本文以Kohya訓練任務為例,為您介紹如何以獨立或整合的方式部署訓練情境的彈性Job服務。並介紹調用該服務執行訓練、擷取訓練結果、終止任務以及查詢相關日誌的操作步驟。
前提條件
已建立OSS儲存空間(Bucket),用於儲存訓練獲得的模型檔案和設定檔。關於如何建立儲存空間,詳情請參見建立儲存空間。
部署訓練情境的彈性Job服務
本方案以PAI提供的預置鏡像kohya_ss為例,為您介紹如何部署Auto Scaling的kohya訓練服務:
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
部署訓練服務。
支援以下兩種部署方式:
整合部署
通過整合方式部署Kohya訓練服務,包括佇列服務、常駐的前端服務和彈性Job服務。具體操作步驟如下:
單擊部署服務,然後在自訂模型部署地區,單擊JSON獨立部署。
在JSON編輯框中填入配置資訊。
{ "cloud": { "computing": { "instance_type": "ecs.gn6i-c4g1.xlarge" } }, "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "features": { "eas.aliyun.com/extra-ephemeral-storage": "30Gi" }, "front_end": { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8001, "script": "python -u kohya_gui.py --listen 0.0.0.0 --server_port 8001 --data-dir /workspace --headless --just-ui --job-service" }, "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJobService" }, "name": "kohya_job", "storage": [ { "mount_path": "/workspace", "oss": { "path": "oss://examplebucket/kohya/", "readOnly": false }, "properties": { "resource_type": "model" } } ] }其中關鍵參數說明如下:
參數
描述
metadata
name
自訂服務名稱,在同地區內唯一。
type
服務類型,設定為ScalableJobService,表示整合部署。
enable_webservice
設定為true,表示部署前端AI-Web應用。
front_end
image
前端執行個體鏡像。鏡像選擇kohya_ss,鏡像版本選擇2.2。
說明由於版本迭代迅速,部署時鏡像版本選擇最高版本即可。
script
前端執行個體的啟動命令,設定為
python -u kohya_gui.py --listen 0.0.0.0 --server_port 8000 --headless --just-ui --job-service。其中:--listen:用於將本程式綁定到指定的本機IP地址上,接收外部請求並進行處理。
--server_port:監聽連接埠號碼。
--just-ui:啟動獨立前端模式,前端服務僅支援展示功能。
--job-service:訓練任務由彈性Job服務執行。
port
連接埠號碼。必須與containers.script中的server_port參數值一致。
containers
image
彈性Job服務的鏡像。如果不配置預設和前端執行個體鏡像一致。
instance_type
彈性Job服務的執行個體的資源規格配置,必須選擇GPU類型。若未配置該參數,則資源規格與cloud.computing.instance_type一致。
storage
path
以OSS掛載為例,請選擇同地區下的OSS路徑,用於儲存訓練產生的模型檔案。本方案樣本為
oss://examplebucket/kohya/。readOnly
設定為false,否則模型檔案無法儲存到OSS中。
mount_path
掛載路徑,可自訂。本方案配置為
/workspace。cloud
instance_type
前端服務執行個體的資源規格配置,選擇CPU類型即可。
單擊部署。
獨立部署
需要分別部署彈性Job服務和前端服務,彈性Job服務可接收多個前端服務的訓練工作要求。具體操作步驟如下:
部署彈性Job服務。
單擊部署服務,然後在自訂模型部署地區,單擊JSON獨立部署。
在JSON編輯框中填入彈性Job服務的配置資訊。
{ "cloud": { "computing": { "instance_type": "ecs.gn6i-c4g1.xlarge" } }, "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "features": { "eas.aliyun.com/extra-ephemeral-storage": "30Gi" }, "metadata": { "instance": 1, "name": "kohya_scalable_job", "type": "ScalableJob" }, "storage": [ { "mount_path": "/workspace", "oss": { "path": "oss://examplebucket/kohya/", "readOnly": false }, "properties": { "resource_type": "model" } } ] }其中關鍵參數說明如下:
參數
描述
metadata
name
自訂服務名稱。同地區內唯一。
type
服務類型。設定為ScalableJob,表示獨立部署。
containers
image
彈性Job服務的鏡像。鏡像選擇kohya_ss,鏡像版本選擇2.2。
說明由於版本迭代迅速,部署時鏡像版本選擇最高版本即可。
storage
path
本方案以OSS掛載為例,請選擇同地區下的OSS路徑,用來儲存訓練產生的模型檔案。本方案樣本為
oss://examplebucket/kohya/。readOnly
設定為false,否則模型檔案無法儲存到OSS中。
mount_path
掛載路徑,可自訂。本方案配置為
/workspace。cloud
instance_type
彈性Job服務的資源規格配置。kohya訓練任務必須選擇GPU類型。
單擊部署。
服務部署成功後,單擊服務方式列下的調用資訊,在公網地址調用頁簽下擷取服務訪問地址和Token,並儲存到本地。
(可選)部署前端服務。
單擊部署服務,然後在自訂模型部署地區,單擊JSON獨立部署。
在JSON編輯框中填入前端服務的配置資訊。
{ "cloud": { "computing": { "instance_type": "ecs.g6.large" } }, "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8000, "script": "python kohya_gui.py --listen 0.0.0.0 --server_port 8000 --headless --just-ui --job-service --job-service-endpoint 166233998075****.vpc.cn-hangzhou.pai-eas.aliyuncs.com --job-service-token test-token --job-service-inputname kohya_scalable_job" } ], "metadata": { "enable_webservice": true, "instance": 1, "name": "kohya_scalable_job_front" }, "storage": [ { "mount_path": "/workspace", "oss": { "path": "oss://examplebucket/kohya/", "readOnly": false }, "properties": { "resource_type": "model" } } ] }其中關鍵參數說明如下:
參數
描述
metadata
name
自訂前端服務名稱。
enable_webservice
設定為true,表示部署前端AI-Web應用。
containers
image
前端服務鏡像。鏡像選擇kohya_ss,鏡像版本選擇2.2。
說明由於版本迭代迅速,部署時鏡像版本選擇最高版本即可。
script
前端服務的啟動命令,設定為
python kohya_gui.py --listen 0.0.0.0 --server_port 8000 --headless --just-ui --job-service --job-service-endpoint 166233998075****.vpc.cn-hangzhou.pai-eas.aliyuncs.com --job-service-token test-token --job-service-inputname kohya_scaled_job。其中:--listen:用於將本程式綁定到指定的本機IP地址上,接收外部請求並進行處理。
--server_port:監聽連接埠號碼。
--just-ui:啟動獨立前端模式,前端服務僅支援展示功能。
--job-service:訓練任務由彈性Job服務執行。
--job-service-endpoint:彈性Job服務的Endpoint。
--job-service-token:彈性Job服務的token。
--job-service-inputname:彈性Job服務的服務名稱。
port
連接埠號碼。必須與containers.script中的server_port參數值一致。
storage
path
本方案以OSS掛載為例,請選擇同地區下的OSS路徑,用來儲存訓練產生的模型檔案。本方案樣本為
oss://examplebucket/kohya/。readOnly
設定為false,否則模型檔案無法儲存到OSS中。
mount_path
掛載路徑,可自訂。本方案配置為
/workspace。cloud
instance_type
前端服務執行個體的資源規格配置,選擇CPU類型即可。
單擊部署。
調用Kohya訓練服務
通過WebUI頁面調用彈性Job服務
如果您使用EAS預置的Kohya鏡像部署前端服務,該鏡像(2.2及其以上版本)已支援彈性Job服務功能。服務部署成功後,您可以單擊服務方式列下的查看Web應用,在WebUI頁面配置Lora訓練參數,進行Kohya模型訓練,詳情請參見訓練LoRA模型。
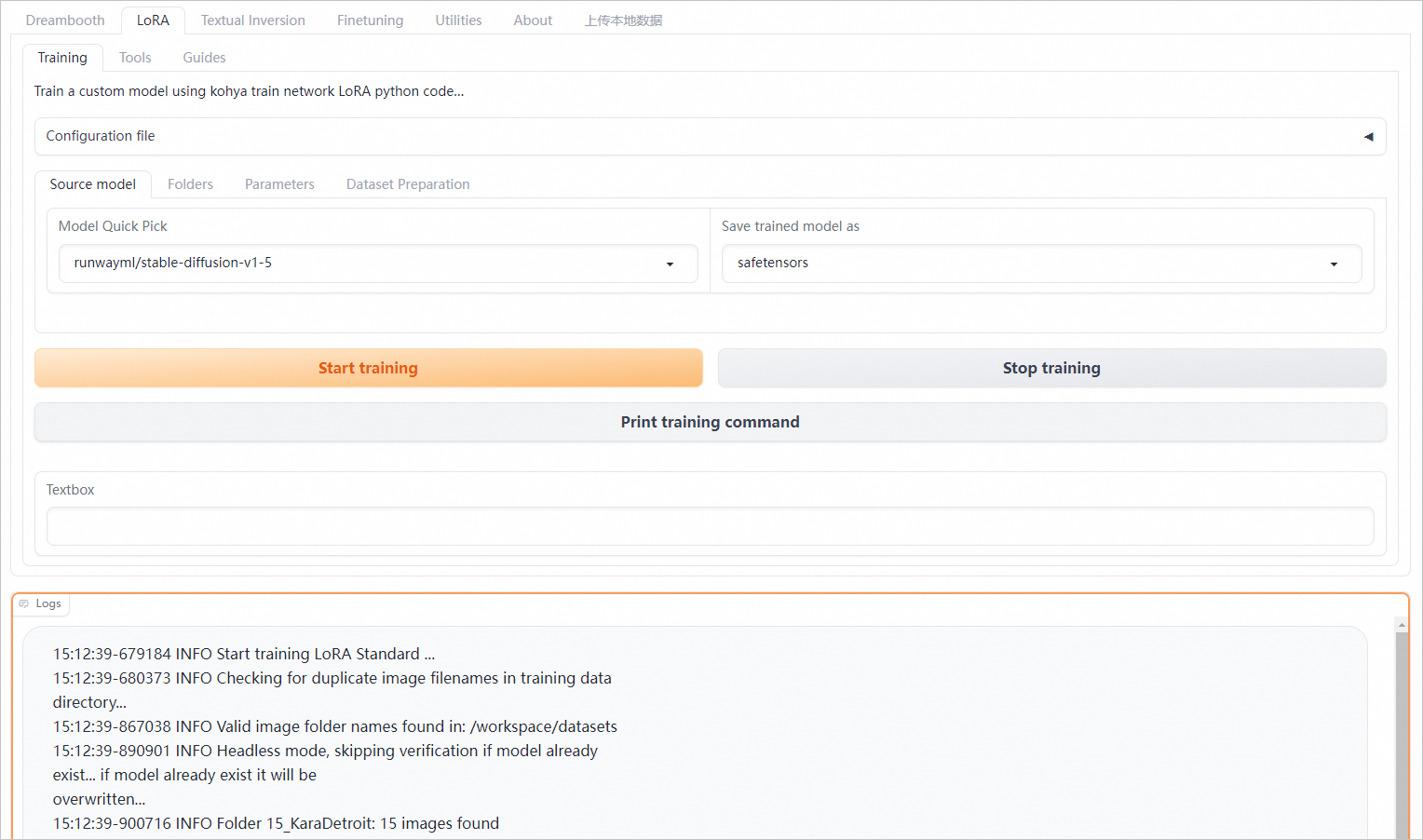
單擊Start training按鈕,即可發送訓練工作要求。在訓練任務完成或被終止前,再次單擊該按鈕無效。彈性Job服務的執行個體會根據訓練任務個數自動Auto Scaling。
單擊Stop training按鈕,可終止當前訓練任務。
自訂前端服務鏡像調用彈性Job服務
您也可以通過以下Python SDK調用彈性Job服務,向彈性job服務的隊列發送command工作要求以及擷取任務執行日誌。如果您使用自訂鏡像部署前端服務,則需要在自訂鏡像中實現以下介面的功能,以便通過WebUI調用彈性Job服務。調用步驟如下所示:
查詢彈性Job服務的訪問地址和Token。
整合部署
在模型線上服務(EAS)頁面中,單擊服務名稱進入服務詳情頁面。在基本資料地區,單擊查看調用資訊。在公網地址調用頁簽中,擷取服務訪問地址和Token。其中:
服務訪問地址:格式為
<queue_name>.<service_name>.<uid>.<region>.pai-eas.aliyuncs.com,例如kohya-job-queue-b****4f0.kohya-job.175805416243****.cn-beijing.pai-eas.aliyuncs.com。其中<queue_name>為佇列服務執行個體名稱-0之前的部分,您可以在服務詳情頁面的服務執行個體列表中進行查看。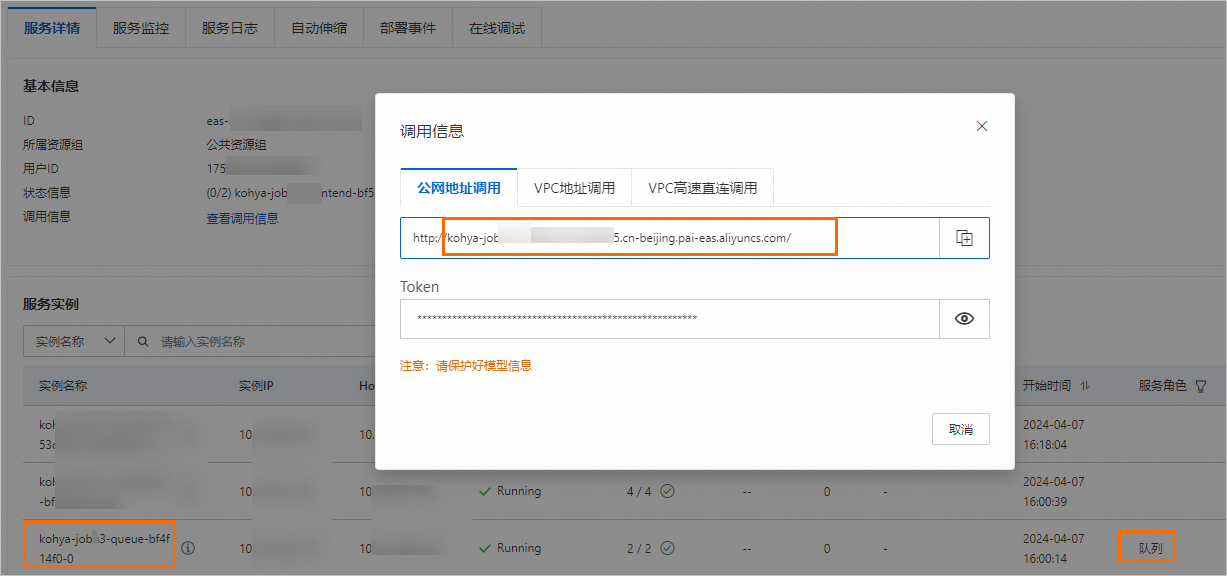
Token:樣本為
OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==。
獨立部署
在模型線上服務(EAS)頁面中,單擊彈性Job服務的服務方式列下的調用資訊,擷取服務訪問地址和Token。其中:
服務訪問地址:樣本為
175805416243****.cn-beijing.pai-eas.aliyuncs.com。Token:樣本為
Njk5NDU5MGYzNmRlZWQ3ND****QyMDIzMGM4MjExNmQ1NjE1NzY5Mw==。
安裝Python SDK。
pip install -U eas-prediction --user關於SDK更多介面的詳細介紹,請參見Python SDK使用說明。
分別為輸入隊列和輸出隊列建立用戶端。
整合部署
from eas_prediction import QueueClient if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # 建立輸入隊列,用於發送command任務的訓練請求和終止請求。 inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 建立輸出隊列,用於擷取command執行狀態和日誌。 sinkQueue = QueueClient(custom_url = sink_url) sinkQueue.set_token(token) sinkQueue.init()其中:
token:替換為上述步驟已擷取的Token。
input_url:替換為上述步驟已擷取的服務訪問地址。
獨立部署
from eas_prediction import QueueClient if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'YmE3NDkyMzdiMzNmMGM3ZmE4ZmNjZDk0M2NiMDA3OT****c1MTUxNg==' input_name = 'kohya_scalable_job' sink_name = input_name + '/sink' # 建立輸入隊列,用於發送command任務的訓練請求和終止請求。 inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init() # 建立輸出隊列,用於擷取command執行狀態和日誌。 sinkQueue = QueueClient(endpoint, sink_name) sinkQueue.set_token(token) sinkQueue.init()其中:
endpoint:替換為上述步驟已擷取的服務訪問地址。
token:替換為上述步驟已擷取的服務Token。
input_name:配置為彈性Job服務名稱。
向輸入隊列發送任務訓練請求。
整合部署
from eas_prediction import QueueClient import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # 建立輸入隊列用戶端,用於發送command請求。 inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 為每個工作要求產生唯一的taskId。 task_id = uuid.uuid1().hex # 建立command字串。 cmd = "for i in {1..10}; do date; sleep 1; done;" # 指定taskType為command,指定taskId。 tags = {"taskType": "command", "taskId": task_id} # 向輸入隊列發送command訓練工作要求。 index, request_id = inputQueue.put(cmd, tags) print(f'send index: {index}, request id: {request_id}')其中關鍵參數說明如下:
參數
描述
token
替換為上述步驟已擷取的Token。
input_url
替換為上述步驟已擷取的服務訪問地址。
cmd
配置為需要執行的命令。Python指令需要加-u參數以便即時輸出任務執行時的日誌。
tags
對於訓練工作要求:
taskType:必須配置為command。
taskId:訓練任務ID,唯一標識訓練任務。
獨立部署
from eas_prediction import QueueClient import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYj****djN2IyODc1MTM5ZQ==' input_name = 'kohya_scalable_job' # 建立輸入隊列用戶端,用於發送command請求。 inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 為每個工作要求產生唯一的taskId。 task_id = uuid.uuid1().hex # 建立command字串。 cmd = "for i in {1..10}; do date; sleep 1; done;" # 指定taskType為command,指定taskId。 tags = {"taskType": "command", "taskId": task_id} # 向輸入隊列發送command訓練工作要求。 index, request_id = inputQueue.put(cmd, tags) print(f'send index: {index}, request id: {request_id}')其中關鍵參數說明如下:
參數
描述
endpoint
按照上述代碼中的配置樣本,替換為上述步驟已擷取的服務訪問地址。
token
替換為上述步驟已擷取的服務Token。
cmd
配置為需要執行的命令。Python指令需要加-u參數以便即時輸出任務執行時的日誌。
tags
對於訓練工作要求:
taskType:必須配置為command。
taskId:訓練任務ID,唯一標識訓練任務。
查詢請求排隊狀態。
整合部署
from eas_prediction import QueueClient import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # 建立輸入隊列用戶端,用於發送command請求。 inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 向輸入隊列發送command請求。 task_id = uuid.uuid1().hex cmd = "for i in {1..100}; do date; sleep 1; done;" tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # 查詢請求資料的排隊狀態。 search_info = inputQueue.search(index) print("index: {}, search info: {}".format(index, search_info))其中:
token:替換為上述步驟已擷取的Token。
input_url:替換為上述步驟已擷取的服務訪問地址。
獨立部署
from eas_prediction import QueueClient import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYjBjOTdjN2I****1MTM5ZQ==' input_name = 'kohya_scalable_job' # 建立輸入隊列用戶端,用於發送command請求。 inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 向輸入隊列發送command請求。 task_id = uuid.uuid1().hex cmd = "for i in {1..100}; do date; sleep 1; done;" tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # 查詢請求資料的排隊狀態。 search_info = inputQueue.search(index) print("index: {}, search info: {}".format(index, search_info))其中:
endpoint:替換為上述步驟已擷取的服務訪問地址中的endpoint。
token:替換為上述步驟已擷取的服務Token。
返回JSON格式的資料:
{ 'IsPending': False, 'WaitCount': 0 }返回欄位說明如下:
參數
描述
IsPending
表示請求是否正在被處理。可能值為:
True:表示請求正在被處理。
False:表示請求正在排隊。
WaitCount
