RDS PostgreSQL支援pgvector外掛程式,提供了一個新的資料類型,能夠方便快捷地對高維向量進行檢索,是一款功能強大的向量相似性匹配搜尋外掛程式。
背景
RDS PostgreSQL支援pgvector外掛程式,能夠儲存向量類型資料,並實現向量相似性匹配,為AI產品提供底層資料支援。
pgvector主要提供如下能力:
支援資料類型vector,能夠對向量資料存放區以及查詢。
支援精確和近似最近鄰搜尋(ANN,Approximate Nearest Neighbor),其距離或相似性的度量方法包括歐氏距離(L2)、餘弦相似性(Cosine)以及內積運算(Inner Product)。索引構建支援HNSW索引、並行索引IVFFlat、向量的逐元素乘法、L1距離函數以及求和彙總。
最大支援建立16000維度向量,最大支援對2000維度向量建立索引。
相關概念及實現原理
嵌入
嵌入(embedding)是指將高維資料對應為低維表示的過程。在機器學習和自然語言處理中,嵌入通常用於將離散的符號或對象表示為連續的向量空間中的點。
在自然語言處理中,詞嵌入(word embedding)是一種常見的技術,它將單詞映射到實數向量,以便電腦可以更好地理解和處理文本。通過詞嵌入,單詞之間的語義和文法關係可以在向量空間中得到反映。
實現原理
嵌入可以將文本、映像、音視頻等資訊在多個維度上抽象,轉化為向量資料。
pgvector提供vector資料類型,使RDS PostgreSQL資料庫具備了儲存向量資料的能力。
pgvector可以對儲存的向量資料進行精確搜尋以及近似最近鄰搜尋。
假設需要將蘋果、香蕉、貓三個Object Storage Service到資料庫中,並使用pgvector計算相似性,實現步驟如下:
先使用嵌入,將蘋果、香蕉、貓三個對象轉化為向量,假設以二維嵌入為例,結果如下:
蘋果:embedding[1,1] 香蕉:embedding[1.2,0.8] 貓:embedding[6,0.4]將嵌入轉化的向量資料存放區到資料庫中。如何將二維向量資料存放區到資料庫中,具體請參見使用樣本。
在二維平面中,三個對象分布如下:
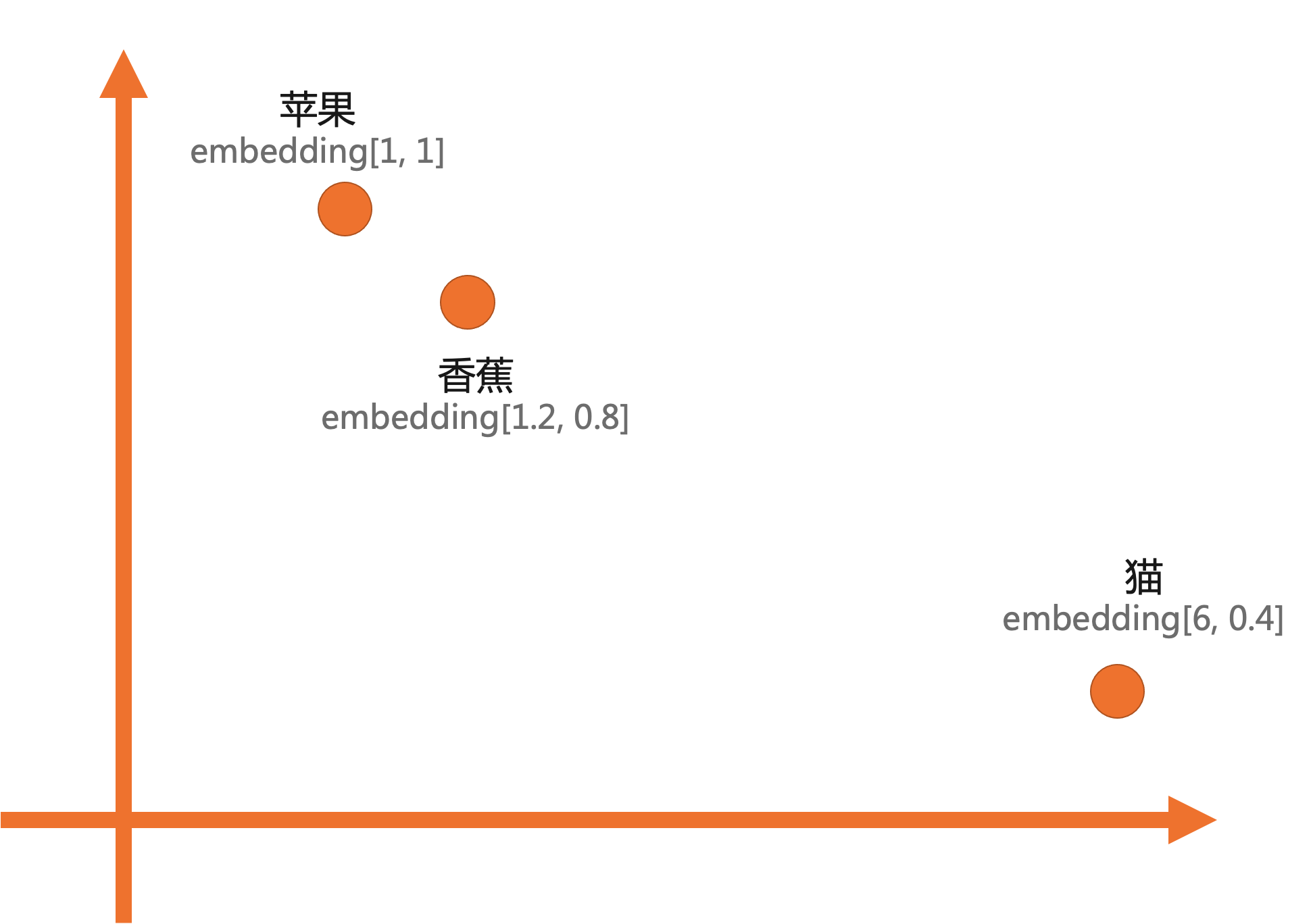
對於蘋果和香蕉,都屬於水果,因此在二維座標視圖中二者的距離更接近,而香蕉與貓屬於兩個完全不同的物種,因此距離較遠。
可以對水果的屬性進一步細化,比如水果的顏色,產地,味道等,每一個屬性都是一個維度,也就代表了維度越高,對於該資訊的分類就更細,也就越有可能搜尋出更精確的結果。
應用情境
儲存向量類型資料。
向量相似性匹配搜尋。
前提條件
RDS PostgreSQL執行個體需滿足以下要求:
執行個體大版本為PostgreSQL 14或以上。
執行個體核心小版本為20230430或以上。對於RDS PostgreSQL 17版本的執行個體,其核心的小版本應為20241030或以上。
已建立RDS PostgreSQL高許可權帳號,如何建立高許可權帳號請參見建立帳號。
外掛程式管理
通過控制台管理外掛程式
安裝外掛程式
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側導覽列單擊外掛程式管理。
