本文介绍SQL开发中涉及的重要参数说明和使用示例。
table.exec.sink.keyed-shuffle
为解决向带有主键的表中写入数据时出现的分布式乱序问题,您可以通过table.exec.sink.keyed-shuffle参数来进行Hash Shuffle操作,这将确保相同主键的数据被发送到算子的同一个并发,减少分布式乱序问题。
注意事项
仅在上游算子能够确保更新记录在主键字段上的顺序性时,Hash Shuffle操作才起作用;否则,Hash Shuffle操作不能解决问题。
在作业专家模式时,修改算子并发度,不适用下面的并发度判定规则。
取值说明
AUTO(默认值):表示在Sink的并发度不为1,且Sink的并发度与上游算子不同时,当数据流向Sink时,Flink会自动对主键字段进行Hash Shuffle操作。
FORCE:表示在Sink并发度不为1时,当数据流向Sink时,Flink会强制对主键字段进行Hash Shuffle操作。
NONE:表示Flink不会根据Sink和上游算子的并发度信息进行Hash Shuffle操作。
使用示例
参数值为AUTO
新建SQL流作业,复制如下测试SQL(显式指定Sink并发度为2),部署作业。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print', --您可以通过sink.parallelism参数直接指定Sink并发度。 'sink.parallelism'='2' ); INSERT INTO sink SELECT * FROM s1; --您也可以通过动态表选项的方式指定Sink并发度。 --INSERT INTO sink /*+ OPTIONS('sink.parallelism' = '2') */ SELECT * FROM s1;在作业运维页面的部署详情页签资源配置区域,将并发度设置为1,在运行参数配置区域其他配置中,不设置
table.exec.sink.keyed-shuffle参数或显式添加table.exec.sink.keyed-shuffle: AUTO(两者效果一致)。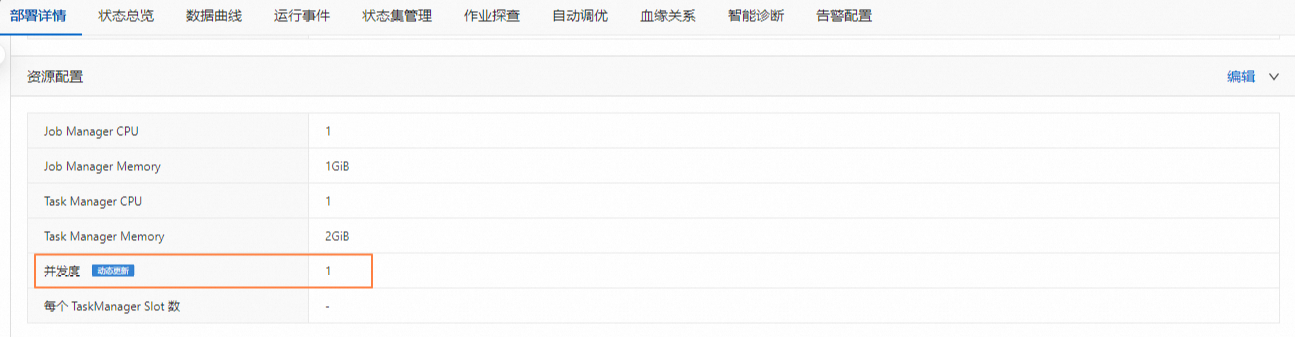
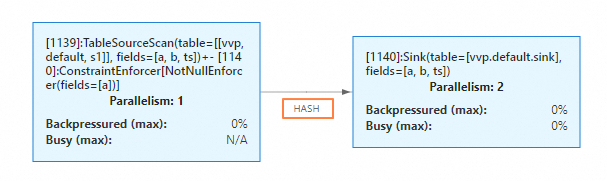
启动作业。在状态总览页签下,您可以看到Sink节点和上游的数据连接方式为HASH。
参数值为FORCE
新建SQL流作业,复制如下测试SQL(不再显式指定Sink并发度),部署作业。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT * FROM s1;在作业运维页面的部署详情页签资源配置区域,将并发度设置为2。在运行参数配置区域其他配置中添加
table.exec.sink.keyed-shuffle: FORCE。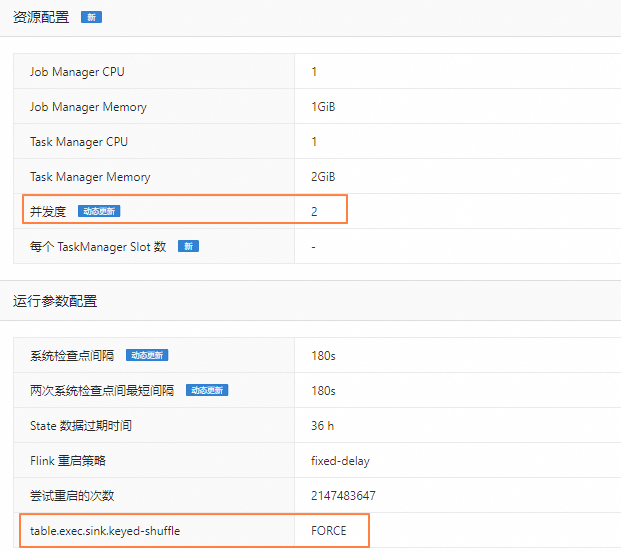
启动作业后,在状态总览页签下,您可以看到Sink节点和上游节点的并发度都为2,并且数据连接方式变成了HASH。
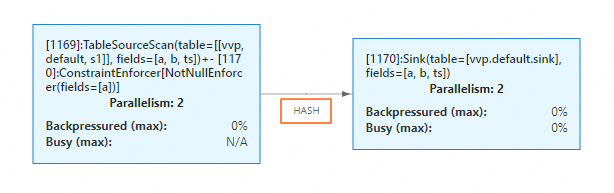
table.exec.mini-batch.size
该参数控制了相关的计算节点进行微批操作所缓存的最大数据条数,达到该值后触发最终的计算和数据输出。该参数只有与table.exec.mini-batch.enabled、table.exec.mini-batch.allow-latency同时使用时才会生效。有关MiniBatch相关的优化请参见MiniBatch Aggregation和MiniBatch 双流Join。
注意事项
在作业启动前,如果未在运行参数配置区域显式设置该参数,在MiniBatch处理模式下,将使用Managed Memory缓存数据,在以下几种条件下都会触发最终计算和数据输出:
收到MiniBatchAssigner节点发送的watermark消息
Managed Memory已满
进行Checkpoint前
作业停止时
取值说明
-1(默认值):表示使用Managed Memory缓存数据。
其他Long类型的负值:同默认设置。
其他Long类型的正值:表示使用Heap Memory来缓存数据。当缓存的数据量达到N条时,会自动触发输出操作。
使用示例
新建SQL流作业,复制如下测试SQL,部署作业。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED, WATERMARK FOR ts AS ts - INTERVAL '1' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random', 'fields.ts.max-past'='5s', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b BIGINT, PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT a, sum(b) FROM s1 GROUP BY a;在作业运维页面的部署详情页运行参数配置区域其他配置中,设置
table.exec.mini-batch.enabled: true和table.exec.mini-batch.allow-latency: 2s参数,不设置table.exec.mini-batch.size(取默认值-1)。启动作业。在状态总览页签下,您可以看到作业包含了MiniBatchAssigner节点、LocalGroupAggregate节点和GlobalGroupAggregate节点。
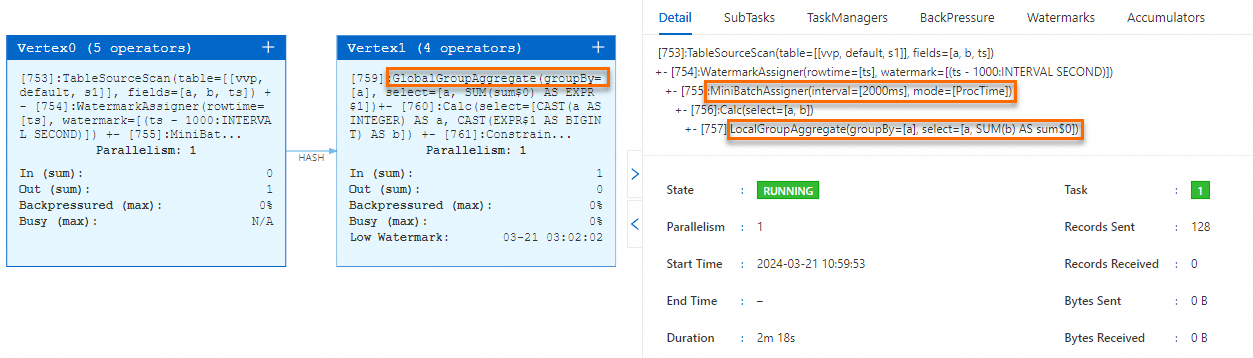
table.exec.agg.mini-batch.output-identical-enabled
在开启State TTL的情况下,MinibatchGlobalAgg节点和MinibatchAgg节点在消费数据后,如果聚合结果未发生变化,默认将不会向下游发送重复的数据,这可能导致下游的有状态节点由于长时间未收到上游发送的数据,自身State过期的问题。该参数控制了开启StateTTL且聚合结果未发生变化的情况下,是否仍然向下游发送重复数据。您可以设置该参数为true,使得MinibatchGlobalAgg和MinibatchAgg两个节点在这种情况下,仍然下发数据。如果您的作业聚合结果变化周期小于State TTL设置时间,则无需手动设置此参数。具体社区Issues详情请参考FLINK-33936。
注意事项
该参数仅在VVR-8.0.8及以上版本生效,在VVR-8.0.8前的版本,其行为等同于取值为false的行为。
当取值从false修改为true时,可能会导致MinibatchGlobalAgg节点和MinibatchAgg节点向下游发送的数据量增加,对下游算子造成压力。
取值说明
false(默认值):表示在开启State TTL的情况下,MinibatchGlobalAgg节点和MinibatchAgg节点在消费数据后,如果聚合结果未发生变化,就不向下游下发数据。
true:表示在开启State TTL的情况下,MinibatchGlobalAgg节点和MinibatchAgg节点在消费数据后,如果聚合结果未发生变化,仍然向下游发送更新的(重复的)数据。
使用示例
新建SQL流作业,复制如下测试SQL,部署作业。
