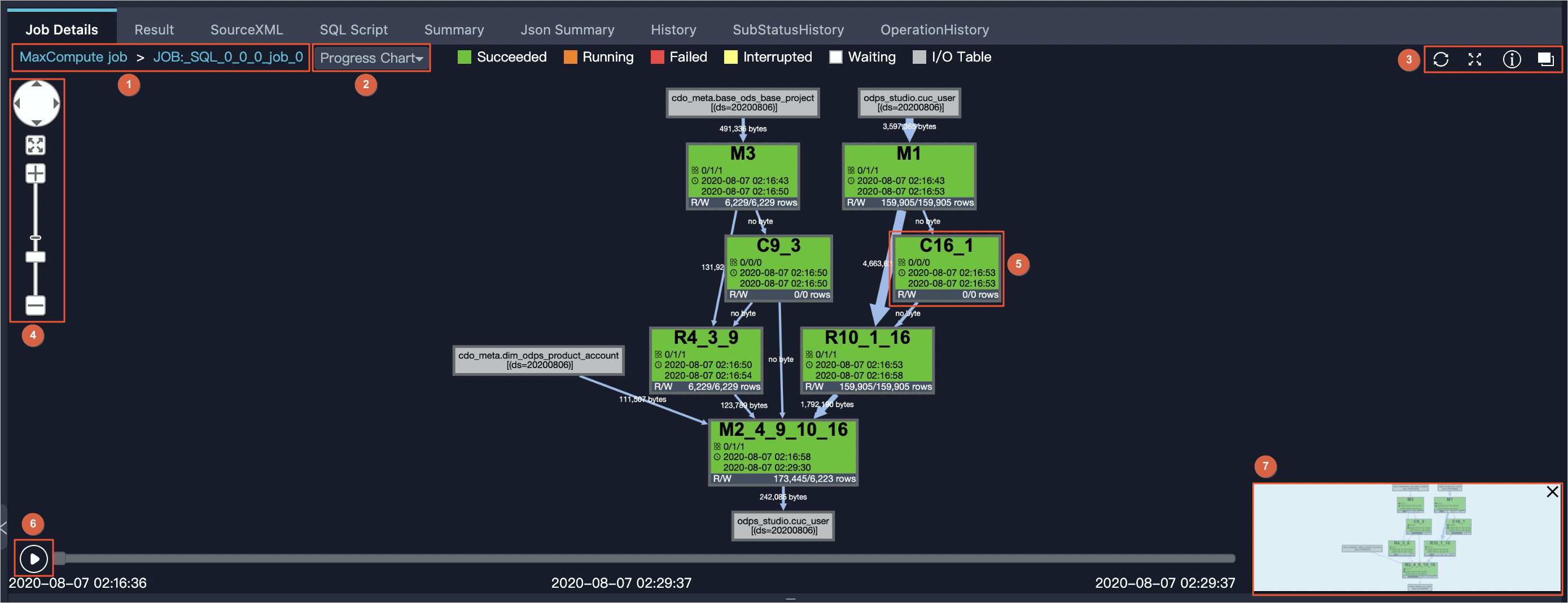
序号
描述
①
面包屑导航,用于切换Fuxi Job。JOB:_SQL_0_0_0_job_0为Fuxi Job名称。
②
排查问题辅助工具。包含Progress Chart、Input Heat Chart、Output Heat Chart、TaskTime Heart Chart和InstanceTime Heart Chart。
③
您可以在此区域刷新作业执行状态(
 )、全屏或缩放显示作业执行图(
)、全屏或缩放显示作业执行图( )、获取MaxCompute Studio文档(
)、获取MaxCompute Studio文档( )和切换至任务上一层级(
)和切换至任务上一层级( )。
)。④
缩放辅助工具。
⑤
Fuxi Task。一个MaxCompute作业由一个或多个Fuxi Job组成。每个Fuxi Job由一个或多个Fuxi Task组成。每个Fuxi Task由一个或者多个Fuxi Instance组成,当用户的输入数据量变大时,MaxCompute会在每个Task启动更多的节点来处理数据,每个节点就是一个Fuxi Instance。例如,简单的MapReduce通常会产生两个Fuxi Task,一个是Map一个是Reduce,两个Fuxi Task的名称分别为M1和R2,当SQL比较复杂时,可能会产生多个Fuxi Task。
您可以在执行界面上看到每个Fuxi Task的名称。例如M1,表示一个Map Task;R4_3_9的3、9表示它依赖M3、C9_3执行结束才能开始执行。同理,M2_4_9_10_16表示M2要依赖R4_3_9、C9_3、R10_1_16、C16_1四个Task执行结束后才能开始执行。R/W表示Task读取和写的行数。
单击某个Task或在Task上单击右键可以查看Task对应的Operator算子依赖关系及全部Operator算子图。
您可以快速查看输入和输出表。
⑥
Fuxi Task回放。单击
 即可开始播放,再次单击则暂停。您也可以手动拖动进度条。进度条左边为开始时间,中间为播放时间,右边为结束时间。
即可开始播放,再次单击则暂停。您也可以手动拖动进度条。进度条左边为开始时间,中间为播放时间,右边为结束时间。⑦
鹰眼。
说明不支持回放Running状态的Fuxi Task。
