本文围绕Flink SQL实时数据处理中的Changelog事件乱序问题,分析了Flink SQL中Changelog事件乱序问题的原因,并提供了解决方案以及处理Changelog事件乱序的建议。以帮助您更好地理解Changelog的概念和应用,更加高效地使用Flink SQL进行实时数据处理。
Flink SQL中的Changelog
Changelog介绍
在关系数据库领域,MySQL使用binlog(二进制日志)记录数据库中所有修改操作,包括INSERT、UPDATE和DELETE操作。类似地,Flink SQL中的Changelog主要记录数据变化,以实现增量数据处理。
在MySQL中,binlog可以用于数据备份、恢复、同步和复制。通过读取和解析binlog中的操作记录,可以实现增量数据同步和复制。变更数据捕获(CDC)作为一种常用的数据同步技术,常被用于监控数据库中的数据变化,并将其转换为事件流进行实时处理。CDC工具可用于将关系数据库中的数据变化实时传输到其他系统或数据仓库,以支持实时分析和报告。当前常用的CDC工具包括Debezium和Maxwell。Flink通过FLINK-15331支持了CDC,可以实时地集成外部系统的CDC数据,并实现实时数据同步和分析。
Changelog事件生成和处理
Changelog介绍中提到的binlog和CDC是与Flink集成的外部Changelog数据源,Flink SQL内部也会生成Changelog数据。为了区分事件是否为更新事件,我们将仅包含INSERT类型事件的Changelog称为追加流或非更新流,而同时包含其他类型(例如UPDATE)事件的Changelog称为更新流。Flink中的一些操作(如分组聚合和去重)可以产生更新事件,生成更新事件的操作通常会使用状态,这类操作被称为状态算子。需要注意的是,并非所有状态算子都支持处理更新流。例如,Over窗口聚合和Interval Join暂不支持更新流作为输入。
实时计算引擎VVR 6.0及以上版本的Query操作,对应的运行时算子、是否支持处理更新流消费以及是否产生更新,详情请参见Query操作运行时信息说明。
Changelog的事件类型
FLINK-6047引入了回撤机制,使用INSERT和DELETE两种事件类型(尽管数据源仅支持INSERT事件),实现了流SQL算子的增量更新算法。FLINK-16987以后,Changelog事件类型被重构为四种类型(如下),形成一个完整的Changelog事件类型体系,便于与CDC生态系统连接。
/**
* A kind of row in a Changelog.
*/
@PublicEvolving
public enum RowKind {
/**
* Insertion operation.
*/
INSERT,
/**
* Previous content of an updated row.
*/
UPDATE_BEFORE,
/**
* New content of an updated row.
