Log Service支援採集Nginx日誌,並進行多維度分析。本文介紹分析網站訪問情況、診斷及調優網站和重要情境警示的分析案例。
前提條件
已採集Nginx訪問日誌,詳情請參見使用Nginx配置模式採集文本日誌。
在日誌採集設定精靈中,已根據日誌欄位自動產生索引,如果您要修改索引,詳情請參見建立索引。
背景資訊
Nginx是一款主流的網站伺服器,當您選用Nginx搭建網站時,Nginx日誌是營運網站的重要訊息。傳統模式下,需使用CNZZ等方式,在前端頁面插入JS,記錄訪問請求。或者利用Realtime Compute、離線計算分析Nginx訪問日誌,此方式還需要搭建環境,在即時性以及分析靈活性上難以平衡。
Log Service支援通過資料接入嚮導一站式採集Nginx日誌,並為Nginx日誌建立索引和儀錶盤。nginx_Nginx訪問日誌儀錶盤包括來源IP分布、請求狀態佔比、要求方法佔比、訪問PV/UV統計、流入流出流量統計、請求UA佔比、前十訪問來源、訪問前十地址和請求時間前十地址等資訊,全方位展示網站訪問情況。您還可以使用Log Service的查詢分析語句,分析網站的延時情況,及時調優網站。針對效能問題、伺服器錯誤、流量變化等重要情境,您還可以設定警示,當滿足警示條件時給您發送警示資訊。
分析網站訪問情況
在Project列表地區,單擊目標Project。

在中,單擊目標LogStore左側的>。
在可視化儀錶盤中,單擊nginx_Nginx訪問日誌。
nginx_Nginx訪問日誌儀錶盤中的重要圖表說明如下所示:
來源IP分布圖展示最近一天訪問IP地址的來源情況,所關聯的查詢分析語句如下所示:
* | select count(1) as c, ip_to_province(remote_addr) as address group by address limit 100請求狀態佔比圖展示最近一天各HTTP狀態代碼的佔比情況,所關聯的查詢分析語句如下所示:
* | select count(1) as pv, status group by status
要求方法佔比圖展示最近一天各要求方法的佔比情況,所關聯的查詢分析語句如下所示:
* | select count(1) as pv ,request_method group by request_method
請求UA佔比圖展示最近一天各種瀏覽器的佔比情況,所關聯的查詢分析語句如下所示:
* | select count(1) as pv, case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end as http_user_agent group by case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end order by pv desc limit 10
前十訪問來源圖展示最近一天PV數最多的前十個訪問來源頁面,所關聯的查詢分析語句如下所示:
* | select count(1) as pv , http_referer group by http_referer order by pv desc limit 10
流入流出流量統計圖展示最近一天流量的流入和流出情況,所關聯的查詢分析語句如下所示:
* | select sum(body_bytes_sent) as net_out, sum(request_length) as net_in ,date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 10000
訪問PV/UV統計圖展示最近一天內的PV數和UV數,所關聯的查詢分析語句如下所示:
*| select approx_distinct(remote_addr) as uv ,count(1) as pv , date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 1000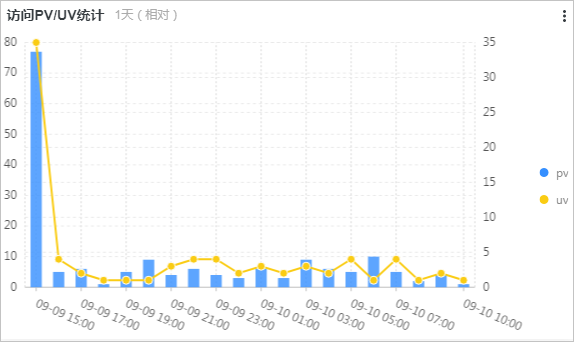
PV預測圖預測未來4小時的PV數,所關聯的查詢分析語句如下所示:
* | select ts_predicate_simple(stamp, value, 6, 1, 'sum') from (select __time__ - __time__ % 60 as stamp, COUNT(1) as value from log GROUP BY stamp order by stamp) LIMIT 1000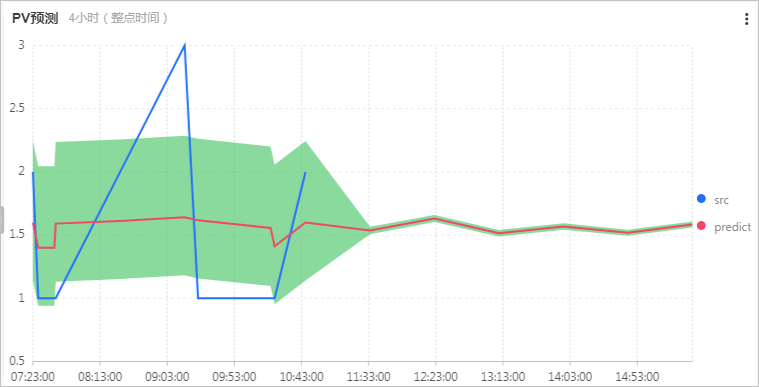
訪問前十地址圖展示最近一天PV數最多的前十個訪問地址,所關聯的查詢分析語句如下所示:
* | select count(1) as pv, split_part(request_uri,'?',1) as path group by path order by pv desc limit 10
診斷及調優網站
在網站運行過程中,還需關注請求延時問題,例如處理請求延時情況如何、哪些頁面的延時較大等。您可以自訂查詢分析語句分析延遲情況,相關案例如下所示,操作步驟可參見查詢與分析快速指引。
計算每5分鐘請求的平均延時和最大延時,從整體瞭解延時情況。
* | select from_unixtime(__time__ -__time__% 300) as time, avg(request_time) as avg_latency , max(request_time) as max_latency group by __time__ -__time__% 300統計最大延時對應的請求頁面,進一步最佳化頁面響應。
* | select from_unixtime(__time__ - __time__% 60) , max_by(request_uri,request_time) group by __time__ - __time__%60統計分析網站所有請求的延時分布,將延時分布分成10個組,分析每個延時區間的請求個數。
* |select numeric_histogram(10,request_time)計算最大的十個延時及其對應值。
* | select max(request_time,10)對延時最大的頁面進行調優。
例如/url2頁面的訪問延時最大,需要對/url2頁面進行調優,則需計算/url2頁面的訪問PV、UV、各種要求方法次數、各種請求狀態次數、各種瀏覽器次數、平均延時和最大延時。
request_uri:"/url2" | select count(1) as pv, approx_distinct(remote_addr) as uv, histogram(method) as method_pv, histogram(status) as status_pv, histogram(user_agent) as user_agent_pv, avg(request_time) as avg_latency, max(request_time) as max_latency* | select diff [1] as today, round((diff [3] -1.0) * 100, 2) as growth FROM ( SELECT compare(pv, 86400) as diff FROM ( SELECT COUNT(1) as pv FROM log ) )統計訪問PV的昨日同比。
* | select t, diff [1] as today, diff [2] as yestoday, diff [3] as percentage from( select t, compare(pv, 86400) as diff from ( select count(1) as pv, date_format(from_unixtime(__time__), '%H:%i') as t from log group by t limit 10000 ) group by t order by t limit 10000 )
警示
針對效能問題、網站錯誤、流量急跌或暴漲等情況,您可以設定查詢分析語句,並設定警示,操作步驟請參見設定警示。
錯誤警示
在網站運行過程中,一般需關注500錯誤,即伺服器錯誤。您可以使用如下查詢分析語句計算單位時間內的錯誤數c,並將警示觸發條件設定為c > 0。
status:500 | select count(1) as c說明對於一些業務壓力較大的服務,偶爾出現幾個500錯誤是正常現象。針對此情況,您可以在建立警示時,設定觸發通知門檻為2,即只有連續2次檢查都符合條件才產生警示。

