為了增強模型產生答案的準確性和資訊豐富度,您可以在大模型RAG服務中整合OpenSearch向量檢索版產品。該產品支援多種向量檢索演算法,高效能支援多種典型情境,並提供圖形化介面,您可以查看索引資訊並實現簡單的資料管理功能。通過整合OpenSearch向量檢索版產品,可以提升RAG對話系統的檢索效率和使用者體驗。本文將介紹如何在部署RAG服務時關聯OpenSearch向量檢索版產品,以及對RAG對話系統的基礎功能和OpenSearch向量檢索版的特色功能進行說明。
背景資訊
EAS簡介
EAS(Elastic Algorithm Service)是PAI的模型線上服務平台,支援將模型部署為線上推理服務和AI-Web應用。EAS提供了彈性擴縮容和藍綠部署等功能,可以支撐您以較低的資源成本擷取高並發且穩定的線上演算法模型服務。此外,EAS具備資源群組管理和版本控制等功能,並且有完整營運監控體系等能力。更詳細的內容介紹,請參見EAS概述。
RAG簡介
隨著AI技術的飛速發展,產生式人工智慧在文本產生、映像產生等領域展現出了令人矚目的成就。然而,在廣泛應用大語言模型(LLM)的過程中,一些固有局限性逐漸顯現:
領域知識局限:大語言模型通常基於大規模通用資料集訓練而成,難以針對專業垂直領域提供深入和針對性處理。
資訊更新滯後:由於模型訓練所依賴的資料集具有靜態特性,大模型無法即時擷取和學習最新的資訊與知識進展。
模型誤導性輸出:受制於資料偏差、模型內在缺陷等因素,大語言模型可能會出現看似合理實則錯誤的輸出,即所謂的“大模型幻覺”。
為克服這些挑戰,並進一步強化大模型的功能性和準確性,檢索增強產生技術RAG(Retrieval-Augmented Generation)應運而生。這一技術通過整合外部知識庫,能夠顯著減少大模型虛構的問題,並提升其擷取及應用最新知識的能力,從而實現更個人化和精準化的LLM定製。
OpenSearch簡介
阿里雲OpenSearch向量檢索版,是一款全託管的大規模分布式向量檢索產品,支援多種向量檢索演算法,高精度下效能表現優異,能完成海量資料下的高性價比向量索引構建和相似性檢索服務,支援索引水平拓展與合并、索引流式構建,資料能夠做到即時動態更新,即增即查。
阿里雲OpenSearch向量檢索版可以高效能支援多種向量檢索典型情境,如:RAG檢索增強產生、多模態檢索、個人化搜推等。更詳細的內容介紹,請參見OpenSearch向量檢索版介紹。
使用流程
EAS自建了RAG系統化解決方案,提供了靈活可調的參數配置,您可以通過WebUI或者API調用RAG服務,定製自己專屬的對話系統。RAG技術架構的核心為檢索和產生:
在檢索方面,EAS支援多種向量檢索庫,包括開源的Faiss、Elasticsearch、Hologres、OpenSearch以及RDS PostgreSQL。
在產生方面,EAS支援豐富的開源模型,例如通義千問、Llama、Mistral、百川等,同時支援ChatGPT調用。
本方案以OpenSearch為例,為您介紹如何使用EAS與阿里雲OpenSearch向量檢索版構建一個大模型RAG對話系統。整體流程大約花費20分鐘,具體流程如下:
首先建立OpenSearch向量檢索版執行個體,並準備部署RAG服務關聯該執行個體時依賴的配置項。
在EAS模型線上服務平台部署RAG服務,並關聯OpenSearch向量檢索版執行個體。
您可以在RAG對話系統中串連OpenSearch,上傳業務資料檔案,並進行知識問答。
前提條件
已建立Virtual Private Cloud、交換器和安全性群組。具體操作,請參見搭建IPv4專用網路和建立安全性群組。
注意事項
本實踐受制於LLM服務的伺服器資源大小以及預設Token數量限制,能支援的對話長度有限,旨在協助您體驗RAG對話系統的基本檢索功能。
準備向量檢索庫OpenSearch
步驟一:建立OpenSearch向量檢索版執行個體
進入OpenSearch控制台,在左上方切換到OpenSearch-向量檢索版:
在執行個體列表頁面,建立OpenSearch向量檢索版執行個體。其中關鍵參數配置如下,更多配置說明,請參見購買OpenSearch向量檢索版執行個體。
參數
描述
商品版本
選擇向量檢索版。
專用網路
選擇已建立的專用網路和交換器。
虛擬交換器
使用者名稱
OpenSearch向量檢索執行個體的使用者名稱。
使用者密碼
OpenSearch向量檢索執行個體的密碼。
步驟二:準備配置項
1.準備執行個體ID
在執行個體列表頁面,查看OpenSearch向量檢索版的執行個體ID,並儲存到本地。

2.準備索引表
執行個體建立成功後,會進入待配置狀態。您需要為該執行個體配置表基礎資訊>資料同步>欄位配置>索引結構,之後等待索引重建完成即可正常搜尋。具體操作步驟如下:
單擊待配置執行個體操作列下的配置。
進行表基礎資訊配置,參數配置完成後,單擊下一步。
其中關鍵參數說明如下,其他參數配置說明,請參見通用版快速入門。
表名稱:自訂索引表名稱。
資料分區數:如果您購買了查詢節點,則在分區數設定時,可配置為不超過256的正整數, 用於提升全量構建速度、單次查詢效能。如果未購買查詢節點,則資料分區數只能配置為1。
資料更新資源數:資料更新所用資源數,每個索引預設免費提供2個4核8G的更新資源,超出免費額度的資源將產生費用,詳情可參考向量檢索版國際站計費文檔
情境模板:選擇通用模板。
進行資料同步配置,參數配置完成後,單擊下一步。
其中全量資料來源支援三種資料來源方式,您可以根據具體業務情況進行選擇:
MaxCompute+API:使用MaxCompute進行資料全量寫入,即時資料通過API寫入。使用該方式時,具體參數配置說明,請參見MaxCompute + API 資料來源。
Object Storage Service+API:使用OSS進行資料全量寫入,即時資料通過API寫入。使用該方式時,具體參數配置說明,請參見OSS + API 資料來源。
API:全量與即時資料均通過API寫入。
進行欄位配置,參數配置完成後,單擊下一步。
將以下欄位設定檔樣本內容儲存為JSON檔案,然後單擊右上方的匯入欄位索引結構,並按控制台操作指引匯入索引檔案。匯入後,將基於檔案內容填寫欄位配置和索引結構。
進行索引結構配置,參數配置完成後,單擊下一步。
其中關鍵配置說明如下,其他參數配置說明,請參見向量索引通用配置。
向量維度:設定為1024。
距離類型:建議選擇InnerProduct。
在確認建立設定精靈頁面,單擊確認建立。
系統將自動跳轉至表管理頁面,當狀態為使用中時,表明索引表建立成功。
3.為OpenSearch向量檢索版執行個體開通公網訪問功能
目前,EAS只能通過公網訪問OpenSearch,需要具備訪問公網的能力。因此,您需要為EAS添加VPC,並為該VPC綁定NAT Gateway和Elastic IP Address(EIP)。同時,為確保OpenSearch執行個體能夠接收來自EAS執行個體的公網請求,您需要為OpenSearch開通公網訪問,並將上述EIP地址加入白名單。以下內容為您介紹如何為EAS的VPC配置公網訪問OpenSearch功能,EAS可以使用與OpenSearch相同的VPC,也可以使用其他VPC。
為後續部署RAG服務時綁定的Virtual Private Cloud配置公網訪問功能。具體操作,請參見使用公網NAT GatewaySNAT功能訪問互連網。
查看已綁定的Elastic IP Address地址。
登入專用網路管理主控台。單擊專用網路執行個體ID,並切換到資源管理頁簽。
單擊已綁定的公網NAT Gateway,進入公網NAT Gateway頁面。
單擊公網NAT Gateway執行個體ID,進入基本資料頁面。
單擊綁定的Elastic IP Address,查看已綁定的Elastic IP Address地址,並儲存到本地。

在OpenSearch向量檢索版執行個體列表頁面,單擊目標執行個體名稱,進入執行個體詳情頁面。
在網路資訊地區,開啟公網訪問開關,並在修改公網訪問白名單配置面板中,按照控制台操作指引,將上述步驟已查詢的Elastic IP Address配置為公網訪問白名單。
在網路資訊地區,將公網網域名稱後的訪問地址儲存到本地。
4.查看執行個體使用者名稱和密碼
即在建立OpenSearch向量檢索版執行個體時,輸入的使用者名稱和密碼。您可以在執行個體詳情頁面的API入口地區查看。
部署RAG服務並關聯OpenSearch
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
在推理服務頁簽,單擊部署服務,然後在情境化模型部署地區,單擊大模型RAG對話系統部署。
在部署大模型RAG對話系統頁面,配置以下關鍵參數,其他參數配置說明,請參見步驟一:部署RAG服務。
參數
描述
基本資料
版本選擇
選擇LLM一體化部署。
RAG版本
選擇pai-rag:0.3.4。
模型類別
選擇qwen1.5-1.8b。
資源資訊
部署資源
系統會根據已選擇的模型類別,自動推薦適合的資源規格。更換至其他資源規格,可能會導致模型服務啟動失敗。
向量檢索庫設定
版本類型
選擇OpenSearch。
訪問地址
配置為步驟二中已擷取的公網網域名稱,不帶http://或https://,例如ha-cn-****.public.ha.aliyuncs.com。
執行個體id
配置為步驟二中已擷取的OpenSearch向量檢索版執行個體的ID。
使用者名稱
配置為建立OpenSearch向量檢索版執行個體時設定的使用者名稱。
密碼
配置為建立OpenSearch向量檢索版執行個體時設定的密碼。
表名稱
配置為步驟二中已建立的索引表名稱。
OSS地址
請選擇當前地區下已建立的OSS儲存目錄。通過掛載OSS路徑實現知識庫管理員。
專用網路
Virtual Private Cloud
您可以選擇與OpenSearch一致的專用網路和交換器。
您也可以使用其他專用網路,但需要確保該專用網路具有公網訪問能力,並將綁定的Elastic IP Address添加為OpenSearch執行個體的公網訪問白名單。具體操作,請參見使用公網NAT GatewaySNAT功能訪問互連網和公網白名單配置。
交換器
安全性群組名稱
選擇安全性群組。
參數配置完成後,單擊部署。
使用RAG對話系統
RAG對話系統的基本使用方法如下,更多詳細介紹,請參見大模型RAG對話系統(v0.3.x)。
1、檢查向量檢索庫配置
單擊目標RAG服務名稱,然後在頁面右上方單擊查看Web應用。
檢查向量檢索庫OpenSearch配置是否正確。
