本文將介紹在建立表時選擇Object Storage Service+API為資料來源的操作步驟。
添加步驟可分為以下兩步:
開通OSS服務
OSS+API資料來源的添加
步驟一:開通OSS服務
1. 開通服務
開通OSS服務,需要和已購買的OpenSearch服務是同一帳號、相同地區。
OSS服務需要和已購買的OpenSearch服務是同一帳號、相同地區,否則會出現鑒權失敗的情況。
2. 建立Bucket
在上傳檔案到OSS之前,您需要建立一個用於隱藏檔的儲存空間Bucket,可以參考建立儲存空間瞭解。
路徑:Object Storage Service 管理主控台 → Bucket列表 → 建立 Bucket
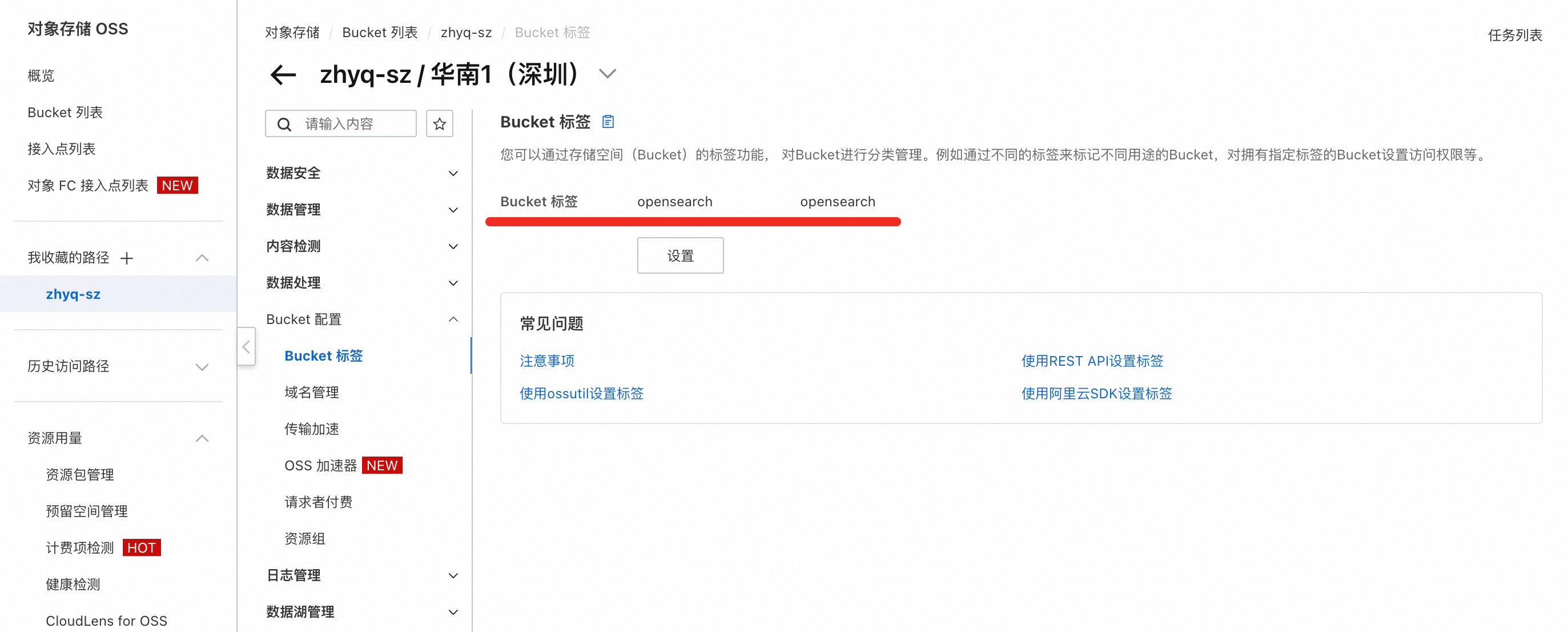
進入已建立的Bucket內,添加OpenSearch標籤。
路徑:Bucket配置 → Bucket 標籤 → 建立標籤
3. OSS檔案格式設定
a. OSS檔案格式
為了使傳輸的檔案能夠被用於索引構建的資料來源,請確保:
檔案採用UTF-8編碼。
檔案資料格式轉化為HA3格式或JSON格式。
ⅰ. JSON格式設定
檔案裡面每行一個JSON資料。
'\n'表示分行符號,單條記錄、一個JSON內部不能有分行符號。
配置的目錄下面不能放其他檔案。
JSON欄位的類型都是String,引擎建索引的時候,會根據schema轉換為欄位指定的類型。
多條記錄樣本,參考以下樣本:
