当SQL查询性能不佳或查询结果不符合预期时,Hologres提供了EXPLAIN和EXPLAIN ANALYZE命令用于分析查询语句执行计划,可以帮助您了解Hologres如何执行查询语句,以便您对查询语句或数据库结构进行调整优化。本文介绍在Hologres中通过EXPLAIN和EXPLAIN ANALYZE查看执行计划及每个算子的含义。
执行计划简介
在Hologres中,优化器(Query Optimizer,QO)会为每一条SQL生成一个执行计划,执行引擎(Query Engine,QE)会根据该执行计划生成最终的执行计划,然后执行并获取SQL结果。执行计划中会反映出SQL的统计信息、执行算子、算子耗时等信息,一个好的执行计划,能够用最少的资源更快的返回结果。因此对于日常开发来说,执行计划至关重要,它可以反应出SQL的问题,从而去针对性优化。
Hologres兼容Postgres,可以根据EXPLAIN和EXPLAIN ANALYZE语法了解SQL的执行计划。
-
EXPLAIN:代表优化器QO根据SQL特征预估的SQL执行计划,并非实际的执行计划,对SQL的运行有一定参考意义。
-
EXPLAIN ANALYZE:代表SQL真实的运行计划,相比EXPLAIN会包含更多的实际运行信息,能准确的反映出SQL的执行算子和算子耗时,可以根据算子耗时去做针对性的SQL优化。
从Hologres V1.3.4x版本开始,支持通过EXPLAIN和EXPLAIN ANALYZE查看更加清晰且阅读性更高的执行计划,本文档基于V1.3.4x版本撰写,建议将实例升级至V1.3.4x及以上版本。
EXPLAIN
-
语法格式
EXPLAIN可以反映出优化器的预估执行计划,语法如下:EXPLAIN <sql>; -
使用示例
以TPC-H中的SQL为例。
说明该示例引用TPC-H的SQL,但是不代表TPC-H的测试结果。
EXPLAIN SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
返回结果
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus -> Gather (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7794.27 rows=3 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) -> Decode (cost=0.00..7791.80 rows=44412 width=76) -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus -> Project (cost=0.00..3550.73 rows=584421302 width=33) -> Project (cost=0.00..2585.43 rows=584421302 width=33) -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) -
结果解释
执行计划需要从下往上看,每个箭头(->)代表一个节点,每个子节点会返回使用的算子,以及预估的行数等。需要关注的算子包括:
参数
描述
cost
算子的预估耗时,父节点的cost也包含子节点的cost。包含预估启动cost和预估总cost,中间使用
..分割。-
预估启动cost:输出阶段开始之前的cost。
-
预估总cost:是假设算子运行完成的总cost。
例如上述返回结果中的Final HashAggregate节点,预估启动cost是
0.00,总cost是7793.27。rows
算子的预估输出行数,主要基于统计信息进行估算。
对于上述返回结果中Scan的预估值,默认值为
1000。说明通常情况下如果出现
rows=1000则说明表的统计信息不正确,没有根据统计信息进行估算,可以通过执行analyze <tablename>命令对表进行统计信息更新。width
算子的预估输出平均宽度(单位:字节),值越大说明列越宽。
-
EXPLAIN ANALYZE
-
语法格式
EXPLAIN ANALYZE可以反应出SQL的实际执行计划,以及对应的算子耗时,从而帮助诊断SQL性能。语法如下:EXPLAIN ANALYZE <sql>; -
使用示例
以TPC-H中的SQL为例。
EXPLAIN ANALYZE SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
返回结果
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus [id=21 dop=1 time=2427/2427/2427ms rows=4(4/4/4) mem=3/3/3KB open=2427/2427/2427ms get_next=0/0/0ms] -> Gather (cost=0.00..7795.27 rows=3 width=80) [20:1 id=100003 dop=1 time=2426/2426/2426ms rows=4(4/4/4) mem=1/1/1KB open=0/0/0ms get_next=2426/2426/2426ms] -> Project (cost=0.00..7795.27 rows=3 width=80) [id=19 dop=20 time=2427/2426/2425ms rows=4(1/0/0) mem=87/87/87KB open=2427/2425/2425ms get_next=1/0/0ms] -> Project (cost=0.00..7794.27 rows=0 