本文為您介紹如何通過提交一個使用MaxCompute計算資源的超參數調優實驗,來運行K均值聚類和聚類模型評估組件,以擷取K均值聚類組件演算法的較優超參數組合。
步驟一:準備資料
您可以參考聚類模型評估中的樣本來準備測試資料和評估資料。
本方案使用公開資料來源pai_online_project.pai_kmeans_test_input和pai_online_project.pai_cluster_evaluation_test_input,您可以直接使用。
步驟二:建立實驗
進入建立實驗頁面。具體操作,請參見建立實驗。
在建立實驗頁面,配置以下關鍵參數,其他參數配置詳情,請參見建立實驗。
執行配置:

參數
描述
任務類型
選擇MaxCompute。
命令
配置以下兩個命令,按照順序依次排列,後續會按順序執行命令。
cmd1:使用準備好的測試資料,運行K均值聚類組件,構建聚類模型。各個參數的配置說明,請參見方式二:PAI命令方式。
pai -name kmeans -project algo_public -DinputTableName=pai_online_project.pai_kmeans_test_input -DselectedColNames=f0,f1 -DappendColNames=f0,f1 -DcenterCount=${centerCount} -Dloop=10 -Daccuracy=0.01 -DdistanceType=${distanceType} -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DidxTableName=pai_kmeans_test_output_idx_${exp_id}_${trial_id} -DclusterCountTableName=pai_kmeans_test_output_couter_${exp_id}_${trial_id} -DcenterTableName=pai_kmeans_test_output_center_${exp_id}_${trial_id};其中:${centerCount}和${distanceType}為定義的超參數變數。
cmd2:基於cmd1產生的聚類結果,運行聚類模型評估組件,來評估聚類模型的優劣性。各個參數的配置說明,請參見方式二:PAI命令方式。