{"field_double": ["100.0", "221.123", "500.3333333"], "field_int32": ["100", "200", "300"], "title": "華為 Mate 9 麒麟960晶片 徠卡雙鏡頭", "color": "紅", "empty_int32": "", "price": "3599", "CMD": "add", "nid": "1", "gather_cn_str": "", "desc": ["str1", "str2", "str3"], "brand": "Huawei", "size": "5.9","__subdocs__":[{"sub_pk":"100","sub_field1":"200","sub_field2":["100","200","300"]},{"sub_pk":"200","sub_field1":"200","sub_field2":["100","200","300"]}]}
{"field_double": ["100.0", "221.123", "500.3333333", "100.0", "221.123", "500.3333333"], "field_int32": ["100", "200", "300", "100", "200", "300"], "title": "Huawei/華為 P10 Plus全網通手機", "color": "藍", "empty_int32": "", "price": "4388", "CMD": "add", "nid": "2", "gather_cn_str": "color藍", "desc": ["str1", "str2", "str3", "str1", "str2", "str3"], "brand": "Huawei", "size": "5.5","__subdocs__":[{"sub_pk":"100","sub_field1":"200","sub_field2":["100","200","300"]},{"sub_pk":"200","sub_field1":"200","sub_field2":["100","200","300"]}]}ⅱ. HA3格式設定
首先看一個完整的資料檔案standard_sample.data的內容。
CMD=add^_
PK=12345321^_
url=http://www.aliyun.com/index.html^_
title=阿里雲計算有限公司^_
body=xxxxxx xxx^_
time=3123423421^_
multi_value_field=1234^]324^]342^_
bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_
^^
CMD=delete^_
PK=12345321^_CMD=add^_
PK=12345321^_
url=http://www.aliyun.com/index.html^_
title=阿里雲計算有限公司^_
body=xxxxxx xxx^_
time=3123423421^_
multi_value_field=1234^]324^]342^_
bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_
^^
CMD=delete^_
PK=12345321^_檔案分隔字元定義:可以看到上面的資料檔案中總共有兩個命令,分別是add、delete。每個命令由多行組成,每行都是一個key-value對。 命令與命令之間用'^^\n'分隔,每一對key-value之間以'^_\n'分隔,多值之間以'^]'分隔,以下是檔案分隔字元介紹。
C++編碼 | ASCII 16進位 | 描述 | (emacs/vi)中的顯示形態 | emacs中輸入方法 | vi中輸入方法 |
"\x1F\n" | 1F0A | key value分隔字元 | ^_(接換行) | C-q C-7 | C-v C-7 |
"\x1E\n" | 1E0A | 命令分隔字元 | ^^(接換行) | C-q C-6 | C-v C-6 |
"\x1D" | 1D | multi value 分隔字元 | ^] | C-q C-5 | C-v C-5 |
"\x1C" | 1C | section weight標誌符 | ^\ | C-q C-4 | C-v C-4 |
"\x1D" | 1D | section 分隔字元 | ^] | C-q C-5 | C-v C-5 |
"\x03" | 03 | sub doc 欄位分隔符號 | ^C | C-q C-c | C-v C-c |
命令格式定義
Add命令格式:add命令表示往索引中增加新的內容,add命令第一行必須為CMD=add,後面是該文檔的field,field順序可以與schema中fields順序一致,所有出現的field必須是fields中指定的。
CMD=add^_ PK=12345321^_ url=http://www.aliyun.com/index.html^_ title=阿里雲計算有限公司^_ body=xxxxxx xxx^_ time=3123423421^_ multi_value_field=1234^]324^]342^_ bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_ ^^CMD=add^_ PK=12345321^_ url=http://www.aliyun.com/index.html^_ title=阿里雲計算有限公司^_ body=xxxxxx xxx^_ time=3123423421^_ multi_value_field=1234^]324^]342^_ bidwords=mp3^\price=35.8^Ptime=13867236221^]mp4^\price=32.8^Ptime=13867236221^_ ^^Delete命令格式:delete命令表示從索引中刪除指定的內容。delete命令第一行必須為CMD=delete,接下來為index schema中定義屬性為primary key 的field,以及用於partition hash的field,如果兩個field相同,則只需要出現一個field。
CMD=delete^_ PK=12345321^_ ^^CMD=delete^_ PK=12345321^_ ^^
