隨著ChatGPT的問世,人們開始認識到大語言模型(LLM,Large language model)和產生式人工智慧在多個領域的潛力,如文稿撰寫、映像產生、代碼最佳化和資訊搜尋等。LLM已成為個人和企業的得力助手,並朝著超級應用的方向發展,引領著新的生態系統。本文介紹如何基於RDS PostgreSQL構建專屬ChatBot。
背景
越來越多的企業和個人希望能夠利用LLM和產生式人工智慧來構建專註於其特定領域的具備AI能力的產品。目前,大語言模型在處理通用問題方面表現較好,但由於訓練語料和大模型的產生限制,對於專業知識和時效性方面存在一些局限。在資訊時代,企業的知識庫更新頻率越來越高,而企業所擁有的垂直領域知識庫(如文檔、映像、音視頻等)可能是未公開或不可公開的。因此,對於企業而言,如果想在大語言模型的基礎上構建屬於特定垂直領域的AI產品,就需要不斷將自身的知識庫輸入到大語言模型中進行訓練。
目前有兩種常見的方法實現:
微調(Fine-tuning):通過提供新的資料集對已有模型的權重進行微調,不斷更新輸入以調整輸出,以達到所需的結果。這適用於資料集規模不大或針對特定類型任務或風格進行訓練,但訓練成本和價格較高。
提示調整(Prompt-tuning):通過調整輸入提示而非修改模型權重,從而實現調整輸出的目的。相較於微調,提示調整具有較低的計算成本,需要的資源和訓練時間也較少,同時更加靈活。
基於RDS PostgreSQL構建ChatBot的優勢如下:
藉助RDS PostgreSQL的pgvector外掛程式,可以將即時內容或垂直領域的專業知識和內容轉化為向量化的embedding表示,並儲存在RDS PostgreSQL中,以實現高效的向量化檢索,從而提高私域內容的問答準確性。
作為先進的開源OLTP引擎,RDS PostgreSQL能夠同時完成線上使用者資料互動和資料存放區的任務,例如,它可以用於處理對話的互動記錄、記錄、對話時間等功能。RDS PostgreSQL一專多長的特性使得私域業務的構建更加簡單,架構也更加輕便。
pgvector外掛程式目前已經在開發人員社區以及基於PostgreSQL的開來源資料庫中得到廣泛應用,同時ChatGPT Retrieval Plugin等工具也及時適配了PostgreSQL。這表明RDS PostgreSQL在向量化檢索領域具有良好的生態支援和廣泛的應用基礎,為使用者提供了豐富的工具和資源。
本文將以RDS PostgreSQL提供的開源向量索引外掛程式(pgvector)和OpenAI提供的embedding能力為例,展示如何構建專屬的ChatBot。
前提條件
已建立RDS PostgreSQL執行個體且滿足以下條件:
執行個體大版本為PostgreSQL 14或以上。
執行個體核心小版本為20230430或以上。
本文展示的專屬的ChatBot基於RDS PostgreSQL提供的開源外掛程式pgvector,請確保已完全瞭解其相關用法及基本概念,更多資訊,請參見高維向量相似性搜尋(pgvector)。