create temporary table src( a int, b string ) with ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.a.min' = '1', 'fields.a.max' = '1', 'fields.b.length' = '3' ); create temporary table snk( a int, max_length_b bigint ) with ( 'connector' = 'blackhole' ); insert into snk select a, max(CHAR_LENGTH(b)) from src group by a;在作业运维页面的部署详情页运行参数配置区域其他配置中,设置
table.exec.mini-batch.enabled: true和table.exec.mini-batch.allow-latency: 2s参数,启用Minibatch Aggregate优化。启动作业。在状态总览页签下,您可以看到作业包含了MinibatchGlobalAggregate节点,点击该节点上的“+”号,可以观察到GlobalGroupAggregate节点在聚合结果不变的情况下,不向下游发送数据。
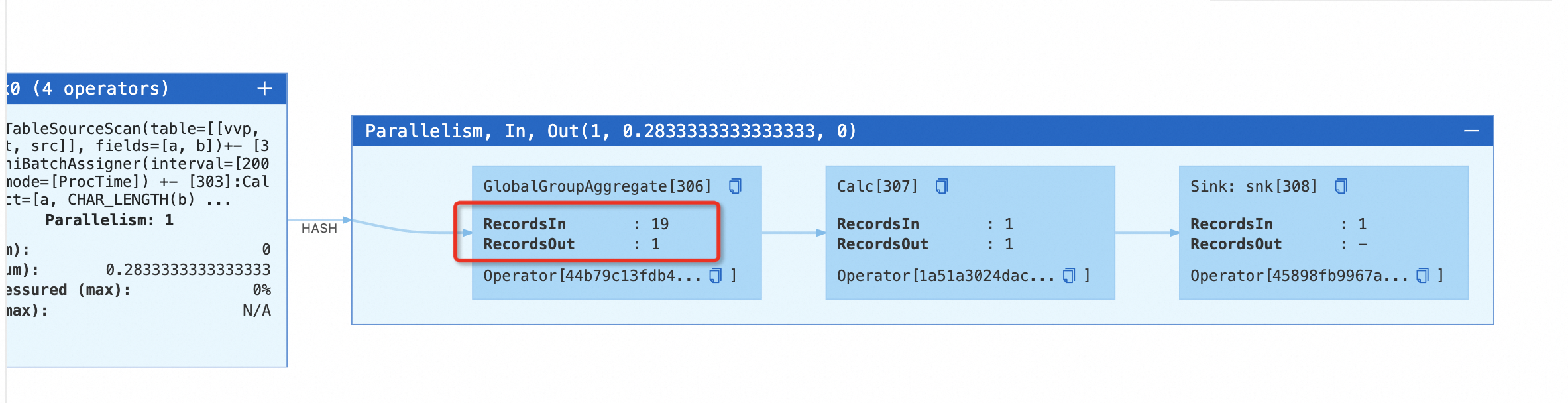
停止该作业,在作业运维页面的部署详情页运行参数配置区域其他配置中,添加参数
table.exec.agg.mini-batch.output-identical-enabled: true启动作业。在状态总览页签下,您可以看到作业包含了MinibatchGlobalAggregate节点,点击该节点上的“+”号,可以观察到GlobalGroupAggregate节点在聚合结果不变的情况下,仍然向下游发送数据。

table.exec.async-lookup.key-ordered-enabled
业务场景在通过维表Join做数据打宽时,通过开启异步模式通常可以获得更好的吞吐性能。当前在维表Join中设置table.exec.async-lookup.output-mode参数和处理的输入是否为更新流最终会对应到异步I/O如下结果顺序:
output-mode\处理的输入 | 更新流 | 非更新流 |
ORDERED | 有序模式 | 有序模式 |
ALLOW_UNORDERED | 有序模式 | 无序模式 |
表格中更新流和ALLOW_UNORDERED的组合通过有序模式确保了正确性,但在一定程度上牺牲了吞吐性能。为优化该场景,推出了table.exec.async-lookup.key-ordered-enabled参数,既兼顾更新流的正确性语义,又保证异步I/O的吞吐性能。对于流中具备相同更新键(可视为变更日志主键)的消息,将按照消息进入算子的先后顺序进行处理。
有序(Ordered)模式:这种模式保持了流的顺序,发出结果消息的顺序与触发异步请求的顺序(消息进入算子的顺序)相同。
无序(Unordered)模式:异步请求一结束就立刻发出结果消息。流中消息的顺序在经过异步I/O算子之后发生了改变。详情请详见异步 I/O | Apache Flink。
应用场景
一段时间内流上相同更新键的消息量较少(比如更新键为主键的场景,相同主键的数据更新频率不高),同时在维表join时对基于更新键的处理有处理顺序的需求。该优化可以保证基于更新键的数据处理顺序。
在包含主键的CDC流中,通过维表join打宽写入Sink(Sink的主键与Source的主键保持一致),且维表join的join key和主键不一致,维表侧join key为主键。该优化会根据CDC主键(被推导为更新键)进行shuffle。相比同场景开启SHUFFLE_HASH优化,在多并发的情况下,可以避免在Sink前产生SinkMaterializer 节点,从而消除因该节点引起的潜在性能问题,尤其可以消除长期运行时该节点产生的大state。有关SinkUpsertMaterializer请参见使用建议。
