如果您想了解费用的分布情况并避免在使用MaxCompute产品时费用超出预期,您可以通过获取MaxCompute账单并进行分析,为资源使用率最大化及降低成本提供有效支撑。本文为您介绍如何通过用量明细表分析MaxCompute的费用分布情况。
背景信息
MaxCompute是一款大数据分析平台,其计算资源的计费方式分为包年包月和按量付费两种。MaxCompute每天以项目为维度进行计费,账单会在第二天06:00前生成。更多MaxCompute计量计费信息,请参见计费项与计费方式。
MaxCompute会在数据开发阶段或者产品上线前发布账单波动(通常情况下为消费增长)信息。您可以自助分析账单波动情况,再对MaxCompute项目的作业进行优化。您可以在阿里云费用中心下载阿里云所有收费产品的用量明细。更多获取和下载账单操作,请参见查看账单详情。
步骤一:下载用量明细
您可以通过用量明细下载每天的详细使用信息,了解费用是如何产生。例如每天的存储费用、计算费用是由哪些任务产生的。
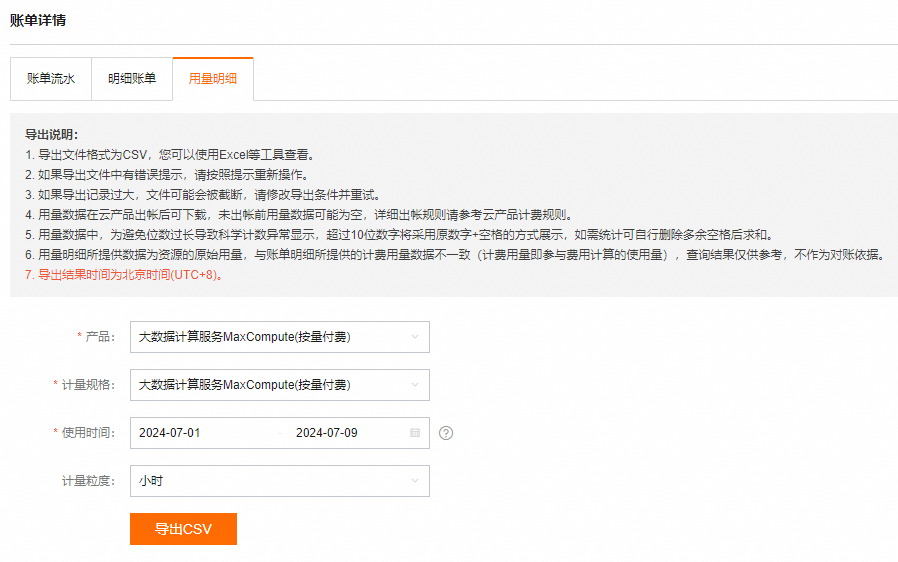
配置参数说明如下:
产品:选择大数据计算服务MaxCompute(按量付费)。
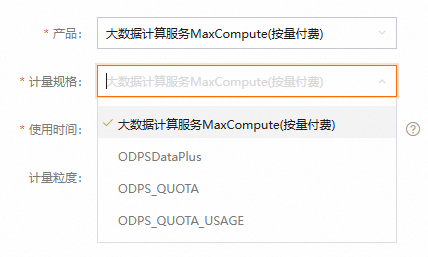
计量规格:
大数据计算服务MaxCompute(按量付费):计算、存储、下载等按量付费计费项的计量明细。
ODPSDataPlus:
某一地域下MaxCompute仅购买包年包月项目而并没有购买按量付费项目。该情形下涉及包年包月项目中存储、下载按量付费计费项的计量明细。
2024年04月25日之前,在中国香港或海外某一地域下MaxCompute同时开通了包年包月项目和按量付费项目。该情形下涉及默认计算Quota是包年包月项目的存储、下载按量付费计费项的计量明细。
而该情形下默认计算Quota为按量付费项目的计量明细,则通过大数据计算服务MaxCompute(按量付费)来查询获取。
ODPS_QUOTA:该参数暂无业务应用,无需关注使用。
ODPS_QUOTA_USAGE:计算和独享Tunnel的弹性预留资源的计量明细。
使用时间:单击下拉框选择开始时间和结束时间。
如果出现跨天执行的任务,例如某任务开始时间为12月1日,结束时间为12月2日,那么需要选择开始时间为12月1日才能在下载的用量明细表中查询到该任务,但是该任务的消费记录体现在12月2日的账单中。
计量粒度:默认单位为小时。
单击导出CSV,等待一段时间后,可前往导出记录下载用量明细表。
步骤二(可选):上传用量明细数据至MaxCompute
如果您期望通过MaxCompute SQL进行用量明细分析,则需要参考本步骤将用量明细导入MaxCompute;如果您只希望使用Excel进行用量明细分析,则无需进行此步骤。
使用MaxCompute客户端(odpscmd)按如下示例语句创建
maxcomputefee表。CREATE TABLE IF NOT EXISTS maxcomputefee ( projectid STRING COMMENT '项目编号' ,feeid STRING COMMENT '计费信息编号' ,meteringtime STRING COMMENT '文件表头(MeteringTime)' ,type STRING COMMENT '数据分类,包括Storage、ComputationSQL、DownloadEx等' ,starttime