AlgoTask类型的作业(例如PAI机器学习),由于只有一个Fuxi Task,故不提供作业执行图。
非SQL类型作业,仅能展示Fuxi Job和Fuxi Task层,不支持展示Operation层。
如果只有一个Fuxi Job,作业执行图默认展示Fuxi Task层依赖关系;否则,默认展示Fuxi Job层依赖关系。
作业运行情况
Job Detail页签的下半部分为作业运行详细信息。界面构成如下。
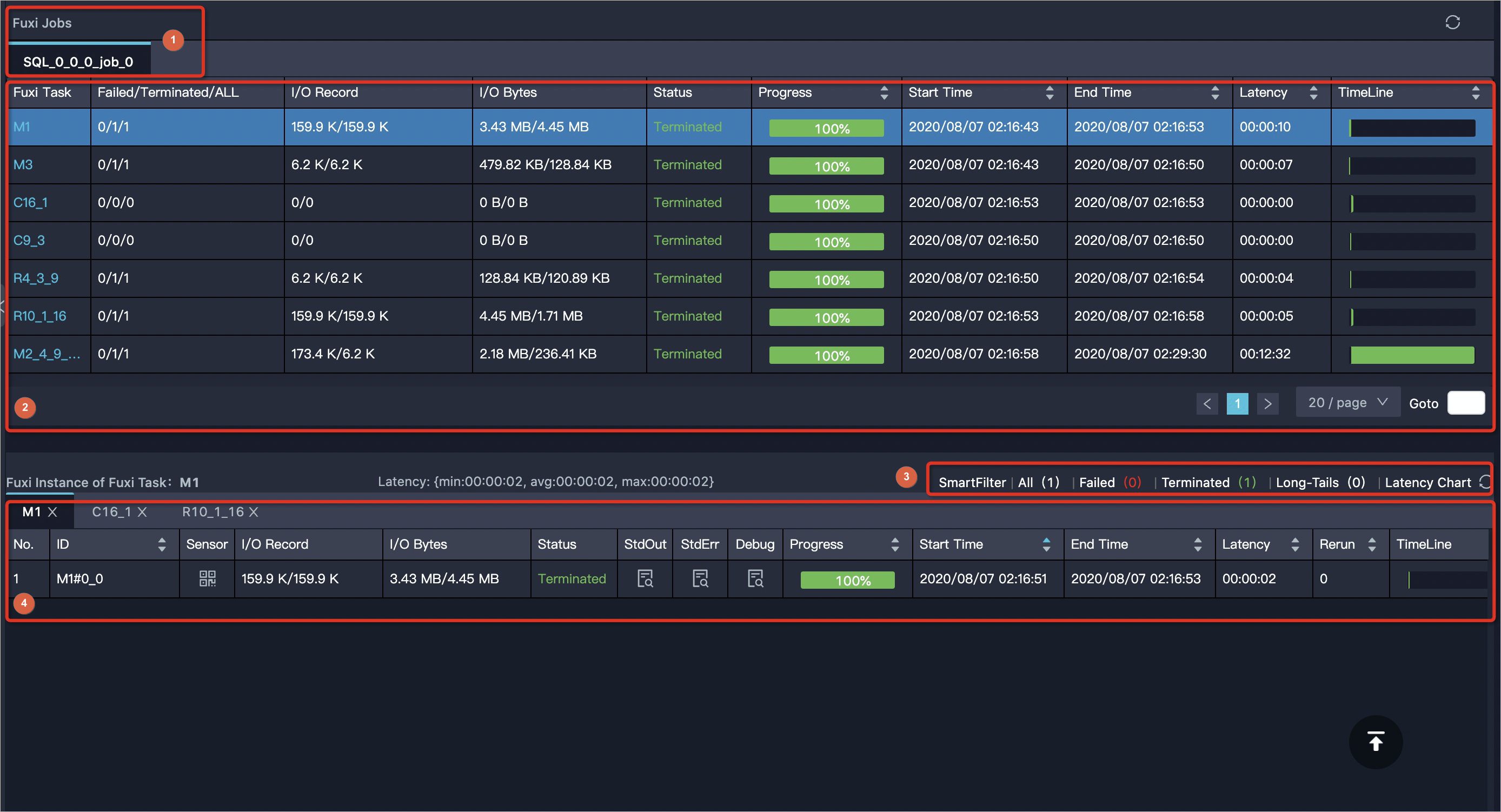
序号
描述
①
Fuxi Job页签,您可以在此切换Fuxi Job。
②
Fuxi Job对应的Fuxi Task详情。在某个Fuxi Job下,单击任一Fuxi Task,在下方会展开该Fuxi Task对应的Fuxi Instance信息。默认展开第一个Fuxi Job的第一个Fuxi Task的Fuxi Instance信息。
对于AlgoTask和CUPID类型作业,此区域会提供Sensor列,您可以单击Fuxi Task对应的Sensor查看Fuxi Instance的CPU及内存信息。Fuxi Job分类如下:
M:数据扫描的作业。
R:R开头的是Reduce Job。
J: J开头的是Join Job。
C:C开头的作业是一个虚拟节点,不涉及任何计算,只做判断选择分支使用。
说明Fuxi Sensor功能在西南1(成都)、华南1(深圳)、华东2(上海)、华东1(杭州)、华北3(张家口)和华北2(北京)区域已开放。
Fuxi Task会有可能因为
interrupted状态而重试运行,此时Progress只显示重试运行部分的进度,所以会出现整个作业已经执行成功但是此Fuxi Task的Progress不是100%的现象,此为正常显示。
③
Logview为不同阶段的Instance进行了分组。您可以单击Failed快速查看出错的节点。
④
Fuxi Instance。
ID示例为
M1#0_0,其中第一个0的位置代表Fuxi Instance的自增ID;第二个0的位置代表任务的重跑次数,0代表没有重跑,值为几就代表重跑几次。StdOut和StdErr。您可以查看输出和错误信息,您自己打印的信息也可以在这里查看,同时提供下载功能。
Debug。调测并排除错误。
Fuxi Instance数量限制:
当使用如下SQL语句时,Fuxi Instance个数限制为1个。
limit。窗函数SQL中没有
