本文为您介绍如何使用数据传输迁移 Oracle 数据库的数据至 OceanBase 数据库 Oracle 租户。
如果数据迁移任务长期处于非活跃状态(任务状态为 失败、已暂停 或 已完成),受增量日志保留时长等影响,任务可能无法恢复。数据传输将主动释放处于非活跃状态超过 3 天的数据迁移任务,以回收相关资源,建议您为任务配置告警并及时处理任务相关异常。
前提条件
数据传输已具备云资源访问权限。详情请参见 数据传输迁移角色授权。
已为源端 Oracle 数据库和目标端 OceanBase 数据库 Oracle 租户创建专用于数据迁移的数据库用户,并为其赋予相关权限。详情请参见 创建数据库用户。
已在目标端 OceanBase 数据库 Oracle 租户创建对应的数据库。OceanBase 数据迁移功能支持迁移表和列,不支持迁移库,您需要提前在目标端创建对应的数据库。
Oracle 源实例必须开启 Archive Log,并且在数据传输增量复制前已经切换过 LogFile。
Oracle 源实例必须已经安装并可正常使用 LogMiner 工具。
您可以通过 LogMiner 工具获取 Oracle 归档日志文件中的具体内容。
确认 Oracle 实例已开启数据库级别或者表级别的补偿日志。
开启数据库级别的 PK 和 UK 补偿日志,当无需同步的表产生较多不必要的日志时,会增加 LogMiner Reader 拉取日志的压力和 Oracle 自身的压力。所以,数据传输支持 Oracle 数据库仅开启表级别的 PK 和 UK 补偿日志。但是,如果在创建迁移任务时,针对非 PK 列或 UK 列设置了 ETL 过滤,请开启对应列的补偿日志,或者直接开启所有列的补偿日志。
Oracle 机器和数据传输机器之间需要进行时钟同步(例如配置 NTP 服务),否则会存在数据风险。如果是 Oracle RAC,则多个 Oracle 实例之间也需要进行时钟同步。
使用限制
源端数据库的操作限制
请勿在结构迁移和全量迁移阶段执行库或表结构变更的 DDL 操作,否则可能造成数据迁移任务中断。
数据传输支持的 Oracle 数据库版本为 10G/11G/12C/18C/19C,12C 及之后版本包含数据库容器(Container Database,CDB)和可插拔数据库(Pluggable Database,PDB)。
数据传输仅支持迁移普通表和视图。
数据传输仅支持迁移库名、表名和列名为 ASCII 码且不包含特殊字符(包括换行、空格,以及 .|"'`()=;/&\)的对象。
目标端是数据库的情况下,数据传输不支持目标端存在触发器(Trigger)。如果存在,可能导致数据迁移失败。
数据传输不支持迁移 Oracle 数据库中的索引组织表(IOT,Index-Organized Table),否则会出现数据迁移任务中断的问题。
数据类型的限制
不支持表中全部列均为 LOB 类型(BLOB/CLOB/NCLOB)的增量数据同步。
对于无主键且包含 LOB 类型字段的表,反向增量会出现数据质量问题。
数据源标识和用户账号等,在数据传输系统内是全局唯一的。
Oracle 数据库的增量日志解析最大支持 5T/天。
Oracle 数据库 11G 及之前版本不支持创建超过 30 个字节的数据库对象。在反向增量步骤中,请注意不能在 OceanBase 数据库 Oracle 租户中创建大于本限制的数据库对象。
数据传输不支持迁移 Oracle 数据库 12C 及之后版本中超过 30 个字节的数据库对象(包括 Schema、表和列等)。如果您需要迁移超过 30 个字节的数据库对象,请联系技术支持人员。
数据传输不支持源端 Oracle 数据库执行某些
UPDATE命令。以下示例为一个不支持的UPDATE命令。UPDATE TABLE_NAME SET KEY=KEY+1;上述示例中,
TABLE_NAME是表名,KEY是定义为主键的 NUMERIC 类型的列。自建数据库所在的 VPC 必须和 OceanBase 数据库位于同一个地域。
注意事项