*/
UPDATE_AFTER,
/**
* Deletion operation.
*/
DELETE
}Flink不使用包含UPDATE_BEFORE和UPDATE_AFTER的复合UPDATE事件类型的原因主要有两个方面:
拆分的事件无论是何种事件类型(仅RowKind不同)都具有相同的事件结构,这使得序列化更简单。如果使用复合UPDATE事件,那么事件要么是异构的,要么是INSERT或DELETE事件对齐UPDATE事件(例如,INSERT事件仅含有UPDATE_AFTER,DELETE事件仅含有UPDATE_BEFORE)。
在分布式环境下,经常涉及数据shuffle(例如Join、聚合)。即使使用复合UPDATE事件,有时仍需将其拆分为单独的DELETE和INSERT事件进行shuffle,例如下面的示例。
示例
下面是一个复合UPDATE事件必须拆分为DELETE和INSERT事件的场景示例。本文后续也将围绕此SQL作业示例讨论Changelog事件乱序问题并提供相应的解决方案。
-- CDC source tables: s1 & s2
CREATE TEMPORARY TABLE s1 (
id BIGINT,
level BIGINT,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
CREATE TEMPORARY TABLE s2 (
id BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
-- sink table: t1
CREATE TEMPORARY TABLE t1 (
id BIGINT,
level BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
-- join s1 and s2 and insert the result into t1
INSERT INTO t1
SELECT
s1.*, s2.attr
FROM s1 JOIN s2
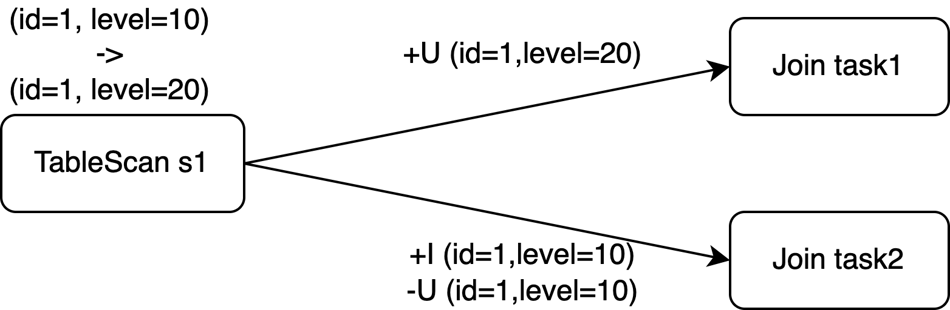
ON s1.level = s2.id;假设源表s1中id为1的记录的Changelog在时间t0插入(id=1, level=10),然后在时间t1将该行更新为(id=1, level=20)。这对应三个拆分事件:
s1 | 事件类型 |
+I(id=1,level=10) | INSERT |
-U(id=1,level=10) | UPDATE_BEFORE |
+U(id=1,level=20) | UPDATE_AFTER |
源表s1的主键是id,但Join操作需要按level列进行shuffle(见子句ON)。
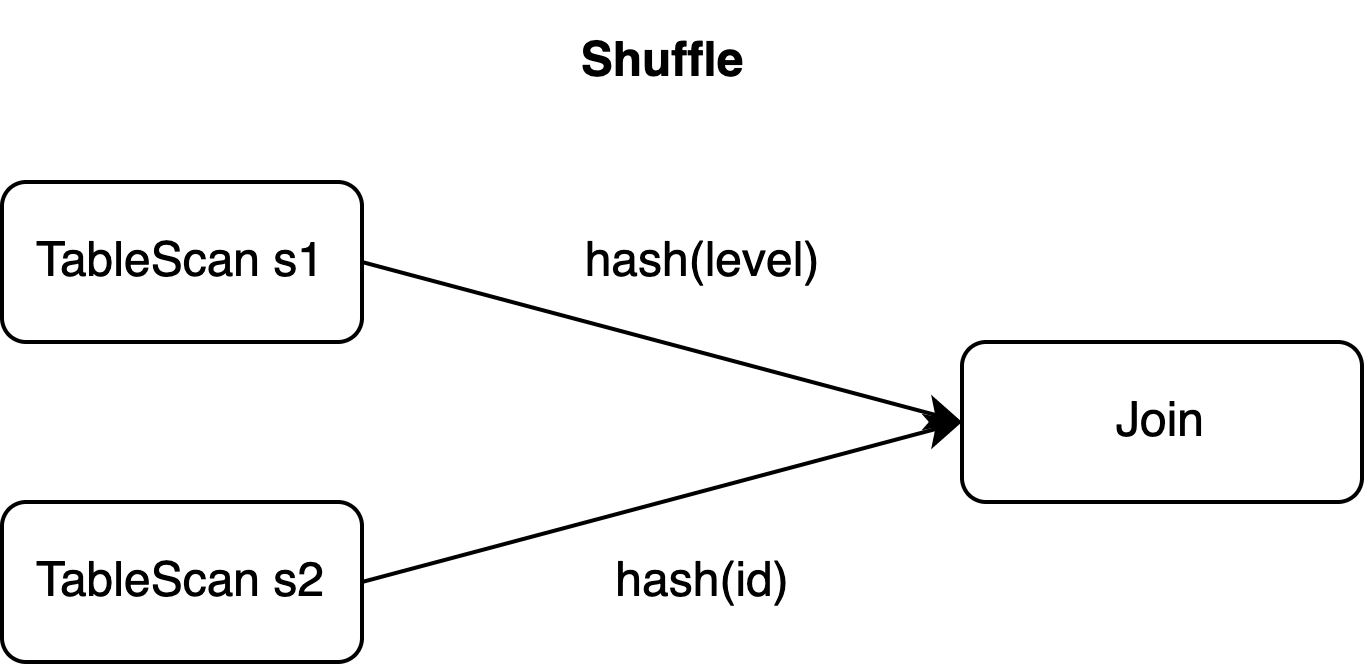
如果Join算子的并发数为2,那么以上三个事件可能会被发送到两个任务中。即使使用复合UPDATE事件,它们也需要在shuffle阶段拆分,来保证数据的并行处理。
