面對當前日益複雜且對資料時效性要求極高的近即時業務情境,MaxCompute基於Delta Table推出了集大規模儲存、高效批量處理和近即時能力於一體的近即時增量一體化架構。本文為您介紹該架構的工作原理及其優勢。
背景和現狀
在當前典型的資料處理業務情境中,對時效性要求較低的大規模資料全量批處理的單一情境,直接採用MaxCompute已經足以滿足業務需求。然而,隨著MaxCompute承載的業務規模和使用情境的不斷豐富,除了處理好大規模離線批處理鏈路之外,對於近即時和增全量處理鏈路也面臨著眾多需求。如下圖所示。
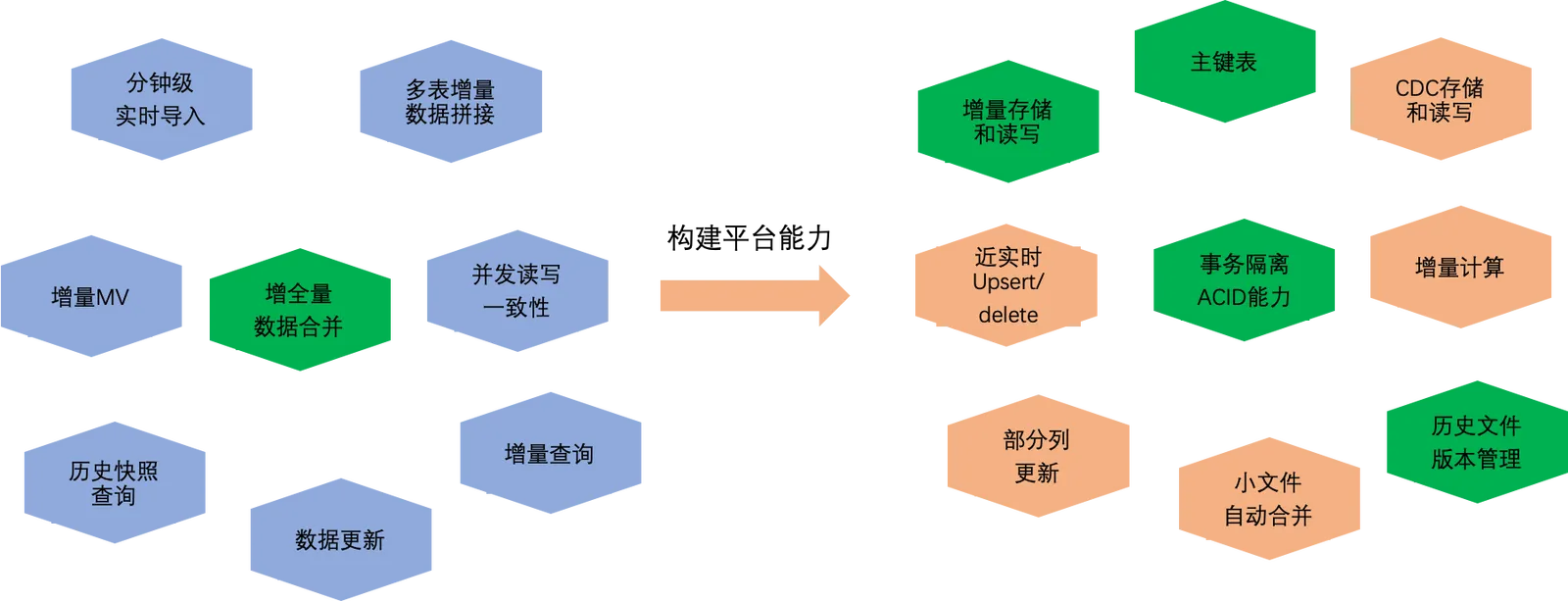
比如近即時資料匯入鏈路,依賴平台引擎具備事務隔離、小檔案自動合并等能力,又比如增全量資料合併鏈路,還依賴增量資料存放區和讀寫,主鍵等能力。在MaxCompute推出新架構之前,為了支援這些複雜的綜合業務情境,只能依賴於下圖所示的三種解決方案,這三種解決方案在成本、易用性、低延時、高吞吐等方面相互制約,很難同時具備較好的效果。如下圖所示。
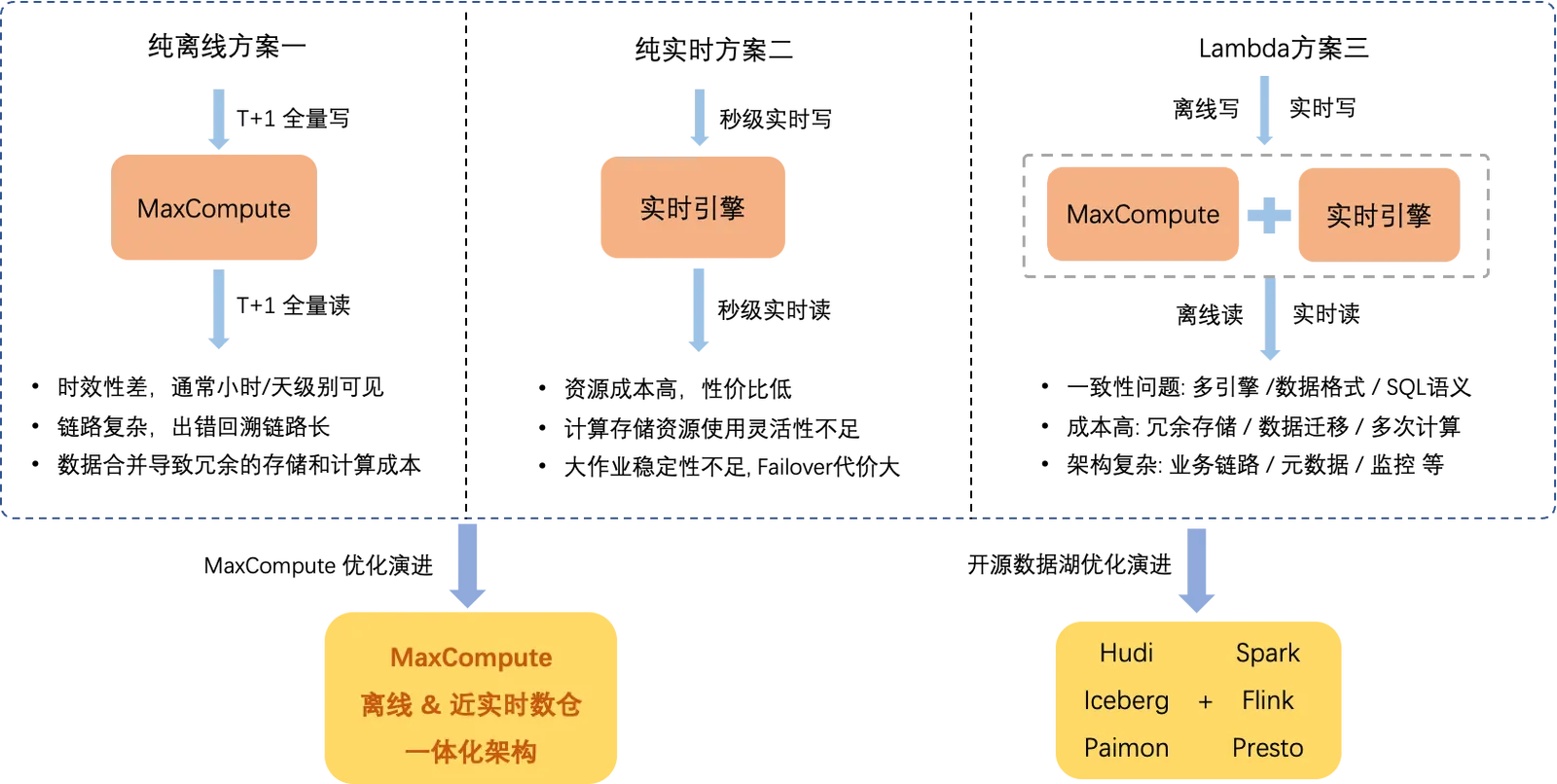
在巨量資料開源生態領域,針對這些問題已經出現了一些典型的解決方案,其中最典型的是Spark、Flink、Trino等開來源資料處理引擎,它們深度整合了Hudi、Delta Lake、Iceberg、Paimon等開來源資料湖,並以開放統一的計算引擎和資料存放區理念為基礎,提供瞭解決Lambda架構帶來的一系列問題的方案。
近即時增全量一體化架構
基於上述背景,MaxCompute推出近即時增全量一體化架構,支援豐富的資料來源,並通過定製開發的接入工具實現增量和離線批量資料匯入到統一的儲存中,由後台資料管理服務自動最佳化編排資料存放區結構,使用統一的計算引擎支援近即時增量處理鏈路和大規模離線批量處理鏈路,而且有統一的中繼資料服務支援事務和檔案中繼資料管理。如下圖所示。
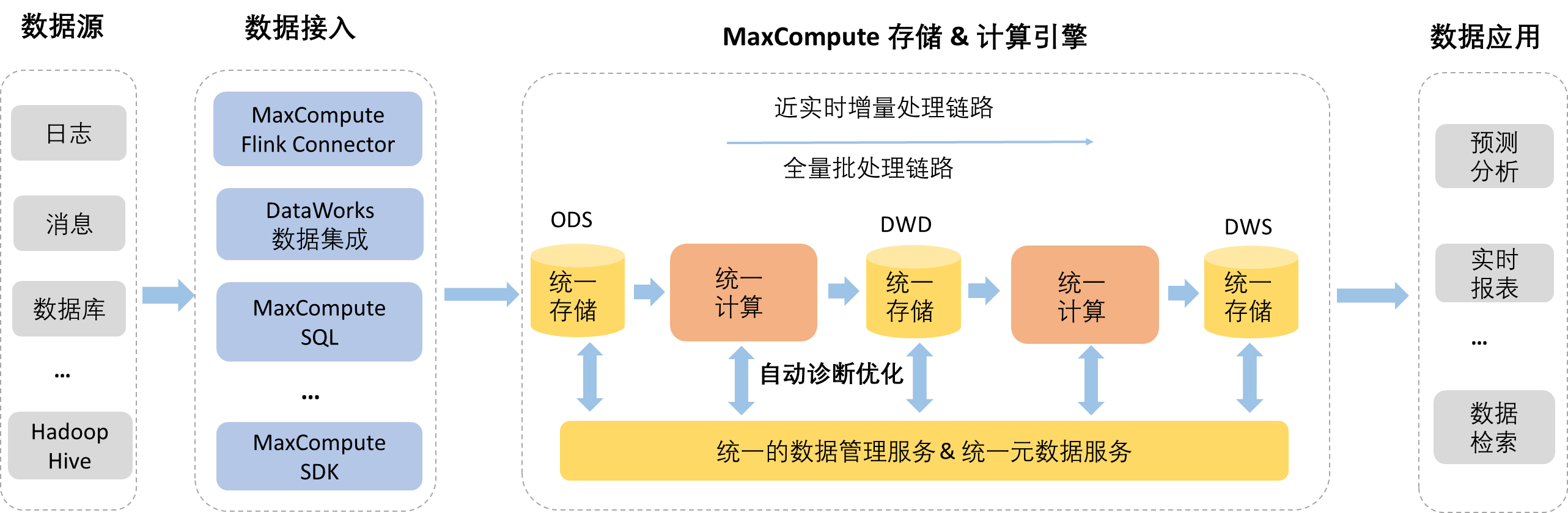
當前架構已支援了部分核心能力,包括主鍵表,Upsert即時寫入、Time travel查詢、增量查詢、SQL DML操作、表資料自動治理最佳化等。架構原理和相關操作詳情,請參見Delta Table概述和基本操作。
架構優勢