表示該請求在排隊隊列中排第幾位。僅IsPending為False時該值才有效,IsPending為True時該值為0。
從輸出隊列中擷取執行結果。
訓練任務的執行日誌會即時寫入到輸出隊列中,可調用
queue.get(request_id=request_id, length=1, timeout='0s', tags=tags)從輸出隊列即時擷取指定task_id的訓練任務的輸出日誌。調用樣本如下:整合部署
from eas_prediction import QueueClient import json import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # 建立輸入隊列用戶端,用於發送command請求。 inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 建立輸出隊列用戶端,用於擷取command執行日誌。 sinkQueue = QueueClient(custom_url = sink_url) sinkQueue.set_token(token) sinkQueue.init() # 向輸入隊列發送command請求。 cmd = "for i in {1..10}; do date; sleep 1; done;" task_id = uuid.uuid1().hex tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # 從輸出隊列即時擷取指定taskId的訓練任務的輸出日誌。 running = True while running: dfs = sinkQueue.get(length=1, timeout='0s', tags=tags) if len(dfs) == 0: continue df = dfs[0] data = json.loads(df.data.decode()) state = data["state"] print(data.get("log", "")) if state in {"Exited", "Stopped", "Fatal", "Backoff"}: running = False其中:
token:替換為上述步驟已擷取的Token。
input_url:替換為上述步驟已擷取的服務訪問地址。
獨立部署
from eas_prediction import QueueClient import json import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYjBjOTdjN2IyOD****M5ZQ==' input_name = 'kohya_scalable_job' sink_name = input_name + '/sink' # 建立輸入隊列用戶端,用於發送command請求。 inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 建立輸出隊列用戶端,用於擷取command執行日誌。 sinkQueue = QueueClient(endpoint, sink_name) sinkQueue.set_token(token) sinkQueue.init() # 向輸入隊列發送command請求。 cmd = "for i in {1..10}; do date; sleep 1; done;" task_id = uuid.uuid1().hex tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # 從輸出隊列即時擷取指定taskId的訓練任務的輸出日誌。 running = True while running: dfs = sinkQueue.get(length=1, timeout='0s', tags=tags) if len(dfs) == 0: continue df = dfs[0] data = json.loads(df.data.decode()) state = data["state"] print(data.get("log", "")) if state in {"Exited", "Stopped", "Fatal", "Backoff"}: running = False其中:
endpoint:替換為上述步驟已擷取的服務訪問地址中的endpoint。
token:替換為上述步驟已擷取的服務Token。
返回資料Bytes類型的資料:
{ "taskId": "e97409eea4a111ee9cb600163e08****", "command": "python3 -u test.py --args=xxx", "state": "Running", "log": "prepare tokenizer\\n" }返回結果中各欄位說明如下:
欄位
描述
taskId
唯一標識訓練任務。
command
job執行的任務指令。
state
指令執行狀態:
Running:執行中。
Exited:已退出。
Fatal:執行異常。
Stopping:正在停止。
Stopped:已停止。
log
輸出日誌。完整的日誌會將同一taskId的日誌按照擷取順序輸出。
停止訓練任務。