当需要进行 Oracle 数据库的增量同步时,Oracle 数据库单个归档文件的大小建议小于 2GB。
Oracle 数据库的归档文件保存 2 天以上,否则由于某个时间段归档量陡增等情况,准备恢复时没有了归档文件,将无法恢复。
如果源端 Oracle 数据库存在交换主键的 DML 语句,将导致数据传输解析日志异常,迁移至目标端时存在数据丢失的问题。交换主键的 DML 语句示例如下:
update test set c1=(case when c1=1 then 2 when c1=2 then 1 end) where c1 in (1,2);Oracle 实例的字符集配置可以为 AL32UTF8、AL16UTF16、ZHS16GBK 和 GB18030。
如果源端字符集为 UTF-8,建议目标端使用兼容源端的字符集(例如,UTF-8、UTF-16 等),避免因字符集不兼容导致目标端出现乱码等问题。
迁移 Oracle 数据库的数据至 OceanBase 数据库 Oracle 租户时,禁止所有表进行导入、导出、Alter Table、Flashback Table、分区分裂或合并等会导致 ROWID 变更的操作。
当源端 Oracle 数据库存在更新分区键、合并分区等影响 RowID 行为的操作时,目标端 OceanBase 数据库 Oracle 租户增加了隐藏列依赖 RowID,可能导致数据丢失的风险。
节点之间的时钟不同步,或者电脑终端和服务器之间的时钟不同步,均可能导致延迟时间(增量同步/反向增量)不准确。
例如,如果时钟早于标准时间,可能导致延迟时间为负数。如果时钟晚于标准时间,可能导致延迟。
由于中国曾经实行夏令时的历史原因,导致 Oracle 数据库至 OceanBase 数据库 Oracle 租户的增量同步中,1986 年~1991 年的夏令时开始和结束的日期,以及 1988 年 4 月 10 日~ 4 月 17 日,
TIMESTAMP(6) WITH TIME ZONE类型,源端和目标端可能存在 1 小时的时间差。在未开启同步 DDL 的情况下,如果您变更目标端的唯一索引,需要重启数据迁移任务,否则可能存在数据不一致的问题。
如果数据迁移任务没有启用正向切换,请删除目标端数据库对应的唯一索引和伪列。如果不删除唯一索引和伪列,会导致无法写入数据,并且在往下游导入数据时,会重新生成伪列,导致与源端数据库的伪列发生冲突。
如果数据迁移任务已启用正向切换,数据传输会根据数据迁移任务的类型,自动删除隐藏列和唯一索引。详情请参见 数据迁移服务隐藏列机制说明。
对于 Oracle 数据库至 OceanBase 数据库 Oracle 租户的增量同步,如果有新增的无主键表迁移,数据传输不会自动删除在 OceanBase 数据库 Oracle 租户目标端添加的隐藏列和唯一索引。在进行反向迁移前,请您手动删除。
您可以查看
logs/msg/manual_table.log文件,确认增量同步阶段添加的无主键表。当源端和目标端的字符编码配置不同时,结构迁移会提供字段长度定义扩大的策略。例如,字段长度扩大 1.5 倍,长度单位从 BYTE 转为 CHAR 等。
转换后可以确保源端不同字符集中的数据能成功迁移至目标端,但割接后反向增量可能会出现数据超长无法写回源端的问题。
如果源端存在包含时区信息的数据类型(例如 TIMESTAMP WITH TIME ZONE),请您确保目标端数据库支持并存在源端对应的时区,否则将导致数据迁移过程中产生数据不一致的问题。
库表汇聚场景下:
建议您使用匹配规则的方式映射源端和目标端的关系。
建议您自行在目标端创建表结构。如果使用数据传输创建,请在结构迁移步骤中跳过部分失败对象。
请检查 Oracle 数据库回收站内的对象。当对象数量大于 100 时,容易造成内部表查询超时,请进行回收站的对象清理工作。
检查回收站是否打开。
SELECT Value FROM V$parameter WHERE Name = 'recyclebin';检查回收站内对象的数量。
SELECT COUNT(*) FROM RECYCLEBIN;