b. 上傳檔案到Bucket
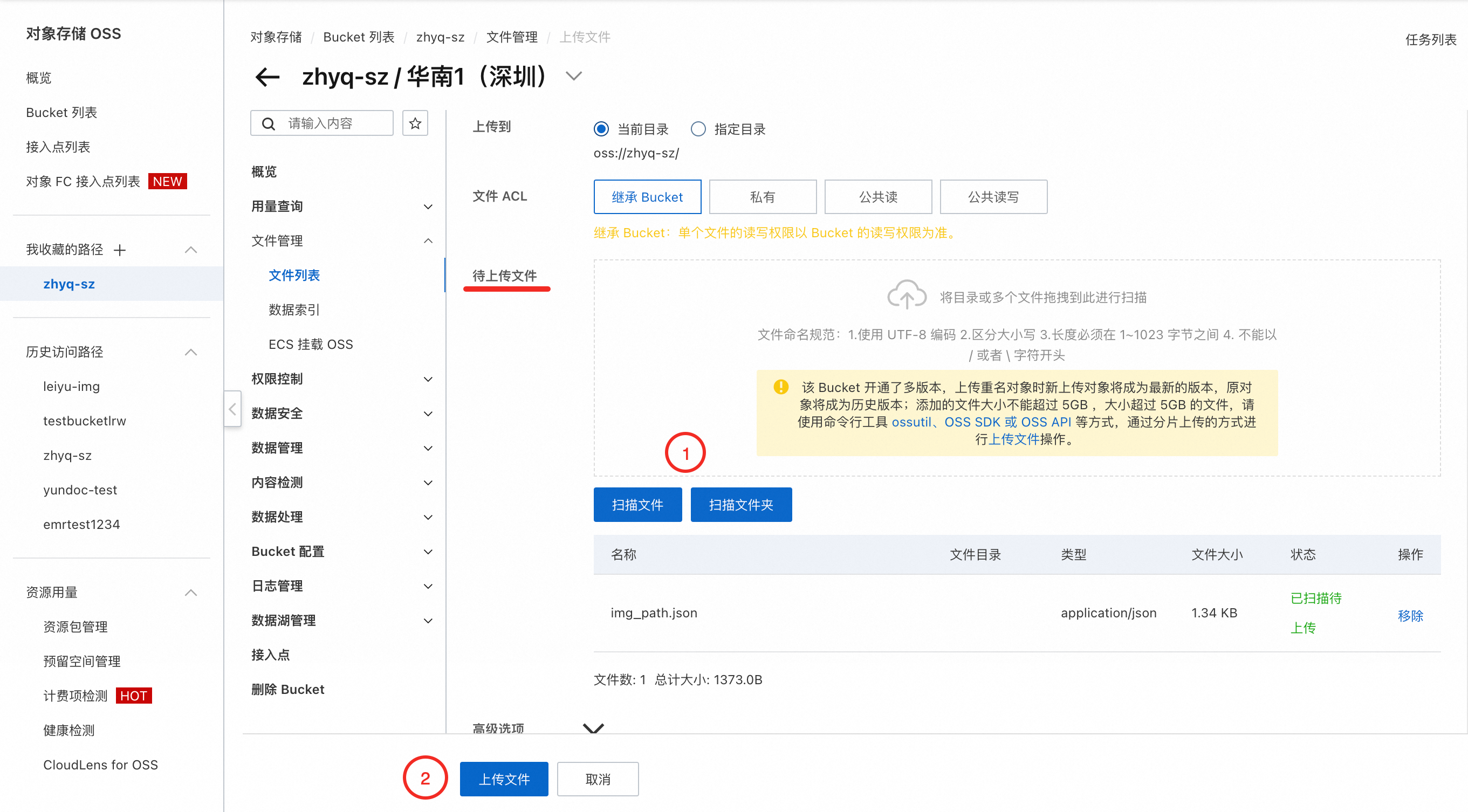
返回到新建立的Bucket控制頁,在左側導覽列找到檔案管理 → 檔案清單 → 上傳檔案 。
在 待上傳檔案 項中選擇掃描檔案的方式,勾選好上傳的內容,再點擊 上傳檔案 ,完成檔案的上傳。
步驟二:OSS+API資料來源添加
購買執行個體:可參考購買OpenSearch向量檢索版執行個體。
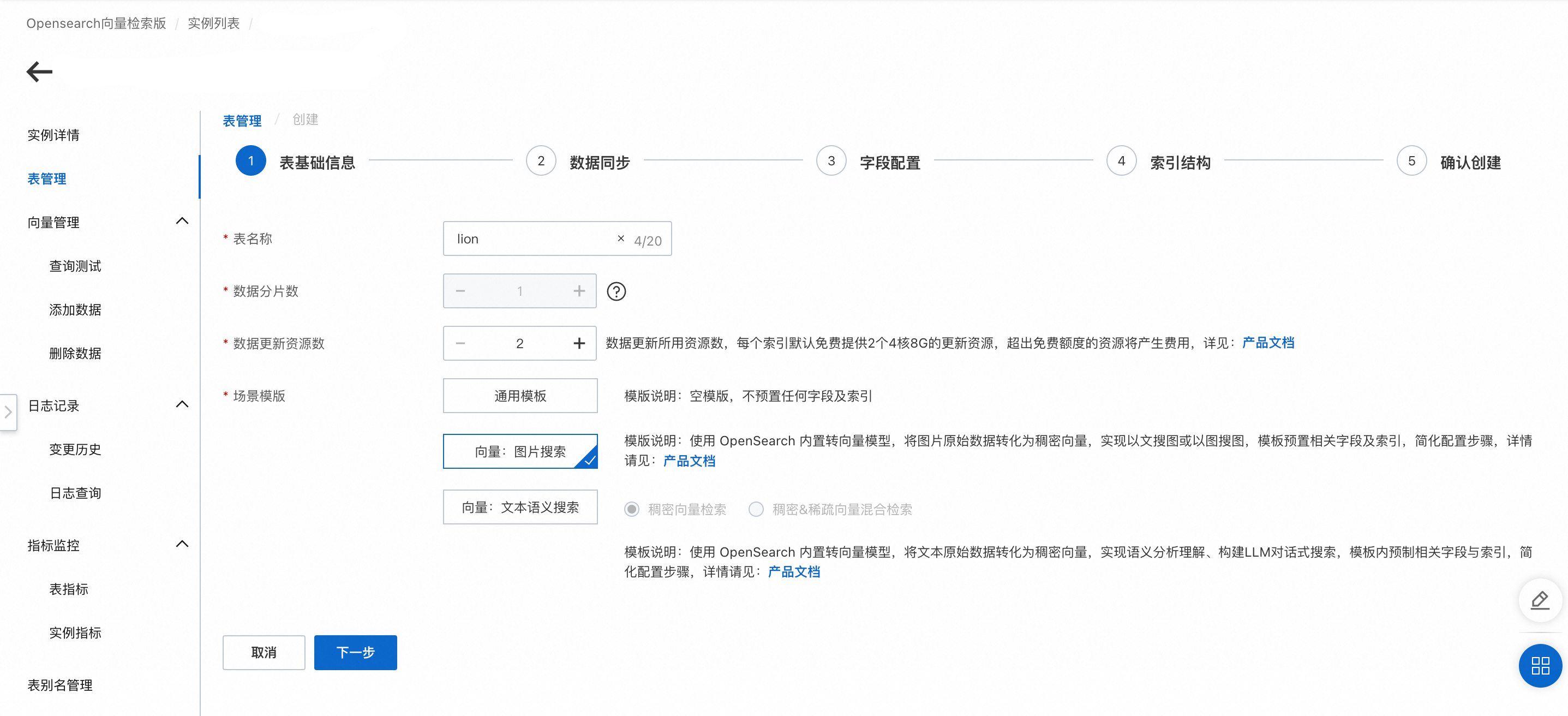
1. 表基礎資訊
從 執行個體列表 中找到已購買的向量檢索版執行個體,在操作欄中點擊管理 ,左側導覽列找到表管理 → 添加表 。
完成表的基礎資訊填寫後,點擊 下一步 。
配置說明:
表名稱:可以自訂。
資料分區數:請填寫不超過256的正整數, 用於提升全量構建速度、單次查詢效能。
資料更新資源數:資料更新所用資源數,每個索引預設免費提供2個4核8G的更新資源,超出免費額度的資源將產生費用,詳情可參考向量檢索版國際站計費文檔。
情境模板:共3個模板可供選擇,包含1.通用模板、2.向量:圖片搜尋模板、3.向量:文本語義搜尋模板
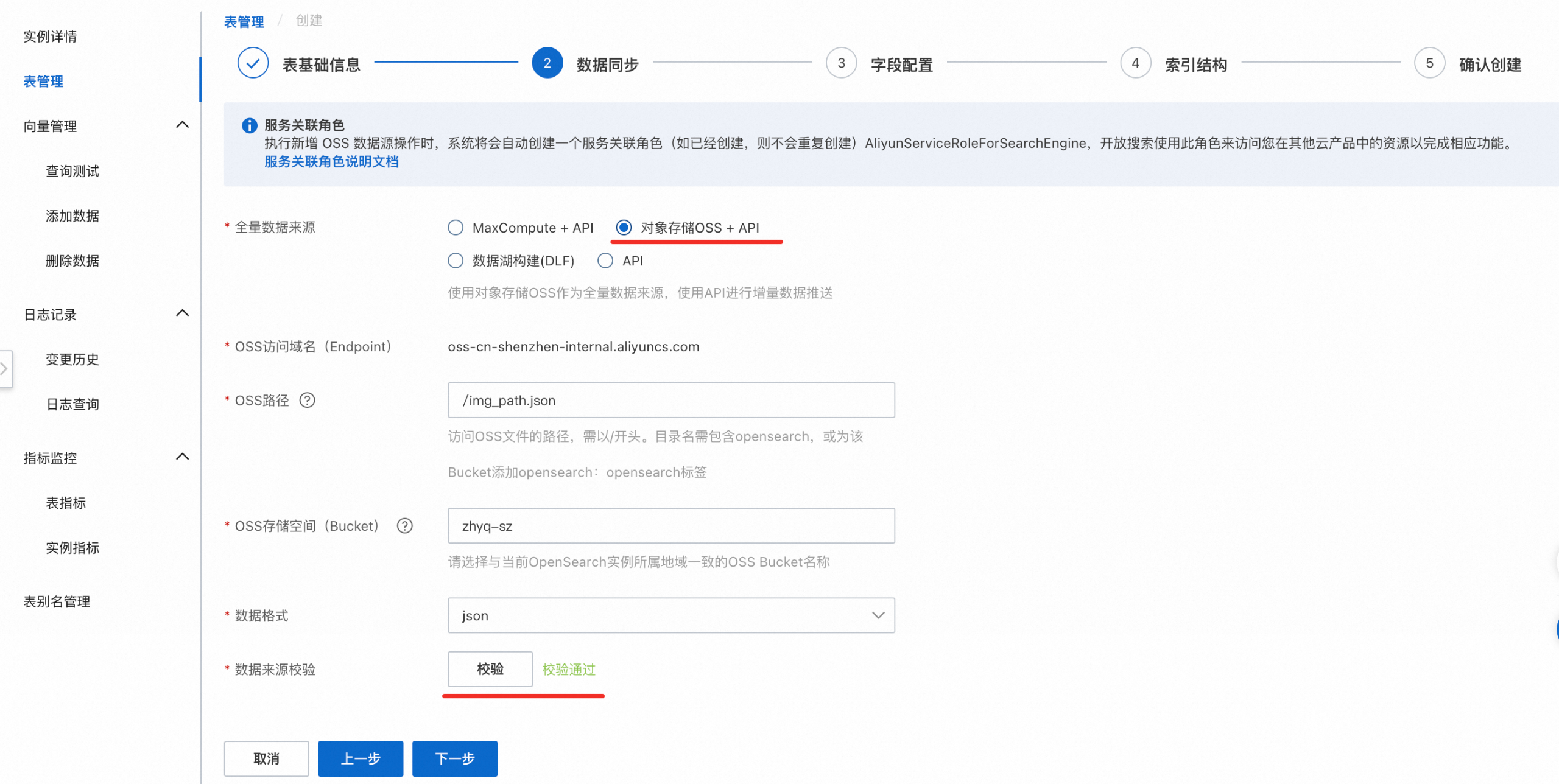
2. 資料同步
全量資料來源 選擇「Object Storage Service+API」,並完成其他項的配置,資料來源校正通過後,點擊 下一步 。
配置說明:
OSS路徑:訪問OSS檔案的路徑,需以/開頭,路徑中不允許包含?、=、&符號,檔案不能放在根目錄,需放在某個檔案夾下然後填寫路徑。
OSS儲存空間(Bucket):OSS的Bucket名稱。
資料格式:傳輸檔案需要是HA3或JSON,否則檔案資料無法傳輸成功。
資料來源校正:校正通過後可進行下一步。
3. 欄位配置
向量檢索版會根據您選擇的情境模板,預置相關欄位,並會將全量資料來源中的欄位,自動匯入下方列表,欄位配置、需資料預先處理-去配置 都設定完成後,點擊 下一步 。
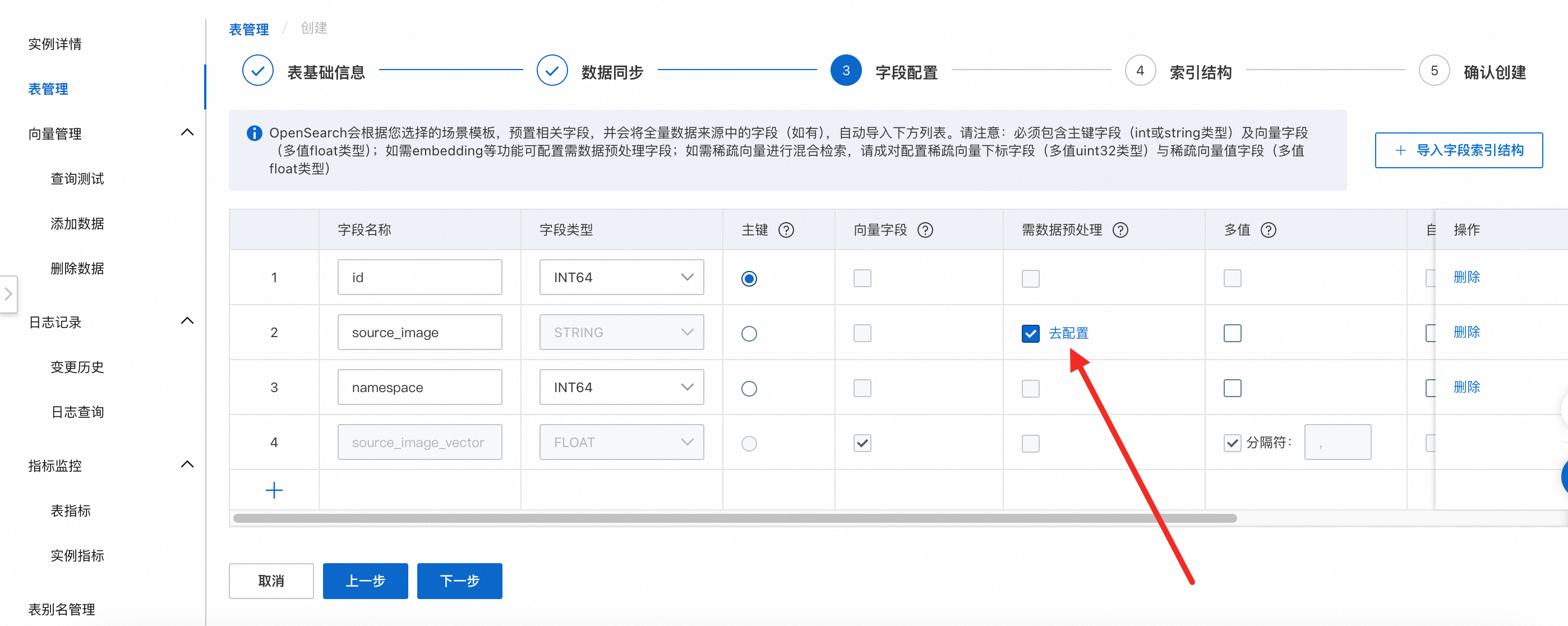
欄位含義:
id(主鍵)
source_image(源圖片)
namespace(命名空間)
source_image_vector(源圖片向量)
配置說明:
必選欄位有:主鍵欄位和向量欄位,主鍵欄位為int或string類型並且需要勾選主鍵按鈕,向量欄位為float類型並且需要勾選向量欄位按鈕。
向量欄位預設為多值的float類型,多值分隔字元預設使用分割符英文逗號進行切分,也可以輸入自訂多值分隔字元。
當資料中缺少欄位或欄位為空白時,系統將自動補充預設值,數字類型預設補0,STRING類型預設補Null 字元串,支援自訂預設值。
需資料預先處理 - 去配置:點擊去配置,進入欄位 source_image 資料預先處理配置介面。
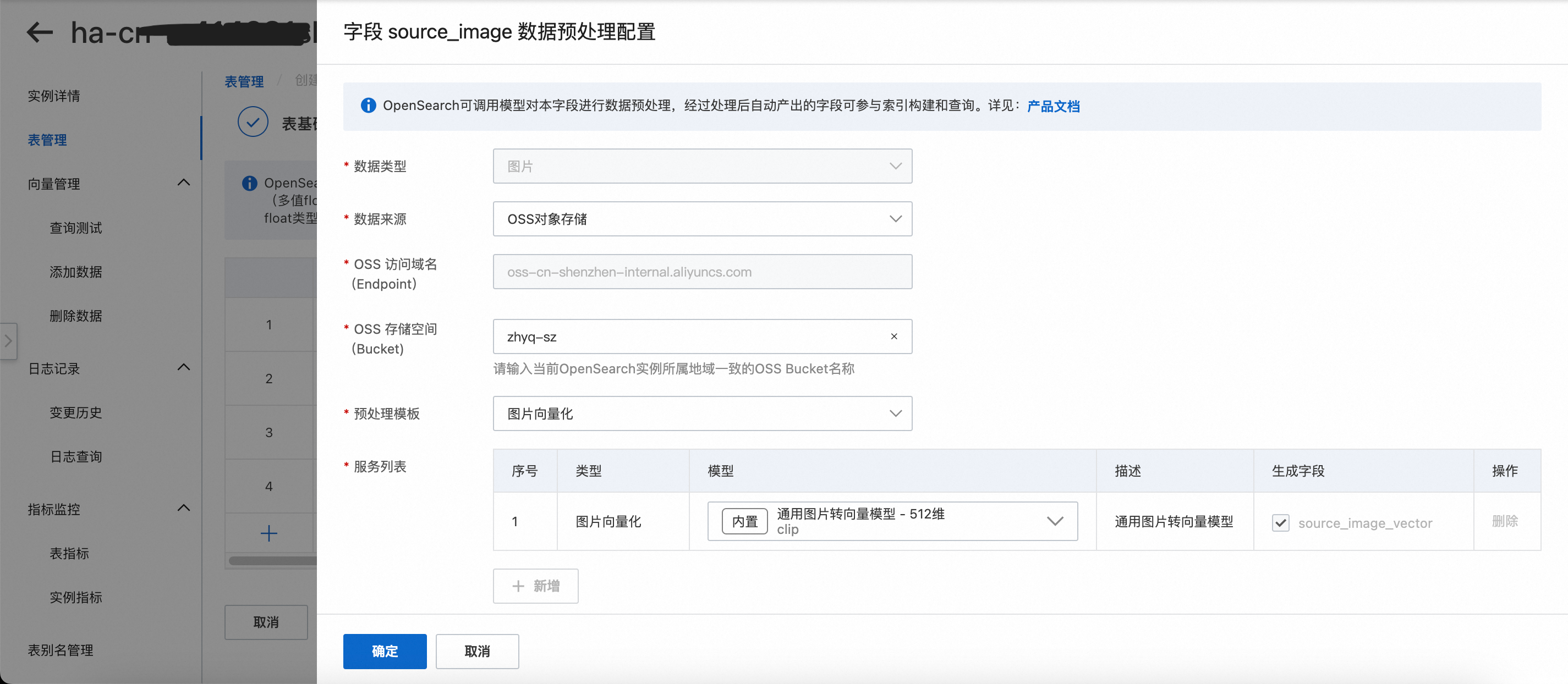
資料來源:有OSSObject Storage Service和Base64編碼的兩種資料類型選項,本次選擇OSSObject Storage Service方式。
