Managed Service for Prometheus支援通過node-exporter採集ECS Linux或Windows主機作業系統相關指標,也支援process-exporter採集進程相關監控資料,另外基於textfile的方式也支援採集使用者寫到檔案中自訂監控指標。
前提條件
已開通可觀測監控Prometheus版。具體操作,請參見Prometheus 執行個體計費。
已建立ECS執行個體。具體操作,請參見通過控制台使用ECS執行個體(快捷版)。
已開通阿里雲資源中心。具體操作,請參見開通資源中心。
主機監控優勢
阿里雲Prometheus主機監控針對阿里雲ECS伺服器提供了一個高效且易於管理的監控方案,這一方案的特點是順應了現代雲端運算環境中對於可觀測性和自動化管理的需求。
阿里雲Prometheus提供的主機監控,具備阿里雲ECS伺服器、自建IDC內伺服器、雲廠商伺服器全類型主機接入能力。針對阿里雲ECS伺服器可根據配置自動安裝各類開源Exporter,各類Exporter採集配置自動產生。託管Prometheus Agent實現自動採集,採集資料統一儲存、統一展示、統一警示。非阿里雲主機不具備自動服務發現的能力,所以需要依賴使用者在接入時手動安裝阿里雲採集探針,主動將監控資料上報到阿里雲Prometheus儲存。
優勢 | 說明 |
主機秒級發現 |
|
探針秒級安裝 |
|
指標秒級採集 |
主機從建立到納入監控系統,整體可以在30 ~ 60s以內完成。主機所有指標資料可以支援1 ~ 60s時間間隔的靈活調整。整體實現主機全方位秒級監控能力。 |
探針Serverless化 |
|
智能指標標籤 |
|
超大規模資料擷取與儲存 |
|
提供完善的上下遊監控資料 |
|
進程級監控 |
|
預設提供Grafana專家級大盤 |
|
步驟一:接入主機監控資料
登入ARMS控制台,在左側導覽列單擊接入中心。
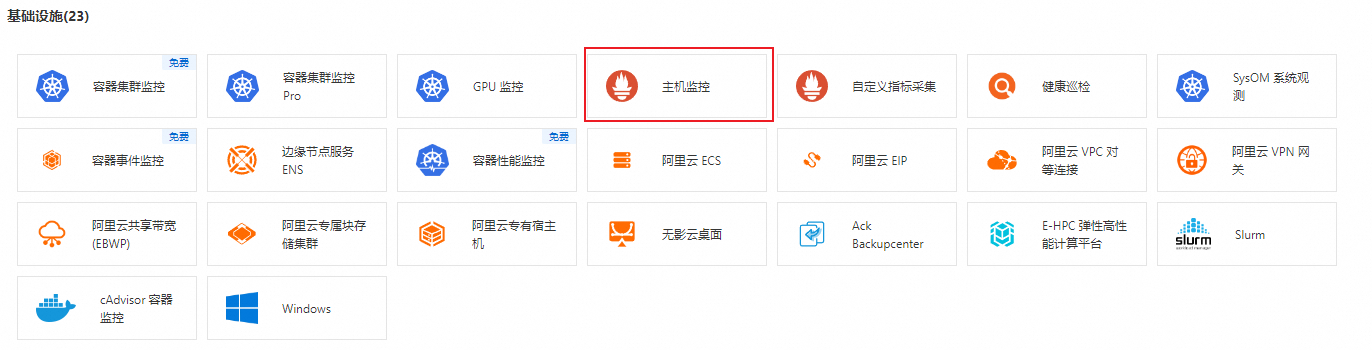
在接入中心頁面,單擊左側基礎設施,然後單擊主機監控。
 說明
說明由於Prometheus依賴阿里雲資源中心擷取雲產品當前登入賬戶的VPC、ECS等資料進行服務發現,如果沒有開通資源中心,接入流程會引導您先開通資源中心,具體操作請參見開通資源中心。
開通資源中心是非同步作業,重新檢測後如果仍然是未開通狀態,可以等待10~20秒左右再單擊重新檢測。
在彈出的頁面中,選擇目標ECS(VPC),然後按照下表說明填寫配置資訊。
指標
說明
NodeExporter 安裝方式
自動安裝(推薦):Prometheus會為使用者選擇的ECS預設安裝node-exporter,您無需其他動作即可接入。
自助安裝:自行安裝node-exporter。
主機服務發現方式
汙點標籤選擇:黑名單機制。標籤匹配到的執行個體將不會接入Prometheus,沒有匹配到的ECS監控指標將會接入Prometheus,預設不會採集容器監控服務的節點。
無條件:安裝和採集當前VPC內所有ECS主機監控指標。
標籤選擇:白名單機制。標籤匹配到的執行個體將會接入Prometheus,沒有匹配到的ECS執行個體將不會接入Prometheus。
IP域選擇:該方式是提供一個網段,當ECS的IP地址匹配該網段時,即被選中。如果填寫VPC對應的網段,即代表命中當前VPC全部ECS。
執行個體ID:指定需要接入的執行個體ID,多個執行個體ID使用英文逗號分隔。
ECS 汙點標籤
每一個汙點標籤由key和value組成,可以設定多個汙點標籤。
採集 TextFile
採集指定檔案中的Prometheus指標。
採集進程狀態指標
預設會採集主機上的進程監控資料。
Node-Exporter 服務連接埠
預設連接埠9100。
Metric 採集間隔(單位/秒)