效能警示
如果在伺服器運行過程出現延遲增大情況,您可以針對延遲建立警示。例如您可以使用如下查詢分析語句分析
/adduser介面所有要求方法為Post的寫請求延時,並將警示觸發條件設定為 l > 300000,即當延時平均值超過300ms則產生警示。Method:Post and URL:"/adduser" | select avg(Latency) as l使用平均值建立警示的方式比較簡單,但會造成一些個體請求延時被平均,無法反映真實情況。針對此問題,您可以使用數學統計中的百分數(例如99%最大延時)來作為警示觸發條件,例如使用如下查詢分析語句計算99%分位的延時大小。
Method:Post and URL:"/adduser" | select approx_percentile(Latency, 0.99) as p99在監控情境中,您可以使用如下查詢分析語句計算一天視窗(1440分鐘)內各分鐘的平均延時大小、50%分位的延時大小和90%分位的延時大小。
* | select avg(Latency) as l, approx_percentile(Latency, 0.5) as p50, approx_percentile(Latency, 0.99) as p99, date_trunc('minute', time) as t group by t order by t desc limit 1440
流量急跌或暴漲警示
如果在網站運行過程中出現流量急跌或暴漲情況,一般屬於不正常現象。針對此問題,您可以計算流量大小,並設定警示。一般根據如下參考資訊反映流量的急跌或暴漲情況:
上一個時間視窗:環比上一個時間段。
上一天該時間段的視窗:環比昨天。
上一周該時間段的視窗:環比上周。
本案例以第一種情況為例,計算流量大小的變動率,日誌查詢範圍為5分鐘。
定義一個計算視窗。
定義一個1分鐘的視窗,計算該分鐘內的流量大小。
* | select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15從分析結果中看,每個視窗內的平均流量是均勻的。

計算視窗內的差異值。
計算最大值或最小值與平均值的變動率,此處以最大值max_ratio為例。
本樣本中計算結果max_ratio為1.02,您可以定義警示條件為max_ratio > 1.5(變動率超過50%)則警示。
* | select max(inflow)/avg(inflow) as max_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)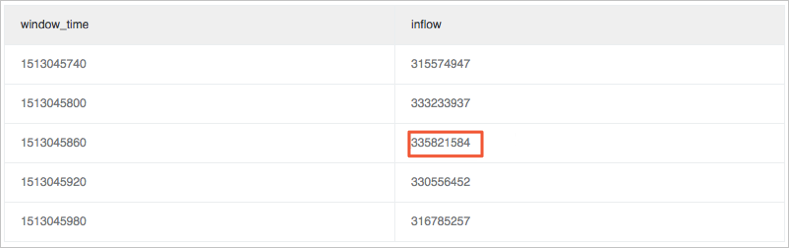
計算最近值變動率,查看最新的數值是否有波動或已恢複。
通過max_by方法擷取視窗中的最大流量進行判斷,本案例中的計算結果latest_ratio為0.97。
* | select max_by(inflow, window_time)/1.0/avg(inflow) as latest_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)說明max_byFunction Compute結果為字元類型,需強制轉換成數字類型。 如果您要計算變化相對率,可以用(1.0-max_by(inflow, window_time)/1.0/avg(inflow)) as latest_ratio。

計算波動率,即計算當前視窗值與上個視窗值的變化值。
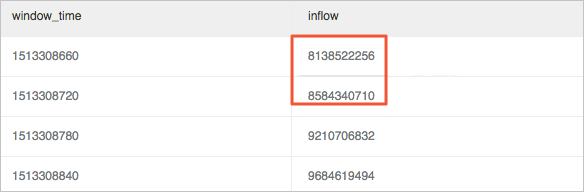
使用視窗函數lag提取當前流量inflow與上一個周期流量inflow "lag(inflow, 1, inflow)over() "進行差值計算,併除以當前流量inflow擷取變動率。例如11點39分流量有一個較大的降低,視窗之間變動率為40%以上。
說明如果要定義一個絕對變動率,可以使用abs函數對計算結果進行統一。
* | select (inflow- lag(inflow, 1, inflow)over() )*1.0/inflow as diff, from_unixtime(window_time) from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)