Changelog事件乱序问题
乱序原因
假设示例中表s2已有两行数据进入Join算子(+I(id=10,attr=a1),+I(id=20,attr=b1)),Join运算符从表s1新接收到三个Changelog事件。在分布式环境中,实际的Join在两个任务上并行处理,下游算子(示例中为Sink任务)接收的事件序列可能情况如下所示。
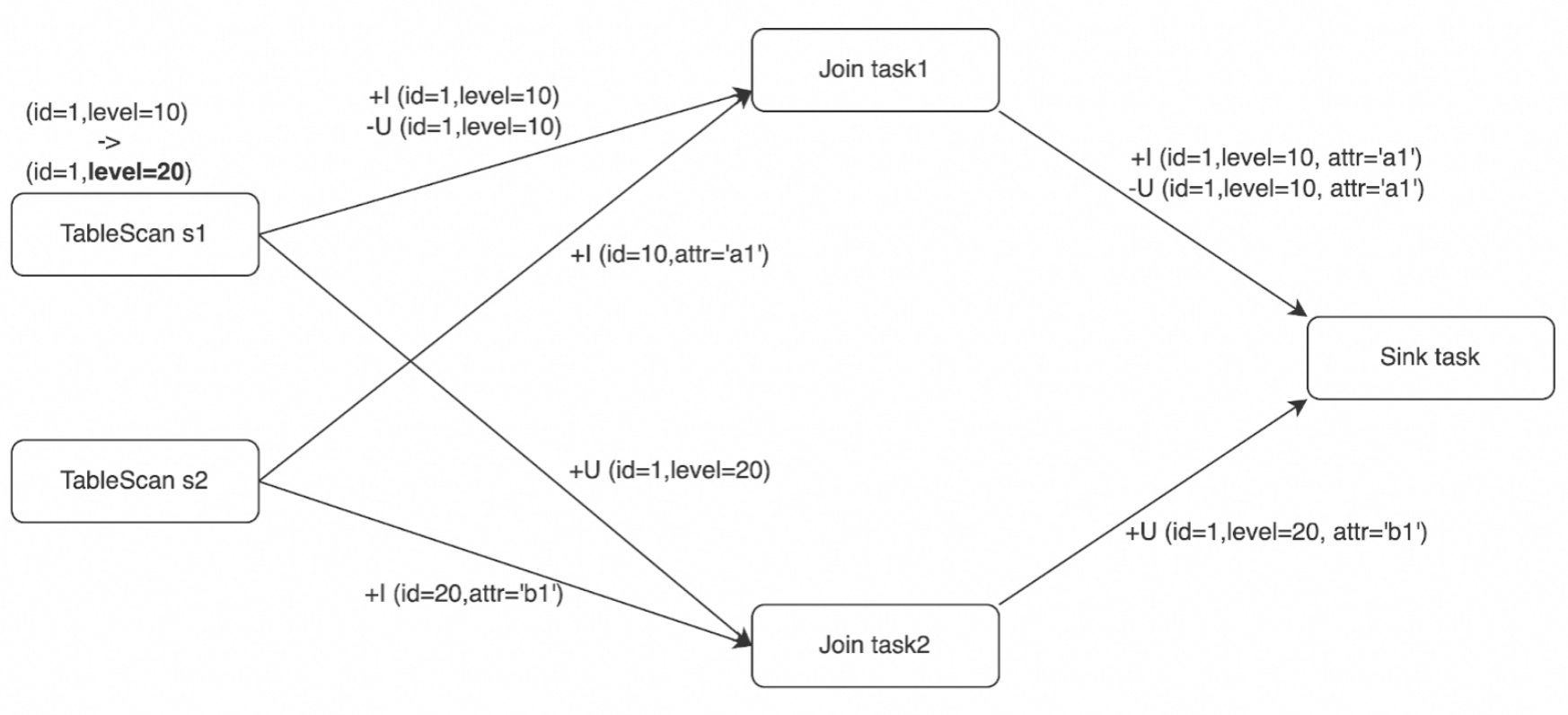
情况1 | 情况2 | 情况3 |
+I (id=1,level=10,attr='a1') -U (id=1,level=10,attr='a1') +U (id=1,level=20,attr='b1') | +U (id=1,level=20,attr='b1') +I (id=1,level=10,attr='a1') -U (id=1,level=10,attr='a1') | +I (id=1,level=10,attr='a1') +U (id=1,level=20,attr='b1') -U (id=1,level=10,attr='a1') |
情况1的事件序列与顺序处理中的事件序列相同。情况2和情况3显示了Changelog事件在Flink SQL中到达下游算子时的乱序情况。乱序情况可能会导致不正确的结果。在示例中,结果表声明的主键是id,外部存储进行upsert更新时,在情况2和3中,如果没有其他措施,将从外部存储不正确地删除id=1的行,而期望的结果是(id=1, level=20, attr='b1')。
使用SinkUpsertMaterializer解决
在示例中,Join操作生成更新流,其中输出包含INSERT事件(+I)和UPDATE事件(-U和+U),如果不正确处理,乱序可能会导致正确性问题。
唯一键与upsert键
唯一键是指SQL操作后满足唯一约束的列或列组合。在本示例中(s1.id)、(s1.id, s1.level)和(s1.id, s2.id)这三组都是唯一键。
Flink SQL的Changelog参考了binlog机制,但实现方式更加简洁。Flink不再像binlog一样记录每个更新的时间戳,而是通过planner中的全局分析来确定主键接收到的更新历史记录的排序。如果某个键维护了唯一键的排序,则对应的键称为upsert键。对于存在upsert键的情况,下游算子可以正确地按照更新历史记录的顺序接收upsert键的值。如果shuffle操作破坏了唯一键的排序,upsert键将为空,此时下游算子需要使用一些算法(例如计数算法)来实现最终的一致性。
在示例中,表s1中的行根据列level进行shuffle。Join生成多个具有相同s1.id的行,因此Join输出的upsert键为空(即Join后唯一键上不存在排序)。此时,Flink需存储所有输入记录,然后检查比较所有列以区分更新和插入。