STRING COMMENT '开始时间' ,storage BIGINT COMMENT '存储(Byte)' ,endtime STRING COMMENT '结束时间' ,computationsqlinput BIGINT COMMENT 'SQL/交互式分析读取量(Byte)' ,computationsqlcomplexity DOUBLE COMMENT 'SQL复杂度' ,uploadex BIGINT COMMENT '公网上行流量Byte' ,download BIGINT COMMENT '公网下行流量Byte' ,cu_usage DOUBLE COMMENT 'MR/Spark作业计算(core*second)' ,Region STRING COMMENT '地域' ,input_ots BIGINT COMMENT '访问OTS的数据输入量' ,input_oss BIGINT COMMENT '访问OSS的数据输入量' ,source_id STRING COMMENT 'DataWorks调度任务ID' ,source_type STRING COMMENT '计算资源规格' ,RecycleBinStorage BIGINT COMMENT '备份存储(Byte)' ,JobOwner STRING COMMENT '作业Owner' ,Signature STRING COMMENT 'SQL作业签名' );账单明细字段说明如下:
项目编号:当前账号或RAM用户对应的阿里云账号的MaxCompute项目列表。
计量信息编号:以存储、计算、上传和下载的任务ID为计费信息编号,SQL为InstanceID,上传和下载为Tunnel SessionId。
数据分类:Storage(存储)、ComputationSql(计算)、UploadIn(内网上传)、UploadEx(外网上传)、DownloadIn(内网下载)、DownloadEx(外网下载)。按照计费规则只有红色部分为实际计费项目。
存储(Byte):每小时读取的存储量,单位为Byte。
开始时间或结束时间:按照实际作业执行时间进行计量,只有存储是按照每个小时取一次数据。
SQL/交互式分析读取量(Byte):SQL计算项,每一次SQL执行时SQL的Input数据量,单位为Byte。
SQL复杂度:SQL的复杂度,为SQL计费因子之一。
公网上行流量(Byte)或公网下行流量(Byte):分别为外网上传或下载的数据量,单位为Byte。
MR/Spark作业计算(Core*Second):MapReduce或Spark作业的计算时单位为
Core*Second,需要转换为计算时Hour。SQL读取量_访问OTS(Byte)、SQL读取量_访问OSS(Byte):外部表实施收费后的读取数据量,单位为Byte。
备份存储(Byte):每小时读取的备份存储量,单位为Byte。
地域:MaxCompute项目所在的地域。
作业Owner:提交作业的用户。
SQL作业签名:用于标识SQL作业,主体内容一致、而多次重复或调度执行的SQL作业签名一致。
使用Tunnel上传数据。
在上传CSV文件时,您需确保CSV文件中的列数、数据类型必须与表maxcomputefee的列数、数据类型保持一致,否则会导入失败。
tunnel upload ODPS_2019-01-12_2019-01-14.csv maxcomputefee -c "UTF-8" -h "true" -dfp "yyyy-MM-dd HH:mm:ss";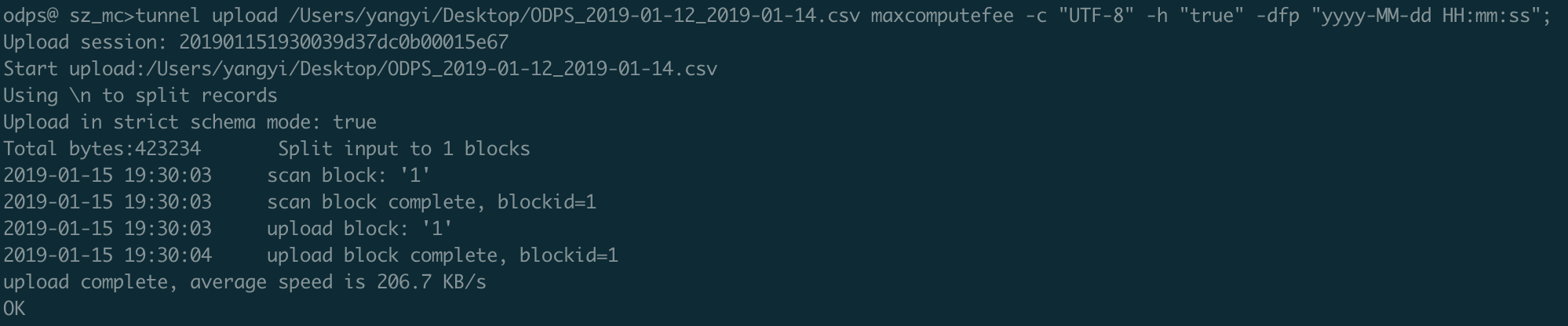 说明