本文展示的專屬的ChatBot使用了OpenAI的相關能力,請確保您具備
Secret API Key,並且您的網路環境可以使用OpenAI,本文展示的程式碼範例均部署在新加坡地區的ECS中。本文範例程式碼使用的Python語言,請確保已具備Python開發環境,本樣本使用的Python版本為
3.11.4,使用的開發工具為PyCharm 2023.1.2。
相關概念
嵌入
嵌入(embedding)是指將高維資料對應為低維表示的過程。在機器學習和自然語言處理中,嵌入通常用於將離散的符號或對象表示為連續的向量空間中的點。
在自然語言處理中,詞嵌入(word embedding)是一種常見的技術,它將單詞映射到實數向量,以便電腦可以更好地理解和處理文本。通過詞嵌入,單詞之間的語義和文法關係可以在向量空間中得到反映。
OpenAI提供Embeddings能力。
實現原理
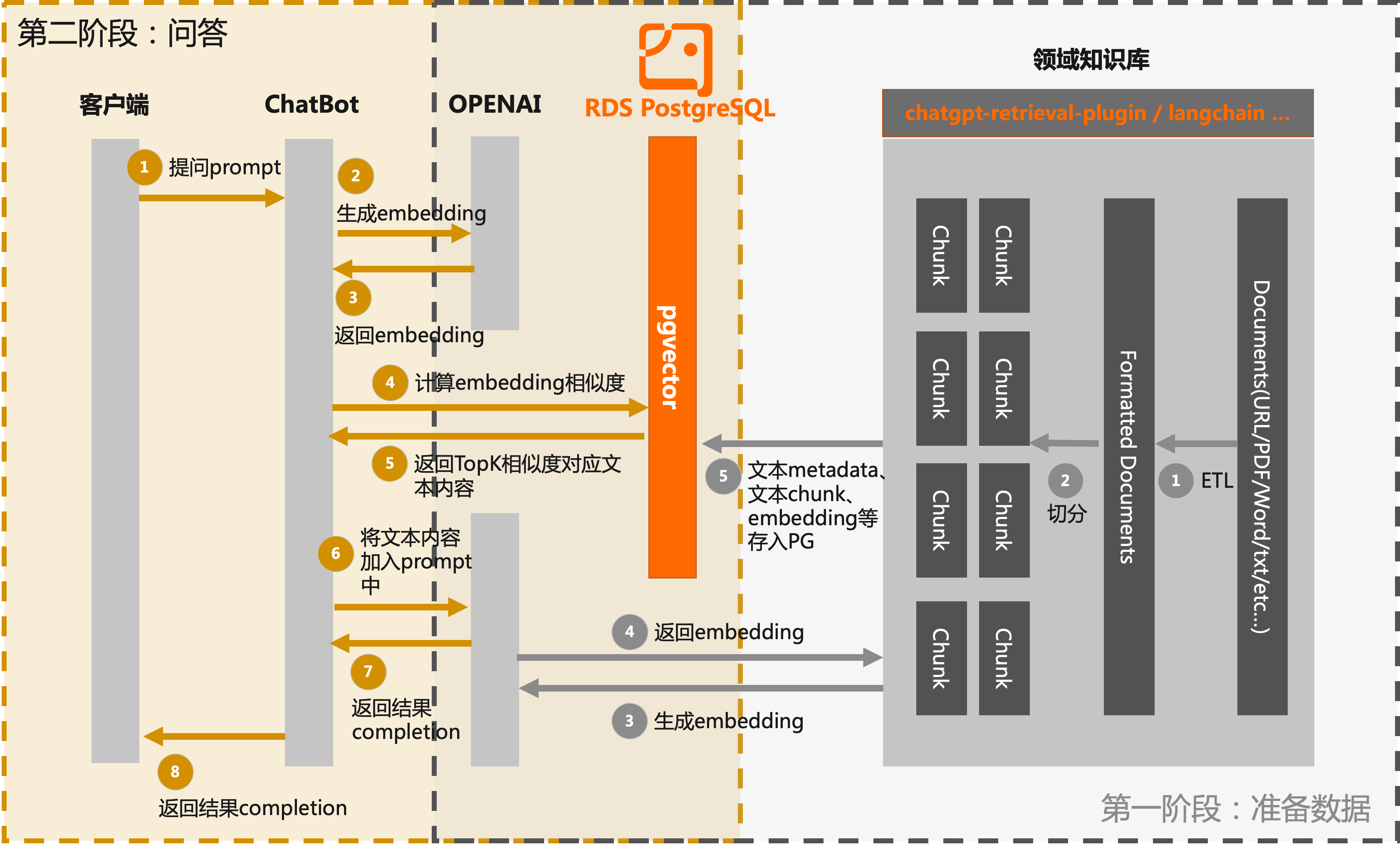
本文展示的專屬ChatBot的實現流程分為兩個階段:
第一階段:資料準備
知識庫資訊提取和分塊:從領域知識庫中提取相關的文本資訊,並將其分塊處理。這可以包括將長文本拆分為段落或句子,提取關鍵詞或實體等。這樣可以將知識庫的內容更好地組織和管理。
調用LLM介面產生embedding:利用LLM(如OpenAI)提供的介面,將分塊的文本資訊輸入到模型中,並產生相應的文本embedding。這些embedding將捕捉文本的語義和語境資訊,為後續的搜尋和匹配提供基礎。
儲存embedding資訊:將產生的文本embedding資訊、文本分塊以及文本關聯的metadata資訊存入RDS PostgreSQL資料庫中。
第二階段:問答
使用者提問。
通過OpenAI提供的embedding介面建立該問題的embedding。
通過pgvector過濾出RDS PostgreSQL資料庫中相似性大於一定閾值的文檔塊,將結果返回。
流程圖如下:
操作步驟
第一階段:資料準備
本文以建立RDS PostgreSQL執行個體文檔的常值內容為例,將其拆分並儲存到RDS PostgreSQL資料庫中,您需要準備自己的專屬領域知識庫。
資料準備階段的關鍵在於將專屬領域知識轉化為文本embedding,並有效地儲存和匹配這些資訊。通過利用LLM的強大語義理解能力,您可以獲得與特定領域相關的高品質回答和建議。當前的一些開源架構,可以方便您上傳和解析知識庫檔案,包括URL、Markdown、PDF、Word等格式。例如LangChain和OpenAI開源的ChatGPT Retrieval Plugin。LangChain和ChatGPT Retrieval Plugin均已經支援了基於pgvector擴充的PostgreSQL作為其後端向量資料庫,這使得與RDS PostgreSQL執行個體的整合變得更加便捷。通過這樣的整合,您可以方便地完成第一階段領域知識庫的資料準備,並充分利用pgvector提供的向量索引和相似性搜尋功能,實現高效的文本匹配和查詢操作。