此外,结果表的主键为列id。Join输出的upsert键与结果表的主键不匹配,需要进行一些处理将Join输出的行进行正确转换为结果表所需的行。
SinkUpsertMaterializer
根据唯一键与upsert键的内容,当Join输出的是更新流且其upsert键与结果表主键不匹配时,需要一个中间步骤来消除乱序带来的影响,以及基于结果表的主键产生新的主键对应的Changelog事件。Flink在Join算子和下游算子之间引入了SinkUpsertMaterializer算子(FLINK-20374)。
结合乱序原因中的Changelog事件,可以看到Changelog事件乱序遵循着一些规则。例如,对于一个特定的upsert键(或upsert键为空则表示所有列),事件ADD(+I、+U)总是在事件RETRACT(-D、-U)之前发生;即使涉及到数据shuffle,相同upsert键的一对匹配的Changelog事件也总是被相同的任务处理。这些规则也说明了为什么示例仅存在乱序原因中三个Changelog事件的组合。
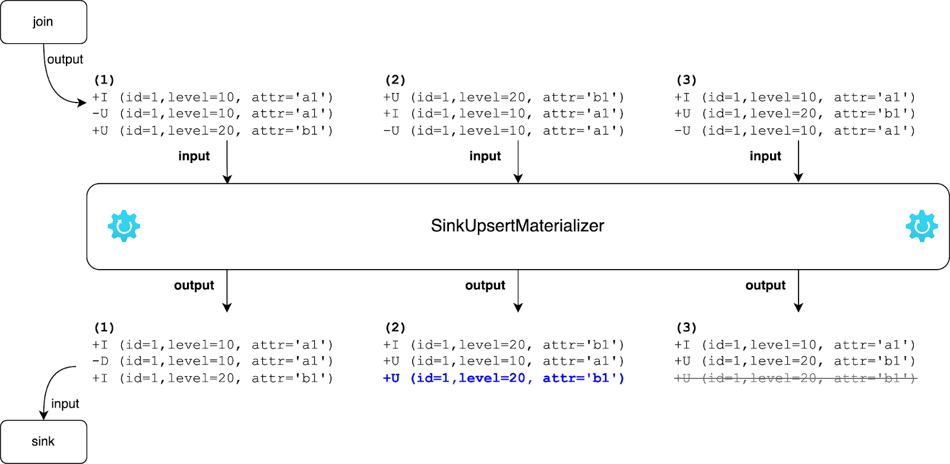
SinkUpsertMaterializer就是基于上述规则实现的,其工作原理如下图所示。SinkUpsertMaterializer在其状态中维护了一个RowData列表。当SinkUpsertMaterializer被触发,在处理输入行时,它根据推断的upsert键或整个行(如果upsert键为空)检查状态列表中是否存在相同的行。在ADD的情况下添加或更新状态中的行,在RETRACT的情况下从状态中删除行。最后,它根据结果表的主键生成Changelog事件,更多详细信息请参见SinkUpsertMaterializer源代码。
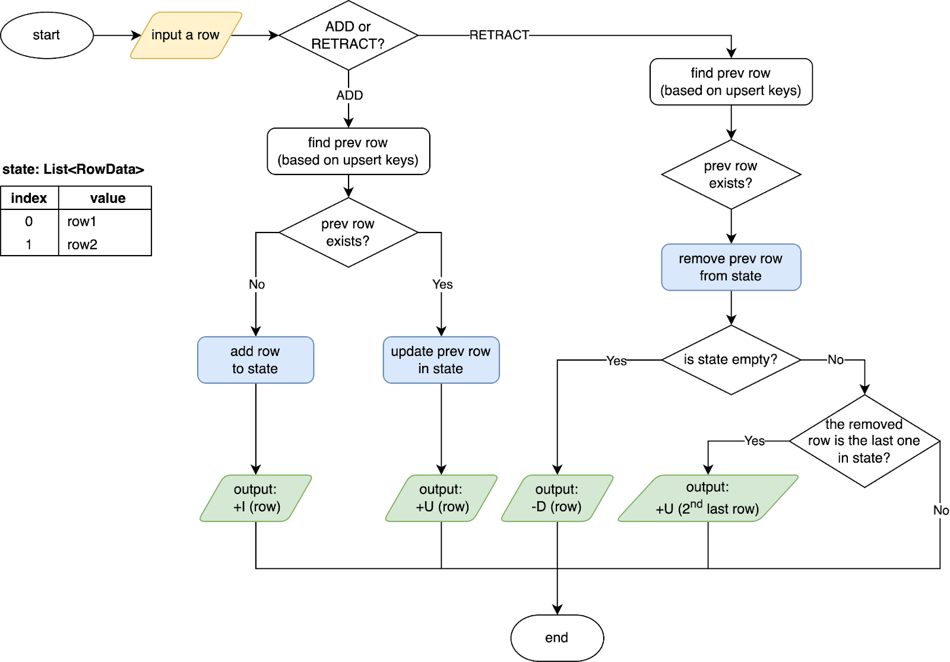
通过SinkUpsertMaterializer,将示例中Join算子输出的Changelog事件处理并转换为结果表主键对应的Changelog事件,结果如下图所示。根据SinkUpsertMaterializer的工作原理,在情况2中,处理-U(id=1,level=10,attr='a1')时,会将最后一行从状态中移除,并向下游发送倒数第二行;在情况3中,当处理+U (id=1,level=20,attr='b1')时,SinkUpsertMaterializer会将其原样发出,而当处理-U(id=1,level=10,attr='a1')时,将从状态中删除行而不发出任何事件。最终,通过SinkUpsertMaterializer算子情况2和3也会得到期望结果 (id=1,level=20,attr='b1')。
常见场景
触发 SinkUpsertMaterializer算子的常见场景如下:
结果表定义主键,而写入该结果表的数据丢失了唯一性。通常包括但不限于以下操作:
源表缺少主键,而结果表却设置了主键。
向结果表插入数据时,忽略了主键列的选择,或错误地使用了源表的非主键数据填充结果表的主键。
