EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验SQL的创建、启动和运维等操作。
前提条件
步骤一:创建并发布开发任务
任务必须先发布,然后才能在任务编排过程中使用。
进入数据开发页面。
在左侧导航栏,选择。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的数据开发。
新建users_task任务。
在开发目录页签下,单击
 图标。
图标。在新建对话框中,输入名称(例如users_task),类型使用默认的SparkSQL,然后单击确定。
拷贝如下代码到新增的Spark SQL页签(users_task)中。
CREATE TABLE IF NOT EXISTS students ( name VARCHAR(64), address VARCHAR(64) ) USING PARQUET PARTITIONED BY (data_date STRING) OPTIONS ( 'path'='oss://<bucketname>/path/' ); INSERT OVERWRITE TABLE students PARTITION (data_date = '${ds}') VALUES ('Ashua Hill', '456 Erica Ct, Cupertino'), ('Brian Reed', '723 Kern Ave, Palo Alto');目前支持以下基础日期变量,默认为昨天。
变量
数据类型
说明
{data_date}
str
表示日期信息的变量,格式为
YYYY-MM-DD。例如,2023-09-18。
{ds}
str
{dt}
str
{data_date_nodash}
str
表示日期信息的变量,格式为
YYYYMMDD。例如,20230918。
{ds_nodash}
str
{dt_nodash}
str
{ts}
str
表示时间戳,格式为
YYYY-MM-DDTHH:MM:SS。例如,2023-09-18T16:07:43。
{ts_nodash}
str
表示时间戳,格式为
YYYYMMDDHHMMSS。例如,20230918160743。