OSSObject Storage Service:需要填寫OSS路徑,其實就是將圖片存放在OSS的檔案夾裡面,從OSS直接匯入。
Base64編碼:相當於需要先將圖片進行一次編碼,然後儲存在資料庫中,或者直接用API方式進行傳輸。
預先處理模板:會根據要進行前置處理過的資料類型(文本或圖片)而展示不同模板,由於本次預先處理的是圖片類型的資料,所以此時預先處理模板展示的分別是(1.圖片向量化、2.OCR圖片文字識別、3.OCR圖片文字識別+圖片向量化)3種模板,本次示範選擇圖片向量化預先處理模板。
服務列表:
選定預先處理模板後,自動出現模板下的服務列表,展示該模板下所用到的模型種類。
可選的模型來源:
內建模型:模型種類與數量較少,可免費調用。
自訂模型:使用者可根據自身需求自訂模型,在向量檢索版頁面模型列表>自訂模型中進行新增模型操作,詳情請參見自訂模型。
4. 索引結構
索引結構配置,配置完成後,點擊下一步。
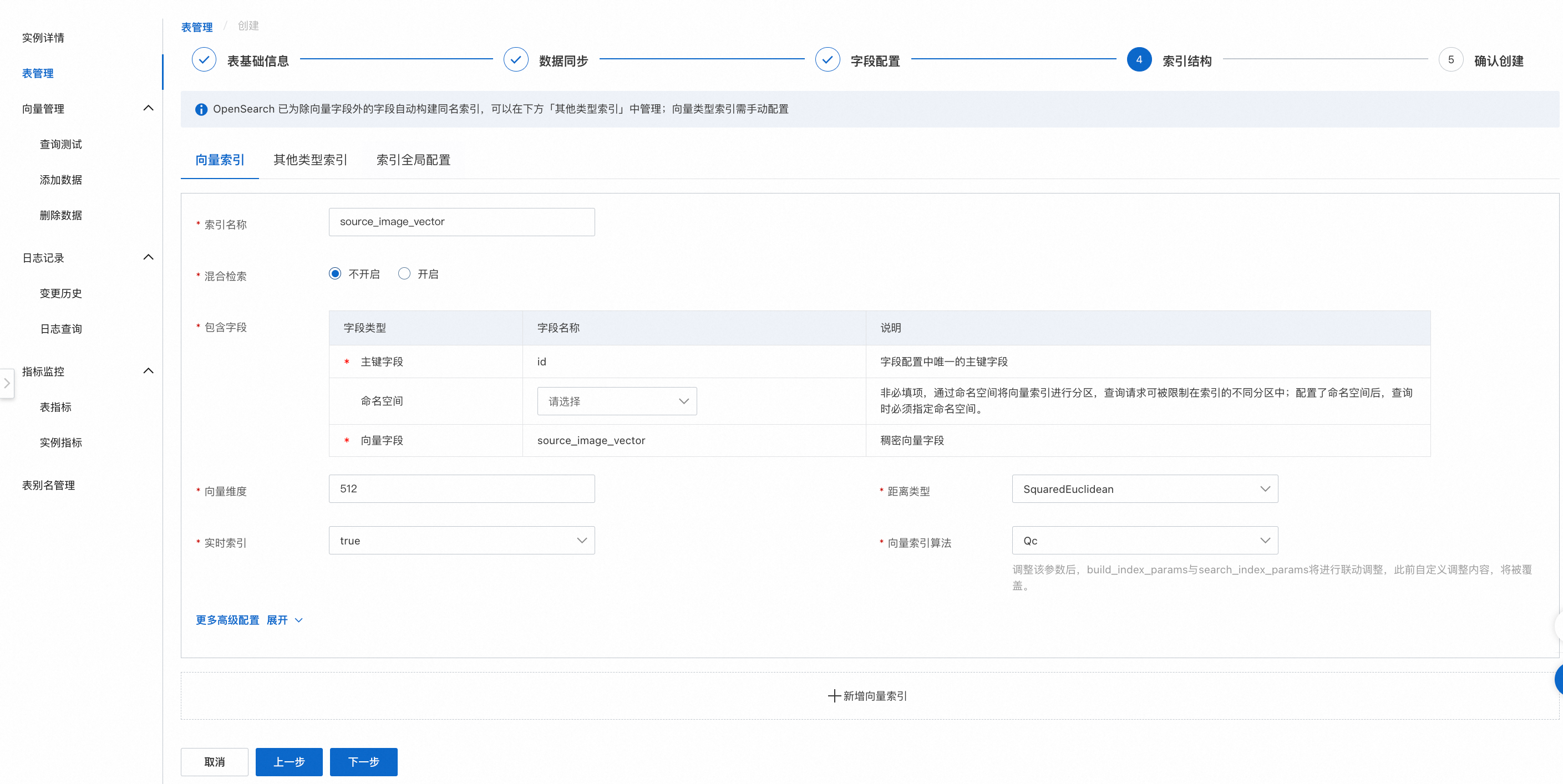
配置說明:
包含欄位:主鍵欄位、向量欄位必須填寫,命名空間欄位非必填,可以為空白。
向量維度、即時索引、距離類型、向量索引演算法可以根據業務情況填寫。
更多進階配置:可直接使用預設參數或根據業務情況調整,詳情可參考向量索引通用配置,索引結構頁設定完畢後,點擊下一步,進入確認建立頁。
5. 確認建立
點擊 確認建立 ,完成後還需等待2分鐘,返回到 執行個體列表 頁,待執行個體狀態為“ 正常 ”後,就可以從 操作欄 - 查詢測試 進行後續的搜尋和測試。