源表的主键数据在转换或经过分组聚合后出现精度损失。例如,将BIGINT类型降为INT类型。
对源表的主键列或经过分组聚合之后的唯一键进行了运算,如数据拼接或将多个主键合并为单一字段。
CREATE TABLE students ( student_id BIGINT NOT NULL, student_name STRING NOT NULL, course_id BIGINT NOT NULL, score DOUBLE NOT NULL, PRIMARY KEY(student_id) NOT ENFORCED ) WITH (...); CREATE TABLE performance_report ( student_info STRING NOT NULL PRIMARY KEY NOT ENFORCED, avg_score DOUBLE NOT NULL ) WITH (...); CREATE TEMPORARY VIEW v AS SELECT student_id, student_name, AVG(score) AS avg_score FROM students GROUP BY student_id, student_name; -- 将分组聚合后的key进行拼接当作主键写入结果表,但实际上已经丢失了唯一性约束 INSERT INTO performance_report SELECT CONCAT('id:', student_id, ',name:', student_name) AS student_info, avg_score FROM v;
结果表的确立依赖于主键的设定,然而在数据输入过程中,其原有的顺序性却遭到破坏。例如本文的示例,双流Join时若一方数据未通过主键与另一方关联,而结果表的主键列又是基于另一方的主键列生成的,这便可能导致数据顺序的混乱。
明确配置了
table.exec.sink.upsert-materialize参数为'force',配置详情请参见下方的参数设置。
使用建议
正如前面所提到的,SinkUpsertMaterializer在其状态中维护了一个RowData列表。这可能会导致状态过大并增加状态访问I/O的开销,最终影响作业的吞吐量。因此,应尽量避免使用它。
参数设置
SinkUpsertMaterializer可以通过table.exec.sink.upsert-materialize进行配置:
auto(默认值):Flink会从正确性的角度推断出乱序是否存在,如果必要的话,则会添加SinkUpsertMaterializer。
none:不使用。
force:强制使用。即便结果表的DDL未指定主键,优化器也会插入SinkUpsertMaterializer状态节点,以确保数据的物理化处理。