说明Tunnel的配置详情请参见Tunnel命令。
您也可以通过DataWorks的数据导入功能来执行此操作,具体请参见使用DataWorks(离线与实时)。
执行如下语句验证数据。
SELECT * FROM maxcomputefee limit 10;
步骤三:分析账单数据
分析SQL费用。
云上用户使用MaxCompute,95%的用户通过SQL即可满足需求,SQL也在消费增长中占很大比例。
一次SQL计算费用 = 计算输入数据量×SQL复杂度×单价(0.0438 USD/GB)
通过Excel分析:分析用量明细中数据分类为ComputationSql的数据。对SQL作业费用进行排序,观察是否存在某些SQL作业费用超出预期或者SQL任务过多。SQL作业费用计算公式为(
SQL/交互式分析读取量(Byte)/1024/1024/1024 × SQL复杂度 × SQL单价)。通过SQL分析(已完成步骤二的数据导入,生成maxcomputefee表):
--分析SQL消费,按照sqlmoney排行。 SELECT to_char(endtime,'yyyymmdd') as ds,feeid as instanceid ,projectid ,computationsqlcomplexity --复杂度 ,SUM((computationsqlinput / 1024 / 1024 / 1024)) as computationsqlinput --数据输入量(GB) ,SUM((computationsqlinput / 1024 / 1024 / 1024)) * computationsqlcomplexity * 0.0438 AS sqlmoney FROM maxcomputefee WHERE TYPE = 'ComputationSql' AND to_char(endtime,'yyyymmdd') >= '20190112' GROUP BY to_char(endtime,'yyyymmdd'),feeid ,projectid ,computationsqlcomplexity ORDER BY sqlmoney DESC LIMIT 10000 ;根据查询结果可以得到以下结论:
大作业可以减小数据读取量、降低复杂度、优化费用成本。
可以按照
ds字段(按照天)进行汇总,分析某个时间段内的SQL消费金额走势。例如利用本地Excel或Quick BI等工具绘制折线图等方式,更直观地反映作业的趋势。根据执行结果可以定位到需要优化的点,方法如下:
通过查询的instanceid,获取目标实例运行日志的Logview地址。
在MaxCompute客户端(odpscmd)或DataWorks中执行
wait <instanceid>;命令,查看instanceid的运行日志。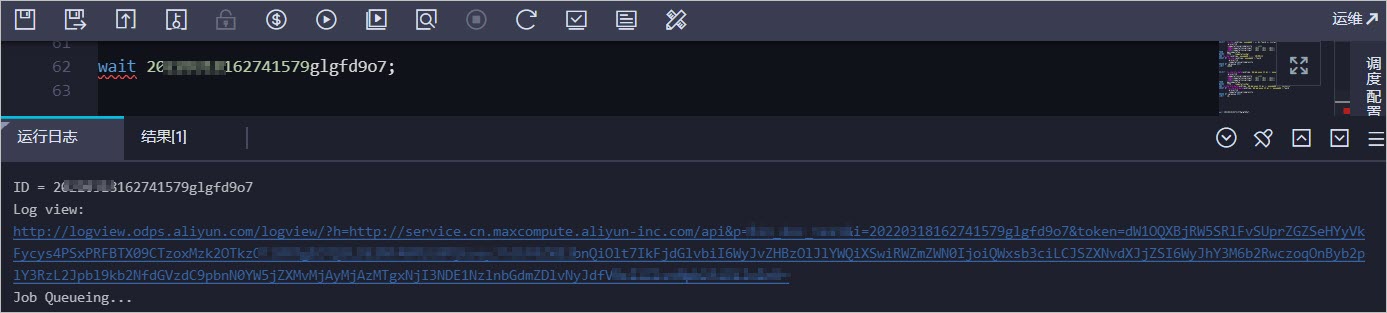
通过如下命令查看作业的详细信息。
DESC instance 2016070102275442go3xxxxxx;返回结果如下:
ID 2016070102275442go3xxxxxx Owner ALIYUN$***@aliyun-inner.com StartTime 2016-07-01 10:27:54 EndTime 2016-07-01 10:28:16 Status Terminated console_query_task_1467340078684 Success Query select count(*) from src where ds='20160628';在浏览器中打开Logview的URL地址,在Logview页面的SourceXML页签,获取该实例的SKYNET_NODENAME。
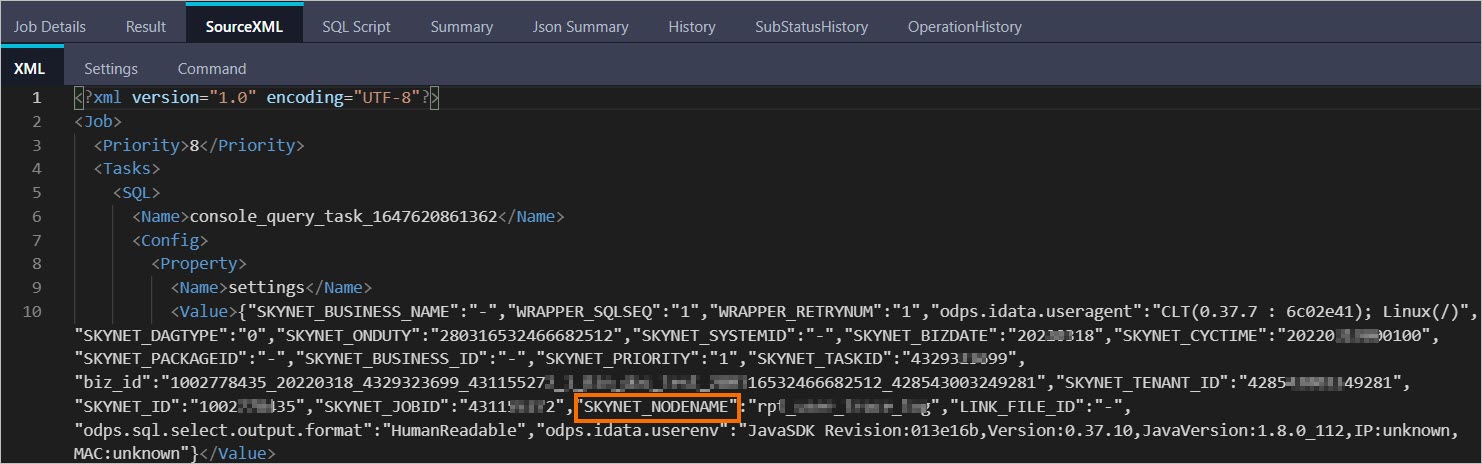 说明
说明关于Logview的介绍,详情请参见使用Logview 2.0查看作业运行信息。
如果获取不到SKYNET_NODENAME或SKYNET_NODENAME无值,您可以在SQL Script页签获取代码片段后,在DataWorks上通过搜索代码片段,获取目标节点进行优化。详情请参见DataWorks代码搜索。
在DataWorks中,搜索查询到的SKYNET_NODENAME,对目标节点进行优化。
分析作业增长趋势
通常费用的增长是由于重复执行或调度属性配置不合理造成作业量暴涨导致。
通过Excel分析:分析用量明细中数据分类为ComputationSql的数据。统计各项目每天的作业数量,观察是否存在某些项目作业数量波动较大。
通过SQL分析(已完成步骤二的数据导入,生成maxcomputefee表):
--分析作业增长趋势。 SELECT TO_CHAR(endtime,'yyyymmdd') AS ds ,projectid ,COUNT(*) AS tasknum FROM maxcomputefee WHERE TYPE = 'ComputationSql' AND TO_CHAR(endtime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(endtime,'yyyymmdd') ,projectid ORDER BY tasknum DESC LIMIT 10000 ;执行结果如下。
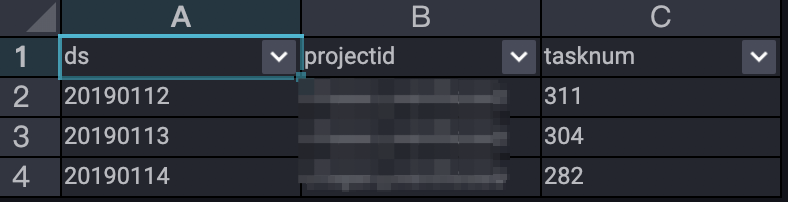 从执行结果可以看出12~14日提交到MaxCompute且执行成功的作业数的波动趋势。
从执行结果可以看出12~14日提交到MaxCompute且执行成功的作业数的波动趋势。
分析存储费用
通过Excel分析存储收取1分钱的原因:
开通MaxCompute进行试用,当前没有业务在MaxCompute上运行,但是每天都有1分钱账单,此问题一般是因为有存留数据在MaxCompute上存储,且数据量不超过0.5 GB。
查看数据分类中的Storage存储计费项,发现
maxcompute_doc项目下存储了508 Byte数据,如下图所示。按照存储费用计费规则,小于等于512 MB数据收取1分钱。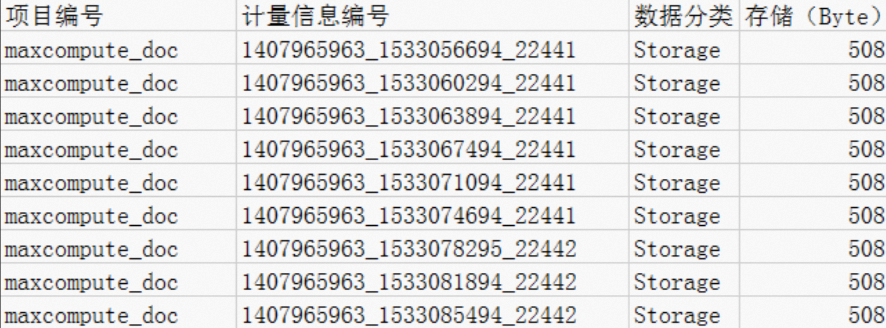 如果这份数据只用于测试,您可以通过以下方式解决此问题。
如果这份数据只用于测试,您可以通过以下方式解决此问题。仅表数据不再使用,请执行
Drop Table语句删除Project下的表数据。Project不再使用,请通过MaxCompute控制台的项目管理删除项目。
通过Excel分析
不足一天的数据存储费用:查看数据分类中的Storage存储计费项,会发现在alian项目下存储了333507833900字节数据,由于是8点上传的数据,所以从09:07开始计量存储费用,一共计量15小时。