發送command工作要求後如果想要停止該任務,需要區分該請求是在排隊狀態還是執行狀態。可通過queue.search(index)確認請求狀態,並根據擷取的請求狀態來處理訓練任務。樣本如下:
整合部署
from eas_prediction.queue_client import QueueClient import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # 建立輸入隊列用戶端,用於發送command請求和終止請求。 inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 向輸入隊列發送command請求。 cmd = "for i in {1..10}; do date; sleep 1; done;" task_id = uuid.uuid1().hex # 該工作要求的task_id。 tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) print(f'cmd send, index: {index}, task_id: {task_id}') job_index = index # 發送工作要求時返回的index。 pending_detail = inputQueue.search(job_index) print(f'search info: {pending_detail}') if len(pending_detail) > 0 and pending_detail.get("IsPending", True) == False: # command任務還在排隊中,直接從輸入隊列中刪除。 inputQueue.delete(job_index) print(f'delete task index: {job_index}') else: # command任務正在執行中,向輸入隊列發送stop訊號。 stop_data = "stop" tags = {"_is_symbol_": "true", "taskId": task_id} inputQueue.put(stop_data, tags) print(f'stop task index: {job_index}')其中關鍵參數說明如下:
參數
描述
token
替換為上述步驟已擷取的Token。
input_url
替換為上述步驟已擷取的服務訪問地址。
stop_data
設定為stop。
tags
_is_symbol_:必填,設定為true表示任務終止訊號。
task_id:表示需要終止的訓練任務的task_id。
獨立部署
from eas_prediction.queue_client import QueueClient import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYjBjOTdjN2IyODc1MTM5****' input_name = 'kohya_scalable_job' # 建立輸入隊列用戶端,用於發送command請求和終止請求。 inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # 向輸入隊列發送command請求。 cmd = "for i in {1..10}; do date; sleep 1; done;" # 該工作要求的task_id。 task_id = uuid.uuid1().hex tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) print(f'cmd send, index: {index}, task_id: {task_id}') job_index = index # 發送工作要求時返回的index。 pending_detail = inputQueue.search(job_index) print(f'search info: {pending_detail}') if len(pending_detail) > 0 and pending_detail.get("IsPending", True) == False: # command任務還在排隊中,直接從輸入隊列中刪除。 inputQueue.delete(job_index) print(f'delete task index: {job_index}') else: # command任務正在執行中,向輸入隊列發送stop訊號。 stop_data = "stop" tags = {"_is_symbol_": "true", "taskId": task_id} inputQueue.put(stop_data, tags) print(f'stop task index: {job_index}')其中關鍵參數說明如下:
參數
描述
endpoint
替換為上述步驟已擷取的服務訪問地址中的endpoint。
token
替換為上述步驟已擷取的服務Token。
stop_data
設定為stop。
tags
_is_symbol_:必填,設定為true表示任務終止訊號。
task_id:表示需要終止的訓練任務的task_id。
相關文檔
關於彈性Job服務更詳細的內容介紹,請參見彈性Job服務功能介紹。
如何在推理情境使用彈性Job服務,請參見部署寫真相機線上推理服務。