在外掛程式市場頁面中,請向下滾動以找到vector外掛程式,並單擊安裝。

您也可以在管理外掛程式頁面,搜尋vector外掛程式,並單擊操作列的安裝。
在彈出的視窗中選擇目標資料庫和高許可權帳號後,單擊安裝,將外掛程式安裝至目標資料庫。
當執行個體的狀態由維護執行個體中變為運行中時,表示外掛程式已成功安裝。
更新和卸載外掛程式
在管理外掛程式頁面的已安裝外掛程式頁簽,單擊目標外掛程式操作列的升級版本,將外掛程式升級到最新版本。
說明如果操作列沒有升級版本按鈕,表示該外掛程式的版本已是最新。
在管理外掛程式頁面的已安裝外掛程式頁簽,單擊目標外掛程式操作列的卸載,卸載目標外掛程式。
通過SQL命令管理外掛程式
僅高許可權帳號可以執行以下命令。如何建立高許可權帳號請參見建立帳號。
建立外掛程式
CREATE EXTENSION IF NOT EXISTS vector;刪除外掛程式
DROP EXTENSION vector;更新外掛程式
ALTER EXTENSION vector UPDATE [ TO new_version ]說明new_version配置為pgvector的版本,pgvector的最新版本號碼及相關特性,請參見pgvector官方文檔。
使用樣本
如下僅是對pgvector的簡單使用樣本,更多使用方法,請參見pgvector官方文檔。
在目錄資料庫中,使用具備建表許可權的使用者建立一個儲存vector類型的表(items),用於儲存embeddings。
CREATE TABLE items ( id bigserial PRIMARY KEY, item text, embedding vector(2) );說明上述樣本中,以二維為例,pgvector最大支援建立16000維度向量。
將向量資料插入表中。
INSERT INTO items (item, embedding) VALUES ('蘋果', '[1, 1]'), ('香蕉', '[1.2, 0.8]'), ('貓', '[6, 0.4]');使用餘弦相似性操作符
<=>計算香蕉與蘋果、貓之間的相似性。SELECT item, embedding <=> '[1.2, 0.8]' AS cosine_distance FROM items ORDER BY cosine_distance;說明在上述樣本中,直接使用
<=>操作符計算餘弦距離,距離越小,相似性越高。您也可以使用歐氏距離操作符
<->或內積運算操作符<#>計算相似性。
結果樣本:
item | cosine_distance ------+---------------------- 香蕉 | 0 蘋果 | 0.019419362524530137 貓 | 0.13289443670962842在上述結果中:
香蕉結果為 0,表示完全符合(距離為0)。
蘋果的結果為 0.019,表示蘋果與香蕉距離很近,相似性很高。
貓的結果為 0.133,表示貓與香蕉距離較遠,相似性較低。
說明您可以在實際業務中設定一個合適的相似性閾值,將相似性較低的結果直接排除。
