通過EAS,您可以一鍵部署開源Kohya_ss服務並訓練LoRA模型。在AI繪畫情境中,您可以將經過訓練的LoRA模型應用於Stable Diffusion(SD)服務,作為輔助模型,以提升SD繪畫的效果。
前提條件
已開通EAS並建立預設工作空間,詳情請參見開通PAI並建立預設工作空間。
如果使用RAM使用者來部署模型,需要為RAM使用者授予EAS的系統管理權限,詳情請參見雲產品依賴與授權:EAS。
已在同地區下建立OSS儲存空間和目錄,用來存放訓練素材、輸出的模型檔案、日誌等。如何上傳檔案請參見控制台上傳檔案。
準備工作
登入OSS管理主控台,進入某個同地區下的Bucket路徑內。例如:
oss://kohya-demo/kohya/。在當前Bucket路徑下建立專案檔夾。例如:
KaraDetroit_loar。同時,在此專案檔夾下建立Image、Log、Model3個檔案夾,如有JSON設定檔也可上傳至此專案檔夾。
Image:存放訓練素材源檔案。
Model:存放訓練完成後的模型檔案。
Log:存放日誌。
SS_config.json:JSON檔案,用於大量設定參數,非必需。使用時可在JSON配置中修改相關參數,如檔案夾路徑、輸出模型命名等。具體配置詳情可參考GitHub。文本樣本請參考SS_config.json。
將準備好的圖片上傳至
Image檔案夾下。本文使用的圖片及描述檔案樣本:100_pic.zip,將下載解壓後的檔案夾上傳到OSS,結果如下圖所示: 重要
重要圖片僅支援格式:
.png,.jpg,.jpeg,.webp,.bmp。每張圖片必須提供一個同名的描述檔案,格式可為
.txt,描述資訊必須放在第一行,如有多個描述資訊,可使用逗號分隔。圖片檔案夾命名必須符合格式:數字+底線+名稱。例如:100_pic。其中,名稱符合OSS檔案名稱規則的任一字元串,數字表示每張圖片重複訓練次數,一般要求大於等於100。總訓練次數一般要求大於1500。
若檔案夾內包含10張圖片,則每張圖片訓練
1500/10=150次,圖片檔案夾名數字部分可為“150”。若檔案夾內包含20張圖片,則每張圖片訓練
1500/20=75(<100)次,圖片檔案夾名數字部分可為“100”。
部署Kohya_ss服務
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
在推理服务頁簽,單擊部署服务,然後在自定义模型部署地區,單擊自定义部署。
在自訂部署頁面,可通過表單或JSON配置相關參數。
通過表單配置參數
參數
描述
基本資料
服務名稱
自訂服務名稱。本案例使用的樣本值為:kohya_ss_demo。
環境資訊
部署方式
選擇鏡像部署,並選中開啟Web應用。
鏡像配置
在官方鏡像列表中選擇kohya_ss>kohya_ss:2.2。
說明由於版本迭代迅速,部署時鏡像版本選擇最高版本即可。
儲存掛載
選擇OSS類型的掛載方式,並配置以下參數:
Uri:選擇同地區下的OSS路徑。本文為
oss://kohya-demo/kohya/。掛載路徑:可自訂。本文為
/workspace。重要是否唯讀必須將開關關閉。否則模型檔案無法輸出到OSS中。
運行命令
選擇鏡像後系統會自動設定運行命令。本文為:
python -u kohya_gui.py --listen=0.0.0.0 --server_port=8000 --headless。--listen:用於將本程式綁定到指定的本機IP地址上,接收外部請求並進行處理。--server_port:監聽連接埠號碼。
資源資訊
資源類型
選擇公用資源。
部署資源
資源規格推薦使用GPU>ml.gu7i.c16m60.1-gu30(性價比最高)。本文選擇了當前最小規格ml.gu7i.c8m30.1-gu30。
通過JSON配置參數
在服務配置中單擊編輯,並設定JSON格式資料。
JSON參考樣本如下。
重要以下樣本第4行"name",第18行"oss"等配置請按實際情況修改。
{ "metadata": { "name": "kohya_ss_demo", "instance": 1, "enable_webservice": true }, "cloud": { "computing": { "instance_type": "ecs.gn6e-c12g1.12xlarge", "instances": null } }, "storage": [ { "oss": { "path": "oss://kohya-demo/kohya/", "readOnly": false }, "properties": { "resource_type": "model" }, "mount_path": "/workspace" }], "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:1.2", "script": "python -u kohya_gui.py --listen=0.0.0.0 --server_port=8000 --headless", "port": 8000 }] }檢查表單配置後單擊部署,等待幾分鐘後即可完成模型部署。當服務狀態為運行中時,服務部署成功。
訓練LoRA模型
單擊目標服務概覽頁的Web應用,進入Kohya_ss服務。
選擇LoRA(LoRA)。

設定Configuration file。可選,若無
SS_config.json可跳過此步驟。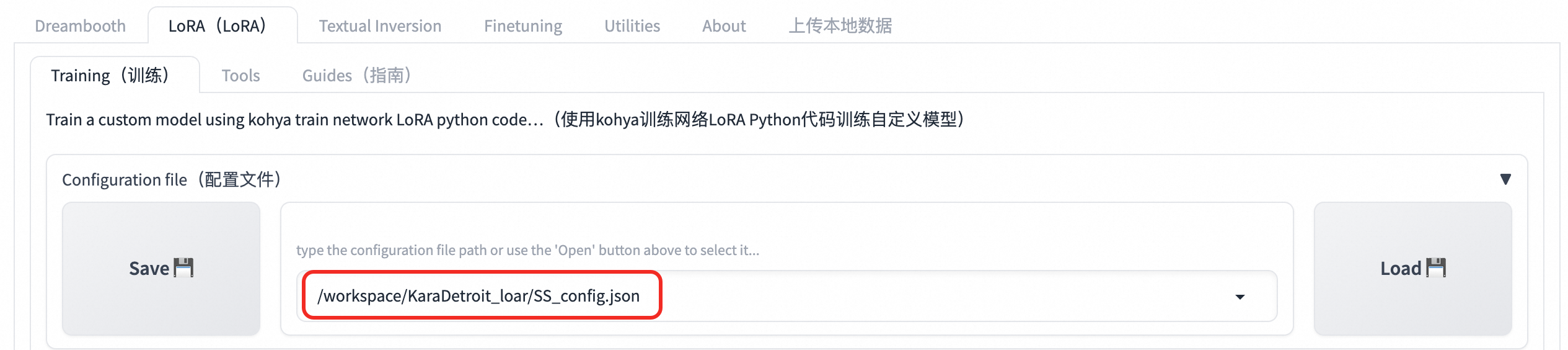 說明