系統已自動設定知識庫default,並自動識別應用了部署RAG服務時配置的向量檢索庫設定。在向量資料庫配置地區,檢查OpenSearch配置是否正確,可修改對應配置項為正確配置,然後單擊更新知識庫。
2、上傳企業知識庫檔案
在知識庫頁簽的檔案管理Tab頁上傳知識庫檔案。
知識庫上傳完成後,系統會自動按照PAI-RAG格式將檔案儲存體到向量檢索庫。對於同名知識庫檔案,除了FAISS外,其他向量檢索庫將會覆蓋原有檔案。支援的檔案類型為.html、.htm、.txt、.pdf、.pptx、.md、Excel(.xlsx或.xls)、.jsonl、.jpeg、.jpg、.png、.csv或Word(.docx),例如rag_chatbot_test_doc.txt。
3、進行知識問答
在對話頁簽,選擇知識庫名稱、使用意圖(使用更多工具選擇查詢知識庫)進行知識問答。
OpenSearch特色功能支援
阿里雲OpenSearch向量檢索版為客戶提供了便捷的圖形化介面,可以高效管理索引表(Table)以及索引(Index),以下內容將為您介紹,如何使用OpenSearch向量檢索版控制台,查看索引資訊並實現簡單的資料管理。
索引表管理
進入阿里雲OpenSearch向量檢索版執行個體詳情頁面。
單擊已建立的執行個體ID,進入執行個體詳情頁面。
進入表管理頁面,對索引表進行管理操作。
在左側導覽列,單擊表管理。
頁面中展示當前執行個體下建立的所有表。
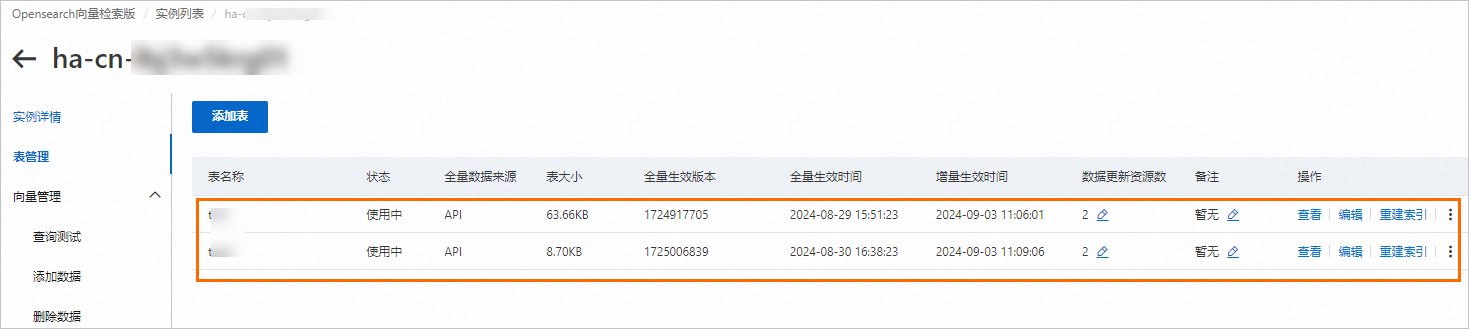
在表管理頁面,對索引表進行管理操作,包括查看欄位及索引結構、編輯索引、索引重建以及刪除索引等。具體操作細節,請參見表管理。
資料管理
進入阿里雲OpenSearch向量檢索版執行個體詳情頁面。
單擊已建立的執行個體ID,進入執行個體詳情頁面。
添加資料。
在左側導覽列,單擊 。
在頁面右側下拉式清單中,選擇表單模式或開發人員模式。
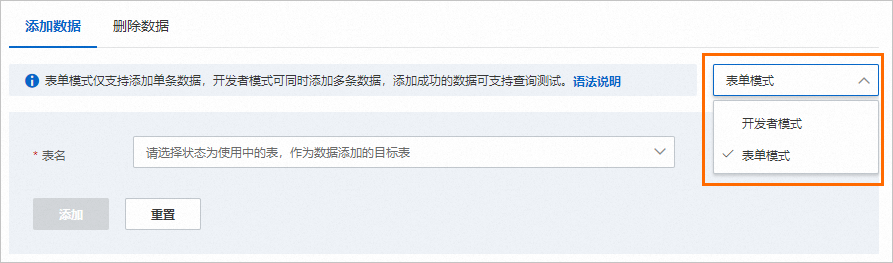
選擇要添加資料的目標索引表(Table)名稱。
按欄位輸入資料內容或填寫資料寫入語句,然後單擊添加。具體操作請參見:添加資料。
當執行結果出現
"message": "success"時,表示資料上傳成功,即可完成單條資料或多條資料的添加。
查看錶指標資料。
在左側導覽列,單擊 。
選擇要查看資料的目標索引表(Table)名稱,即可查看索引內文檔個數、每秒請求成功次數等指標。詳情請參見表指標。
刪除資料。
在左側導覽列,選擇。
在頁面右側下拉式清單中,選擇表單模式或開發人員模式。
選擇表名並輸入主鍵,然後單擊刪除。具體操作請參見:刪除資料。
當執行結果出現
"message": "success"時,表示資料刪除成功。
相關文檔
針對AIGC和LLM的典型前沿情境,EAS提供了簡化的部署方式。您可以很方便地一鍵拉起服務,包括ComfyUI部署、Stable Diffusion WebUI部署、ModelScope模型部署、HuggingFace模型部署、Triton部署以及TFserving部署等。詳情請參見EAS情境化部署說明。
RAG服務WebUI介面提供了豐富的推理參數配置選項,以滿足多樣化需求。此外,RAG服務也支援通過API介面進行調用。具體實現細節以及參數配置說明,請參見大模型RAG對話系統(v0.3.x)。
大模型RAG對話系統還支援與其他向量檢索庫進行關聯,例如Elasticsearch或RDS PostgreSQL等。詳情請參見基於EAS&Elasticsearch搭建RAG檢索增強對話系統或基於EAS&RDS PostgreSQL搭建RAG檢索增強對話系統。