说明天计量范围以当天的结束时间为准,所以最后一条数据不包括在4月4日账单中。
按照存储费用计费规则先计算24小时存储平均值,再根据计费公式进行计算。
--计算存储平均值。 333507833900 Byte×15/1024/1024/1024/24=194.127109076362103 GB --一天的存储费用计算如下,结果保留4位小数。 194.127109076362103GB×0.0006 USD/GB/天=0.1165 USD/天
通过SQL分析存储费用的分布(已完成步骤二的数据导入,生成maxcomputefee表):
--分析存储费用。 SELECT t.ds ,t.projectid ,t.storage ,CASE WHEN t.storage < 0.5 THEN t.storage*0.01 ---当项目的实际数据存储量大于0 MB小于等于512MB时,计费单价为0.01元/GB/天 WHEN t.storage >= 0.5 THEN t.storage*0.004 ---当项目的实际数据存储量大于512MB时,计费单价为0.004元/GB/天 END storage_fee FROM ( SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(storage/1024/1024/1024)/24 AS storage FROM maxcomputefee WHERE TYPE = 'Storage' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid ) t ORDER BY storage_fee DESC ;执行结果如下。
 根据执行结果可以分析得出如下结论:
根据执行结果可以分析得出如下结论:存储在12日有一个增长的过程,但在14日出现降低。
存储优化,建议为表设置生命周期,删除长期不使用的临时表等。
通过SQL分析长期存储、低频存储、长期存储访问和低频存储访问的分布。(已完成步骤二的数据导入,生成maxcomputefee表):
--分析长期存储费用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(storage/1024/1024/1024)/24*0.0011 AS longTerm_storage FROM maxcomputefee WHERE TYPE = 'ColdStorage' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid; --分析低频存储费用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(storage/1024/1024/1024)/24*0.0011 AS lowFre_storage FROM maxcomputefee WHERE TYPE = 'LowFreqStorage' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid; --分析长期存储访问费用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(computationsqlinput/1024/1024/1024)*0.522 AS longTerm_IO FROM maxcomputefee