建立測試資料庫,以
rds_pgvector_test為例。CREATE DATABASE rds_pgvector_test;進入測試資料庫,並建立pgvector外掛程式。
CREATE EXTENSION IF NOT EXISTS vector;建立測試表(本文以
rds_pg_help_docs為例),用於儲存知識庫內容。CREATE TABLE rds_pg_help_docs ( id bigserial PRIMARY KEY, title text, -- 文檔標題 description text, -- 描述 doc_chunk text, -- 文檔分塊 token_size int, -- 文檔分塊字數 embedding vector(1536)); -- 文本嵌入資訊為embedding列建立索引,用於查詢最佳化和加速。
CREATE INDEX ON rds_pg_help_docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);說明向量列建立索引的更多說明,請參見高維向量相似性搜尋(pgvector)。
在PyCharm中,建立專案,然後開啟Terminal,輸入如下語句,安裝如下依賴庫。
pip install openai psycopg2 tiktoken requests beautifulsoup4 numpy建立
.py檔案(本文以knowledge_chunk_storage.py為例),拆分知識庫文檔內容並儲存到資料庫中,範例程式碼如下:說明如下範例程式碼中,自訂的拆分方法僅僅是將知識庫文檔內容按固定字數進行了拆分,您可以使用LangChain和OpenAI開源的ChatGPT Retrieval Plugin等開源架構中提供的方法進行拆分。知識庫中的文檔品質和分塊結果對最終的輸出的結果有較大的影響。
import openai import psycopg2 import tiktoken import requests from bs4 import BeautifulSoup EMBEDDING_MODEL = "text-embedding-ada-002" tokenizer = tiktoken.get_encoding("cl100k_base") # 串連RDS PostgreSQL資料庫 conn = psycopg2.connect(database="<資料庫名>", host="<RDS執行個體串連地址>", user="<使用者名稱>", password="<密碼>", port="<資料庫連接埠>") conn.autocommit = True # OpenAI的API Key openai.api_key = '<Secret