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus [id=16 dop=20 time=2427/2425/2424ms rows=4(1/0/0) mem=574/570/569KB open=2427/2425/2424ms get_next=1/0/0ms] -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus [20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus [id=12 dop=20 time=2428/2357/2256ms rows=80(4/4/4) mem=574/574/574KB open=2428/2357/2256ms get_next=1/0/0ms] -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) [id=11 dop=20 time=2427/2356/2255ms rows=936(52/46/44) mem=7/6/6KB open=0/0/0ms get_next=2427/2356/2255ms pull_dop=9/9/9] -> Decode (cost=0.00..7791.80 rows=44412 width=76) [id=8 dop=234 time=2435/1484/5ms rows=936(4/4/4) mem=0/0/0B open=2435/1484/5ms get_next=4/0/0ms] -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus [id=5 dop=234 time=2435/1484/3ms rows=936(4/4/4) mem=313/312/168KB open=2435/1484/3ms get_next=0/0/0ms] -> Project (cost=0.00..3550.73 rows=584421302 width=33) [id=4 dop=234 time=2145/1281/2ms rows=585075720(4222846/2500323/3500) mem=142/141/69KB open=10/1/0ms get_next=2145/1280/2ms] -> Project (cost=0.00..2585.43 rows=584421302 width=33) [id=3 dop=234 time=582/322/2ms rows=585075720(4222846/2500323/3500) mem=142/142/69KB open=10/1/0ms get_next=582/320/2ms] -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) [id=2 dop=234 time=259/125/1ms rows=585075720(4222846/2500323/3500) mem=1418/886/81KB open=10/1/0ms get_next=253/124/0ms] ADVICE: [node id : 1000xxx] distribution key miss match! table lineitem defined distribution keys : l_orderkey; request distribution columns : l_returnflag, l_linestatus; shuffle data skew in different shards! max rows is 20, min rows is 0 Query id:[300200511xxxx] ======================cost====================== Total cost:[2505] ms Optimizer cost:[47] ms Init gangs cost:[4] ms Build gang desc table cost:[2] ms Start query cost:[18] ms - Wait schema cost:[0] ms - Lock query cost:[0] ms - Create dataset reader cost:[0] ms - Create split reader cost:[0] ms Get the first block cost:[2434] ms Get result cost:[2434] ms ====================resource==================== Memory: 921(244/230/217) MB, straggler worker id: 72969760xxx CPU time: 149772(38159/37443/36736) ms, straggler worker id: 72969760xxx Physical read bytes: 3345(839/836/834) MB, straggler worker id: 72969760xxx Read bytes: 41787(10451/10446/10444) MB, straggler worker id: 72969760xxx DAG instance count: 41(11/10/10), straggler worker id: 72969760xxx Fragment instance count: 275(70/68/67), straggler worker id: 72969760xxx -