說明設定檔路徑為通過表單配置參數中的掛載路徑+OSS中建立的檔案夾路徑+SS_config.json。在本文中為:
/workspace/KaraDetroit_loar/SS_config.json。設定SourceModel。本文使用safetensors,相比較checkpoint來說更具有安全性。

設定Folders。填寫前面步驟在OSS中所建立的
Image、Log、Model路徑和輸出檔案名。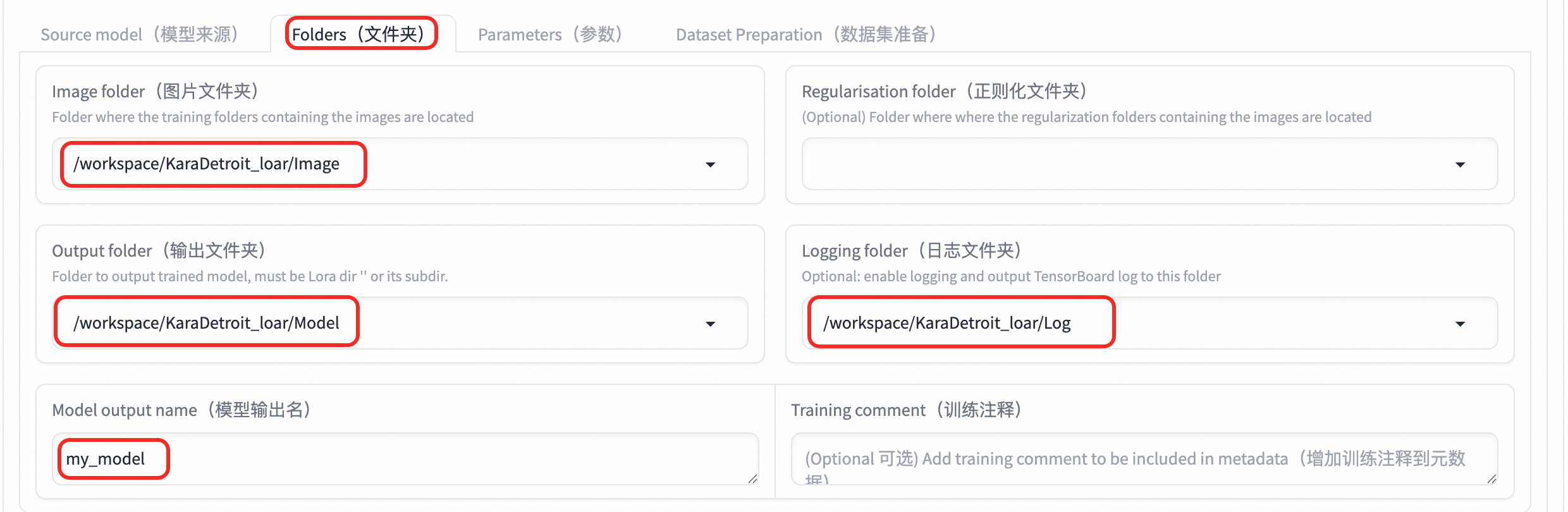
參數
描述
Image folder
需要訓練的圖片檔案夾路徑。設定為通過表單配置參數中的掛載路徑拼接OSS中建立的
Image路徑。在本文中為:/workspace/KaraDetroit_loar/Image。Logging folder
輸出日誌的檔案夾路徑。設定為通過表單配置參數中的掛載路徑拼接OSS中建立的
Log路徑。在本文中為:/workspace/KaraDetroit_loar/Log。Output folder
輸出模型的檔案夾路徑。設定為通過表單配置參數中的掛載路徑拼接OSS中建立的
Model路徑。在本文中為:/workspace/KaraDetroit_loar/Model。Model output name
模型輸出名稱。例如:my_model。
設定Parameters(參數)。樣本值見準備工作步驟中的
SS_config.json內容。參數
描述
LoRA Type
LoRA類型:
LoCON:可以調整SD的每一層。如:Res、Block、Transformer。LoHA:同樣大小處理更多資訊。
LoRA network weights
LoRA網路權重,如果要接著訓練則選用最後訓練的LoRA。選填。
Train batch size
訓練批量大小。該值越大,對顯存的要求越高。
Epoch
訓練輪數,將所有資料訓練一次為一輪。需要自行計算。一般情況下:
Kohya中總訓練次數 = 訓練圖片數量 x 重複次數 x 訓練輪數 / 訓練批量大小。WebUI中總訓練次數 = 訓練圖片數量 x 重複次數。
使用類別映像時,在Kohya或在WebUI中總訓練次數都會乘2,在Kohya中模型儲存次數會減半。
Save every N epochs
每N個訓練周期儲存一次。如設為2,則每完成2輪訓練儲存一次訓練結果。
Caption Extension
打標副檔名,例如:.txt。選填。
Mixed precision
混合精度。視顯卡效能決定。預設可選no、fp16、bf16。30GB顯存以上的顯卡建議設定為bf16。
Save precision
儲存精度,同上。
Number of CPU threads per core
