本文介紹如何使用Prometheus監控Cassandra。
步驟一:自行部署Cassandra JMX Agent(可選)
若所屬環境為ECS,您需要部署Agent。若所屬環境為容器環境,請忽略此步驟。
您需要根據Cassandra的版本下載合適的Cassandra JMX Agent到Cassandra所在的ECS內。
解壓縮下載的Agent壓縮包到
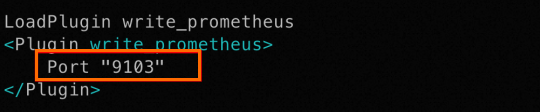
MCAC_ROOT,修改cassandra-env.sh檔案,追加以下內容。MCAC_ROOT=/path/to/directory JVM_OPTS="$JVM_OPTS -javaagent:${MCAC_ROOT}/lib/datastax-mcac-agent.jar"重要Cassandra JMX Agent給Prometheus暴露的資料抓取連接埠為9103,如果需要修改為其他的連接埠,則修改${MCAC_ROOT}/config/collectd.conf.tmpl檔案中的如下圖所示的內容為想要提供的連接埠。
完成上述配置之後,重新啟動Cassandra應用程式,在ECS伺服器上執行命令
curl localhost:{jmx連接埠}/metrics,查看是否正常有資料返回,如果有資料返回,則說明Cassandra JMX Agent已經正確安裝。
步驟二:接入 Cassandra
在左側導覽列,單擊接入中心。
在接入中心頁面的資料庫地區,單擊 Cassandra。

在Cassandra面板的開始接入頁簽完成接入,然後單擊確定。
參數
說明
選擇所屬環境類型
可以接入以下兩種服務環境:
Container Service環境
ECS(VPC)
選擇叢集
選擇目的地組群。
Pod 標籤
部署 Cassandra 服務 Pod 的標籤(建議使用有特定標識的標籤)
服務連接埠
步驟一中安裝的 Cassandra JMX Agent 的連接埠,預設連接埠號碼會自動填滿。
Metrics 採集路徑
步驟一中安裝的 Cassandra JMX Agent 指標透出路徑,預設路徑會自動填滿。
Metric 採集間隔(單位/秒)
可觀測監控 Prometheus 版採集指標資料的時間間隔,預設30秒。
步驟三:查看Cassandra大盤資料
在左側導覽列,單擊接入管理。
在接入管理頁面的已接入環境頁簽中,選擇目標環境,在目標環境列表中,單擊目標環境名稱進入容器環境詳情頁面。

在組件管理頁簽下的組件類型地區,單擊Cassandra,然後單擊大盤,即可查看所有的大盤名稱。

單擊目標大盤名稱,查看對應的Grafana大盤。
步驟四:配置 Cassandra 監控警示
在組件管理頁簽下的組件類型地區,單擊Cassandra,然後單擊警示規則,即可查看預設建立的警示規則。