如果在创建数据迁移任务时,您仅配置了 增量同步,数据传输要求源端数据库的归档日志保存 48 小时以上。
如果在创建数据迁移任务时,您配置了 全量迁移+增量同步,数据传输要求源端数据库的归档日志至少保留 7 天以上。否则数据传输可能因无法获取增量日志而导致数据迁移任务失败,甚至导致源端和目标端数据不一致。
如果源端或目标端存在仅大小写不同的表对象,可能会因为源端或目标端大小写不敏感导致数据迁移的结果不符合预期。
目标端为 OceanBase 数据库 MySQL 租户 V4.1.0 及之后版本时,支持 Latin1 字符集的迁移。
源端为 Oracle 数据库的增量同步任务(通过 Kafka 获取增量数据除外),如果单个事务跨归档,LogMiner 在跨归档的事务中无法正确返回完整的数据信息,便可能存在丢失数据的问题。建议您配置全量数据校验和数据订正,以确保数据一致性。
支持的源端和目标端实例类型
下表中,OceanBase 数据库 Oracle 租户简称为 OB_Oracle。
源端 | 目标端 |
Oracle(VPC 内自建数据库) | OB_Oracle(OceanBase 集群实例) |
Oracle(公网 IP 自建数据库) | OB_Oracle(OceanBase 集群实例) |
数据类型映射
CLOB 和 BLOB 类型的数据必须小于 48 MB。
不支持迁移 ROWID、BFILE、XMLType、UROWID、UNDEFINED 和 UDT 类型的数据。
不支持 LONG 或 LONG RAW 类型的表进行增量同步。
Oracle 数据库 | OceanBase 数据库 Oracle 租户 |
CHAR(n CHAR) | CHAR(n CHAR) |
CHAR(n BYTE) | CHAR(n BYTE) |
NCHAR(n) | NCHAR(n) |
VARCHAR2(n) | VARCHAR2(n) |
NVARCHAR2(n) | NVARCHAR2(n) |
NUMBER(n) | NUMBER(n) |
NUMBER (p, s) | NUMBER(p,s) |
RAW | RAW |
CLOB | CLOB |
NCLOB | NVARCHAR2 说明 OceanBase 数据库 Oracle 租户中,NVARCHAR2 类型的字段不支持空值。如果源端存在空值,则以字符串 NULL 表示。 |
BLOB | BLOB |
REAL | FLOAT |
FLOAT(n) | FLOAT |
BINARY_FLOAT | BINARY_FLOAT |
BINARY_DOUBLE | BINARY_DOUBLE |
DATE | DATE |
TIMESTAMP | TIMESTAMP |
TIMESTAMP WITH TIME ZONE | TIMESTAMP WITH TIME ZONE |
TIMESTAMP WITH LOCAL TIME ZONE | TIMESTAMP WITH LOCAL TIME ZONE |
INTERVAL YEAR(p) TO MONTH | INTERVAL YEAR(p) TO MONTH |
INTERVAL DAY(p) TO SECOND | INTERVAL DAY(p) TO SECOND |
LONG | CLOB 重要 该类型不支持增量同步。 |
LONG RAW | BLOB 重要 该类型不支持增量同步。 |
SDO_GEOMETRY | SDO_GEOMETRY |
检查和修改 Oracle 实例的系统配置
您需要进行下述操作:
在源端 Oracle 数据库开启归档模式
在源端 Oracle 数据库开启补偿日志
(可选)设置 Oracle 数据库的系统参数
在源端 Oracle 数据库开启归档模式
SELECT log_mode FROM v$database;log_mode 字段需要是 archivelog。否则,您需要根据下述方法进行修改。
执行下述命令,开启归档模式。