WHERE TYPE = 'SqlLongterm' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid; --分析低频存储访问费用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(computationsqlinput/1024/1024/1024)*0.522 AS lowFre_IO FROM maxcomputefee WHERE TYPE = 'SqlLowFrequency' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid;
分析下载费用
对于外网或者跨区域的数据下载,MaxCompute将按照下载的数据量进行计费。
一次下载费用=下载数据量×单价(0.1166USD/GB)
通过Excel分析:数据分类为DownloadEx代表公网下载计费项。
公网下行流量产生了一条约0.036 GB(38199736 Byte)的下行流量,根据下载费用(按量付费)标准,产生费用为
(38,199,736 bytes/1024/1024/1024) × 0.1166 USD/GB = 0.004 USD。下载优化举例。查看您的Tunnel设置的Service,是否因为设置了公共网络产生费用,更多信息请参见Endpoint。如果是大批量下载,您本地在苏州,Region在华东2(上海),则可以先通过华东2(上海)的ECS把数据下载到虚拟机,然后利用ECS包月下载资源。
通过SQL分析下载费用的分布(已完成步骤二的数据导入,生成maxcomputefee表):
--分析下载消费明细。 SELECT TO_CHAR(starttime,'yyyymmdd') AS ds ,projectid ,SUM((download/1024/1024/1024)*0.1166) AS download_fee FROM maxcomputefee WHERE type = 'DownloadEx' AND TO_CHAR(starttime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(starttime,'yyyymmdd') ,projectid ORDER BY download_fee DESC ;
分析MapReduce作业消费
MapReduce作业当日计算费用 = 当日总计算时×单价(0.0690 USD/Hour/Task)
通过Excel分析:分析用量明细中数据分类为MapReduce的数据。按照计算资源规格分别对MapReduce作业费用进行计算及排序。MapReduce作业费用计算公式为
(MR/Spark作业计算(Core*Second)/3600 × 单价(0.0690))。通过SQL分析(已完成步骤二的数据导入,生成maxcomputefee表):
--分析MapReduce作业消费。 SELECT TO_CHAR(starttime,'yyyymmdd') AS ds ,projectid ,(cu_usage/3600)*0.0690 AS mr_fee FROM maxcomputefee WHERE type = 'MapReduce' AND TO_CHAR(starttime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(starttime,'yyyymmdd') ,projectid ,cu_usage ORDER BY mr_fee DESC ;