為了提高相似性查詢的效率,pgvector支援為向量資料建立索引,執行如下語句,為embedding欄位建立索引。
建立HNSW索引
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64);參數說明:
參數
說明
m
表示構建HNSW索引時,每層中每個節點的最大鄰近節點數目。
該值越大,圖的稠密度越高,通常會導致召回率的提高,同時構建和查詢所需的時間也相應增加。
ef_construction
表示構建HNSW索引時,候選集的大小,即搜尋在構建過程中保留多少候選節點用於選擇最優串連。
該值越大,通常召回率也越高,但構建和查詢所需的時間也相應增加。
建立IVF索引
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);參數說明:
參數/取值
說明
items
添加索引的表名。
embedding
添加索引的列名。
vector_cosine_ops
向量索引方法中指定的存取方法。
餘弦相似性搜尋,使用
vector_cosine_ops。歐氏距離,使用
vector_l2_ops。內積相似性,使用
vector_ip_ops。
lists = 100
lists參數表示將資料集分成的列表數,該值越大,表示資料集被分割得越多,每個子集的大小相對較小,索引查詢速度越快。但隨著lists值的增加,查詢的召回率可能會下降。
說明召回率是指在資訊檢索或分類任務中,正確檢索或分類的樣本數量與所有相關樣本數量之比。召回率衡量了系統能夠找到所有相關樣本的能力,它是一個重要的評估指標。
構建索引需要的記憶體較多,當lists參數值超過2000時,會直接報錯
ERROR: memory required is xxx MB, maintenance_work_mem is xxx MB,您需要設定更大的maintenance_work_mem才能為向量資料建立索引,該值設定過大執行個體會有很高的OOM風險。設定方法,請參見設定執行個體參數。您需要通過調整lists參數的值,在查詢速度和召回率之間進行權衡,以滿足具體應用情境的需求。
您可以使用如下兩種方式之一來設定ivfflat.probes參數,指定在索引中搜尋的列表數量,通過增加ivfflat.probes的值,將搜尋更多的列表,可以提高查詢結果的召回率,即找到更多相關的結果。
會話層級
SET ivfflat.probes = 10;事務層級
BEGIN; SET LOCAL ivfflat.probes = 10; SELECT ... COMMIT;
ivfflat.probes的值越大,查詢結果的召回率越高,但是查詢的速度會降低,根據具體的應用需求和資料集的特性,lists和ivfflat.probes的值可能需要進行調整以獲得最佳的查詢效能和召回率。
說明如果ivfflat.probes的值與建立索引時指定的lists值相等時,查詢將會忽略向量索引並進行全表掃描。在這種情況下,索引不會被使用,而是直接對整個表進行搜尋,可能會降低查詢效能。
效能資料
為向量資料設定索引時,需要根據實際業務資料量及應用情境,在查詢速度和召回率之間進行權衡。相關效能測試請參見: