PolarDB新增支援並行DDL的功能。當資料庫硬體資源空閑時,您可以通過並行DDL功能加速DDL執行,避免阻塞後續相關的DML操作,縮短執行DDL操作的視窗期。
適用範圍
建立二級索引時,PolarDB叢集版本需滿足如下條件之一:
PolarDB MySQL版8.0.2版本且修訂版本為8.0.2.1.7及以上。
PolarDB MySQL版8.0.1版本且修訂版本為8.0.1.1.10及以上。
PolarDB MySQL版5.7版本且修訂版本為5.7.1.0.7及以上
建立主鍵索引時,PolarDB叢集版本需滿足如下條件之一:
PolarDB MySQL版8.0.2版本且修訂版本為8.0.2.2.9及以上。
PolarDB MySQL版8.0.1版本且修訂版本為8.0.1.1.31及以上。
如何確認叢集版本,詳情請參見查詢版本號碼。
注意事項
開啟並行DDL功能後,由於並行線程數的增加,硬體資源(如CPU、記憶體、IO等)的佔用也會隨之增加,可能會影響同一時間內執行的其他SQL操作,因此建議在業務低峰或硬體資源充足時使用並行DDL。
使用限制
目前並行DDL加速支援建立主鍵索引和二級索引(不包括全文索引、空間索引和虛擬列上的二級索引)的DDL操作。
背景資訊
傳統的DDL操作基於單核和傳統硬碟設計,導致針對大表的DDL操作耗時較久,延遲過高。以建立二級索引為例,過高延遲的DDL操作會阻塞後續依賴新索引的DML查詢操作。多核處理器的發展為並行DDL使用更多線程數提供了硬體支援,而固態硬碟(Solid State Disk,簡稱SSD)的普及使得隨機訪問延遲與順序訪問延遲相近,使用並行DDL加速大表的索引建立顯得尤為重要。
使用方法
innodb_polar_parallel_ddl_threads
您可以通過如下innodb_polar_parallel_ddl_threads參數開啟並行DDL功能:
參數
層級
說明
innodb_polar_parallel_ddl_threads
Session
控制每一個DDL操作的並行線程數。取值範圍:1~16。預設值為1,即執行單線程DDL。
若該參數值不為1,當執行建立二級索引操作時將自動開啟並行DDL。
說明該參數取值為1的時候,系統預設開啟2個並行線程數。
innodb_parallel_build_primary_index
您可以通過如下innodb_parallel_build_primary_index參數控制允許建立主鍵索引時使用並行DDL功能:
說明如果需要使用並行建立主鍵索引功能,請前往配額中心,在配額ID為polardb_mysql_pddl_for_pk的操作列,單擊申請,申請試用。
參數
層級
說明
innodb_parallel_build_primary_index
Global
控制是否允許建立主鍵索引時使用並行DDL功能。取值範圍如下:
ON:允許建立主鍵索引時使用並行DDL功能
OFF:不允許建立主鍵索引時使用並行DDL功能(預設值)
innodb_polar_use_sample_sort
若僅開啟並行DDL功能仍不能滿足您的需求,您可以通過innodb_polar_use_sample_sort參數對建立索引過程中的排序進行進一步最佳化。
參數
層級
說明
innodb_polar_use_sample_sort