採集資料的時間間隔,預設為15秒。
自動設定安全性群組
預設開啟。
自訂ECS Tag注入
指定ECS標籤的Key,系統會自動將標籤的索引值對注入到Prometheus指標中。
單擊確定,等待1~2分鐘即可完成ECS主機監控指標接入。
接入成功後,如果監控大盤沒有資料,需要確認ECS的安全性群組在入方向需要允許100.64.0.0/10和192.168.0.0/18網段對9100和9256的存取權限,查看ECS的安全性群組詳情,請參見查詢安全性群組。9100是node-exporter的預設連接埠,9256是process-exporter的預設連接埠,具體連接埠需要根據您自身配置進行調整。
步驟二:查看監控大盤
在左側導覽列單擊接入管理。
在接入管理頁面的已接入環境頁簽中,選擇ECS環境。
在ECS環境列表中,單擊目標環境名稱進入ECS環境詳情頁面。
在組件管理頁簽,單擊組件類型地區的大盤,即可查看內建的Grafana大盤。
步驟三:配置警示
登入Prometheus控制台,在左側導覽列單擊接入管理。
在接入管理頁面的已接入環境頁簽中,選擇ECS環境。
在ECS環境列表中,單擊目標環境名稱進入ECS環境詳情頁面。
在組件管理頁簽,單擊組件類型地區的警示規則,即可查看內建的警示規則。
內建的警示規則會產生警示事件,但不會進行警示通知。如果您希望將警示通知發送到郵件或其他平台,可以單擊編輯配置通知方式。在警示配置頁面您也可以自訂警示閾值、期間、警示內容等,具體操作,請參見建立Prometheus警示規則。
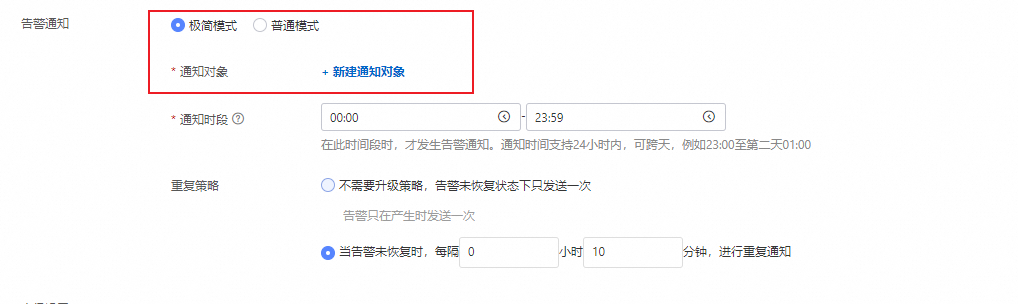
在極簡模式下,您可以設定警示的通知對象、通知時段和重複策略。
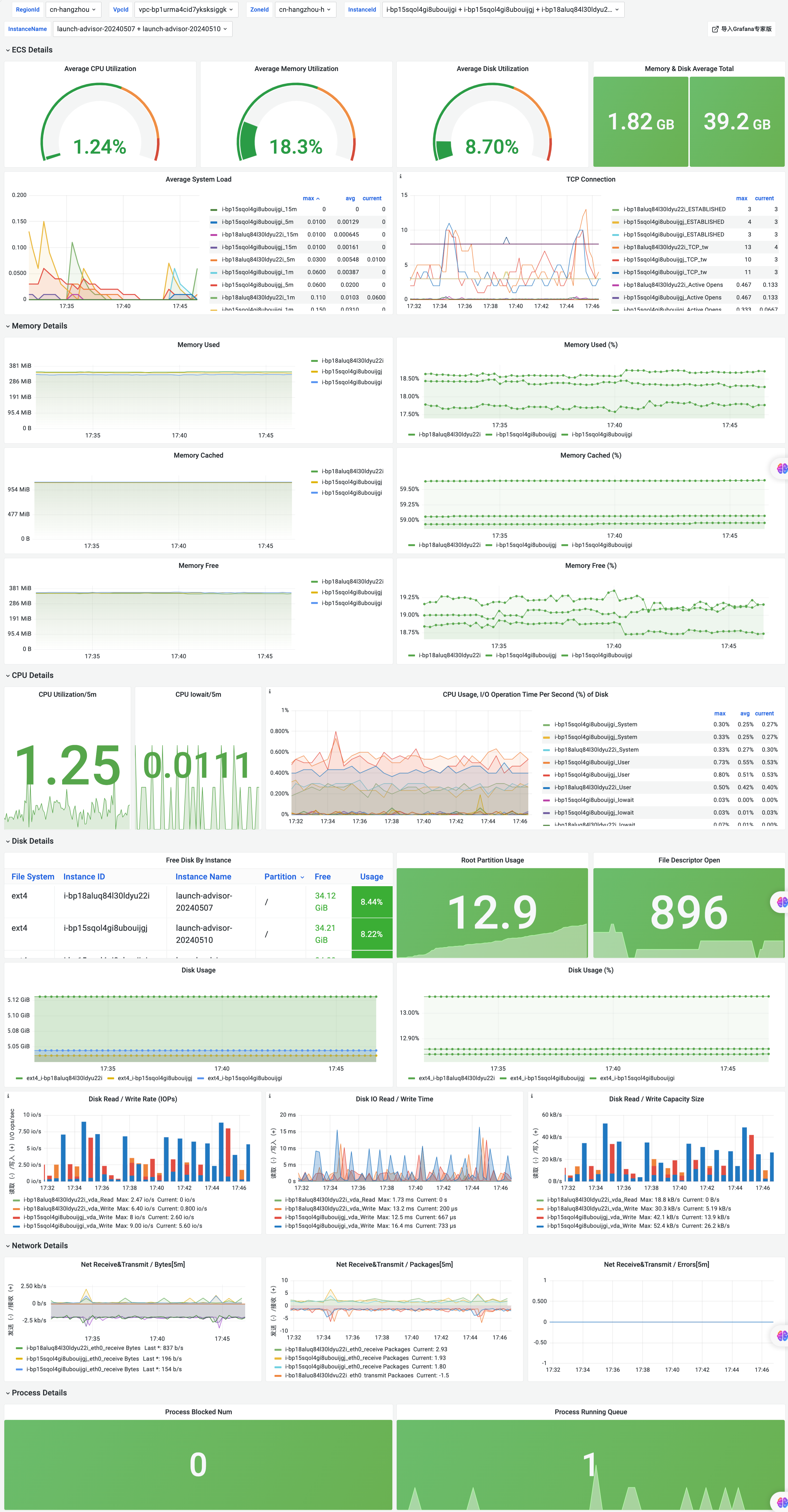
Grafana大盤圖例
ECS Overview大盤

ECS Detail大盤