在数据库下拉列表中选择一个数据库,在会话下拉列表中选择一个已启动的会话实例。
您也可以在下拉列表中选择创建SQL会话,直接创建一个新的会话实例。会话管理更多介绍,请参见管理SQL会话。
单击运行,执行创建的任务。
返回结果信息可以在下方的运行结果中查看。如果有异常,则可以在运行问题中查看。
发布users_task任务。
说明任务指定的参数会伴随任务一起发布,并成为产线运行任务时使用的参数;而在SQL编辑器中执行的任务则使用会话中的参数。
在新增的Spark SQL页签中,单击发布。
在弹出的对话框中,可以输入发布信息,然后单击确定。
新建users_count任务。
在开发目录页签下,单击
图标。在新建对话框中,输入名称(例如users_count),类型使用默认的SparkSQL,单击确定。
拷贝如下代码到新增的Spark SQL任务页签(users_count)中。
SELECT COUNT(1) FROM students;在数据库下拉列表中选择一个数据库,在会话下拉列表中选择一个已启动的会话实例。
您也可以在下拉列表中选择创建SQL会话,直接创建一个新的会话实例。会话管理更多介绍,请参见管理SQL会话。
单击运行,执行创建的任务。
返回结果信息可以在下方的运行结果中查看。如果有异常,则可以在运行问题中查看。
发布users_count任务。
说明任务指定的参数会伴随任务一起发布,并成为产线运行任务时使用的参数;而在SQL编辑器中执行的任务则使用会话中的参数。
在新增的Spark SQL任务页签中,单击发布。
在弹出的对话框中,可以输入发布信息,然后单击确定。
步骤二:创建工作流及其节点
在左侧导航栏中,单击任务编排。
在任务编排页面,单击创建工作流。
在创建工作流面板中,输入工作流名称(例如,spark_workflow_task),然后单击下一步。
其他设置区域的参数,请根据您的实际情况配置,更多参数信息请参见管理工作流。
添加users_task节点。
在新建的节点画布中,单击添加节点。
弹出添加节点面板,在来源文件路径下拉列表中选择已发布的任务users_task,然后单击保存。
添加users_count节点。
单击添加节点。