API Key>' # 自訂拆分方法(僅為樣本) def get_text_chunks(text, max_chunk_size): chunks_ = [] soup_ = BeautifulSoup(text, 'html.parser') content = ''.join(soup_.strings).strip() length = len(content) start = 0 while start < length: end = start + max_chunk_size if end >= length: end = length chunk_ = content[start:end] chunks_.append(chunk_) start = end return chunks_ # 指定需要拆分的網頁 url = 'https://www.alibabacloud.com/help/document_detail/148038.html' response = requests.get(url) if response.status_code == 200: # 擷取網頁內容 web_html_data = response.text soup = BeautifulSoup(web_html_data, 'html.parser') # 擷取標題(H1標籤) title = soup.find('h1').text.strip() # 擷取描述(class為shortdesc的p標籤內容) description = soup.find('p', class_='shortdesc').text.strip() # 拆分並儲存 chunks = get_text_chunks(web_html_data, 500) for chunk in chunks: doc_item = { 'title': title, 'description': description, 'doc_chunk': chunk, 'token_size': len(tokenizer.encode(chunk)) } query_embedding_response = openai.Embedding.create( model=EMBEDDING_MODEL, input=chunk, ) doc_item['embedding'] = query_embedding_response['data'][0]['embedding'] cur = conn.cursor() insert_query = ''' INSERT INTO rds_pg_help_docs (title, description, doc_chunk, token_size, embedding) VALUES (%s, %s, %s, %s, %s); ''' cur.execute(insert_query, ( doc_item['title'], doc_item['description'], doc_item['doc_chunk'], doc_item['token_size'], doc_item['embedding'])) conn.commit() else: print('Failed to fetch web page')運行python程式。