partition by key。Aggregate操作SQL中没有
group by key。Join操作SQL中没有等值Join Key。
order by。
Fuxi Sensor
Fuxi Sensor是展示MaxCompute作业全维度的资源视图。您可以通过Fuxi Sensor查看Fuxi Instance的CPU及内存的实际消耗量。Fuxi Sensor是作业问题定位以及作业运行质量分析的重要工具。例如以下场景的作业问题可借助Fuxi Sensor进行分析:
作业内存溢出时,分析实际使用的内存量。
查看机器学习作业Fuxi Instance的以下资源使用情况:
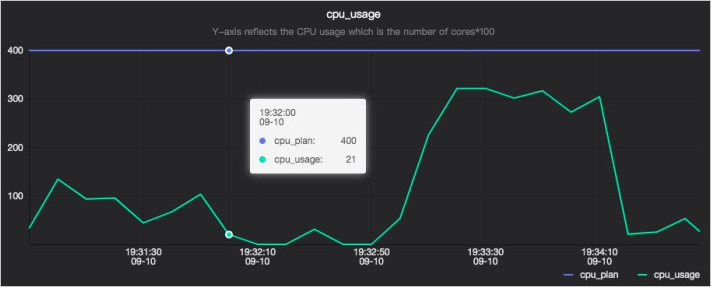
CPU使用量
CPU指标包括两条线,一条显示申请的CPU量(cpu_plan),另一条显示实际的CPU使用量(cpu_usage)。纵坐标中的400,表示4个Processor。目前用户只可以通过调整Processor的个数来调整申请的CPU量,目前用户无法调整CPU使用量。
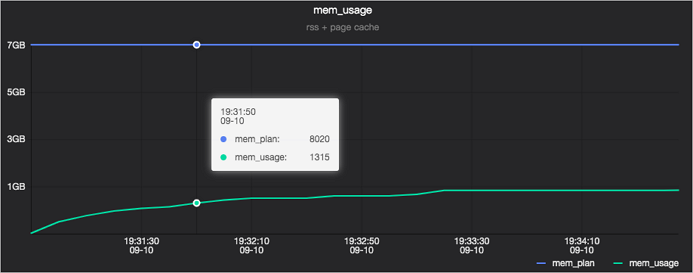
内存使用量
内存指标包括两条线,一条显示申请的内存量(mem_plan),另一条显示实际的内存使用量(mem_usage)。
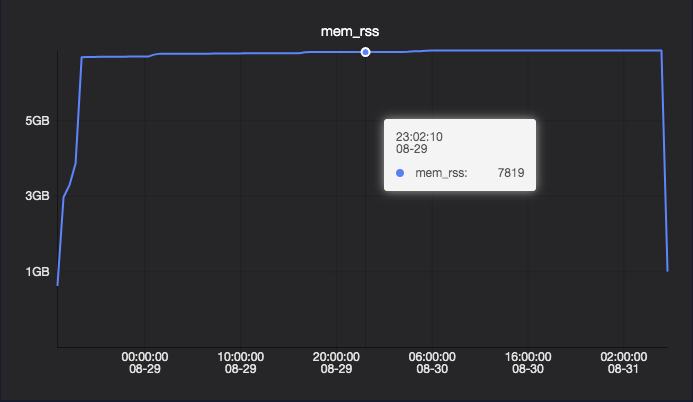
内存使用量(mem_usage)包括两部分信息RSS(Resident Set Size)和PageCache。RSS是Malloc(非文件映射)发生缺页之后的内存,该部分内存,在内存紧张时无法被回收。PageCache是内核缓存文件占用的内存,例如读写日志文件,PageCache在内存紧张时通常是可以被回收。
内存详情
RSS内存使用量
PageCache内存使用量

Result
Result页签显示的内容有如下两种情况:
当前作业运行成功,显示的为运行结果。
您可以使用如下面命令选择关闭显示运行结果。
setproject odps.forbid.fetch.result.by.bearertoken=true;您可以通过设置如下Flag参数改变显示结果样式。
--CSV格式 set odps.sql.select.output.format=csv; --Text格式 set odps.sql.select.output.format=HumanReadable;