SHUTDOWN IMMEDIATE; STARTUP MOUNT; ALTER DATABASE ARCHIVELOG; ALTER DATABASE OPEN;执行下述命令,查看归档日志的路径和配额。
检查
recovery file的路径和配额,建议db_recovery_file_dest_size的配置值尽量大一些。另外,开启归档后,需要用 RMAN 等方法定期清理归档日志。SHOW PARAMETER db_recovery_file_dest;根据业务需要更改归档日志的配额。
ALTER SYSTEM SET db_recovery_file_dest_size =50G SCOPE = BOTH;
在源端 Oracle 数据库开启补偿日志
LogMiner Reader 支持 Oracle 系统配置仅开启表级别的补偿日志。如果在迁移过程中,源端 Oracle 数据库新创建了表并需要迁移,则您需要在执行 DML 操作前,打开 PK、UK 的补偿日志。否则,数据传输会报日志不全的异常。
对于源端和目标端索引不一致、ETL 不符合预期和分区表迁移性能降低等问题,您需要添加以下补偿日志:
添加 DataBase 级别或 Table 级别的
supplemental_log_data_pk和supplemental_log_data_ui。添加具体列到补偿日志
添加源端和目标端中所有 PK 和 UK 涉及的列,以解决源端和目标端索引不一致的问题。
如果有 ETL,请添加 ETL 的列。解决 ETL 不符合预期的问题。
如果目标端是分区表,请添加分区列,以解决无法进行分区裁剪,导致写入性能降低的问题。
您可以执行下述语句,检查添加结果。
SELECT log_group_type FROM all_log_groups WHERE OWNER = '<schema_name>' AND table_name = '<table_name>';查询结果中包含 ALL COLUMN LOGGING,则检查通过。如果未包含,请查看
ALL_LOG_GROUP_COLUMNS表中,是否包含上述并集的所有列。添加具体列至补偿日志的方式,示例如下:
ALTER TABLE <table_name> ADD SUPPLEMENTAL LOG GROUP <table_name_group> (c1, c2) ALWAYS;
下表为数据迁移任务在运行过程中,如果进行 DDL 操作,可能会遇到的风险及解决方式。
操作 | 风险 | 解决方式 |
CREATE TABLE(且该表需要同步) | 如果该表存在目标端是分区表,源和目标端的索引不一致,需要进行 ETL 等情况,可能会影响数据迁移性能,导致 ETL 不符合预期。 | 必须开启 DataBase 级别的 PK、UK 补偿日志。手动添加涉及的列至补偿日志。 |
增加、删除和修改 PK/UK/分区列,或修改 ETL 列 | 会不满足启动时要求添加补偿日志的规则,可能导致数据不一致或数据迁移性能降低的问题。 | 根据上述补偿日志的规则进行相应的添加。 |
LogMiner Reader 根据以下两种方式进行检查。如果检查到补偿日志未打开,则退出。
DataBase 级别打开
supplemental_log_data_pk和supplemental_log_data_ui。执行下述命令,检查是否已打开补偿日志。如果查询结果均为
YES,表示已打开补偿日志。SELECT supplemental_log_data_pk, supplemental_log_data_ui FROM v$database;如果未打开,请执行下述操作:
执行下述语句,打开补偿日志。
ALTER DATABASE ADD supplemental log DATA(PRIMARY KEY, UNIQUE) columns;打开后,切换 2 次归档日志,并且启动任务前需要等待 5 分钟以上。如果是 Oracle RAC,多个实例交替切换。
ALTER SYSTEM SWITCH LOGFILE;Oracle RAC 的情况下,如果一个实例切换多次后,再切换到另外的实例,而非交替切换,则在定位起始拉取文件时,后切换的实例可能定位到开启补偿日志前的日志。
