本文介紹了PolarDB MySQL版通過ePQ(彈性並行查詢)技術來實現冷資料並行查詢的方法,並提供了詳細的使用說明。
背景資訊
隨著OSS表的使用日益普及以及儲存資料量的持續增長,OSS表的查詢效率問題越發凸顯,嚴重影響使用體驗。一種有效改善策略是採用ePQ(彈性並行查詢)。通過增加線程數量來顯著加快查詢速度,以此最佳化查詢體驗,提高資料檢索效率,確保更快地擷取資訊。
功能說明
冷資料並行查詢功能目前僅支援CSV格式的資料。通過將不同的任務分配給獨立的workers來並行掃描OSS上的CSV資料,從而顯著提高查詢速度。其原理圖如下:
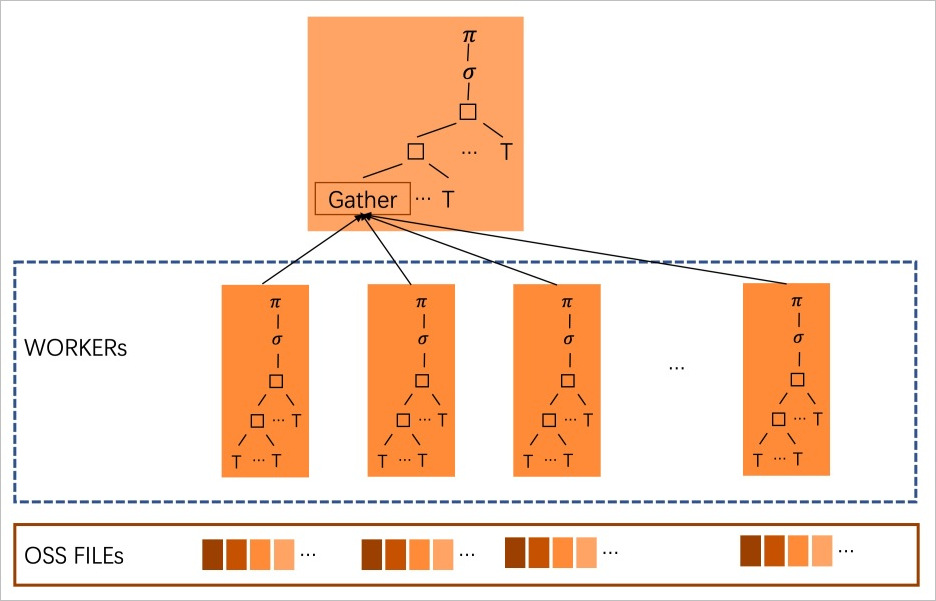
版本要求
以下是對資料庫引擎版本和核心小版本的具體要求:
單機並行:
資料庫引擎版本為MySQL 8.0.1,核心小版本需為8.0.1.1.34及以上。
產品版本:企業版/。
單機並行:
資料庫引擎版本為MySQL 8.0.2,核心小版本需為8.0.2.2.24及以上。
產品版本:企業版。
多機並行:
資料庫引擎版本為MySQL 8.0.2,核心小版本需為8.0.2.2.24及以上。
產品版本:企業版。
前提條件

loose_csv_max_oss_threads表示當前節點可以並行的最大OSS線程總數。loose_csv_max_oss_threads取值範圍1~100,預設值為1,如未修改將無法進行冷資料並行查詢。單個OSS線程預設消耗128 MB記憶體,請根據執行個體剩餘記憶體量適當加大loose_csv_max_oss_threads參數。
使用說明
本文的樣本基於TPC-H基準運行測試,並不能與發行的TPC-H基準測試結果進行比較,本文中的樣本並不完全符合TPC-H基準測試的所有要求。查看更多詳情請參見TPC-H測試集。
在開啟並行查詢的情境下,調大參數loose_csv_max_oss_threads即可實現冷資料的並行查詢。
樣本:首先歸檔一張OSS冷儲存表,這裡以lineitem為例:
mysql> show create table lineitem;
*************************** 1. row ***************************
Table: lineitem
Create Table: CREATE TABLE `lineitem` (
`l_orderkey` int(11) NOT NULL,
`l_partkey` int(11) NOT NULL,
`l_suppkey` int(11) NOT NULL,
`l_linenumber` int(11) NOT NULL,
`l_quantity` decimal(10,2) NOT NULL,
`l_extendedprice` decimal(10,2) NOT NULL,
`l_discount` decimal(10,2) NOT NULL,
`l_tax` decimal(10,2) NOT NULL,
`l_returnflag` char(1) NOT NULL,
`l_linestatus` char(1) NOT NULL,
`l_shipDATE` date NOT NULL,
`l_commitDATE` date NOT NULL,
`l_receiptDATE` date NOT NULL,
`l_shipinstruct` char(25) NOT NULL,
`l_shipmode` char(10) NOT NULL,
`l_comment` varchar(44) NOT NULL
) ENGINE=CSV DEFAULT CHARSET=utf8 /*!99990 800020204 NULL_MARKER='NULL' */ CONNECTION='default_oss_server'
1 row in set (0.00 sec)開啟並行查詢的方法有很多,以hint為例,可以通過在查詢中添加hint來開啟並行查詢。通過查詢計劃可以看到,如果Extra列中含有Parallel scan(並行掃描)策略,則開啟了並行查詢,而workers數量則代表了並行度。
串列查詢
通過使用EXPLAIN查詢語句,可以查看Extra列是否含有Parallel scan標記的執行情況,從而可以判斷當前線程是否處於正常的查詢計劃,當前並未開啟並行查詢。
mysql> explain SELECT
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+----------+------------+------+---------------+------+---------+------+----------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+----------+----------+-------------+
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 61560489 | 0.41 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+----------+----------+-------------+
1 row in set, 1 warning (1.23 sec)可以觀察到,在正常的查詢計劃中,表的聚集計算和掃描是在一個線程中串列完成。
並行查詢
啟用了並行查詢hint(/*+ PARALLEL(4) */)之後,執行計畫顯示lineitem表正在使用並行查詢來提升速度。從執行計畫中的Extra列所顯示的Parallel scan(4 workers)資訊可知,本次查詢正通過4個背景工作執行緒並發執行。
mysql> explain SELECT /*+ PARALLEL(4) */
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 15390122 | 0.41 | Parallel scan (4 workers); Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+----------------------------------------+
2 rows in set, 1 warning (2.17 sec)可以觀察到當前節點已經啟用了四個workers,這意味著已經實現了並行查詢,整體查詢速度相當於單線程查詢的四倍。
多節點並行查詢
從執行計畫可以看到,lineitem表使用了Parallel scan,每個節點計劃使用4個workers來並存執行,總共有2個節點,8個workers來執行。Extra顯示了具體的workers數量和節點數量。
mysql> explain SELECT /*+ PARALLEL(4) */
-> sum(l_extendedprice * l_discount) AS revenue
-> FROM
-> lineitem
-> WHERE
-> l_shipdate >= date '1994-01-01'
-> AND l_shipdate < date '1994-01-01' + interval '1' year
-> AND l_discount between 0.05 - 0.01 AND 0.05 + 0.01
-> AND l_quantity < 24;
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
| 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | lineitem | NULL | ALL | NULL | NULL | NULL | NULL | 59986051 | 0.41 | Parallel scan (8 workers); MPP (2 nodes); Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+----------+----------+-------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)可以觀察到,當前已經開啟了2個節點執行,匯流排程並行度為8個線程。這意味著已經開啟多節點並行查詢,整體查詢速度相當於單線程的查詢8倍。