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_online_project.pai_cluster_evaluation_test_input -DselectedColNames=f0,f1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DoutputTableName=pai_ft_cluster_evaluation_out_${exp_id}_${trial_id};超參數
每個超參數對應的約束類型和搜尋空間配置如下:
centerCount:
約束類型:choice。
搜尋空間:單擊
 ,增加4個枚舉值,分別為2、3、4和5。
,增加4個枚舉值,分別為2、3、4和5。
distanceType:
約束類型:choice。
搜尋空間:單擊
,增加3個枚舉值,分別為euclidean、cosine和cityblock。
使用上述配置可以產生12種超參數組合,後續實驗會分別為每種超參數組合建立一個Trial,在每個Trial中使用一組超參數組合來運行K均值聚類組件和聚類模型評估組件。
Trial配置:
參數
描述
指標類型
選擇table。
計算方式
選擇best。
指標權重
key:vrc。
Value:1。
指標來源
配置為
select GET_JSON_OBJECT(summary, '$.calinhara') as vrc from pai_ft_cluster_evaluation_out_${exp_id}_${trial_id};。最佳化方向
選擇越大越好。
模型名稱
配置為
pai_kmeans_test_output_model_${exp_id}_${trial_id}。搜尋配置:
參數
描述
搜尋演算法
選擇TPE。
最大搜尋次數
配置為6。
最大並發量
配置為3。
單擊提交。
系統在實驗列表頁面自動建立一個實驗。
步驟三:查看實驗詳情和運行結果
在實驗列表頁面,單擊實驗名稱,進入實驗詳情頁面。
在該頁面,您可以查看Trial的執行進度和狀態統計。
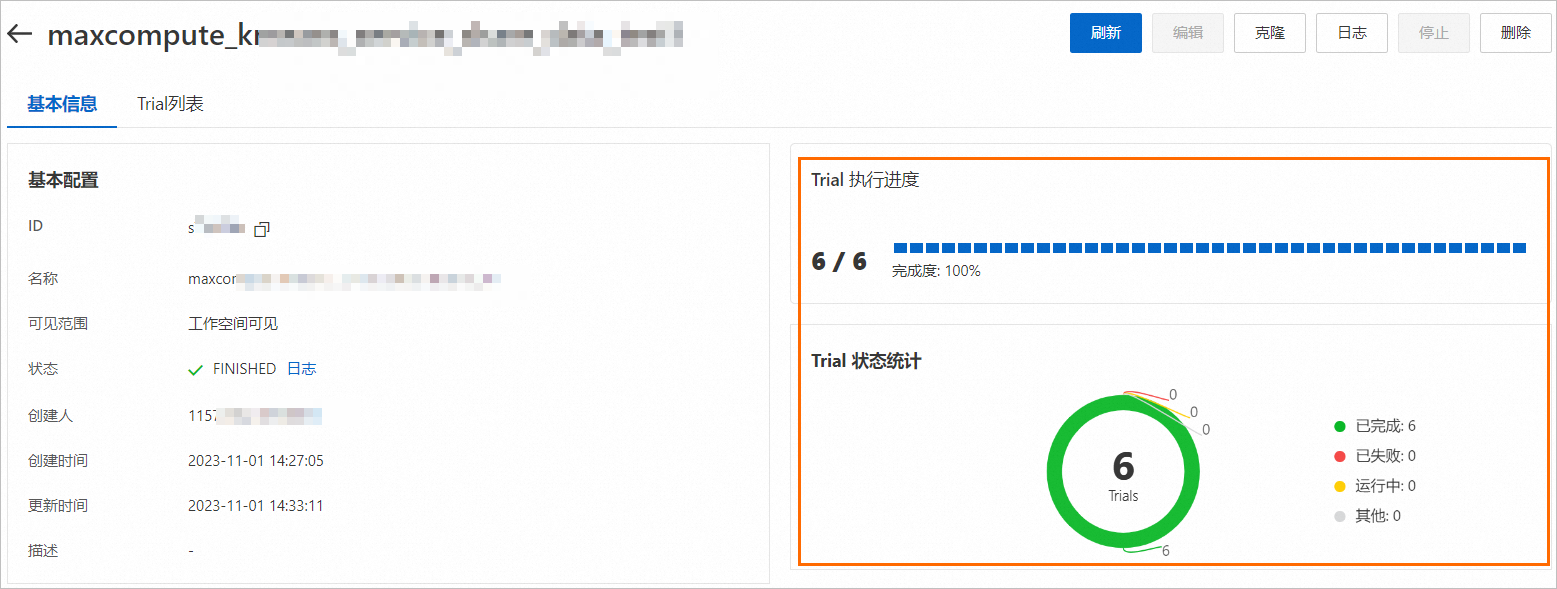
實驗根據配置的搜尋演算法和最大搜尋次數自動建立6個Trial。
單擊Trial列表,您可以在該頁面查看該實驗自動產生的所有Trial列表,以及每個Trial的執行狀態、最終指標和超參數組合。
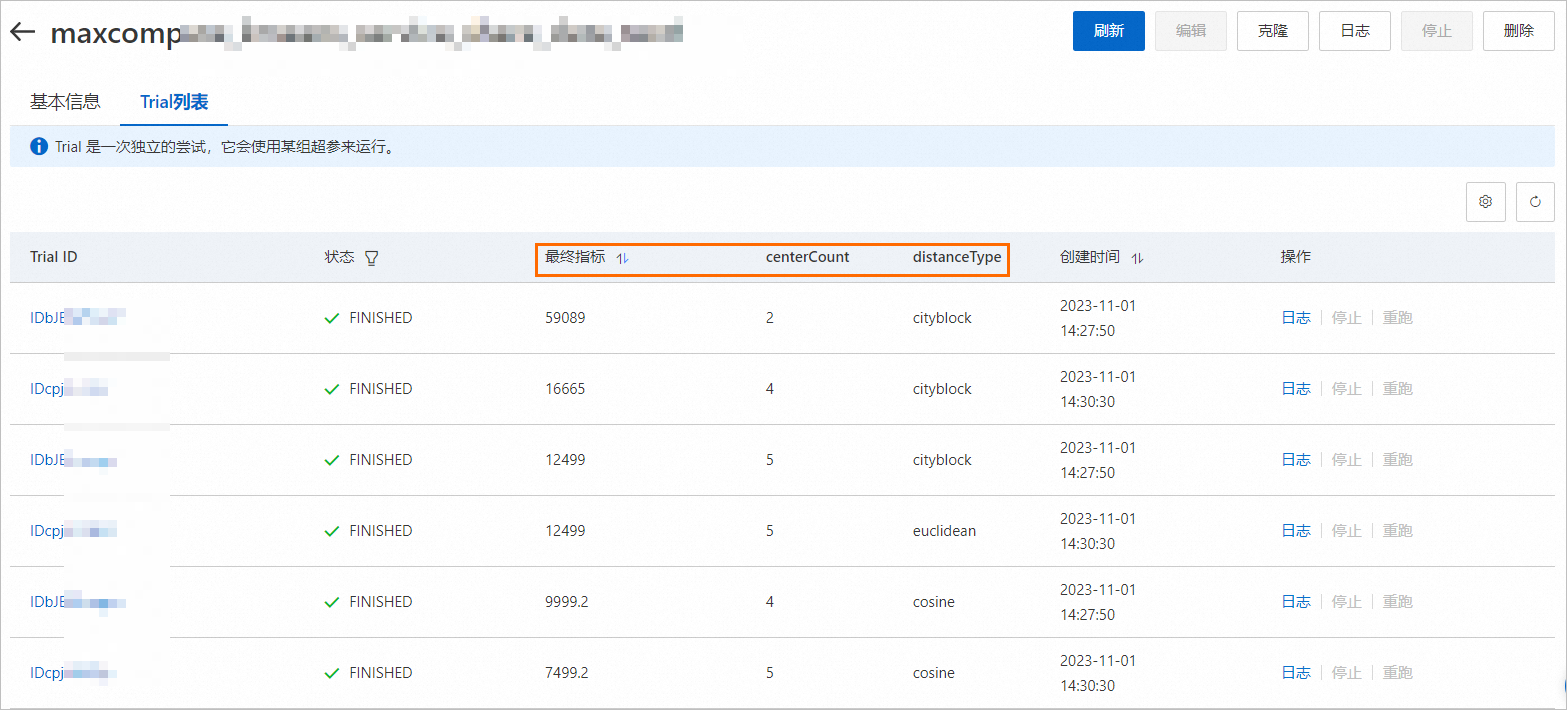
根據配置的最佳化方向(越大越好),從上圖可以看出,最終指標為59089對應的超參組合(centerCount:2;distanceType:cityblock)較優。