PolarDB通過DDL物理複製最佳化功能,在主節點寫物理日誌和唯讀節點應用物理日誌的關鍵路徑上進行了全面最佳化,大大縮短了主節點上DDL操作的執行時間和唯讀節點上解析DDL的物理日誌複寫延遲時間。本文介紹如何使用DDL物理複製最佳化功能。
前提條件
PolarDB叢集版本需為以下版本之一,您可以通過查詢版本號碼確認叢集版本:
PolarDB MySQL版8.0.1版本且Revision version為8.0.1.1.10及以上。
PolarDB MySQL版5.7版本且Revision version為5.7.1.0.10及以上。
使用限制
目前並行DDL物理複製最佳化僅支援建立主鍵或二級索引(不包括全文索引和空間索引)的DDL操作。
對於只需修改中繼資料的DDL操作(如rename),因其本身執行速度已經很快,無需使用該最佳化功能。
不支援在PolarDB MySQL版8.0.2版本和5.6版本使用該最佳化功能。
背景資訊
PolarDB通過儲存計算分離架構,實現了主節點和唯讀節點共用同一份儲存資料,既降低了儲存成本,又提高了叢集的可用性和可靠性。為實現這一架構,PolarDB採用了業界領先的物理複製技術,不僅實現了共用儲存架構上主節點和唯讀節點間的資料一致性,而且減少了Binlog fsync操作帶來的I/O開銷。
InnoDB中的資料是通過B-Tree來維護索引的,然而大部分Slow DDL操作(如增加主鍵或二級索引、optimize table等)往往需要重建或新增B-Tree索引,導致大量物理日誌的產生。而針對物理日誌進行的操作往往出現在DDL執行的關鍵路徑上,增加了DDL操作的執行時間。此外,物理複製技術要求唯讀節點解析和應用這些新產生的物理日誌,由於DDL操作而產生的大量物理日誌可能嚴重影響唯讀節點的日誌同步進程,甚至導致唯讀節點不可用等問題。
針對上述問題,PolarDB提供了DDL物理複製最佳化功能,在主節點寫物理日誌和唯讀節點應用物理日誌的關鍵路徑上做了全面的最佳化,使得主節點在執行建立主鍵DDL操作的執行時間最多可減少20.6%,唯讀節點解析DDL的複寫延遲時間最多約可減少至原來的0.4%。
使用方法
您可以通過設定如下參數開啟DDL物理複製最佳化功能。
參數 | 層級 | 說明 |
innodb_bulk_load_page_grained_redo_enable | Global | DDL物理複製最佳化功能開關,取值範圍如下:
|
效能測試
測試準備
測試環境
PolarDB MySQL版8.0版本的叢集(包含1個主節點和1個唯讀節點)規格為16核128 GB。
叢集儲存空間為50 TB。
測試表結構
通過如下語句建立一張名為