需要注意的是,设置为auto并不一定意味着实际数据是乱序的。例如,使用grouping sets语法结合coalesce转换null值时,SQL planner可能无法确定由grouping sets与coalesce组合生成的upsert键是否与结果表的主键匹配。出于正确性的考虑,Flink将添加SinkUpsertMaterializer。如果一个作业可以在不使用SinkUpsertMaterializer的情况下生成正确的输出,建议设置为none。
避免使用SinkUpsertMaterializer
为了避免使用SinkUpsertMaterializer,您可以:
确保在进行去重、分组聚合等操作时,所使用的分区键要与结果表的主键相同。
如果单并发可以处理对应的数据量,改成单并发可以避免处理过程中产生额外的乱序(原始输入的乱序除外),此时在作业参数中设置table.exec.sink.upsert-materialize为 none 显式关闭生成 SinkUpsertMaterializer 节点。
如果下游算子与上游的去重、分组聚合或其他算子相连,且在VVR 6.0以下版本中没有出现数据准确性问题,那么可以参考原资源配置,并将table.exec.sink.upsert-materialize更改为none,将作业迁移到实时计算引擎VVR 6.0及以上版本,引擎升级请参见作业引擎版本升级。
若必须使用SinkUpsertMaterializer,需注意以下事项:
避免在写入结果表时添加由非确定性函数(如CURRENT_TIMESTAMP、NOW)生成的列,可能会导致Sink输入在没有upsert键时,SinkUpsertMaterializer的状态异常膨胀。
如果已出现SinkUpsertMaterializer算子存在大状态的情况并影响了性能,请考虑增加作业并发度,操作步骤请参见配置作业资源。
使用注意事项
SinkUpsertMaterializer虽然解决了Changelog事件乱序问题,但可能引起持续状态增加的问题。主要原因有:
状态有效期过长(未设置或设置过长的状态TTL)。但如果TTL设置过短,可能会导致FLINK-29225中描述的问题,即本应删除的脏数据仍保留在状态中。当消息的DELETE事件与其ADD事件之间的时间间隔超过配置的TTL时会出现这种情况,此时,Flink会在日志中产生一条如下警告信息。
int index = findremoveFirst(values, row); if (index == -1) { LOG.info(STATE_CLEARED_WARN_MSG); return; }您可以根据业务需要设置合理的TTL,具体操作请参见运行参数配置,实时计算VVR 8.0.7及以上版本,支持为不同算子设置不同TTL,进一步节约大状态作业的使用资源,具体操作请参见配置算子并发、Chain策略和TTL。
当SinkUpsertMaterializer输入的更新流无法推导出upsert键,并且更新流中存在非确定性列时,将无法正确删除历史数据,这会导致状态持续增加。
相关文档
实时计算引擎版本和Apache Flink版本对应关系,详情请参见功能发布记录。