Table 级别打开
supplemental_log_data_pk和supplemental_log_data_ui。执行下述语句,确认 DataBase 级别的
supplemental_log_data_min是否已打开。SELECT supplemental_log_data_min FROM v$database;查询结果为
YES或IMPLICIT,表示已打开。执行下述语句,确认待同步表的表级别补偿日志是否打开。
SELECT log_group_type FROM all_log_groups WHERE OWNER = '<schema_name>' AND table_name = '<table_name>';每种补偿日志返回一行,结果中需要包含
ALL COLUMN LOGGING,或者PRIMARY KEY LOGGING和UNIQUE KEY LOGGING。如果未打开表级别的补偿日志,请执行下述语句。
ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE) COLUMNS;打开后,切换 2 次归档日志,并且启动任务前需要等待 5 分钟以上。如果是 Oracle RAC,多个实例交替切换。
ALTER SYSTEM SWITCH LOGFILE;
设置 Oracle 数据库的系统参数(可选)
建议您将 Oracle 数据库的系统参数 _log_parallelism_max 设置为 1,通常该系统参数默认为 2。
查询
_log_parallelism_max的值。您可以通过以下两种方式进行查询:方式一
SELECT NAM.KSPPINM,VAL.KSPPSTVL,NAM.KSPPDESC FROM SYS.X$KSPPI NAM,SYS.X$KSPPSV VAL WHERE NAM.INDX= VAL.INDX AND NAM.KSPPINM LIKE '_%' AND UPPER(NAM.KSPPINM) LIKE '%LOG_PARALLEL%';方式二
SELECT VALUE FROM v$parameter WHERE name = '_log_parallelism_max';
修改
_log_parallelism_max的值。进行修改时,分为以下两种情况:Oracle RAC 修改
ALTER SYSTEM SET "_log_parallelism_max" = 1 SID = '*' SCOPE = spfile;非 Oracle RAC 修改
ALTER SYSTEM SET "_log_parallelism_max" = 1 SCOPE = spfile;
Oracle 数据库 10G 版本修改
_log_parallelism_max参数时,如果报错write to SPFILE requested but no SPFILE specified at startup,请执行下述操作:CREATE SPFILE FROM PFILE; SHUTDOWN IMMEDIATE; STARTUP; SHOW PARAMETER SPFILE;修改系统参数
_log_parallelism_max后,请重启实例,切换 2 次归档日志,并且启动任务前需要等待 5 分钟以上。
操作步骤
登录 OceanBase 管理控制台,购买数据迁移任务。
详情请参见 购买数据迁移任务。
在 数据传输 > 数据迁移 页面,单击新购买的数据迁移任务后的 配置。

如果您需要引用已有的任务配置信息,可以单击 引用配置。详情请参见 引用数据迁移任务配置。
在 选择源和目标 页面,配置各项参数。
参数
描述
迁移任务名称
建议使用中文、数字和字母的组合。名称中不能包含空格,长度不能超过 64 个字符。
源端
如果您已新建 Oracle 数据源,请从下拉列表中进行选择。如果未新建,请单击下拉列表中的 新建数据源,在右侧对话框进行新建。参数详情请参见 新建 Oracle 数据源。
目标端