您還可以根據業務需求新增警示規則,建立Prometheus警示規則的具體操作,請參見建立Prometheus警示規則。
關鍵計量說明
叢集/節點基礎資訊
指標名稱 | 關鍵層級 | 指標描述 | 指標說明 |
mcac_client_connected_native_clients | Major | CQL串連數 | 串連數過多會佔用系統過多資源,導致用戶端延遲變高。 |
mcac_table_live_disk_space_used_total | Major | cassandra佔據的空間 | 該指標過高可能導致硬碟空間不足以及資料存取延遲增加。 |
mcac_table_snapshots_size | Recommand | cassandra快照檔案大小 | 快照用於資料恢複,該指標過高可能導致硬碟空間不足從而無法儲存下完整的快照。 |
collectd_uptime | Major | 節點開機時間 | 該指標過高說明系統長期沒有進行重啟,存在漏洞的系統可能會帶來安全隱患。 |
關鍵效能指標
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_table_read_latency | Critical | 用戶端讀取資料的延遲 | 該指標過高會導致應用程式的讀取速度變慢,影響使用者體驗。 |
mcac_table_write_latency | Critical | 用戶端寫資料的延遲 | 該指標過高會導致應用程式的寫入速度變慢,影響使用者體驗。 |
異常和錯誤
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_client_request_timeouts_total | Critical | 逾時的用戶端請求 | 該指標過高,說明系統負載較高,會嚴重影響使用者體驗。 |
mcac_client_request_failures_total | Critical | 出現異常的用戶端請求 | 該指標過高,說明系統負載較高,會嚴重影響使用者體驗。 |
mcac_dropped_message_dropped_total | Critical | 丟棄的訊息 | 該指標過高,說明系統負載較高,會嚴重影響使用者體驗。 |
緩衝和布隆過濾器
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_table_key_cache_hit_rate | Major | key_cache的命中率 | 該指標過低可能會導致應用程式的讀取速度變慢,影響使用者體驗。 |
mcac_table_row_cache_hit_total | Major | row_cache的叫用次數 | 該指標過低可能會導致應用程式的讀取速度變慢,影響使用者體驗。 |
mcac_table_row_cache_miss_total | Recommand | row_cache未命中的次數 | 該指標過高可能會導致應用程式的讀取速度變慢,影響使用者體驗。 |
mcac_table_row_cache_hit_out_of_range_total | Recommand | row_cache命中但還是去訪問磁碟的次數 | 該指標過高可能會導致應用程式的讀取速度變慢,影響使用者體驗。 |
mcac_table_bloom_filter_false_ratio | Major | 布隆過濾器的誤判率 | 當布隆過濾器誤判比例過高時,會導致查詢結果中有很多本來不存在的元素被判斷為存在,從而浪費查詢時間和資源。這會降低查詢效能並增加查詢成本。 |
CPU/記憶體/硬碟使用趨勢
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
collectd_cpu_total | Critical | CPU的使用率 | 該指標過高說明系統負載較高,會導致用戶端請求延遲過高,嚴重影響使用者體驗。 |
collectd_memory | Critical | 記憶體的使用率 | 該指標過高說明系統負載較高,會導致用戶端請求延遲升高,嚴重影響使用者體驗。 |
collectd_df_df_complex | Critical | 硬碟的使用率 | 該指標過高說明硬碟可用空間不足,會導致資料無法正常持久化儲存,有宕機的風險。 |
SSTable壓縮
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_table_pending_compactions | Major | 進行中的SSTable壓縮任務 | 該指標過高說明系統負載較高,會導致用戶端請求延遲升高,建議合理配置SSTable的壓縮間隔。 |
mcac_table_compaction_bytes_written_total | Major | SSTable的壓縮速率 | 該指標過低說明系統壓縮速率較慢,會導致壓縮任務累積,建議提高節點的硬體設定。 |
mcac_table_compression_ratio | Major | SSTable的壓縮率 | 該指標過高說明壓縮後的檔案仍然過大,壓縮沒有達到預期的效果。 |
磁碟檔案
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_table_live_ss_table_count | Major | SSTable的數量 | 該指標越高會導致硬碟佔用過高並且讀寫延遲增加,需合理配置SSTable的壓縮策略。 |
mcac_table_live_disk_space_used_total | Major | SSTable佔用的硬碟空間 | 該指標越高會導致硬碟佔用過高並且讀寫延遲增加,需合理配置SSTable的壓縮策略。 |
mcac_table_ss_tables_per_read_histogram | Major | 一次read操作需要讀取的SSTable數量 | 該指標越高會導致用戶端讀取延遲增加。 |
mcac_commit_log_total_commit_log_size | Major | Commit Log佔用的硬碟空間 | 該指標過高會導致硬碟空間不足,讀寫效能下降以及資料恢復增加。 |
mcac_table_memtable_live_data_size | Major | MemTable佔用的空間 | 該指標過高會導致資料寫入效能下降,節點穩定性下降。 |
mcac_table_waiting_on_free_memtable_space | Major | 等待釋放MemTable花費的時間 | 該指標過高會導致資料寫入效能下降,節點穩定性下降。 |
線程池狀態
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_thread_pools_active_tasks | Critical | 線程池中正在活躍的任務數量 | 阻塞任務過多會導致佔用系統資源過高,響應速度下降甚至系統崩潰。 |
mcac_thread_pools_total_blocked_tasks_total | Critical | 線程池中正處於阻塞狀態的任務數量 | 阻塞任務過多會導致佔用系統資源過高,響應速度下降甚至系統崩潰。 |
mcac_thread_pools_pending_tasks | Critical | 線程池中處於pending狀態的任務數量 | 處於pending狀態的任務過多會導致佔用系統資源過高,這些任務對應的請求逾時,甚至導致系統崩潰。 |
mcac_thread_pools_completed_tasks | Major | 線程池中已經完成的任務數量 | 該指標可以反映系統的輸送量,該指標越高說明系統的效能優秀。 |
JVM相關
指標名稱 | 重要層級 | 指標描述 | 指標說明 |
mcac_jvm_memory_used | Critical | 已經使用的JVM堆記憶體大小 | 該指標越高,可能導致記憶體不足,觸發頻繁的記憶體回收,降低應用的吞吐率。 |
mcac_jvm_gc_time | Critical | 應用程式用於GC的時間 | 該指標過高說明GC過於頻繁,系統用於執行使用者任務時間較少,可能導致用戶端請求逾時,甚至導致系統崩潰等。 |