维表join的join key和主键不一致,维表侧join key为主键,且之后存在rank节点,该优化会根据CDC主键(被推导为更新键)进行shuffle。相比同场景开启SHUFFLE_HASH优化,可以避免UpdateFastRank退化为RetractRank。RetractRank如何能优化成UpdateFastRank请参见TopN优化技巧。
注意事项
当流上不存在更新键时,会将整行数据作为key。
在短时间内同一个更新键存在较频繁的更新时吞吐量会降低,因为针对同一个更新键的数据是严格按照顺序处理的。
Key-Ordered模式相比原有异步维表Join新增了Keyed State,开启或关闭该模式会影响状态兼容性。
仅适用于VVR 8.0.10及以上版本且维表Join的输入是更新流,配置
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'、table.exec.async-lookup.key-ordered-enabled='true'时才会生效。
取值说明
false(默认值):表示不开启Key-Ordered模式。
true:表示开启Key-Ordered模式。
使用示例
以使用Hologres异步维表Join为例,新建SQL流作业,复制如下测试SQL,部署作业。
Hologres连接器详情请参见实时数仓Hologres。
create TEMPORARY table bid_source( auction BIGINT, bidder BIGINT, price BIGINT, channel VARCHAR, url VARCHAR, dateTime TIMESTAMP(3), extra VARCHAR, proc_time as proctime(), WATERMARK FOR dateTime AS dateTime - INTERVAL '4' SECOND ) with ( 'connector' = 'kafka', -- 非insert only流连接器 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' ); CREATE TEMPORARY TABLE users ( user_id STRING PRIMARY KEY NOT ENFORCED, -- 定义主键 user_name VARCHAR(255) NOT NULL, age INT NOT NULL ) WITH ( 'connector' = 'hologres', -- 支持异步lookup功能连机器 'async' = 'true', 'dbname' = 'holo db name', --Hologres的数据库名称 'tablename' = 'schema_name.table_name', --Hologres用于接收数据的表名称 'username' = 'access id', --当前阿里云账号的AccessKey ID 'password' = 'access key', --当前阿里云账号的AccessKey Secret 'endpoint' = 'holo vpc endpoint', --当前Hologres实例VPC网络的Endpoint ); CREATE TEMPORARY TABLE bh ( auction BIGINT, age int ) WITH ( 'connector' = 'blackhole' ); insert into bh SELECT bid_source.auction, u.age FROM bid_source JOIN users FOR SYSTEM_TIME AS OF bid_source.proc_time AS u ON bid_source.channel = u.user_id;在作业运维页面的部署详情页签运行参数配置区域其他配置中,设置