结果解释
EXPLAIN ANALYZE的执行结果反映的是真实执行路径,其结果是一个由多个算子组成的树状结构,会反映出每个阶段每个算子的详细执行信息。EXPLAIN ANALYZE的结果主要包括Query Plan、Advice、Cost耗时、Resource资源消耗情况。
QUERY PLAN
在QUERY PLAN中,会反映每个算子的详细执行信息。同EXPLAIN一样,EXPLAIN ANALYZE中的Query Plan需要从下往上看,每个箭头(->)代表一个节点。
|
示例 |
说明 |
|
(cost=0.00..2585.43 rows=584421302 width=33) |
都代表优化器的预估值,非真实值,同Explain含义一致。
|
|
[20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] |
代表实际执行的消耗值,即真实数据。
|
由于一条SQL语句可能涉及到多个算子,下面将会有单独章节对算子进行详细介绍,请参见算子含义。
对于time、row、mem这类数值:
-
当前算子的time值是下方算子耗时的累加,所以当前算子的耗时需要用当前算子的time值减去下方算子的耗时。
-
对于row、mem则是每个算子的独立计算,不是累加值。
ADVICE
ADVICE中主要系统根据当前EXPLAIN ANALYZE的执行结果,自动生成的调优建议如下:
-
建议为表设置distribution key,clustering key,bitmap等,如
Table xxx misses bitmap index。 -
表缺少统计信息:
Table xxx Miss Stats! please run 'analyze xxx';。 -
数据可能存在倾斜:
shuffle data xxx in different shards! max rows is 20, min rows is 0。
Advice的结果只是根据当前SQL的Explain Analyze结果给出的建议,不一定完全适用,需要根据业务具体分析,并合理采取相应的操作。
Cost耗时
Cost代表Query的总耗时以及在每个阶段运行的详细耗时,可以通过每个阶段的耗时初步判断性能瓶颈。
Total cost:代表Query执行的总耗时,单位毫秒(ms),其中:
-
Optimizer cost:代表优化器(QO)生成执行计划的耗时,单位毫秒(ms)。
-
Build gang desc table cost:将查询优化器生成的执行计划,转换为执行引擎所需的数据结构所花费的时间,单位毫秒(ms)。
-
Init gangs cost:将QO生成的执行计划进一步预处理,并将请求发送给执行引擎,从而开始Start Query阶段的耗时,单位毫秒(ms)。
-
Start query cost:从Init gangs步骤执行完成时开始计算,真正开始执行Query前的初始化阶段,包括了加锁,对齐Schema版本等过程,主要有以下几个节点:
-
Wait schema cost:存储引擎(Storage Engine,SE)和Frontend(FE)对齐Schema版本所耗时间。当表的Schema发生变化时,FE会更新节点版本,同理SE也会更新节点版本,如果FE和SE的版本不对齐,则会出现Schema延迟。如果延迟较高,一般原因是因为SE处理慢,尤其是分区父表的DDL较多时,延迟较高,导致数据写入/查询慢,建议针对性优化DDL频率。
-
Lock query cost:Query加锁所耗时间,如果耗时较高,则说明Query在等锁。
-
Create dataset reader cost:创建索引数据读取器的耗时,耗时较高有可能是未命中Cache。
-
Create split reader cost:打开文件消耗的时间,耗时高则说明文件meta没有命中缓存,IO开销较高。
-
-
Get result cost:从Start Query阶段结束开始计算,到所有结果均返回所花费的时间。Get result cost包含Get the first block cost,单位毫秒(ms)。
-
Get the first block cost:从Start Query阶段结束开始计算,到返回第一批数据(即第一个record batch)为止的时间。某些场景下该指标会与比Get result cost指标非常接近或者一致。例如当查询计划的顶部是Hash Agg算子,建立Hash Table做聚合运算需要依赖下游算子的全量数据。而对于普通带过滤条件的查询,数据流式进行计算和返回,此场景下,该指标通常会与Get result cost数值有较大的差距(取决于数据量)。
-
Resource资源消耗情况
Resource代表Query运行的资源消耗,格式为:total(max/avg/min),包含总的资源累加和消耗资源的最大值、平均值和最小值。
因为Hologres是分布式引擎,一个实例有多个Worker节点,每个Worker节点计算完成会进行结果合并,并最终返回给客户端。因此在资源消耗中,会使用total(max worker/avg worker/min worker)的格式来反应整体消耗,其中:
-
total:代表Query的总消耗。
-
max:代表单个Worker节点消耗的最大值。
-
avg:代表平均Worker节点的消耗(avg=total/worker节点数)。
-
min:代表单个Worker节点消耗的最小值。
以下为各资源消耗指标的详细解释:
|
指标 |
描述 |
|
Memory |
Query运行过程中所消耗的内存,包括消耗总内存、以及Worker节点消耗的最大内存、平均内存和最小内存。 |
|
CPU time |