t0的表:CREATE TABLE t0(a INT PRIMARY KEY, b INT) ENGINE=InnoDB;測試表資料
使用如下語句產生隨機測試資料:
DELIMITER // CREATE PROCEDURE populate_t0() BEGIN DECLARE i int DEFAULT 1; WHILE (i <= $table_size) DO INSERT INTO t0 VALUES (i, 1000000 * RAND()); SET i = i + 1; END WHILE; END // DELIMITER ; CALL populate_t0();說明實際測試時請將
$table_size替換成具體的表內記錄數,如1000000。本測試分別使用了包含1000000行、10000000行、100000000行、1000000000行記錄數的表。
測試使用的DDL操作
add primary keyadd secondary Indexoptimize table
測試方法
測試一:測試當物理複製DDL最佳化功能開啟或關閉時,在不同資料量的表中執行不同DDL操作所需的時間。
測試二:測試當物理複製DDL最佳化功能與並行DDL配合使用時,在包含10億資料量的表中執行
add secondary Index操作所需的時間。測試三:測試當物理複製DDL最佳化功能開啟或關閉時,叢集(包含10億資料量的表)中主節點的並發執行DDL運算元量不同的情況下(1、2、4、6和8),唯讀節點的效能(如節點狀態是否正常、CPU使用率峰值和複寫延遲時間等)。
測試結果
測試一
當innodb_bulk_load_page_grained_redo_enable參數開啟或關閉時,測試在不同資料量(1百萬、1千萬、1億和10億)的表中執行
add primary key(a)操作所需的時間(單位:秒),結果如下圖所示。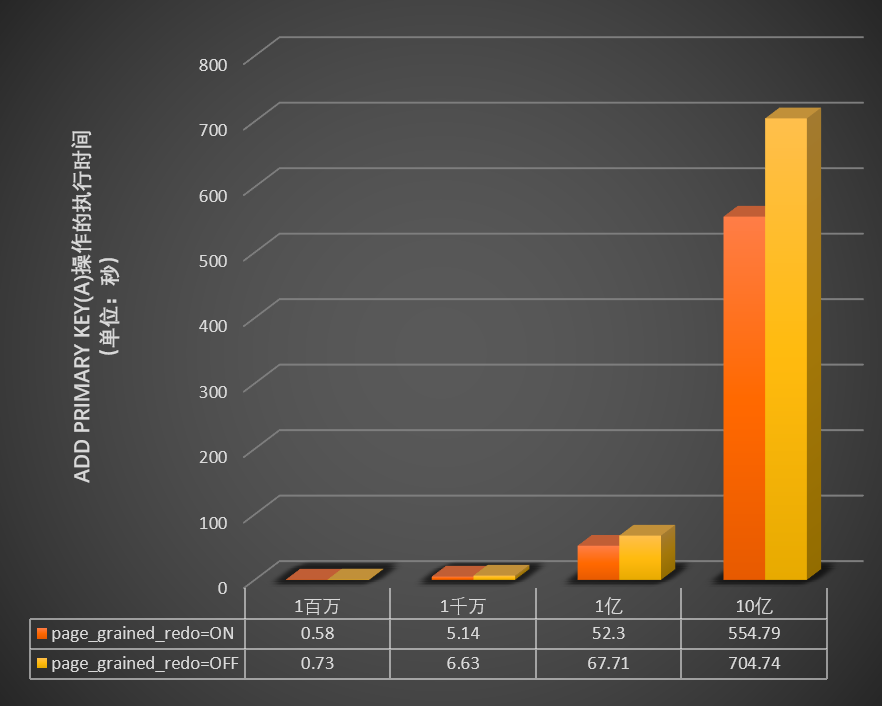
當innodb_bulk_load_page_grained_redo_enable參數開啟或關閉時,測試在不同資料量(1百萬、1千萬、1億和10億)的表中執行
optimize table操作所需的時間(單位:秒),結果如下圖所示。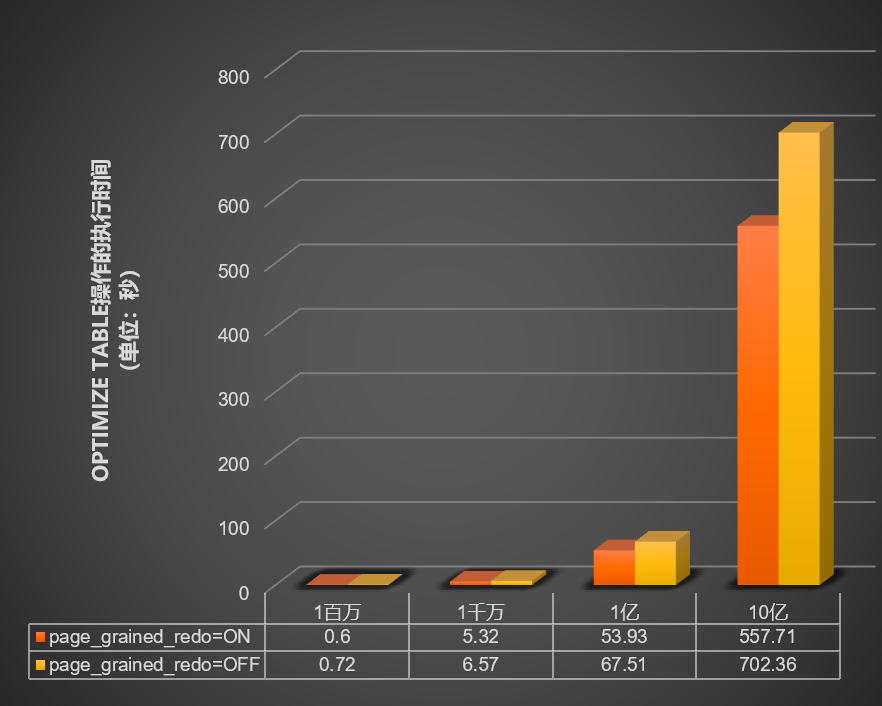
測試二
並行DDL的innodb_polar_use_sample_sort和innodb_polar_use_parallel_bulk_load參數開啟的情況下,測試innodb_bulk_load_page_grained_redo_enable參數開啟或關閉後,在包含10億資料量的表中使用不同並行線程數(即設定innodb_polar_parallel_ddl_threads參數為1、2、4、8、16和32),執行