近即時增全量一體化架構儘可能涵蓋了開來源資料湖(HUDI、Iceberg)的主要通用功能,以便於相關業務鏈路之間的遷移。此外,作為完全自研設計的新架構,在功能、效能、穩定性和整合等方面也具備許多獨特亮點:
統一的儲存服務、中繼資料和計算引擎,實現了深度和高效的整合。該系統具備低成本的儲存、高效的資料檔案管理和查詢效率,同時還支援Time travel增量查詢。
開發一套通用且完備的SQL文法系統,支援所有核心功能。
深度定製最佳化的資料匯入工具,支援很多複雜的業務情境。
無縫銜接MaxCompute現有的業務情境,減少資料移轉的繁瑣與風險,同時還降低了資料存放區和計算成本。
實現完全自動化的資料檔案管理,以確保更佳的讀寫穩定性和效能,自動最佳化儲存效率並降低成本。
基於MaxCompute平台完全託管,可以開箱即用,無需額外接入成本,功能生效只需建立Delta Table即可。
作為完全自主研發的架構,需求開發節奏完全自主可控。
業務情境
表格式和資料治理
建表
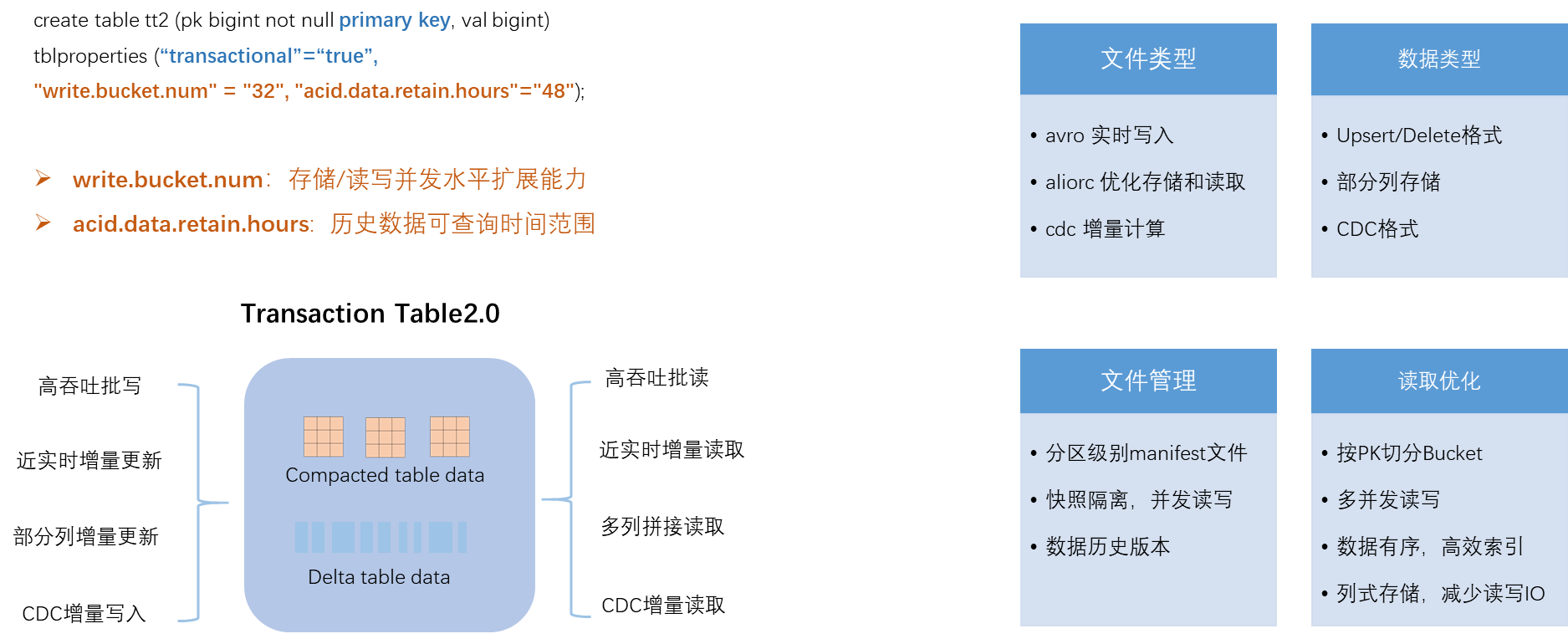
為了支援近即時增全量一體化架構,MaxCompute引入Delta Table並統一了表資料群組織格式,可以同時支援既有的批處理鏈路,以及近即時增量等新鏈路的所有功能。建表文法樣本如下。
CREATE TABLE tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) tblproperties ("transactional"="true");
CREATE TABLE par_tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) PARTITIONED BY (pt STRING) tblproperties ("transactional"="true");執行建表命令CREATE TABLE建立Delta Table表,只需要設定主鍵Primary Key(PK)以及"transactional"="true"。其中,PK用來保障資料行的Unique屬性,transactional屬性用來配置ACID事務機制,滿足讀寫快照隔離。建表詳情請參見表操作。
Delta Table表關鍵屬性
Delta Table表屬性詳情請參見Delta Table表參數。其中關鍵屬性介紹如下:
write.bucket.num:預設值為16,取值範圍為
(0, 4096]。表示每個分區或非分區表的分桶數量,也表示資料寫入的並發節點數量。分區表支援修改,新分區預設生效,非分區表不支援修改。說明資料寫入和查詢的並發度可以通過增加桶數量來實現水平擴充,但是,並非桶數量並非越多越好。因為每個資料檔案會歸屬於一個桶,桶數量的增加會導致更多的小檔案產生,進一步增加儲存成本和壓力,同時也會影響讀取效率。對於桶數量的建議如下:
通用情境(包含非分區表/分區表情況):
如果資料量小於1 GB,建議將bucket桶的數量設定為4~16個。
如果資料量大於1 GB,建議每個bucket桶承載的資料大小可設在128 MB~256 MB之間。
當資料量大於1 TB時,建議每個bucket桶的資料範圍調整為500 MB~1 GB。
海量分區增量表的分區推薦:
對於存在海量分區(500個分區以上)的增量表,並且每個分區的資料量較小(比如在幾十兆以內),建議每個分區的bucket桶數量儘可能少,配置在1~2個即可,避免產生過多的小檔案片段。
acid.data.retain.hours:預設取值為24,取值範圍為[0, 168]。表示Time travel可查詢資料歷史狀態的時間範圍(單位:小時)。如果您不需要Time travel查詢歷史資料,建議將此屬性值設定為0,代表關閉Time travel查詢功能,這樣可以有效節省資料歷史狀態的儲存成本。若需要超過168小時(7天)的長時間TimeTravel歷史回溯,可聯絡MaxCompute支援人員。
建議您按照實際的業務情境設定合理的時間周期,設定的時間越長,儲存的歷史資料越多,產生的儲存費用就越多,而且也會在一定程度上影響查詢效率。
說明超過已配置的時間後,系統開始自動回收清理,一旦清理完成,Time travel就查詢不到對應的歷史狀態了。回收的資料主要包含動作記錄和資料檔案兩部分。
特殊情況下您可執行
purge命令,手動觸發強制清除歷史資料。
Schema Evolution
Delta Table支援完整的Schema Evolution操作,包括增加和刪除列。在Time travel查詢歷史資料時,會根據歷史資料的Schema來讀取資料。另外,PK列不支援修改。簡單樣本如下。詳細DDL文法詳情,請參見表操作。
ALTER TABLE tt2 ADD columns (val2 string);表資料群組織格式