当前作业运行失败,显示的为失败原因。
SourceXML
XML
在该页签下以XML方式显示作业等级以及Task相关信息。
Settings
在该页签下显示了当前Task的相关Setting信息。
Command
在该页签下显示了当前Task的相关Flag设置情况。
SQL Script
该页签下显示当前Task的SQL运行脚本。
History
该页签下显示了当前Task的运行历史记录。
SubStatusHistory
在该页签下显示了当前SubTask的运行状态,具体含义如下。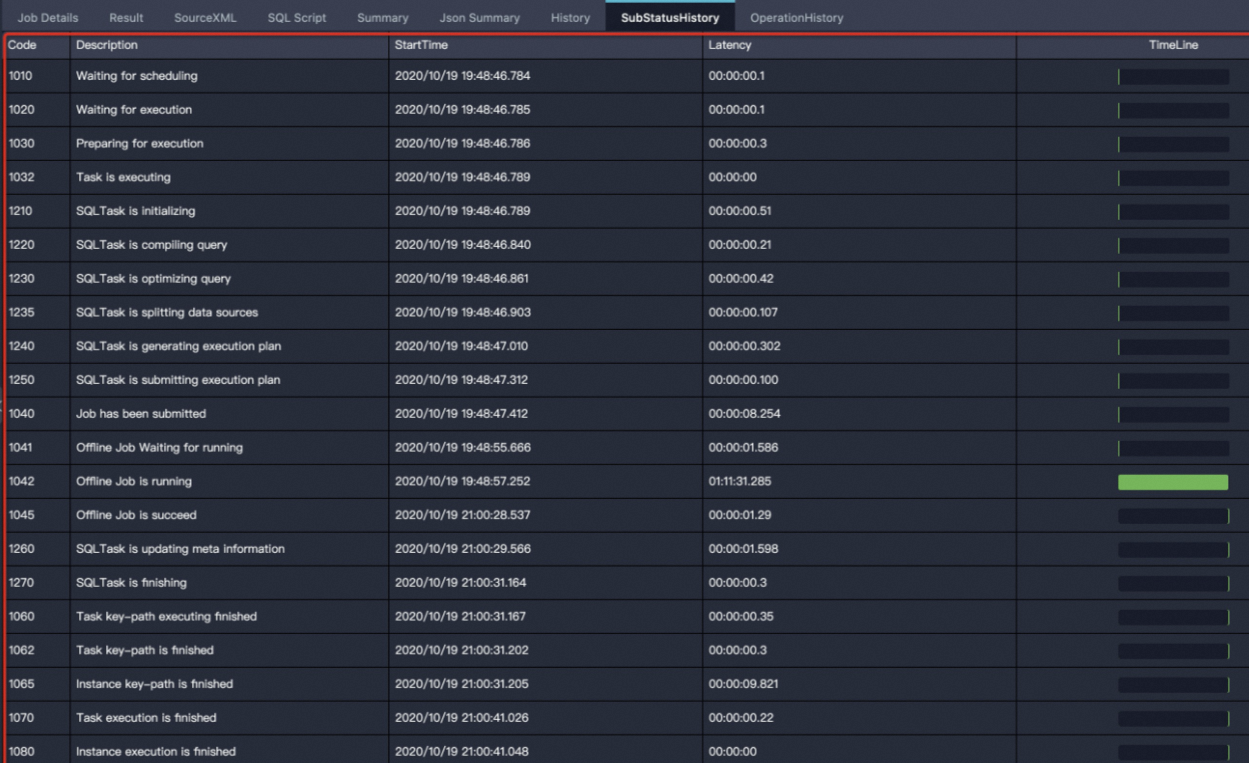
状态 | 说明 |
Waiting for scheduling | 作业已提交,等待MaxCompute框架调度,通常时间很短。 |
Waiting for cluster resource | MaxCompute框架发现Fuxi计算集群没资源,等待中。 |
Waiting for concurrent task slot | Project级别流控,Project可以设置并行提交SQL个数。 |
Waiting for data replication | 等待数据复制。 |
Waiting for execution slot | 系统级别流控。 |
Waiting for cleaning up of previous task attempt | 等待清理执行历史完成。 |
Waiting for execution | 从父进程队列拿出来分发给子进程执行过程,通常很快。 |
Preparing for execution | 明确知道交给子进程,如果子进程出问题才会时间长。 |
Task is executing | 作业在框架处理中。 |
SQLTask is initializing | SQL作业初始化中。 |
SQLTask is compiling query | SQL作业编译中。 |
SQLTask is optimizing query | SQL作业优化Query,如果执行计划复杂,优化时间会稍长,但过长可能就是出问题了。 |
SQLTask is splitting data sources | SQL作业优化中,切分Data Sources。 |
SQLTask is generating execution plan | SQL作业生成执行计划中,时间长可能是读取分区太多,或者小文件太多。 |