add secondary Index操作所需的時間(單位:秒),結果如下圖所示。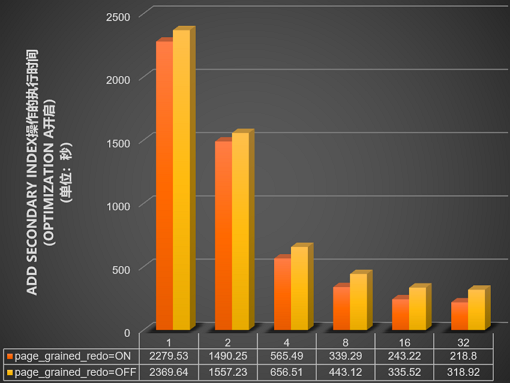
並行DDL的innodb_polar_use_sample_sort和innodb_polar_use_parallel_bulk_load參數關閉的情況下,測試innodb_bulk_load_page_grained_redo_enable參數開啟或關閉後,在包含10億資料量的表中使用不同並行線程數(1、2、4、8、16和32),執行
add secondary Index操作所需的時間(單位:秒),結果如下圖所示。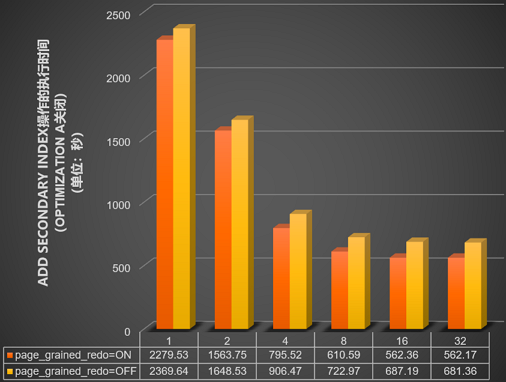
測試三
innodb_bulk_load_page_grained_redo_enable參數開啟的情況下,測試當叢集(包含10億資料量的表)中主節點的並發執行DDL運算元量不同(1、2、4、6和8)時唯讀節點的效能,結果如下表所示。
並發DDL數量
1
2
4
6
8
唯讀節點狀態
正常
正常
正常
正常
正常
CPU使用率峰值(單位:%)
1.86
1.71
1.76
2.25
2.36
記憶體使用量率峰值(單位:%)
10.37
10.80
10.88
11
11.1
讀IOPS峰值(單位:次/每秒)
10965
10762
10305
10611
10751
複寫延遲峰值(單位:秒)
0
0.73
0.87
0.93
0.03
innodb_bulk_load_page_grained_redo_enable參數關閉的情況下,測試當叢集(包含10億資料量的表)中主節點的並發執行DDL運算元量不同(1、2、4、6和8)時唯讀節點的效能,結果如下表所示。
說明並發DDL數為4時的資料為唯讀節點不可用前的測試資料。
表中
-符號表示在當前並發DDL數情境下未能執行相關DDL操作,因此無相應測試資料。
並發DDL數
1
2
4
6
8
唯讀節點狀態
正常
正常
不可用
不可用
不可用
CPU使用率峰值(單位:%)
4.2
9.5
10.3
-
-
記憶體使用量率峰值(單位:%)
22.15
23.55
68.61
-
-
讀IOPS峰值(單位:次/每秒)
9243
7578
7669
-
-
複寫延遲峰值(單位:秒)
0.8
14.67
211
-
-
聯絡我們
若您對DDL操作有任何疑問,請聯絡我們。