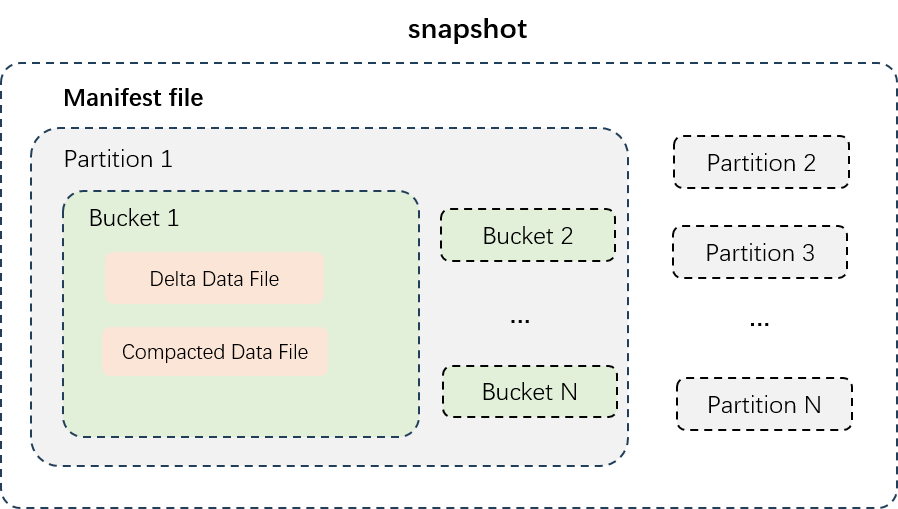
如上圖所示,展示了分區表的資料結構,先按照分區對資料檔案進行物理隔離,不同分區的資料在不同的目錄之下。每個分區內的資料按照桶數量來切分資料,每個桶的資料檔案單獨存放。資料檔案類型主要分為Delta Data File和Compacted Data File兩種:
Delta Data File:每次事務寫入或者小檔案合并後產生的增量資料檔案,會儲存每行記錄的中間歷史狀態,用於滿足近即時增量讀寫需求。
Compacted Data File:Delta Data File經過Compact執行產生的資料檔案,會消除資料記錄的中間歷史狀態,PK值相同的記錄只會保留一行,按照列式壓縮儲存,用來支撐高效的資料查詢需求。
資料自動治理最佳化
存在的問題-小檔案膨脹
Delta Table支援分鐘級近即時增量資料匯入。但在高流量即時寫入情境下可能會導致增量小檔案數量膨脹,尤其是桶數量較大的情況,從而引發儲存訪問壓力大、成本高,資料讀寫I/O效率低下等問題。如果Update和Delete格式的資料較多,也會造成資料中間狀態的冗餘記錄較多,進一步增加儲存和計算的成本,查詢效率降低等問題。
解決方案-自動治理與最佳化
MaxCompute儲存引擎配套支援了合理高效的表資料服務,對儲存資料進行自動治理與最佳化,降低儲存和計算成本,提升分析處理效能。
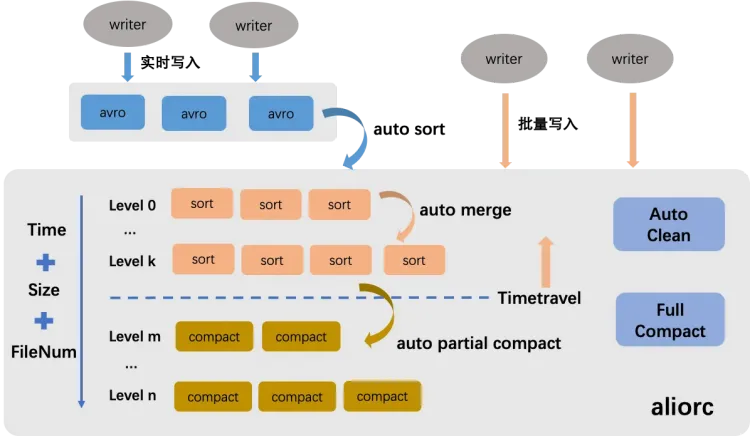
如上圖所示,Delta Table的表資料服務主要分成Auto Sort、Auto Merge、Auto Partial Compact、Auto Clean,您無需手動設定,儲存引擎服務會智能識別並自動收集各個維度資料資訊,配置合理的策略自動執行。
Auto Sort:支援將即時寫入的行存Avro檔案轉換為AliORC列式儲存格式,從而顯著降低儲存開支成本並大幅提升資料讀取效能。
Auto Merge:自動合并小檔案,解決小檔案數量膨脹引發的各種問題。
主要策略是周期性地根據資料檔案大小、檔案數量、寫入時序等多個維度進行綜合分析,進行分層次的合并。該過程確保不會清除任何記錄的中間歷史狀態,從而保證Time travel查詢的完整性和可追溯性。