SQLTask is submitting execution plan | SQL作业提交执行计划。 |
Job has been submitted | 作业提交计算集群。 |
Offline Job Waiting for running | 作业提交计算集群后发现Fuxi集群Quota组无资源,此状态表示作业在等待计算资源。作业提交计算集群前本来以为有计算资源,实际提交后发现无计算资源,就会等待。此状态只会出现一次,后续就算没有计算资源也不会再显示。 |
Offline Job is running | Fuxi作业执行中, 如果运行中无资源,会一直保持该状态。例如高优先级作业抢占资源,导致部分Fuxi Instance不能运行,状态为 |
Offline Job is failed | Fuxi作业执行失败。 |
Offline Job is succeed | Fuxi作业执行成功。 |
SQLTask is updating meta information | SQL作业更新元数据信息状态,生成动态分区时,时间可能会稍长。 |
SQLTask is finishing | SQL作业执行结束。 |
Online Job is cancelled by fuxi |
|
Task rerun | 作业重跑,可能是 |
Online Job Waiting for running |
|
Online Job is running |
|
Online Job is failed |
|
Online Job is succeed |
|
Online Job is cancelled by fuxi |
|
Task key-path executing finished | 作业关键路径完成,但是Detailstatus等尚未完成. |
Task key-path is finished | 作业关键路径完成。 |
Instance key-path is finished | Instance关键路径完成。 |
Task execution is finished | 作业处理完成,生成DetailStatus。 |
Instance execution is finished | 作业处理完成。 |
Execution failed | 作业执行失败。 |