CPU每核線程數。主要為顯存,根據所購執行個體和需求調整。
Learning rate
學習率。預設0.0001。
LR Scheduler
學習率調度器。按需選擇
cosine或cosine with restart等函數。LR Warmup(% of steps)
學習預熱步數。按需調節,預設為10,無需預熱則可選擇0。
Optimizer
最佳化器。按需選擇,預設
AdamW8bit,DAdaptation代表自動操作。Max Resolution
最大解析度。根據圖片情況進行設定。
Network Rank(Dimension)
模型複雜度。一般設定為128即可適應大部分情境。
Network Alpha
一般設定為比Network Rank(Dimension)小或者相同,常用的便是Network Rank設定為128,Network Alpha設定為64。
Convolution Rank(Dimension)
& Convolution Alpha
卷積度,LoRA對模型的微調涵蓋範圍。需根據不同的LoRA Type進行調整。
Kohya官方建議:
LoCon:dim <= 64,alpha = 1(或更低)。LoHA:dim <= 32,alpha = 1。
clip skip
使用的CLIP模型的次數,取值範圍是1到12,值越小,產生的映像就越接近原始映像或輸入映像。
寫實模型:選擇1。
二次元:選擇2。
Sample every n epoch
每N輪樣本。每幾輪儲存一次樣本。
Sample Prompts
提示詞樣本。需要使用命令,參數如下:
--n:提示詞、反向提示詞。--w:圖片寬度。--h:圖片高度。--d:映像種子。--l:提示詞相關性(cfg)。--s:迭代步數(steps)。
在頁面下方,單擊Start training開始進行訓練。

在模型線上服務(EAS)頁面的服務列表中單擊對應的服務名稱,進入服務詳情。單擊日誌即可即時查看訓練進度。
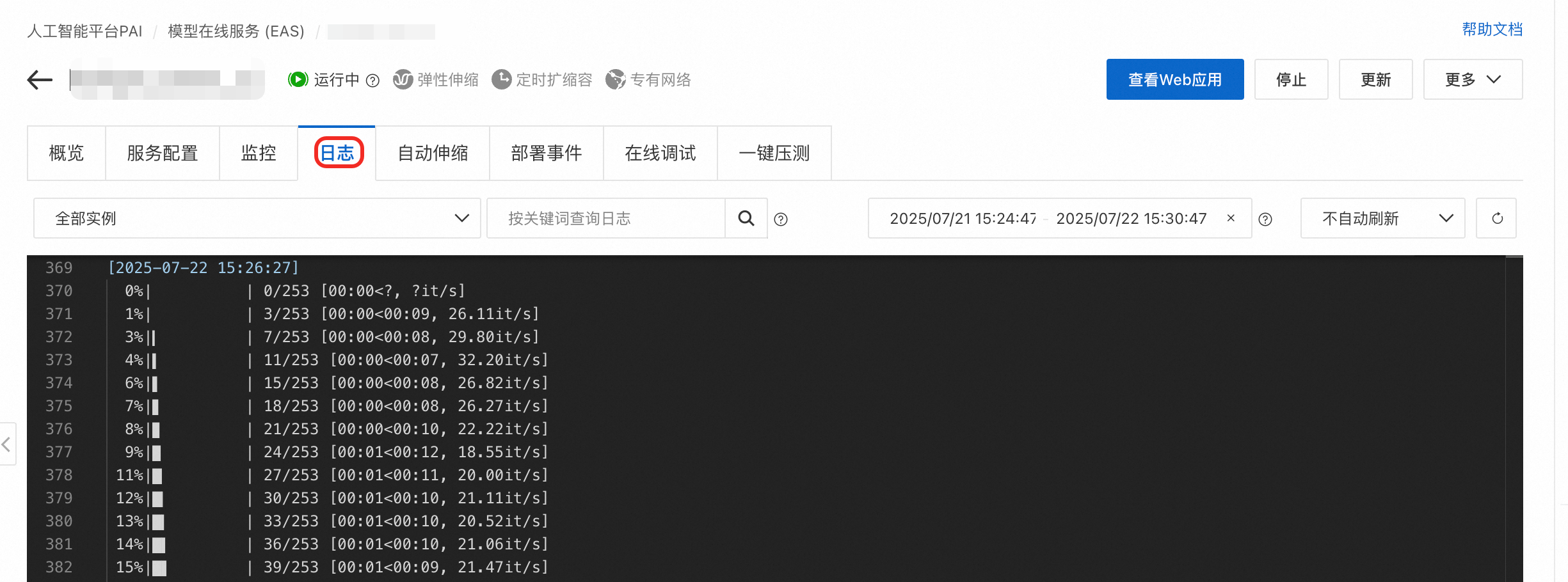
當出現
model saved即表示訓練完成。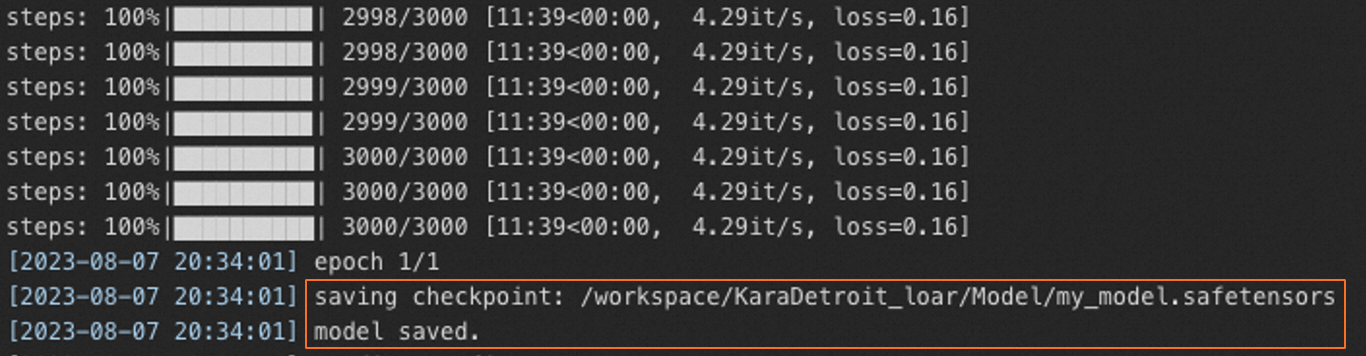
訓練完成後,在配置的模型目錄(
Model)中擷取訓練得到的LoRA模型檔案。例如:my_model.safetensors。
使用訓練的LoRA模型進行Stable Diffusion AIGC繪畫
當您訓練好自己的LoRA模型後,可將其上傳到相應的SD WebUI的目錄中進行掛載使用,從而實現利用自己訓練的LoRA模型產生圖片。如何部署Stable Diffusion服務,可參考:5分鐘使用EAS一鍵部署Stable Diffusion實現文生圖能力。