Auto Partial Compact:自動合并檔案並消除記錄的歷史狀態,以降低Update和Delete記錄過多所帶來的額外儲存成本,並提升讀取效率。
主要策略是周期性地根據增量資料大小、寫入時序以及Time travel查詢時間等多個維度進行綜合分析來執行Compact操作。
說明該操作只針對超過Time travel可查詢時間範圍的記錄進行Compact操作。
Auto Clean:將自動清理無效檔案,節省儲存成本。Auto Sort、Auto Merge、Auto Partial Compact操作執行完成並產生新的資料檔案後,原有的資料檔案即失去實際效用,系統會即時啟動自動刪除流程,迅速釋放儲存空間,確儲存儲成本的即時節約。
對於對查詢效能有極高要求的情境,您可考慮手動觸發全量資料的major compact操作。詳情請參見COMPACTION。
SET odps.merge.task.mode=service; ALTER TABLE tt2 compact major;說明該操作對每個資料桶內的全部資訊進行深度整合,徹底消除所有歷史狀態,同時產生全新的Aliorc列式隱藏檔,因此,此類操作不僅會產生額外的執行開銷,還會增加新組建檔案的儲存成本,建議僅在必要時實施。
資料寫入
分鐘級近即時Upsert寫入
MaxCompute離線架構一般以小時或天層級,大量匯入增量資料至新表或新分區中。然後配置對應的離線ETL處理鏈路,將增量資料和存量表資料進行Join Merge操作,產生新的全量資料。此離線鏈路的延時較長,資源和儲存也會有一定的消耗。
近即時增全量一體化架構的Upsert即時寫入鏈路,可以保持資料從寫入到查詢的延時在5~10分鐘,滿足分鐘級近即時業務需求,並且不需要複雜的ETL鏈路來進行增全量資料的合併作業,節省了相應的計算和儲存成本。且在實際業務資料處理情境中,涉及的資料來源豐富多樣,可能存在資料庫、日誌系統或者其他訊息佇列等系統。為了方便您將資料寫入Delta Table, MaxCompute深度定製開發了開源的Flink Connector工具,聯合DataWorksData Integration以及其他資料匯入工具,針對高並發、容錯、事務提交等情境做了定製化的設計及開發最佳化,以滿足延時低、正確性高等要求。
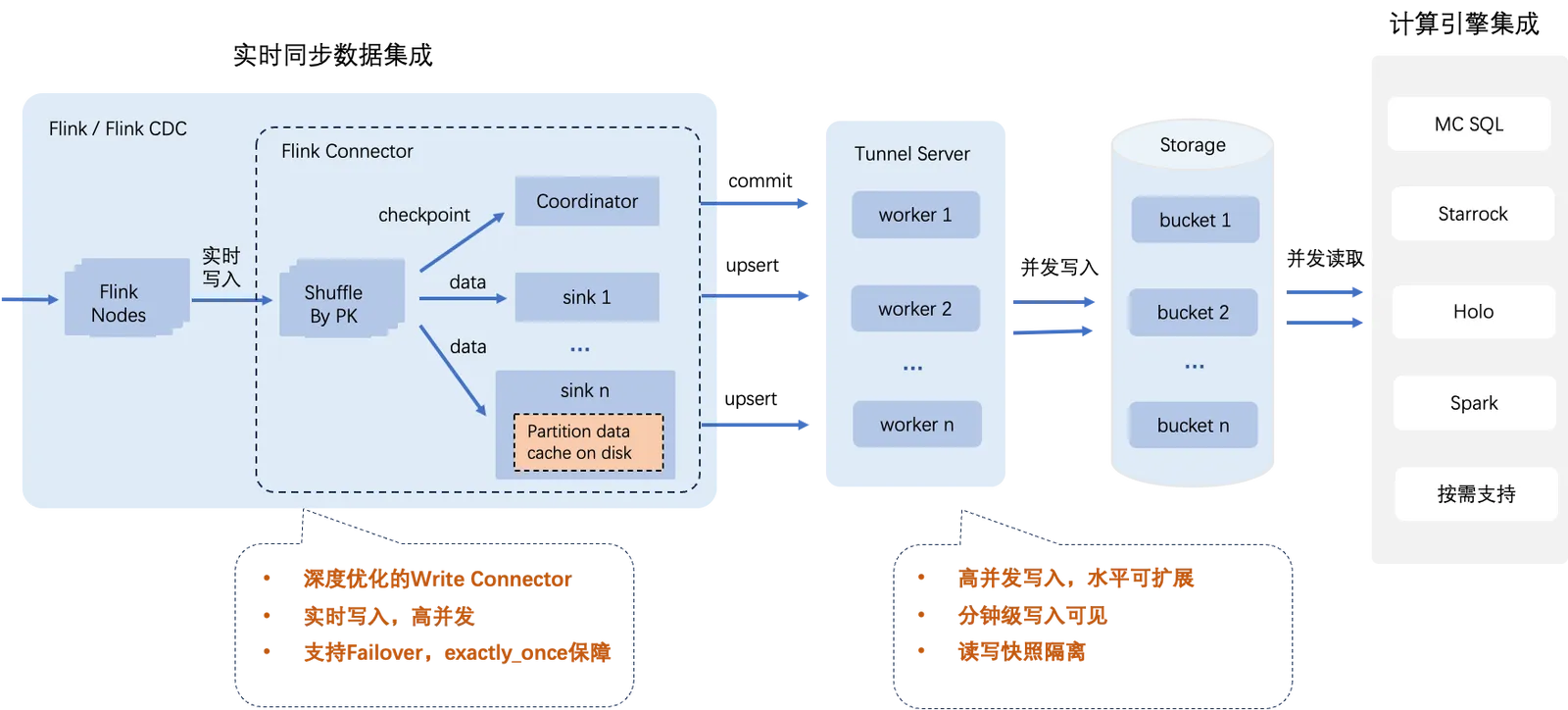