如果您已新建 OceanBase 数据库 Oracle 租户数据源,请从下拉列表中进行选择。如果未新建,请单击下拉列表中的 新建数据源,在右侧对话框进行新建。参数详情请参见 新建 OceanBase 数据源。
标签(可选)
单击文本框,在下拉列表中选择目标标签。您也可以单击 管理标签 进行新建、修改和删除。详情请参见 通过标签管理数据迁移任务。
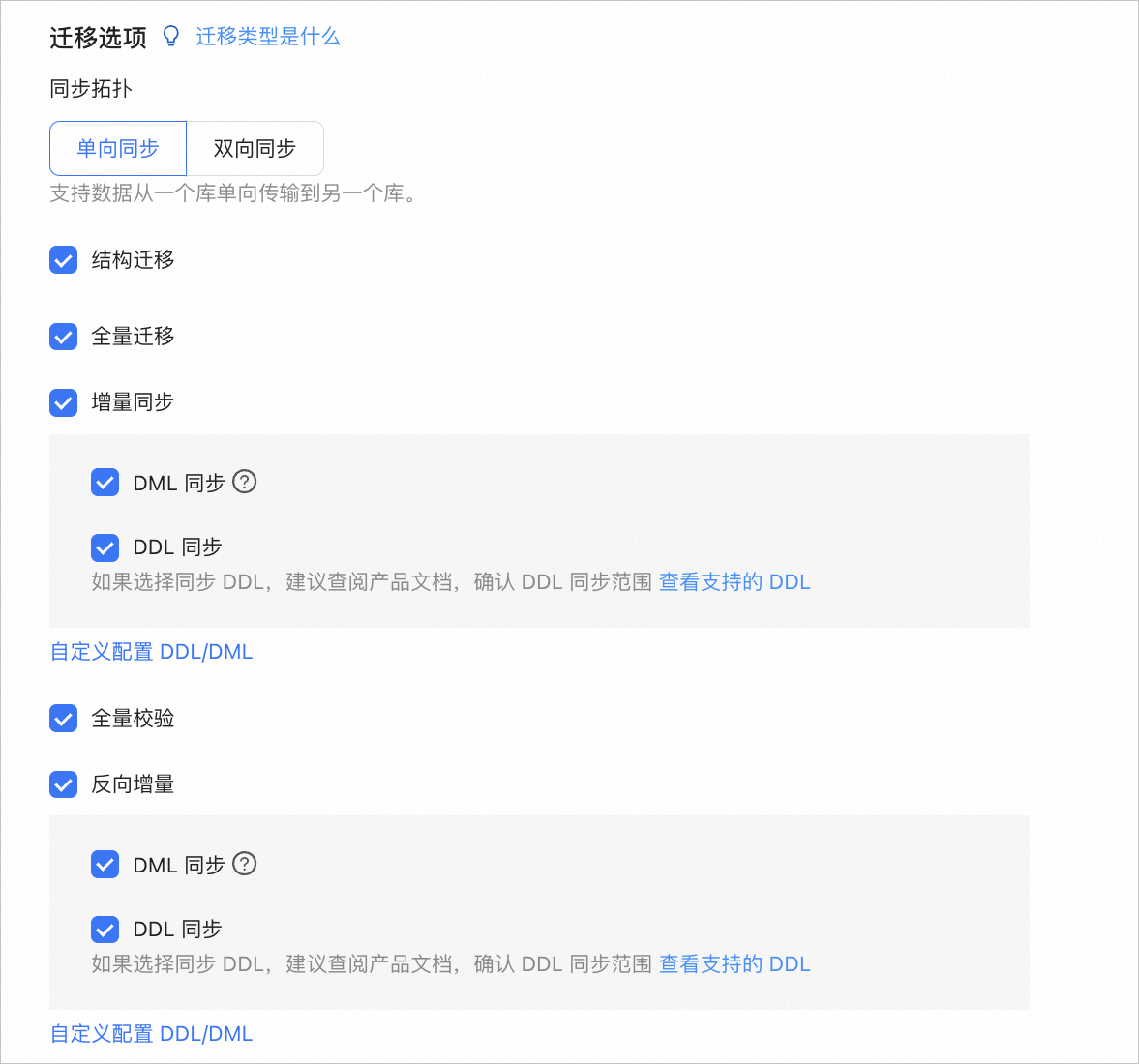
单击 下一步。在 选择迁移类型 页面,选择 同步拓扑 为 单向同步。
数据传输支持 单向同步 和 双向同步。本文为您介绍单向同步的操作,双向同步的详情请参见 配置双向同步任务。
选择当前数据迁移任务的迁移类型。
同步拓扑为单向同步时,支持的迁移类型包括 结构迁移、全量迁移、增量同步、全量校验 和 反向增量。
迁移类型
描述
结构迁移
结构迁移任务开始后,数据传输会将源库中的数据对象定义(表、索引、约束、注释和视图等)迁移到目标数据库中,并自动过滤临时表。
全量迁移
全量迁移任务开始后,数据传输会将源端库表的存量数据迁移至目标端数据库对应的表中。如果选择 全量迁移,建议您在迁移数据前,使用
GATHER_SCHEMA_STATS或GATHER_TABLE_STATS语句收集 Oracle 数据库的统计信息。增量同步
增量同步任务开始后,数据传输会同步源端数据库发生变化的数据(新增、修改或删除)至目标端数据库对应的表中。
增量同步 包括 DML 同步 和 DDL 同步,您可以根据需求进行自定义配置。详情请参见 自定义配置 DDL/DML。增量同步 的使用限制如下:
多表到单表的汇集场景,均不支持 DDL 同步。
如果您选择了 DDL 同步,当源端数据库发生数据传输不支持的同步 DDL 操作时,会存在数据迁移中断的风险。
如果 DDL 操作为新增列,请将该列的属性设置为 Null,否则会存在数据迁移中断的风险。
全量校验
在全量迁移完成、增量数据同步至目标端并与源端基本追平后,数据传输会自动发起一轮针对源端数据库配置的数据表和目标表的全量数据校验任务。
如果选择 全量校验,建议您在全量校验开始前,分别收集 Oracle 数据库和 OceanBase 数据库 Oracle 租户的统计信息。
如果您选择了 增量同步,且 DML 同步 选项中未选择所有的 DML,则数据传输不支持本场景下的全量数据校验。
反向增量
反向增量任务开始后,可以实时将业务切换后在目标端数据库产生的变更数据回流至源端数据库。
通常反向增量会复用增量同步的配置,您也可以根据实际需求进行自定义配置。
单击 下一步。在 选择迁移对象 页面,选择当前数据迁移任务的迁移对象。
您可以通过 指定对象 和 匹配规则 两个入口选择迁移对象。本文为您介绍通过 指定对象 方式选择迁移对象的具体操作,配置匹配规则的详情请参见 配置和修改匹配规则 中库到库的通配规则说明和配置方式。
重要待迁移的表名和其中的列名不能包含中文字符。
当数据库的库名或表名存在“$$”字符时,会影响数据迁移任务的创建。
如果您在 选择迁移类型 步骤已勾选 DDL 同步,建议通过匹配规则方式选择迁移对象,以确保所有符合迁移对象规则的新增对象都将被同步。如果您通过指定对象方式选择迁移对象,则新增对象或重命名后的对象将不会被同步。
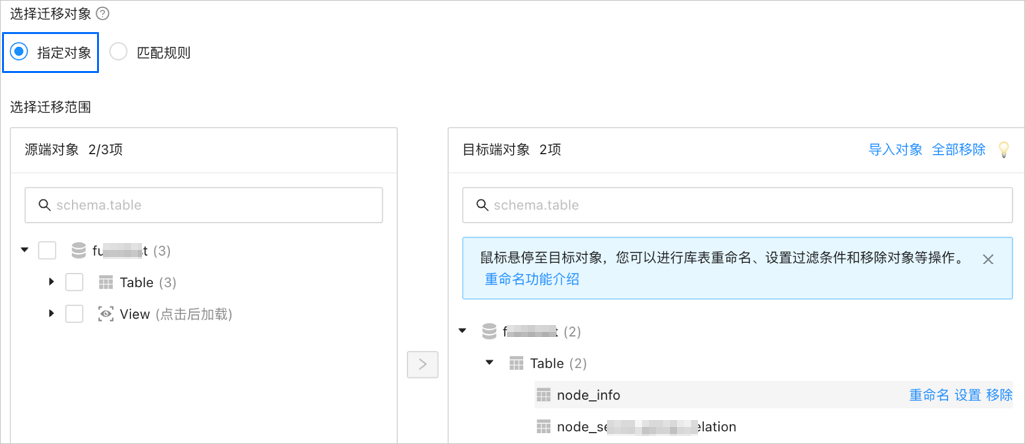
在 选择迁移对象 区域,选中 指定对象。
在 选择迁移范围 区域的 源端对象 列表选中需要迁移的对象。您可以选择一个或多个库的表、视图作为迁移对象。
单击 >,将其添加至 目标端对象 列表中。
数据传输支持通过文本导入对象,并支持对目标端对象进行重命名、设置行过滤、查看列信息,以及移除单个或全部迁移对象等操作。
说明通过 匹配规则 方式选择迁移对象时,重命名能力由匹配规则语法覆盖,操作处仅支持设置过滤条件。详情请参见 配置和修改匹配规则。
操作
描述
导入对象
在选择区域的右侧列表中,单击右上角的 导入对象。
在对话框中,单击 确定。
重要导入会覆盖之前的操作选择,请谨慎操作。
在 导入迁移对象 对话框中,导入需要迁移的对象。