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'和table.exec.async-lookup.key-ordered-enabled='true'参数。启动作业。在状态总览页签下,您可以看到作业async属性KEY_ORDERED:true。
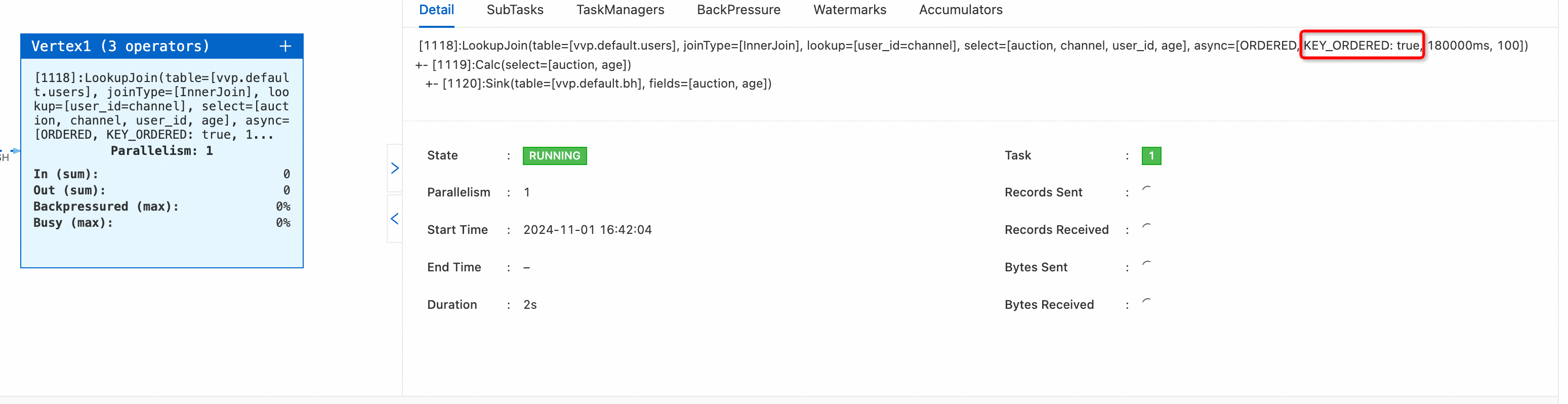
table.optimizer.window-join-enabled
该参数用于控制是否启用窗口关联操作。启用后,Flink会按照窗口关联方式优化对应的执行计划,在窗口较小时,可以减少状态开销提升性能,另外相比于双流JOIN,启用窗口关联可以避免对下游输出更新消息,适用于业务场景中需要通过较小的时间窗口条件进行关联的场景。
注意事项
取值说明
使用示例
新建SQL流作业,复制如下测试SQL,直接通过SET语句设置table.optimizer.window-join-enabled参数为true,然后选中SQL文本右键执行,查看执行计划结果。
SET 'table.optimizer.window-join-enabled' = 'true'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;可以看到执行计划中Optimized Execution Plan部分包含了WindowJoin节点。
== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- WindowJoin(leftWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], rightWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], joinType=[InnerJoin], where=[(num = num0)], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0]) :- Exchange(distribution=[hash[num]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])修改SQL中的SET语句,设置table.optimizer.window-join-enabled参数为false或删除该SET语句,然后选中SQL文本右键执行,查看修改后的执行计划结果。
-- set to 'false' or remove this setting clause SET 'table.optimizer.window-join-enabled' = 'false'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;可以看到执行计划中Optimized Execution Plan部分不再包含WindowJoin节点,变成了双流Join。
== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- Join(joinType=[InnerJoin], where=[((num = num0) AND (window_start = window_start0) AND (window_end = window_end0))], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]) :- Exchange(distribution=[hash[num, window_start, window_end]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num, window_start, window_end]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])