弹出添加节点面板,在来源文件路径下拉列表中选择已发布的任务users_count,在上游节点下拉列表中选择users_task,单击保存。
在新建的节点画布中,单击发布工作流。
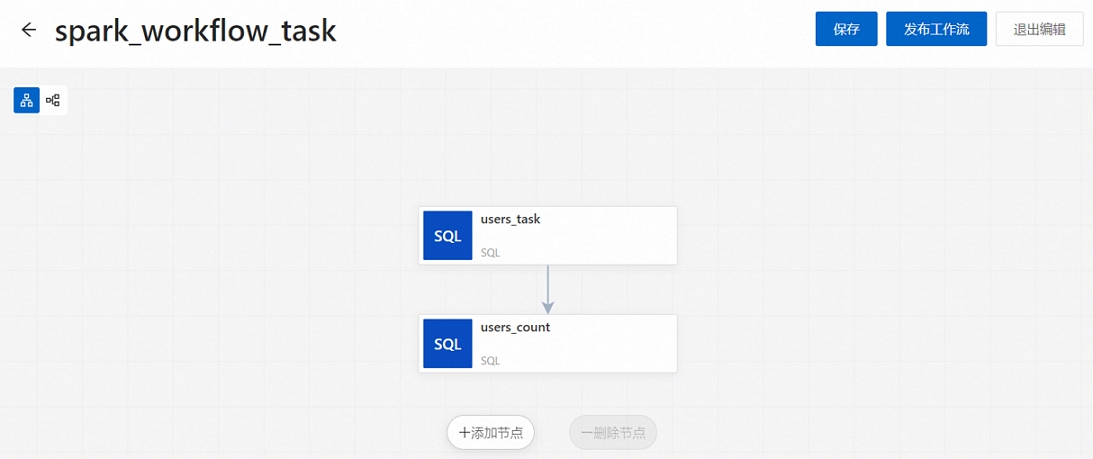
在发布对话框中,可以输入发布信息,然后单击确定。
步骤三:运行工作流
在任务编排页面,单击新建工作流(例如,spark_workflow_task)的工作流名称。
在工作流实例列表页面,单击运行。
说明在配置了调度周期后,您也可以在任务编排页面通过左侧的开关按钮启动调度。
在运行工作流对话框中,单击确定。
步骤四:查看实例状态
在任务编排页面,单击目标工作流名称(例如,spark_workflow_task)。
在工作流实例列表页面,您可以查看对应的所有工作流实例,以及各工作流实例的运行时间、运行状态等。
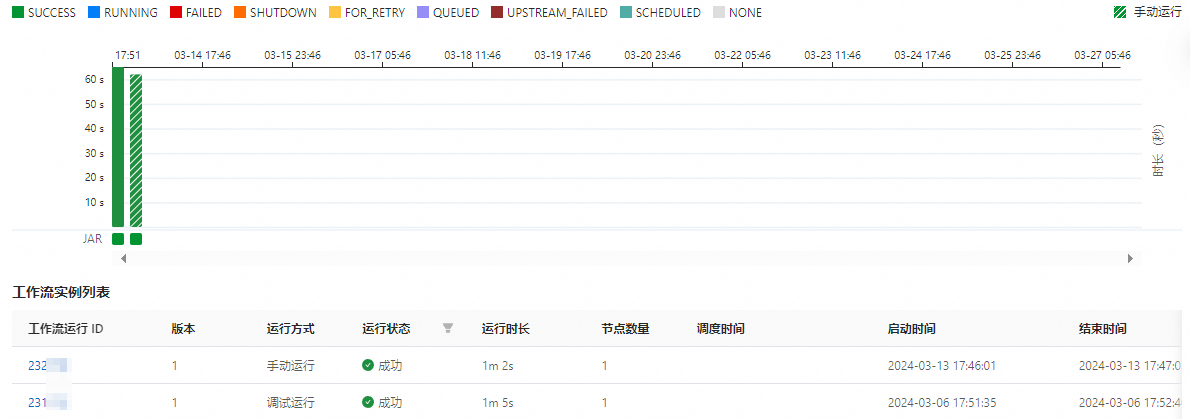
单击工作流实例列表区域的工作流运行ID,或单击上方的工作流实例图页签,可以查看对应的工作流实例图。
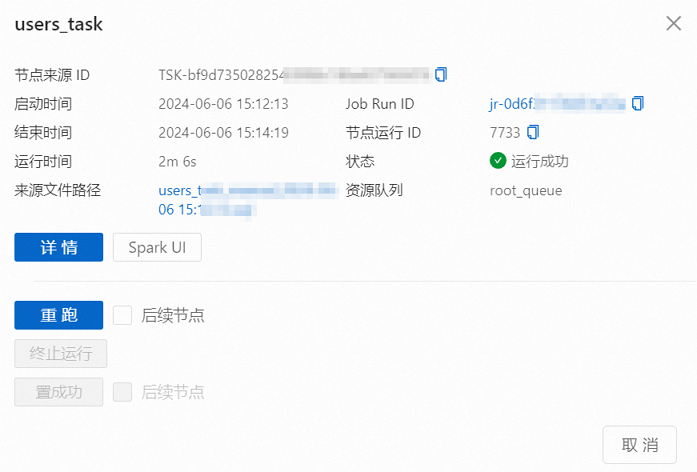
单击目标节点实例,在弹出的节点信息框中,您可以根据需要操作或查看信息。
关于此部分内容的相关操作及详细介绍,请参见查看节点实例。
例如,单击Spark UI跳转至Spark Jobs页面,可以查看Spark任务的实时信息。
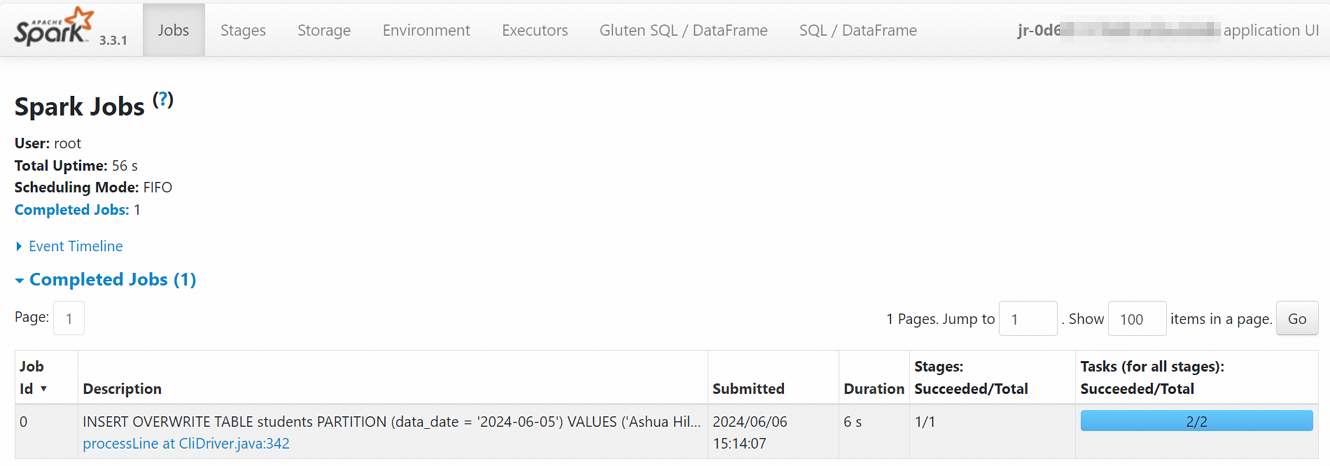
单击任务运行ID,进入任务历史页面,可以查看指标、诊断和日志信息。
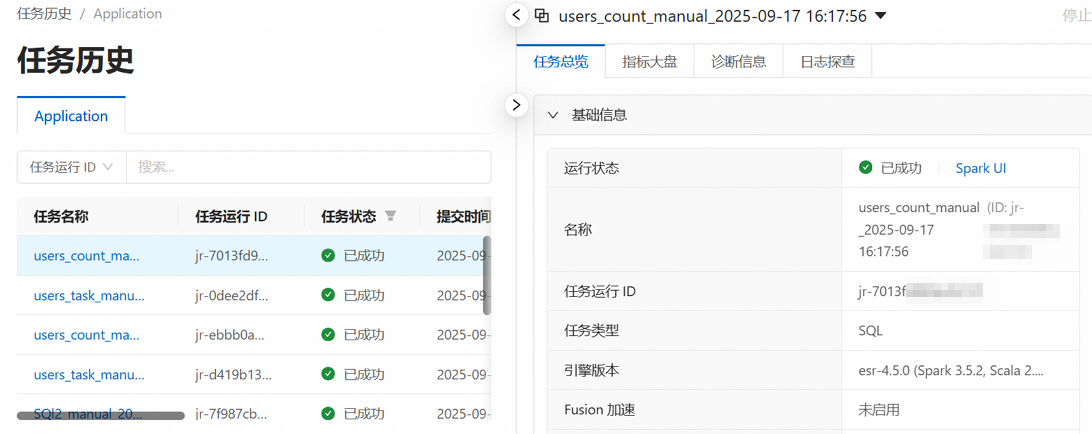
步骤五:工作流运维
在任务编排页面,单击目标工作流名称,进入工作流实例列表页面。您可以:
在工作流信息区域,可以编辑部分参数。
在工作流实例列表区域,可以查看所有工作流。单击工作流运行ID,可以进入工作流实例图页面。
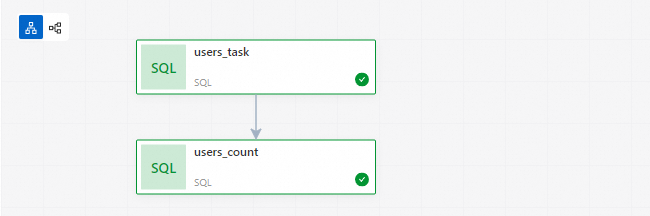
步骤六:查看数据
在左侧导航栏中,单击数据开发。
新建SparkSQL开发,然后输入并运行以下命令查看表的详细信息。
SELECT * FROM students;返回信息如下所示。