您可以通过导入 CSV 文件的方式进行库表重命名、设置行过滤条件等操作。详情请参见 下载和导入迁移对象配置。
单击 检验合法性。
完成迁移对象导入后,请先检验合法性。目前暂不支持列字段映射。
通过检验后,单击 确定。
重命名
数据传输支持重命名迁移对象的名称,详情请参见 数据库库表重命名。
设置
数据传输支持
WHERE条件实现行过滤,详情请参见 SQL 条件过滤数据。您还可以在 查看列 区域,查看迁移对象的列信息。
移除/全部移除
数据传输支持在数据映射时,对暂时选中到目标端的单个或多个对象进行移除操作。
移除单个迁移对象
在选择区域的右侧列表中,鼠标悬停至目标对象,单击显示的 移除,即可移除该迁移对象。
移除全部迁移对象
在选择区域的右侧列表中,单击右上角的 全部移除。在对话框中,单击 确定,即可移除全部迁移对象。
单击 下一步。在 迁移选项 页面,配置各项参数。
全量迁移
在 选择迁移类型 页面,选中 单向同步 > 全量迁移,才会显示下述参数。
参数
描述
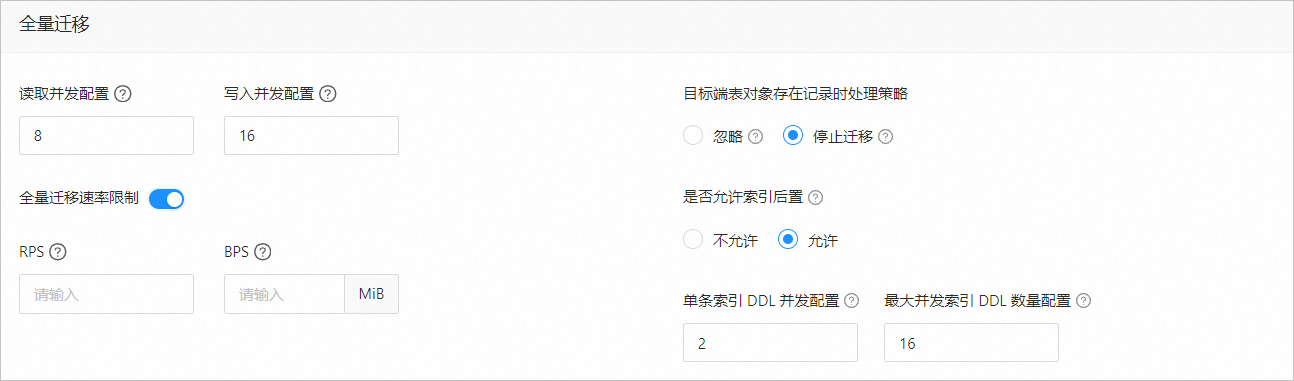
读取并发配置
该参数用于配置全量迁移阶段从源端读取数据的并发数,最大限制为 512 并发数过高可能会造成源端压力过大,影响业务。
写入并发配置
该参数用于配置全量迁移阶段往目标端写入数据的并发数,最大限制为 512。并发数过高可能会造成目标端压力过大,影响业务。
全量迁移速率限制
您可以根据实际需求决定是否开启全量迁移速率限制。如果开启,请设置 RPS(全量迁移阶段每秒最多可以迁移至目标端的数据行数的最大值限制)和 BPS(全量迁移阶段每秒最多可以迁移至目标端的数据量的最大值限制)。
说明此处设置的 RPS 和 BPS 仅作为限速限流能力,全量迁移实际可以达到的性能受限于源端、目标端、实例规格配置等因素的影响。
目标端表对象存在记录时处理策略
处理策略包括 忽略 和 停止迁移:
选择 忽略:当目标端表对象存在数据时,如果原数据与写入数据冲突,数据传输采用将冲突数据记录日志,保留原数据不变的策略进行数据写入。
重要选择 忽略,全量校验将使用 IN 模式拉取数据,无法校验目标端存在源端没有的数据的场景,并且校验性能会有一定程度降级。
选择默认值 停止迁移:当目标端表对象存在数据时,全量迁移会报错不允许迁移,请处理好目标端数据后再继续迁移。
重要如果出错后单击恢复,数据传输将忽略该配置选项,继续迁移表数据,请谨慎操作。
是否允许索引后置
您可以设置是否允许全量数据迁移完成后再创建索引,索引后置功能能够缩短全量迁移耗时。选择索引后置的注意事项,请参见表格下方的说明。
重要在 选择迁移类型 页面同时选中 结构迁移 和 全量迁移,才会显示该参数。
仅非唯一键索引支持后置创建。
执行索引时,如果目标端 OceanBase 数据库遇到下述报错,数据传输会进行忽略,默认索引创建成功,不会再重复创建。
OceanBase 数据库 MySQL 兼容模式报错
Duplicate key name。OceanBase 数据库 Oracle 兼容模式报错
name is already used by an existing object。
当目标端为 OceanBase 数据库,并且此处选择 允许 后,请进行下述配置:
单条索引 DDL 并发配置:并行度越高,资源消耗越大,迁移速度越快。
最大并发索引 DDL 数量配置:同一时刻,系统调用的后置索引 DDL 数量的最大值限制。
允许索引后置的情况下,建议您根据 OceanBase 数据库的硬件条件和当前业务流量情况,通过黑屏客户端工具调整以下业务租户参数。
// 文件内存缓冲区限制 alter system set _temporary_file_io_area_size = '10' tenant = 'xxx'; // V4.x 关闭限流 alter system set sys_bkgd_net_percentage = 100;增量同步
在 选择迁移类型 页面,选中 单向同步 > 增量同步,才会显示下述参数。
参数
描述