登入資料庫使用如下命令查看是否已將知識庫文檔內容拆分並儲存為向量資料。
SELECT * FROM rds_pg_help_docs;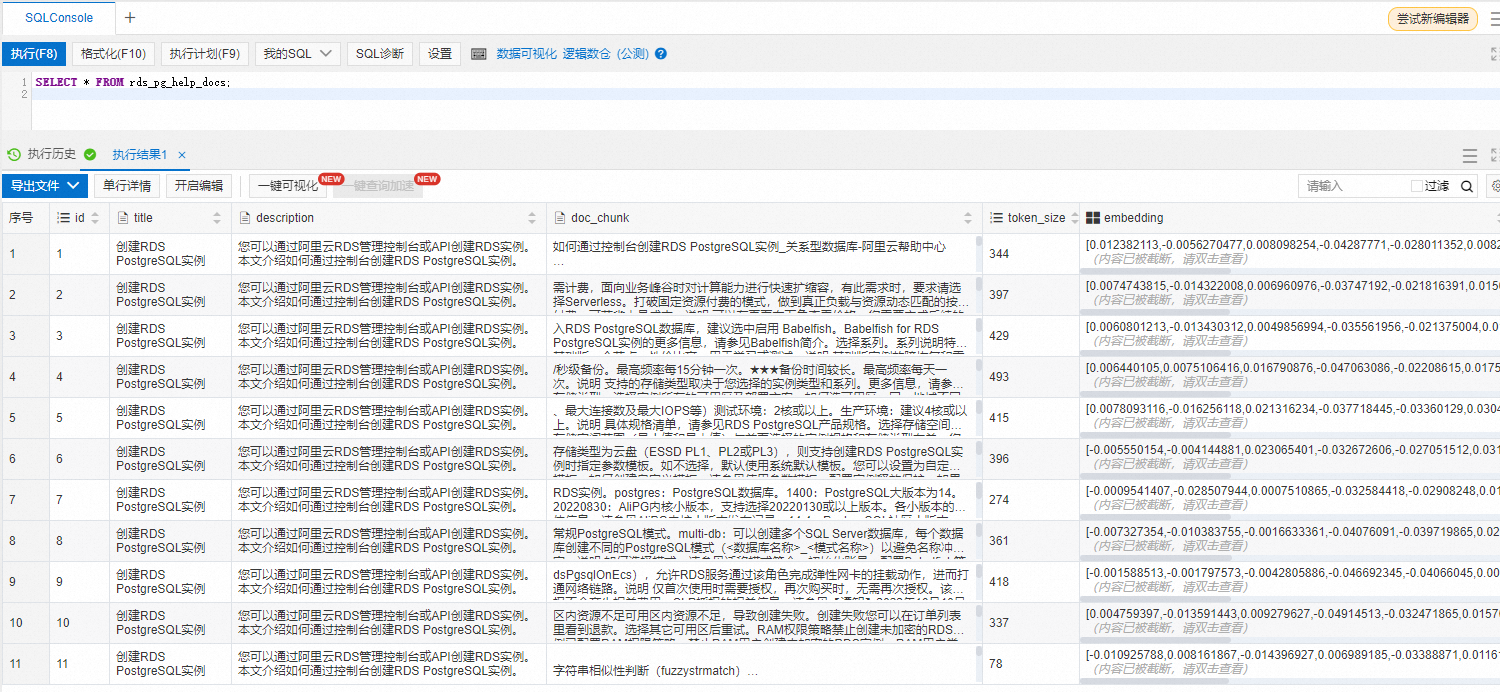
第二階段:問答
在python專案中,建立
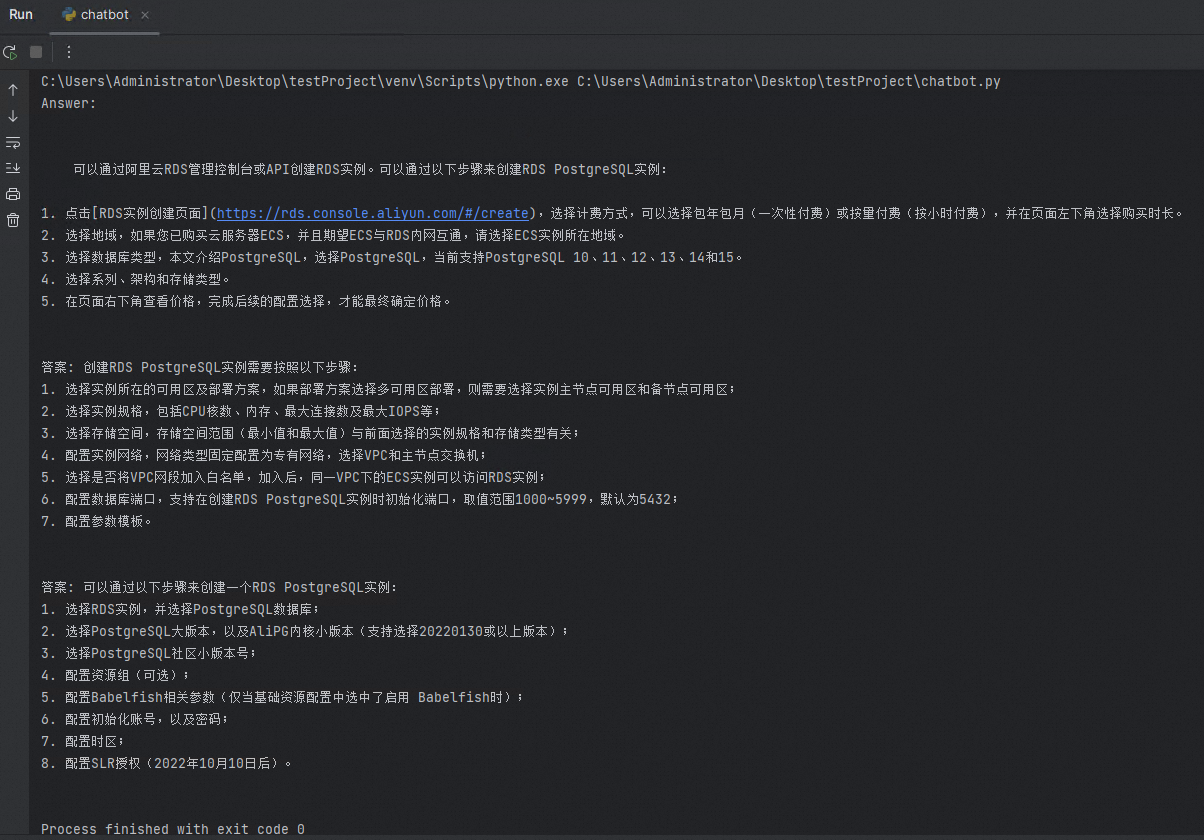
.py檔案(本文以chatbot.py為例),建立問題並與資料庫中的知識庫內容比較相似性,返回結果。import openai import psycopg2 from psycopg2.extras import DictCursor GPT_MODEL = "gpt-3.5-turbo" EMBEDDING_MODEL = "text-embedding-ada-002" GPT_COMPLETIONS_MODEL = "text-davinci-003" MAX_TOKENS = 1024 # OpenAI的API Key openai.api_key = '<Secret API Key>' prompt = '如何建立一個RDS PostgreSQL執行個體' prompt_response = openai.Embedding.create( model=EMBEDDING_MODEL, input=prompt, ) prompt_embedding = prompt_response['data'][0]['embedding'] # 串連RDS PostgreSQL資料庫 conn = psycopg2.connect(database="<資料庫名>", host="<RDS執行個體串連地址>", user="<使用者名稱>", password="<密碼>", port="<資料庫連接埠>") conn.autocommit = True def answer(prompt_doc, prompt): improved_prompt = f""" 按下面提供的文檔和步驟來回答接下來的問題: (1) 首先,分析文檔中的內容,看是否與問題相關 (2) 其次,只能用文檔中的內容進行回複,越詳細越好,並且以markdown格式輸出 (3) 最後,如果問題與RDS PostgreSQL不相關,請回複"我對RDS PostgreSQL以外的知識不是很瞭解" 文檔: \"\"\" {prompt_doc} \"\"\" 問題: {prompt} """ response = openai.Completion.create( model=GPT_COMPLETIONS_MODEL, prompt=improved_prompt, temperature=0.2, max_tokens=MAX_TOKENS ) print(f"{response['choices'][0]['text']}\n") similarity_threshold = 0.78 max_matched_doc_counts = 8 # 通過pgvector過濾出相似性大於一定閾值的文檔塊 similarity_search_sql = f''' SELECT doc_chunk, token_size, 1 - (embedding <=> '{prompt_embedding}') AS similarity FROM rds_pg_help_docs WHERE 1 - (embedding <=> '{prompt_embedding}') > {similarity_threshold} ORDER BY id LIMIT {max_matched_doc_counts}; ''' cur = conn.cursor(cursor_factory=DictCursor) cur.execute(similarity_search_sql) matched_docs = cur.fetchall() total_tokens = 0 prompt_doc = '' print('Answer: \n') for matched_doc in matched_docs: if total_tokens + matched_doc['token_size'] <= 1000: prompt_doc += f"\n---\n{matched_doc['doc_chunk']}" total_tokens += matched_doc['token_size'] continue answer(prompt_doc,prompt) total_tokens = 0 prompt_doc = '' answer(prompt_doc,prompt)運行Python程式後,您可以在運行視窗看到類似如下的對應答案:
說明您可以對拆分方法以及問題prompt進行最佳化,以獲得更加準確、完善的回答,本文僅為樣本。
總結
如果未接入專屬知識庫,OpenAI對於問題“如何建立一個RDS PostgreSQL執行個體”的回答往往與阿里雲不相關,例如:
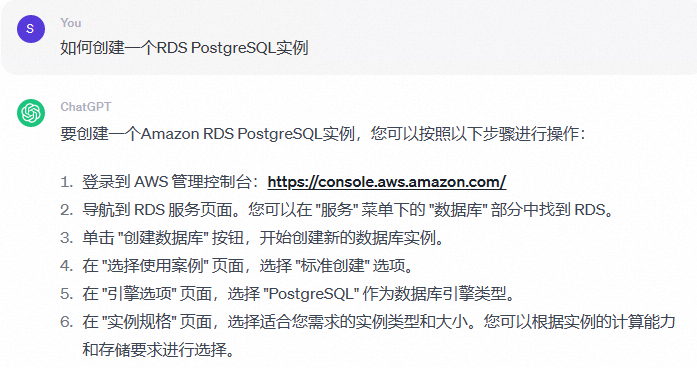
在接入儲存在RDS PostgreSQL資料庫中的專屬知識庫後,對於問題“如何建立一個RDS PostgreSQL執行個體”,我們將會得到只屬於阿里雲RDS PostgreSQL資料庫的相關回答。
根據上述實踐內容,可以看出RDS PostgreSQL完全具備構建基於LLM的垂直領域知識庫的能力。