Query运行时消耗的总CPU时间(单位毫秒,非精确值)。 体现所有计算任务所耗费的CPU时间,是多个CPU Core计算时间的累加,粗略地体现复杂度。 |
|
Physical read bytes |
从磁盘上读取的数据量,单位Bytes,当Query没有命中缓存Cache时,则需要去磁盘读取数据。 |
|
Read bytes |
Query读取的总字节大小,单位Bytes,包括物理读(Physical Read)和从内存Cache中读取的数据大小。反映Query执行获取的数据量的大小。 |
|
Affected rows |
DML影响的行数,只有DML才会展示该指标。 |
|
Dag instance count |
查询计划DAG instance数量,数值越大表示查询越复杂,并行度越高。 |
|
Fragment instance count |
查询计划Fragment instance数量,数值越大表示计划越多,文件数越多。 |
|
straggler_worker_id |
表示该资源指标消耗最大的Worker节点的id。 |
算子含义
SCAN
-
seq scan
Seq Scan表示顺序地从表中读取数据,会进行全表扫描。
on后对应的是所扫描的表名。示例:对一张普通内表查询,在执行计划中会有Seq scan。
EXPLAIN SELECT * FROM public.holo_lineitem_100g;返回结果:
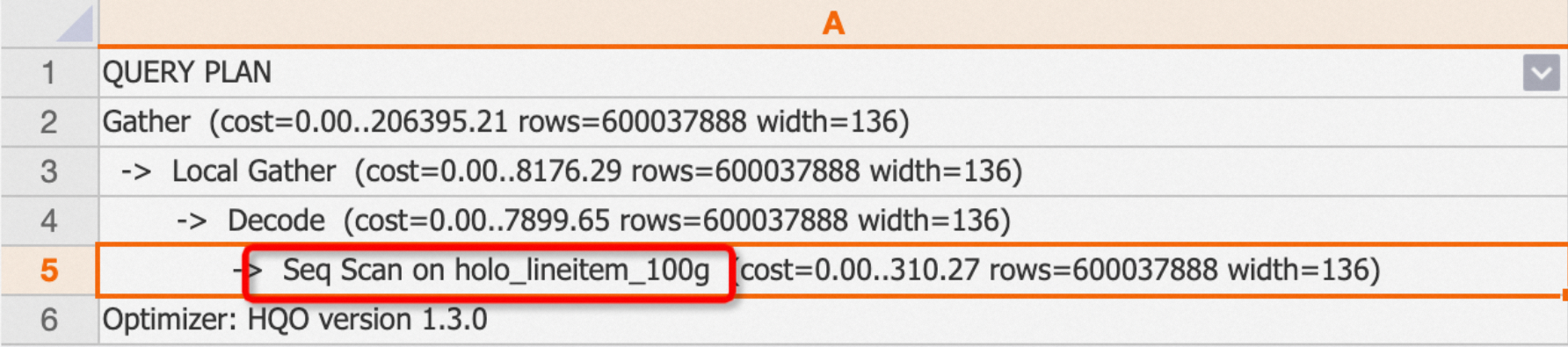
-
查询分区表
如果是分区表,执行计划中则是
Seq Scan on Partitioned Table,且会通过Partitions selected: x out of y来展示SQL中扫描了多少分区。示例:查询一个分区父表,且只扫描了一个分区。
EXPLAIN SELECT * FROM public.hologres_parent;返回结果:

-
查询外部表
如果查询的是外部表,执行计划中则会有
Foreign Table Type区分外部表的来源。type分类包括:MaxCompute、OSS、Hologres。示例:查询MaxCompute外部表。
EXPLAIN SELECT * FROM public.odps_lineitem_100;返回结果:
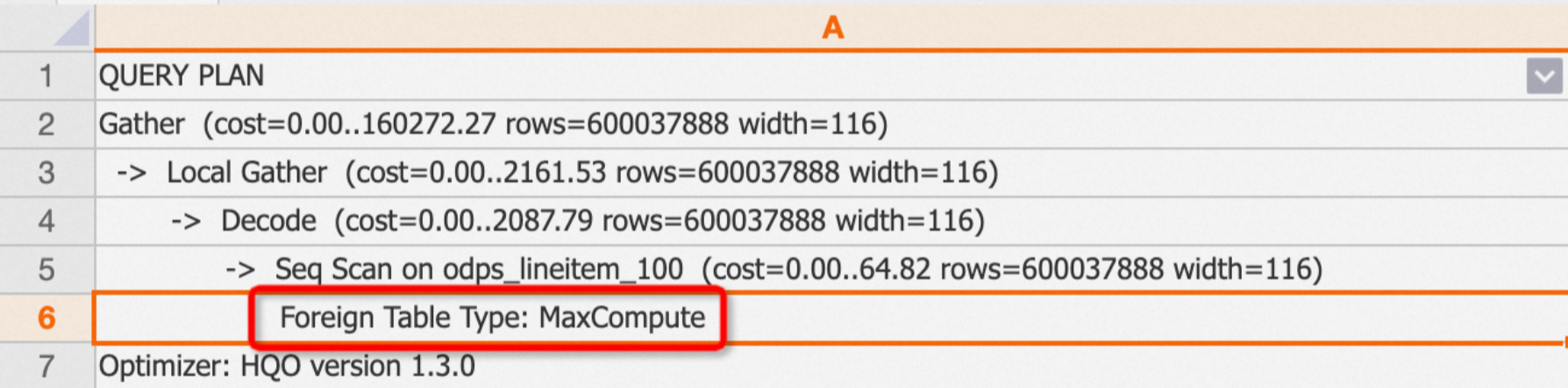
-
-
Index Scan和 Index Seek
如果扫描表有命中索引,根据表的存储格式(行存或列存)不同,Hologres在底层使用的索引也不同,根据索引扫描时主要有Clustering_index和Index Seek(又名pk_index)两种索引。其中:
-
Clustering_index:表示使用了列存表的索引(例如segment 、clustering等),只要查询命中索引就会使用Clustering_index。
Seq Scan Using Clustering_index通常会跟Filter一起出现,Filter是子节点,会列出命中的索引,包括clustering filter、segment filter、bitmap filter等,详情请参见列存表原理。-
示例1:查询命中索引。
BEGIN; CREATE TABLE column_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('column_test', 'orientation', 'column'); CALL set_table_property('column_test', 'distribution_key', 'id'); CALL set_table_property('column_test', 'clustering_key', 'id'); COMMIT; INSERT INTO column_test VALUES(1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM column_test WHERE id>2;返回结果:
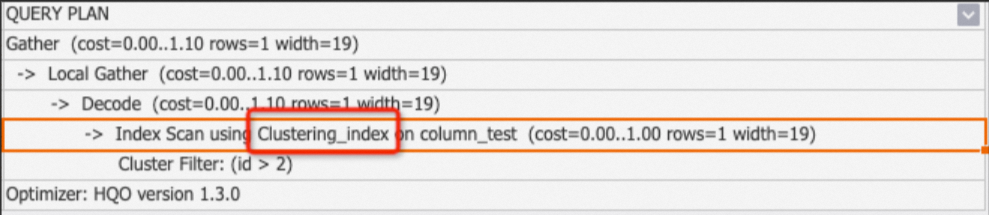
-
示例2:假如查询没有命中索引,则不会使用clustering_index。
EXPLAIN SELECT * FROM column_test WHERE age>10;返回结果:

-
-
Index Seek(又名pk_index):表示使用了行存表的索引,主要是主键索引。一般情况下,基于主键的行存表点查是走Fixed Plan,但是未走Fixed Plan的行存表且带有主键的查询就会走pk_index,更多原理请参见行存表原理。
示例:查询行存表。
BEGIN; CREATE TABLE row_test_1 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_1', 'orientation', 'row'); CALL set_table_property('row_test_1', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_1 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); BEGIN; CREATE TABLE row_test_2 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_2', 'orientation', 'row'); CALL set_table_property('row_test_2', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_2 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); --pk_index EXPLAIN SELECT * FROM (SELECT id FROM row_test_1 WHERE id = 1) t1 JOIN row_test_2 t2 ON t1.id = t2.id;返回结果:

-
Filter
Filter代表将数据根据SQL条件进行过滤,一般会跟随seq scan on table一起,是seq scan的子节点,表示扫描表时是否有过滤,以及过滤条件是否命中索引。主要包括以下几种Filter:
-
Filter
如果执行计划中,仅包含Filter,则说明过滤条件没有命中任何索引。此时需要去检查表索引,重新为SQL设置合理的索引,从而提升查询性能。
说明如果执行计划中存在
One-Time Filter: false,说明输出结果为空集。示例:
BEGIN; CREATE TABLE clustering_index_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('clustering_index_test', 'orientation', 'column'); CALL set_table_property('clustering_index_test', 'distribution_key', 'id'); CALL set_table_property('clustering_index_test', 'clustering_key', 'age'); COMMIT; INSERT INTO clustering_index_test VALUES (1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM clustering_index_test WHERE id>2;返回结果:
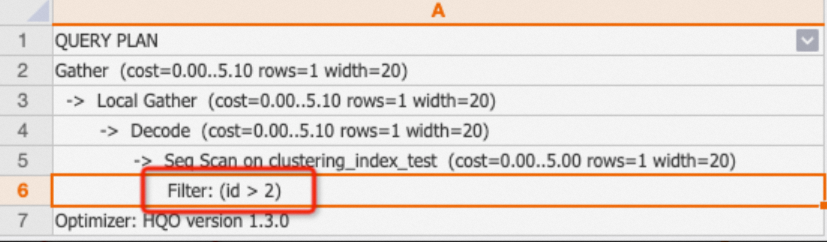
-
Segment Filter
Segment Filter表示查询时命中了segment索引,与index_scan一起出现,详情请参见Event Time Column(Segment Key)。
-
Cluster Filter
Cluster Filter表示查询时命中了clustering索引,详情请参见聚簇索引Clustering Key。
-
Bitmap Filter
Bitmap Filter表示查询时命中了Bitmap索引,详情请参见位图索引Bitmap。
-
Join Filter
join完后还需要对数据做一遍filter。
Decode
Decode表示对数据进行解码或者编码,以加速text等文本类数据的计算。
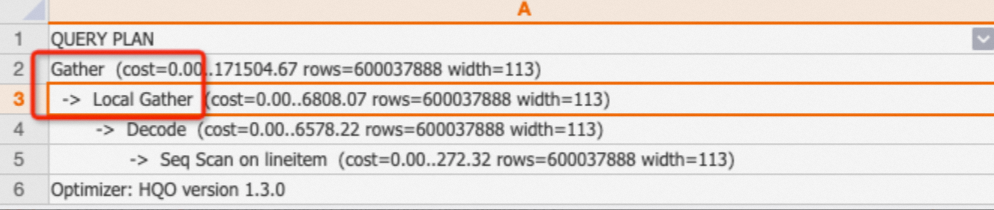
Local Gather和Gather
在Hologres中,数据会在shard内按照文件的形式存储。Local Gather代表数据从多个文件合并到一个shard上。Gather则代表将多个shard的数据合并汇总成最终结果。
示例:
EXPLAIN SELECT * FROM public.lineitem;返回结果:其执行计划如下,代表数据被扫描出来后,会先通过Local Gather在shard级汇总,然后通过Gather合并成最终数据。
Redistribution
Redistribution表示数据通过哈希分布或者随机分布,查询时shuffle到一个或者多个shard。
-
Redistribution算子常见的场景:
-
通常出现在join、count distinct(本质上也是join)以及group by的场景中,表的distribution key没有设置,或者设置不合理,导致查询时数据在多个shard间shuffle。尤其是在多表join的场景,如果出现redistribution,则说明没有利用local join的能力,导致查询性能不佳。
-
当对应的key(如join key、group by key)涉及到表达式时,例如对字段cast类型改变了原来的字段类型等,则无法利用上local join的能力,会出现redistribution。
-
-
示例:
-
示例1:两表join,distribution key设置不合理导致出现redistribution。
BEGIN; CREATE TABLE tbl1( a int not null, b text not null ); CALL set_table_property('tbl1', 'distribution_key', 'a'); CREATE TABLE tbl2( c int not null, d text not null ); CALL set_table_property('tbl2', 'distribution_key', 'd'); COMMIT; EXPLAIN SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a=tbl2.c;返回结果:执行计划如下,出现redistribution,说明distribution key设置不合理(SQL中join条件是
tbl1.a=tbl2.c,而两个表的distribution key分别为a和d,join时数据就会shuffle)。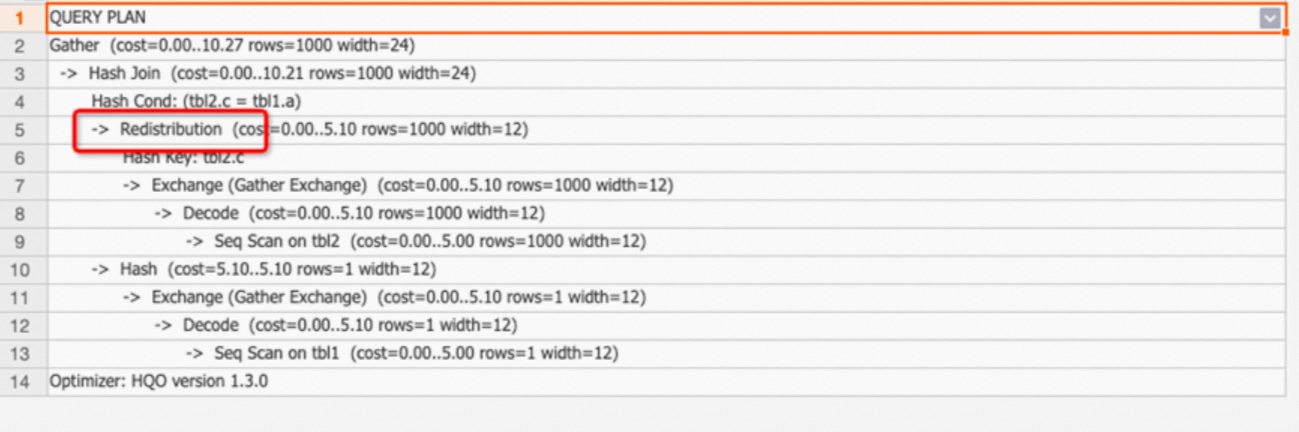
调优建议:如果出现redistribution算子,建议关注表的distribution key设置是否合理。更多关于redistribution的场景和distribution key的设置请参见分布键Distribution Key。
-
示例2:如下执行计划中,join key涉及到表达式,改变了原字段的类型,无法使用local join的能力,出现redistribution。

调优建议:尽量不使用表达式。
-
Join
与标准数据库的定义一致,多表关联(Join)根据SQL的书写方式又分为hash join、nested loop和merge join。
-
Hash Join
hash join是指两个表或者多表join时,基于其中一个表(一般为小表)在内存中构建一个hash表,并把join的列值进行hash计算后放进hash表中,之后逐行的读取另外的表,计算出其hash值并在hash表中查找,最终返回匹配的数据。根据hash join的细分类,还可以继续划分,如下表:
分类
描述
Hash Left Join
多表关联时,根据join条件从左表中返回所有满足条件的行,然后匹配右表,如果没有匹配到数据,则返回null。
Hash Right Join
多表关联时,返回右表的全部行和左边满足join条件的行,如果右表的行在左表中没有匹配数据,那么左表则返回null。
Hash Inner Join
多表关联时,只返回满足join条件的行。
Hash Full Join
多表关联时,从左表和右表返回所有的行,如果其中一个表的数据在另外一个表中没有匹配,则无法匹配的表返回null。
Hash Anti Join
仅返回未匹配到的数据,多用于not exists查询条件。
Hash Semi Join
有任意匹配则返回一项,通常是由exists查询,结果不会产生重复项。
当查看hash join相关的执行计划时,还需要关注其子节点:
-
hash cond:代表join的关联条件,如
hash cond(tmp.a=tmp1.b)。 -
hash key:一般出现在group by场景中,表示将group by的key在多个shard上进行hash计算。
当出现hash join时,我们需要额外关注join表中的小表(数据量较小的表)是否是做了hash表,可以通过如下几种方式查看:
-
执行计划中,有hash字样的表是hash表。
-
执行计划中,从下往上看,最下面的表则是hash表。
调优建议:
-
更新统计信息
hash join的核心调优思路就是尽可能的将小表作为hash表,如果是大表作为hash表,因为要在内存中构建hash表,那么就会消耗较多的资源,大多数情况都是因为表的统计信息没有更新导致优化器QO将大表作为了hash表。
示例:因为统计信息未更新(rows=1000),两表join时大表hash_join_test_2作为hash表(tbl2数据量有100万,tbl1数据量只有1万),导致查询效率较低。
BEGIN ; CREATE TABLE public.hash_join_test_1 ( a integer not null, b text not null ); CALL set_table_property('public.hash_join_test_1', 'distribution_key', 'a'); CREATE TABLE public.hash_join_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.hash_join_test_2', 'distribution_key', 'c'); COMMIT ; INSERT INTO hash_join_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO hash_join_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM hash_join_test_1 tbl1 JOIN hash_join_test_2 tbl2 ON tbl1.a=tbl2.c;执行计划中大表hash_join_test_2作为hash表,如下:

如果统计信息没有及时更新,可以手动执行
analyze <tablename>更新统计信息。示例如下:ANALYZE hash_join_test_1; ANALYZE hash_join_test_2;更新后的执行计划如下,小表hash_join_test_1变成了hash表,且优化器预估的行数正确。

-
调整join order
通常情况下,更新统计信息能解决大部分的join关联问题。但是当SQL比较复杂且是多表关联时(至少5张表),Hologres优化器(QO)的默认机制会根据SQL选择更加合理的执行计划,导致优化器在选择执行计划上会耗费较多时间。我们可以通过如下GUC控制join order,以降低QO的耗时。
SET optimizer_join_order = '<value>';value参数的取值如下:
value取值
描述
exhaustive(默认)
通过算法进行Join Order转换,会生成最优的执行计划,但多表关联时会导致优化器开销变高。
query
按照SQL的方式生成执行计划,优化器不做任何改变,仅适用于多表关联且表数据量不大(低于亿级)的场景,从而降低QO开销。同时不建议将该参数设置成DB级别,否则会影响其余join的性能。
greedy
通过贪心算法生成Join Order,优化器开销适中。
-
-
Nested Loop Join和Materialize
Nested Loop代表嵌套循环连接,多表关联时,先从一张表中读取数据,成为外层表,再将外层驱动表的每条数据遍历另外的表(即内层表),然后内外层表嵌套循环进行Join,相当于计算笛卡尔积。在执行计划中第一内层表通常有Materialize算子。
优化建议:
-
Nested Loop的原理是内层表被外层表驱动,外层表返回的每一行都要在内层表中检索与之匹配的行,因此返回的结果集不能太大,否则会消耗较多资源,尽量将返回结果较小的表作为外层表。
-
非等值的join通常会生成Nested Loop join,在SQL书写中尽量避免非等值join。
-
Nested Loop join的示例如下:
BEGIN; CREATE TABLE public.nestedloop_test_1 ( a integer not null, b integer not null ); CALL set_table_property('public.nestedloop_test_1', 'distribution_key', 'a'); CREATE TABLE public.nestedloop_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.nestedloop_test_2', 'distribution_key', 'c'); COMMIT; INSERT INTO nestedloop_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO nestedloop_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM nestedloop_test_1 tbl1,nestedloop_test_2 tbl2 WHERE tbl1.a>tbl2.c;从下述执行计划中可以看出存在Materialize和Nested Loop算子,说明该SQL走的是Nested Loop join路径。

-
-
Cross Join
从V3.0版本开始,Cross Join作为Nested Loop Join的一种实现优化,主要用于处理包含小表的非等值Join等场景。与Nested Loop Join每次从外层循环提取一行数据并遍历内层循环所有数据,然后重置内层循环子查询状态的计算流程相比,Cross Join直接将小表数据全部加载到内存中,然后依次与流式读取的大表数据进行Join计算,从而显著提升计算性能。然而,相较于Nested Loop Join,Cross Join会占用更多的内存资源。
您可以查看查询计划,如果出现如下Cross Join算子,表示使用了Cross Join。
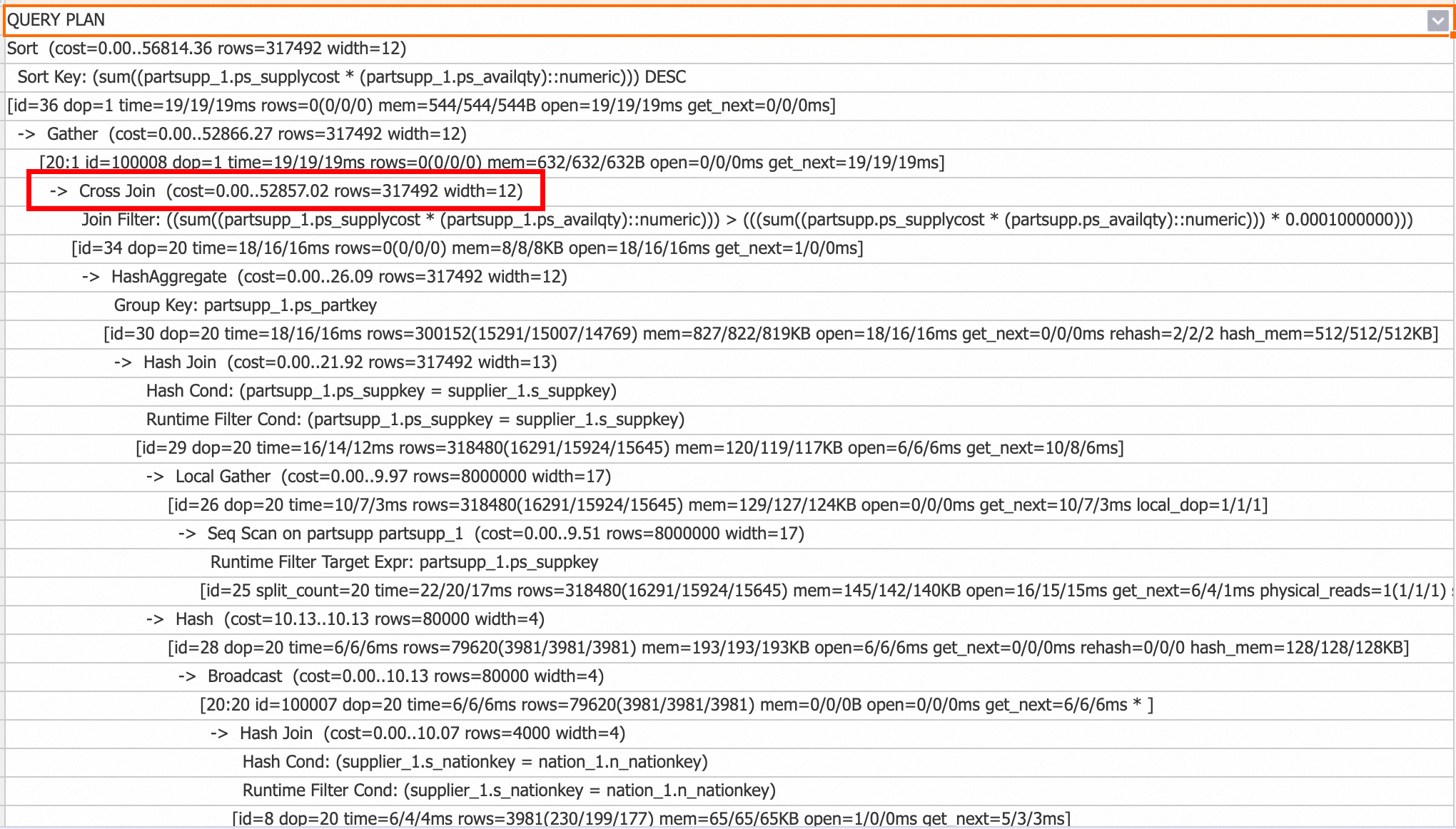
如需禁用Cross Join,可以使用以下SQL语句进行关闭。
-- session级别关闭 SET hg_experimental_enable_cross_join_rewrite = off; -- database级别关闭,新建连接生效 ALTER database <database name> hg_experimental_enable_cross_join_rewrite = off;
Broadcast
Broadcast指通过广播的方式将数据分发到各个shard,通常用在Broadcast Join的场景中,一般是小表join大表。下发SQL时,优化器QO会比较redistribution和Broadcast的代价,然后根据算法生成执行计划。
调优建议:
-
当查询表的数据量较小且实例的shard数比较少时(比如shard count=5)时,走Broadcast比较划算。
示例:两表join,broadcast_test_1和broadcast_test_2的数据量差异比较明显。
BEGIN; CREATE TABLE broadcast_test_1 ( f1 int, f2 int); CALL set_table_property('broadcast_test_1','distribution_key','f2'); CREATE TABLE broadcast_test_2 ( f1 int, f2 int); COMMIT; INSERT INTO broadcast_test_1 SELECT i AS f1, i AS f2 FROM generate_series(1, 30)i; INSERT INTO broadcast_test_2 SELECT i AS f1, i AS f2 FROM generate_series(1, 30000)i; ANALYZE broadcast_test_1; ANALYZE broadcast_test_2; EXPLAIN SELECT * FROM broadcast_test_1 t1, broadcast_test_2 t2 WHERE t1.f1=t2.f1;返回结果:

-
如果不是小表但又生成了Broadcast算子,通常情况是因为统计信息未及时更新导致(比如统计信息中rows=1000,实际扫描100万),需要及时更新统计信息,执行
analyze <tablename>。
Shard prune和Shards selected
-
Shard prune
表示获取Shard的方式,包括:
-
lazaily:根据节点中的Shard ID先标记对应的Shard,在后续计算时选择对应的Shard。
-
eagerly:根据命中的Shard选择对应的Shard,不需要的Shard则不需要选择。
优化器会根据执行计划来自动匹配Shard prume的方式,无需手动调节。
-
-
Shards selected
Shards selected表示选中了多少个Shard,例如1 out of 20表示在20个Shard中选中了一个Shard。
ExecuteExternalSQL