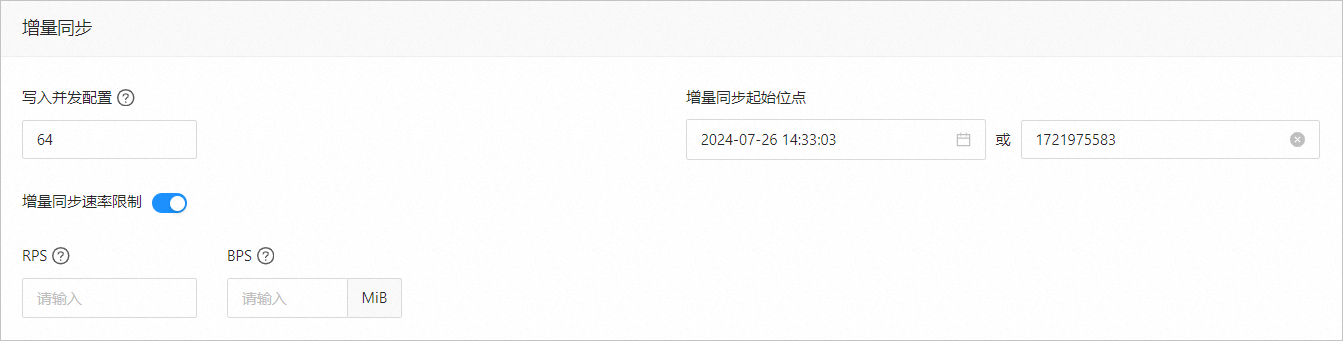
写入并发配置
该参数用于配置增量同步阶段往目标端写入数据的并发数,最大限制为 512。并发数过高可能会造成目标端压力过大,影响业务。
增量同步速率限制
您可以根据实际需求决定是否开启增量同步速率限制。如果开启,请设置 RPS(增量同步阶段每秒最多可以同步至目标端的数据行数的最大值限制)和 BPS(增量同步阶段每秒最多可以同步至目标端的数据量的最大值限制)。
说明此处设置的 RPS 和 BPS 仅作为限速限流能力,增量同步实际可以达到的性能受限于源端、目标端、实例规格配置等因素的影响。
增量同步起始位点
如果选择迁移类型时已选择 全量迁移,则不显示该参数。
如果选择迁移类型时未选择 全量迁移,但选择了 增量同步,请在此处指定迁移某个时间节点之后的数据,默认为当前系统时间。详情请参见 设置增量同步位点。
反向增量
在 选择迁移类型 页面,选中 单向同步 > 反向增量,才会显示该区域的参数。反向增量的配置参数默认 复用增量同步配置。
您也可以取消复用增量同步配置,根据实际需求进行配置。
参数
描述
写入并发配置
该参数用于配置反向增量阶段往源端写入数据的并发数,最大限制为 512。并发数过高可能会造成源端压力过大,影响业务。
反向增量速率限制
您可以根据实际需求决定是否开启反向增量速率限制。如果开启,请设置 RPS(反向增量同步阶段每秒最多可以同步至源端的数据行数的最大值限制)和 BPS(反向增量同步阶段每秒最多可以同步至源端的数据量的最大值限制)。
说明此处设置的 RPS 和 BPS 仅作为限速限流能力,反向增量同步实际可以达到的性能受限于源端、目标端、实例规格配置等因素的影响。
增量同步起始位点
如果选择迁移类型时已选择 全量迁移,则不显示该参数。
如果选择迁移类型时未选择 全量迁移,但选择了 增量同步,则默认以正向切换(如有)为准,不支持修改。
高级选项

参数
描述
字符编码与长度定义选项
在 选择迁移类型 页面选中 结构迁移,且源端和目标端的字符集不一致时,才会显示该参数。
说明源端和目标端的字符集不一致(例如,源端为 GBK,目标端为 UTF-8)时,可能会发生字段截断,数据不一致的情况。
当您选择 自动放大目标端字段长度,即 N BYTE → 1.5N BYTE 时,如果转换后的长度超过最大长度限制,则转换后的长度为最大长度限制。
无非空唯一键表增加隐藏列
迁移 Oracle 数据库的数据至 OceanBase 数据库 Oracle 租户时,您需要配置是否为无非空唯一键表增加隐藏列。详情请参见 数据迁移服务隐藏列机制说明。
目标端表对象存储类型
当目标端 OceanBase 数据库 Oracle 租户为 V4.3.0 及之后版本,并且在 选择迁移类型 页面,选中 结构迁移 或 增量同步 > DDL 同步,才会显示该区域的参数。
目标端表对象存储类型包括 默认、行存、列存 和 行列混存,该配置用于确定结构迁移或增量同步时目标端表对象的存储类型,详情请参见 default_table_store_format。
说明默认 选项是根据目标端参数配置自适应其他选项,是结构迁移的表对象或增量 DDL 的新增表对象根据设置的存储类型写入对应的结构。
单击 预检查,系统对数据迁移任务进行预检查。
在 预检查 环节,数据传输会检查数据库用户的读写权限、数据库的网络连接等是否符合要求。全部检查任务均通过后才能启动数据迁移任务。如果预检查报错:
您可以在排查并处理问题后,重新执行预检查,直至预检查成功。
您也可以单击错误预检查项操作列中的 跳过,会弹出对话框提示您跳过本操作的具体影响,确认可以跳过后,请单击对话框中的 确定。
预检查成功后,单击 启动任务。
如果您暂时无需启动任务,请单击 保存。后续您只能在 迁移任务列表 页面手动启动任务或通过批量操作启动任务。批量操作的详情请参见 批量操作数据迁移任务。
数据传输支持在数据迁移任务运行过程中修改迁移对象及其行过滤条件,详情请参见 查看和修改迁移对象及其过滤条件。数据迁移任务启动后,会根据所选择的迁移类型依次执行,详情请参见 查看迁移详情。