基於未經處理資料和聚類結果,評估聚類模型的優劣性,從而輸出評估指標。
使用限制
僅原PAI-Studio平台支援查看該組件的可視化報告。
背景資訊
評估指標Calinski-Harabasz又稱VRC(Variance Ratio Criterion),其計算公式如下。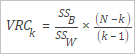
參數 | 描述 |
SSB | 聚類之間的方差,定義如下。
|
SSW | 聚類內的方差,定義如下。
|
N | 記錄的總數量。 |
k | 聚類中心點的數量。 |
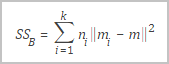 其中:
其中: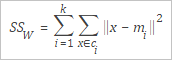 其中:
其中:組件配置
您可以使用以下任意一種方式,配置聚類模型評估組件參數。
方式一:可視化方式
在Designer工作流程頁面配置組件參數。
頁簽 | 參數 | 描述 |
欄位設定 | 參與評估列 | 參與評估的列名,該參數必須與模型儲存的特徵列保持一致。 |
輸入為稀疏格式 | 使用KV格式表示稀疏資料。 | |
kv鍵間分隔字元 | 預設為英文逗號(,)。 | |
kv鍵內分隔字元 | 預設為英文冒號(:)。 | |
執行調優 | 核心數 | 與參數每個核的記憶體大小搭配使用,取值範圍為正整數。 |
每個核的記憶體大小 | 與參數核心數搭配使用,單位為MB。 |
方式二:PAI命令方式
使用PAI命令方式,配置該組件參數。您可以使用SQL指令碼組件進行PAI命令調用,詳情請參見SQL指令碼。
PAI -name cluster_evaluation
-project algo_public
-DinputTableName=pai_cluster_evaluation_test_input
-DselectedColNames=f0,f3
-DmodelName=pai_kmeans_test_model
-DoutputTableName=pai_ft_cluster_evaluation_out;參數 | 是否必選 | 描述 | 預設值 |
inputTableName | 是 | 輸入表的名稱。 | 無 |
selectedColNames | 否 | 輸入表中,參與評估的列名,多個列以英文逗號(,)分隔。該參數必須與模型儲存的特徵列保持一致。 | 所有列 |
inputTablePartitions | 否 | 輸入表中,參與訓練的分區。支援以下格式:
說明 如果指定多個分區,則使用英文逗號(,)分隔。 | 全表 |
enableSparse | 否 | 輸入資料是否為稀疏格式,取值範圍為{true,false}。 | false |
itemDelimiter | 否 | 稀疏格式KV對之間的分隔字元。 | 英文逗號(,) |
kvDelimiter | 否 | 稀疏格式key和value之間的分隔字元。 | 英文冒號(;) |
modelName | 是 | 輸入的聚類模型。 | 無 |
outputTableName | 是 | 輸出表。 | 無 |
lifecycle | 否 | 輸出表的生命週期。 | 無 |
樣本
使用SQL語句,產生測試資料。
create table if not exists pai_cluster_evaluation_test_input as select * from ( select 1 as id, 1 as f0,2 as f3 union all select 2 as id, 1 as f0,3 as f3 union all select 3 as id, 1 as f0,4 as f3 union all select 4 as id, 0 as f0,3 as f3 union all select 5 as id, 0 as f0,4 as f3 )tmp;使用PAI命令,構建聚類模型(以K均值聚類為例)。
PAI -name kmeans -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DcenterCount=3 -Dloop=10 -Daccuracy=0.00001 -DdistanceType=euclidean -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_model -DidxTableName=pai_kmeans_test_idx使用PAI命令,提交聚類模型評估組件的參數。
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DmodelName=pai_kmeans_test_model -DoutputTableName=pai_ft_cluster_evaluation_out;查看評估輸出表pai_ft_cluster_evaluation_out,其可視化報告如下圖所示。
 表中各欄位含義如下。
表中各欄位含義如下。表欄位
描述
count
總記錄數。
centerCount
聚類中心數。
calinhara
Calinski Harabasz指標。