如上圖所示:
主要相容Flink生態的計算引擎與工具都可通過配置Flink作業,有效地利用MaxCompute Flink Connector實現對Delta Table的即時資料寫入。
通過調整Delta Table表屬性write bucket num,可以靈活配置寫入並發度,從而實現寫入速度的水平擴充。
由於MaxCompute進行了高效最佳化,若將Delta Table表屬性write bucket num配置為Flink sink並發數的整數倍,其寫入效能最佳。
結合Flink內建的Checkpoint機制處理容錯情境,確保資料處理過程遵循exactly_once語義。
支援上千分區同時寫入,滿足海量分區並發寫入情境需求。
滿足資料分鐘級可見,支援讀寫快照隔離。
不同的環境和配置都可能對流量吞吐情況產生影響,流量吞吐上限可參考單個桶1 MB/s的處理能力進行評估。MaxCompute資料轉送渠道預設使用共用的公用Data Transmission Service資源群組,可能會存在輸送量不穩定的問題,尤其是在資源競爭激烈時,並且存在資源使用上限。為了確保更穩定地寫入輸送量,您可以選擇購買與使用獨享Data Transmission Service資源群組。
說明獨享Data Transmission Service資源需額外收費,詳情請參見資料轉送獨享資源費用(訂用帳戶)。
資料庫整庫即時同步寫入-DataWorksData Integration
當前資料庫系統與巨量資料處理引擎都有各自擅長的資料處理情境,面對一些複雜的業務需求,往往需要同時運用OLTP(聯機交易處理)、OLAP(線上分析處理)及離線分析引擎來對資料進行全面且深入的分析與處理,因此資料就需要在不同引擎間流轉。其中,將資料庫中單表或至整庫的即時更新記錄無縫同步至MaxCompute進行分析處理是目前比較典型的業務鏈路。
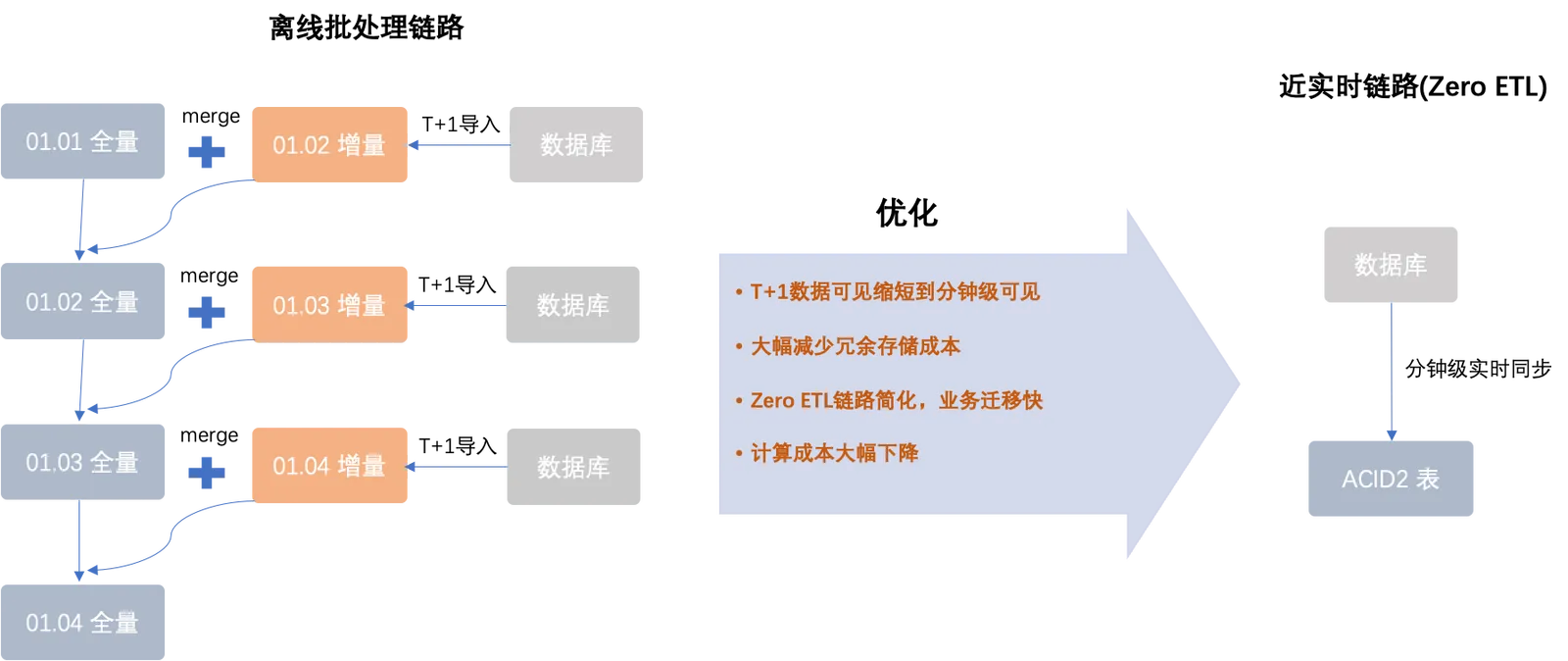
如上圖所示:
左邊流程是MaxCompute離線架構,一般以小時或天層級大量匯入增量資料至新表或新分區中,然後配置對應的離線ETL處理鏈路,將增量資料和存量表資料進行Join Merge操作,產生新的全量資料。此離線鏈路的延時較長,資源和儲存也會有一定的消耗。