如何在Stable Diffusion WebUI中上傳LoRA模型檔案,詳情設定如下:
Stable Diffusion WebUI的叢集版(Cluster)
配置Stable Diffusion WebUI鏡像,需選擇-cluster版本(例如stable-diffusion-webui:4.2-cluster-webui)。服務啟動成功後會在掛載的OSS路徑下自動建立
/data-{當前登入使用者ID}/models/Lora路徑。在運行命令中添加以下參數:
--lora-dir,選擇性參數。--lora-dir未指定時,所有使用者的模型檔案隔離,只載入{OSS路徑}/data-{當前登入使用者ID}/models/Lora下的模型檔案。--lora-dir指定時,所有使用者均會載入該目錄以及{OSS路徑}/data-{當前登入使用者ID}/models/Lora目錄下的模型檔案。例如:--lora-dir /code/stable-diffusion-webui/data-oss/models/Lora。
--data-dir {OSS掛載路徑},例如:--data-dir /code/stable-diffusion-webui/data-oss。
將LoRA模型檔案上傳到
{OSS路徑}/data-{當前登入使用者ID}/models/Lora中。例如:oss://bucket-test/data-oss/data-1596******100/models/Lora。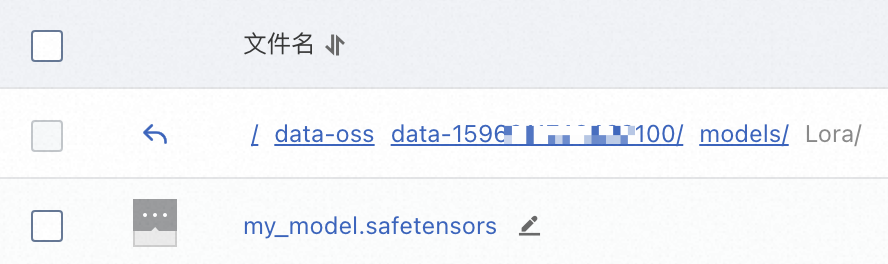 說明
說明OSS中的
/data-{當前登入使用者ID}/models/Lora路徑會在當前服務啟動成功後自動建立,因此需在服務啟動成功後再上傳LoRA模型檔案。{當前登入使用者ID}可在頁面右上方的個人頭像處查看。
Stable Diffusion WebUI的單機版
配置Stable Diffusion WebUI鏡像,需選擇非
-cluster版本(例如stable-diffusion-webui:4.2-standard)。服務啟動成功後會在掛載的OSS路徑下自動建立/models/Lora路徑。在運行命令中添加參數:
--data-dir {OSS掛載路徑}。例如:--data-dir /code/stable-diffusion-webui/data-oss。將LoRA模型檔案上傳到
{OSS路徑}/models/Lora下。例如:oss://bucket-test/data-oss/models/Lora。 說明
說明掛載的OSS中的
/models/Lora路徑會在當前服務啟動成功後自動建立,無需自行建立。因此需要在服務啟動成功後再上傳LoRA模型檔案。