Session
sample sort最佳化功能開關,取值範圍如下:
ON:開啟sample sort最佳化功能開關
OFF:關閉sample sort最佳化功能開關(預設值)
innodb_polar_use_parallel_bulk_load
若上述功能仍不能滿足您的需求,您還可以通過innodb_polar_use_parallel_bulk_load參數對建立索引樹的過程進行進一步最佳化。
參數
層級
說明
innodb_polar_use_parallel_bulk_load
Session
並行bulk load最佳化功能開關,取值範圍如下:
ON:開啟並行bulk load最佳化功能開關
OFF:關閉並行bulk load最佳化功能開關(預設值)
效能測試
測試環境
一個規格為16核128 GB的標準版PolarDB MySQL版8.0版本的叢集。
叢集儲存空間為50 TB。
測試表結構
通過如下語句建立一張名為
t0的表:CREATE TABLE t0( a INT PRIMARY KEY, b INT) ENGINE=InnoDB;測試表資料
通過如下語句產生測試資料:
DELIMITER // CREATE PROCEDURE populate_t0() BEGIN DECLARE i int DEFAULT 1; WHILE (i <= $table_size) DO INSERT INTO t0 VALUES (i, 1000000 * RAND()); SET i = i + 1; END WHILE; END // DELIMITER ; CALL populate_t0() ;說明實際測試時請將
$table_size替換成具體的表內記錄數,如1000000。本測試分別使用了包含1000000行、10000000行、100000000行、1000000000行記錄數的表,以及一張包含1 TB資料量的表。
1 TB資料量的測試用表通過Sysbench工具產生。如何使用Sysbench工具,請參見測試載入器。
測試方法
當使用不同的並行線程數(即設定innodb_polar_parallel_ddl_threads參數為1、2、4、8、16和32)時,測試在不同資料量的表中開啟並行DDL後,在資料類型為
INT的欄位b上建立二級索引帶來的DDL執行效率的提升比例。測試結果
僅開啟innodb_polar_parallel_ddl_threads參數後,並行DDL加速比結果如下圖所示。
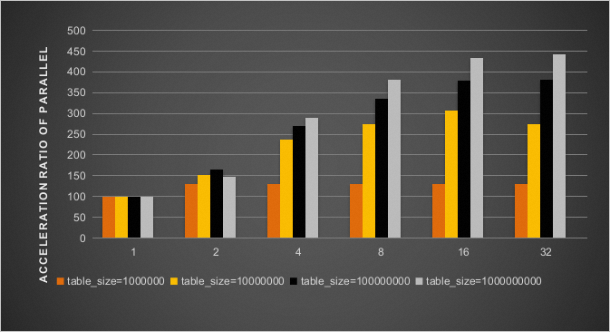
同時開啟innodb_polar_parallel_ddl_threads和innodb_polar_use_sample_sort參數後,並行DDL加速比結果如下圖所示。
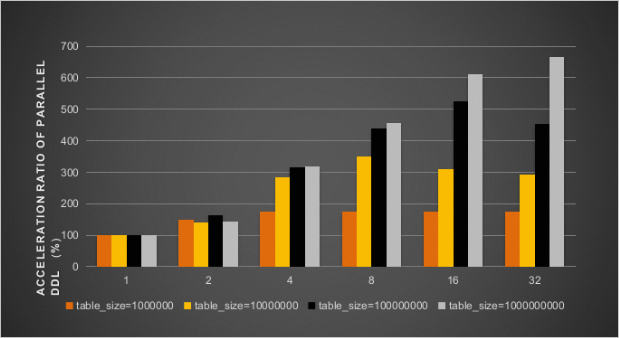
同時開啟innodb_polar_parallel_ddl_threads、innodb_polar_use_sample_sort和innodb_polar_use_parallel_bulk_load參數後,並行DDL加速比結果如下圖所示。
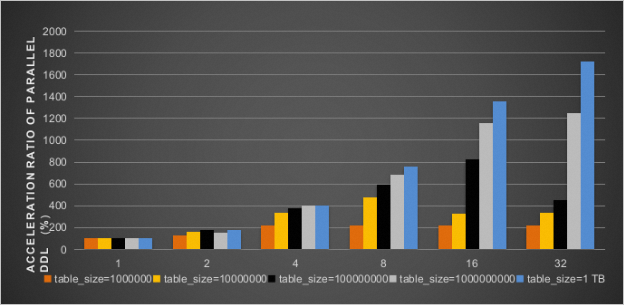
聯絡我們
若您對DDL操作有任何疑問,請聯絡我們。