如Hologres的产品架构介绍,Hologres的计算引擎会分为HQE、PQE、SQE等,其中PQE是原生Postgres引擎,部分Hologres自研引擎HQE还没有支持的算子和函数,会通过PQE执行,相比于HQE,PQE的执行效率会更低。当我们在执行计划中看到有ExecuteExternalSQL算子,说明有函数或者算子走了PQE。
-
示例1:走PQE的SQL示例如下。
CREATE TABLE pqe_test(a text); INSERT INTO pqe_test VALUES ('2023-01-28 16:25:19.082698+08'); EXPLAIN SELECT a::timestamp FROM pqe_test;执行计划如下:有ExecuteExternalSQL说明
::timestamp算子走的是PQE。
-
示例2:将
::timestamp改写成to_timestamp,可以走HQE,SQL示例如下。EXPLAIN SELECT to_timestamp(a,'YYYY-MM-DD HH24:MI:SS') FROM pqe_test;执行计划如下,结果中没有ExecuteExternalSQL,表明没有走PQE。

调优建议:通过执行计划找到SQL走了PQE的函数或者算子,并通过改写使其走到HQE,提升查询效率。常见的算子改写列表请参见优化查询性能。
Hologres的每个版本在不断优化PQE的支持,将更多的PQE下推至HQE实现,因此部分函数可以通过升级版本实现自动下推,详情请参见函数功能发布记录。
Aggregate
Aggregate代表将数据聚合,可以是一个聚合函数或者多个聚合函数的组合。根据SQL书写,系统又会将Aggregate分为HashAggregate,GroupAggregate等。其中:
-
GroupAggregate:表示数据已经按照group by进行了预排序。
-
HashAggregate(最常见):表示数据先进行hash计算,然后通过hash值分发至不同的shard进行聚合,最终通过Gather算子聚合。
EXPLAIN SELECT l_orderkey,count(l_linenumber) FROM public.holo_lineitem_100g GROUP BY l_orderkey; -
多阶段HashAggregate:数据是在shard中按照文件存储的,文件有不同的层级,当数据量多时,聚合的阶段也会分为多个阶段。主要的子算子包括:
-
Partial HashAggregate:文件和shard内的聚合。
-
Final HashAggregate:多个shard上的数据聚合在一起。
示例:TPC-H Q6查询,走了多阶段HashAggregate。
EXPLAIN SELECT sum(l_extendedprice * l_discount) AS revenue FROM lineitem WHERE l_shipdate >= date '1996-01-01' AND l_shipdate < date '1996-01-01' + interval '1' year AND l_discount BETWEEN 0.02 - 0.01 AND 0.02 + 0.01 AND l_quantity < 24;返回结果:

调优建议:一般情况下,优化器会根据数据量决定是单阶段HashAggregate还是多阶段HashAggregate,如果Explain Analyze中Aggregate算子的耗时较高,通常情况是数据量较大,但是优化器只让Aggregate只做了shard级别的聚合,没有在文件级别聚合,可以通过如下GUC参数执行多阶段HashAggregate。如果本身SQL已经是多阶段Aggregate了,则不需要去做额外的调整。
SET optimizer_force_multistage_agg = on; -
Sort
sort表示将数据按顺序排序(升序ASC或者降序DESC),通常是order by子句的结果。
示例:对TPC-H lineitem表的l_shipdate列进行排序输出。
EXPLAIN SELECT l_shipdate FROM public.lineitem ORDER BY l_shipdate;返回结果:
调优建议:如果order by的数据量较大,将会消耗较多的资源,需要尽量避免大数据量的排序查询。
Limit
limit表示SQL最终允许返回的数据行数。但需要注意的是,limit仅代表最终返回的行数,并不代表实际计算中扫描的行数,实际扫描的行数要看limit是否下推至Seq Scan节点。如果下推至Seq Scan节点,才是扫描limit N的数据。
示例:如下SQL,有limit 1且下推到了Seq Scan节点,只需要扫描一行数据即可出结果。
EXPLAIN SELECT * FROM public.lineitem limit 1;返回结果: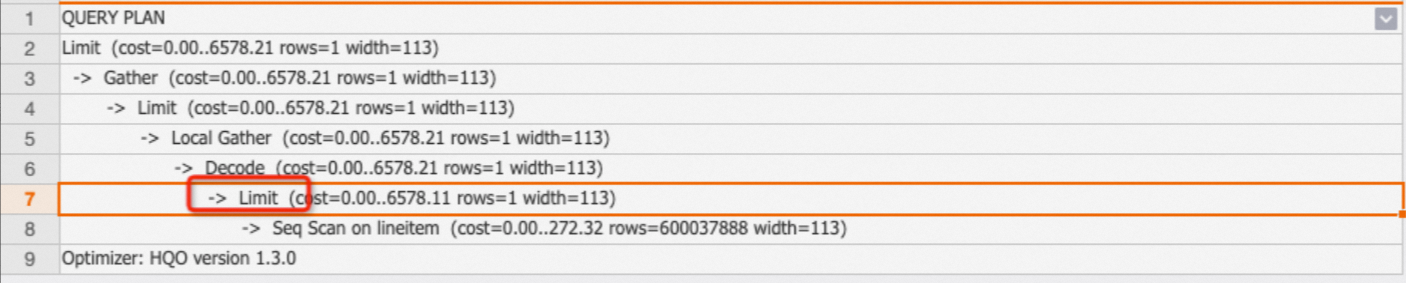
调优建议:
-
并不是所有的Limit都会被下推,所以在SQL查询中,尽量避免全表扫描,尽量多增加过滤条件。
-
尽量避免Limit N时,N为超大值(例如,N为十万或百万)场景,否则即使Limit下推了,也会因为扫描过多的数据量而增加耗时。
Append
子查询的结果合并,通常为Union All操作。
Exchange
Shard内的数据交换。无需过多关注。
Forward
Forward代表将算子的数据在HQE与PQE或者SQE之间传输,一般是HQE+PQE或者HQE+SQE的组合会出现。
Project
Project一般表示子查询与外层查询的映射关系,无需过多关注。
相关文档
HoloWeb可视化查看执行计划,请参见查看执行计划。