右邊流程是近即時增全量一體化架構,與MaxCompute離線架構相比摒棄了繁瑣的周期性提取與合并過程,實現即時(以分鐘層級精確度)讀取資料庫中的變更記錄,而且僅依賴單一的Delta Table即可完成資料更新,從而最大限度地削減了計算與儲存成本。
SQL DML與Upsert批處理鏈路
為了讓您更便捷地操作Delta Table,並輕鬆實現複雜資料查詢和操作需求,MaxCompute已對SQL引擎的核心模組Compiler、Optimizer和Runtime等進行了適配和最佳化,並實現了特定文法解析、最佳化計劃、PK列去重邏輯以及Runtime Upsert並發寫入等功能,確保對SQL文法的全套支援。如下圖所示。
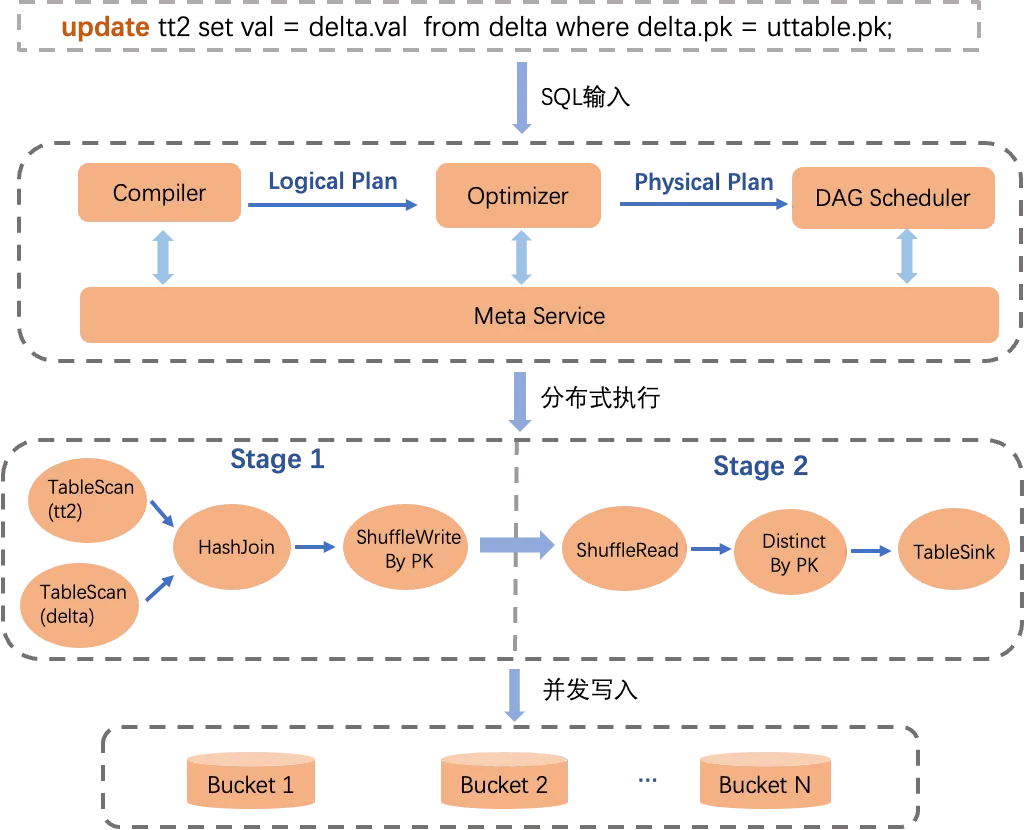
其中:
在資料處理完成之後,Meta Service會執行事務衝突檢測,原子更新資料檔案元資訊等,以保障讀寫隔離和事務一致性。
對於Upsert批式寫入能力,由於Delta Table表在查詢時會自動根據PK值來合并記錄,因此對於Insert和Update情境,不需要使用複雜的Update、Merge Into文法,可統一使用Insert Into插入新資料即可,使用簡單,並且能節省一些讀取I/O和計算資源。SQL DML文法詳情,請參見DML操作。
資料查詢
Time travel時間旅行查詢
MaxCompute Delta Table計算引擎可高效支援Time travel查詢的典型業務情境,即查詢歷史版本的資料。該功能可用於回溯歷史狀態的業務資料,或在資料出錯時用來恢複歷史狀態資料以進行資料校正。同時,也支援直接使用Restore操作恢複到指定的歷史版本。簡單樣本如下。
//查詢指定時間戳記的歷史資料
SELECT * FROM tt2 TIMESTAMP AS OF '2024-04-01 01:00:00';
//查詢5分鐘之間的歷史資料
SELECT * FROM tt2 TIMESTAMP AS OF CURRENT_TIMESTAMP() - 300;
//查詢截止到最近第二次Commit寫入的歷史資料
SELECT * FROM tt2 TIMESTAMP AS OF GET_LATEST_TIMESTAMP('tt2', 2);Time travel查詢處理過程如下所示。
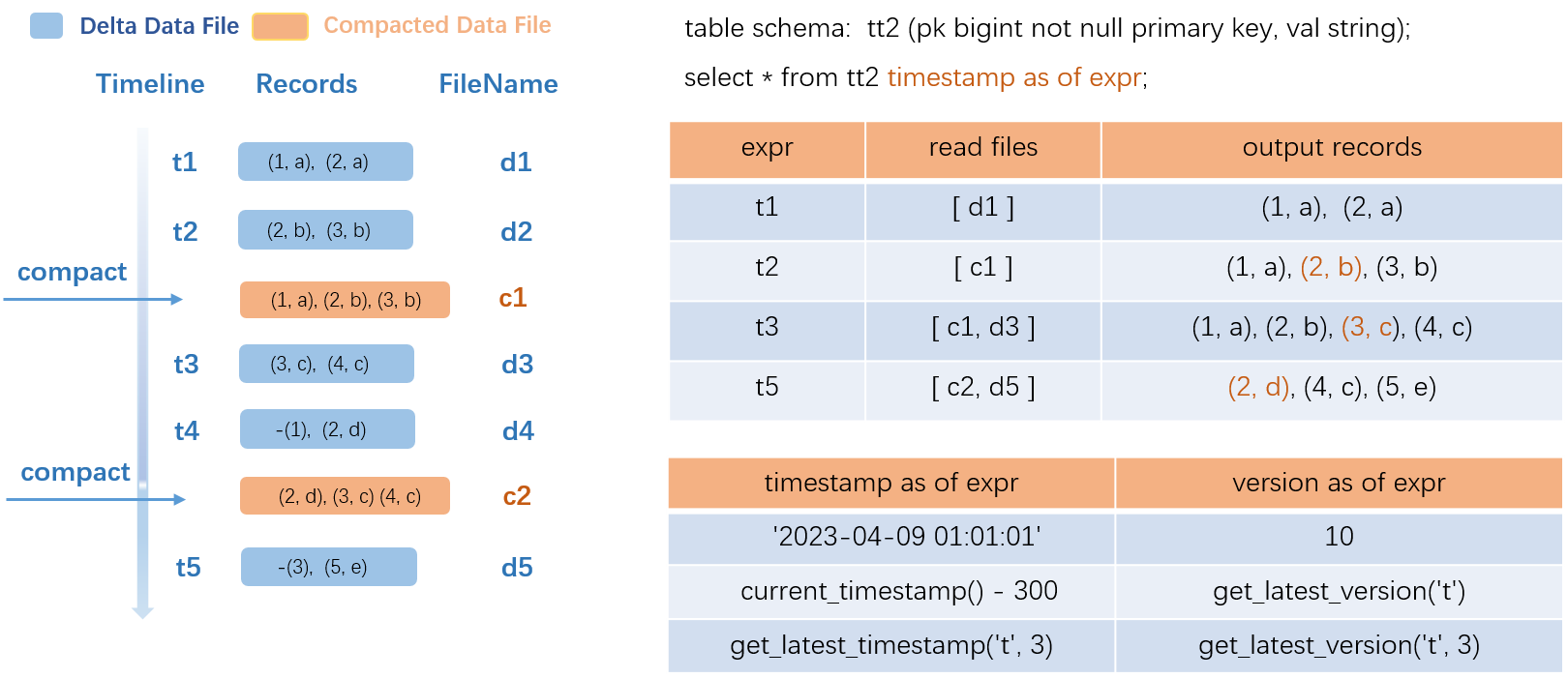