分析外部表作业(OTS和OSS)
一次SQL外部表计算费用 = 计算输入数据量×单价(0.0044 USD/GB)
通过Excel分析:分析用量明细中数据分类为ComputationSqlOTS、ComputationSqlOSS的数据。对SQL外部表计算费用进行排序,费用计算公式为
SQL/交互式分析读取量(Byte)/1024/1024/1024 × 单价 ( 0.0044)。通过SQL分析(已完成步骤二的数据导入,生成maxcomputefee表):
--分析OTS外部表SQL作业消费。 SELECT TO_CHAR(starttime,'yyyymmdd') AS ds ,projectid ,(computationsqlinput/1024/1024/1024)*1*0.03 AS ots_fee FROM maxcomputefee WHERE type = 'ComputationSqlOTS' AND TO_CHAR(starttime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(starttime,'yyyymmdd') ,projectid ,computationsqlinput ORDER BY ots_fee DESC ; --分析OSS外部表SQL作业消费。 SELECT TO_CHAR(starttime,'yyyymmdd') AS ds ,projectid ,(computationsqlinput/1024/1024/1024)*1*0.03 AS oss_fee FROM maxcomputefee WHERE type = 'ComputationSqlOSS' AND TO_CHAR(starttime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(starttime,'yyyymmdd') ,projectid ,computationsqlinput ORDER BY oss_fee DESC ;
分析Spark计算费用
Spark作业当日计算费用 = 当日总计算时×单价(0.1041 USD/Hour/Task)
通过Excel分析:分用量明细中数据分类为spark的数据。对作业费用进行排序,计算公式为
(MR/Spark作业计算(Core*Second)/3600 × 单价(0.1041))。通过SQL分析(已完成步骤二的数据导入,生成maxcomputefee表):
--分析Spark作业消费。 SELECT TO_CHAR(starttime,'yyyymmdd') AS ds ,projectid ,(cu_usage/3600)*0.1041 AS mr_fee FROM maxcomputefee WHERE type = 'spark' AND TO_CHAR(starttime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(starttime,'yyyymmdd') ,projectid ,cu_usage ORDER BY mr_fee DESC ;
相关文档
TO_CHAR函数分为字符串类型和日期类型两种,关于TO_CHAR函数的详情,请参见TO_CHAR。