在輸入Time travel查詢語句後,會先從Meta服務中解析出要查詢的歷史資料版本,然後過濾出要讀取的Compacted Data File和Delta Data File,進行合并然後輸出。其中,Compacted Data File可以用來加速查詢,提高讀取效率。
上圖以事務表(src)為例:
圖左側展示了資料變化過程,t1~t5代表了5個事務的時間版本,分別執行了5次資料寫入的事務,產生了5個Delta Data File,在t2和t4時刻分別執行了COMPACTION操作,產生了2個Compacted Data File(c1和c2),其中c1已經消除了中間狀態記錄
(2,a),只保留最新狀態的記錄(2,b)。如查詢t1時刻的歷史資料,只需讀取Delta Data File資料類型的d1並輸出;如查詢t2時刻的歷史資料,只需讀取Compacted Data File資料類型的c1並輸出其三條記錄;如查詢t3時刻的歷史資料,就會輸出Compacted Data File資料類型的c1以及Delta Data File資料類型的d3併合並輸出,可以此類推其他時刻的查詢。可見,Compacted Data File檔案雖可用來加速查詢,但需要觸發較重的COMPACTION操作,您需要結合自己的業務情境選擇合適的觸發策略。
在SQL文法中,除了可以直接指定一些常量和常用函數外,您可以通過TIMESTAMP AS OF expr和VERSION AS OF expr函數進行精準查詢。
增量查詢
為了實現Delta Table的增量查詢和增量計算最佳化,MaxCompute專門設計並開發了新的SQL增量查詢文法。關於增量查詢文法,詳情請參見Incremental查詢參數與使用限制。增量查詢處理過程如下圖所示。
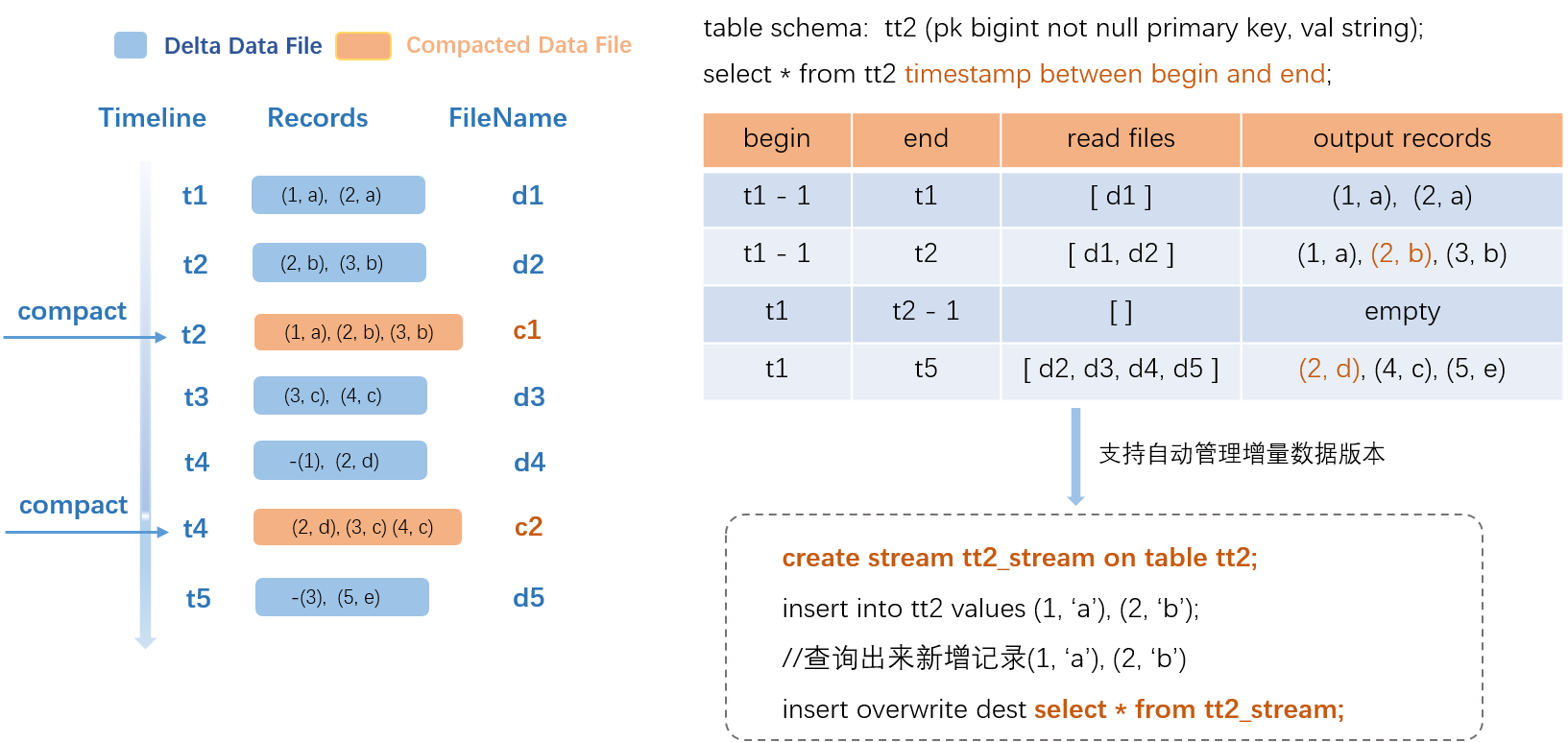
在輸入SQL語句後,MaxCompute引擎將會解析要查詢的歷史增量資料版本,並過濾要讀取的Compacted Data File檔案,然後進行合并輸出。上圖以事務表(src)為例:
圖左側展示了資料變化過程,t1~t5代表了5個事務的時間版本,分別執行了5次資料寫入的事務,產生了5個Compacted Data File,在t2和t4時刻分別執行了COMPACTION操作,產生了2個Compacted Data File(c1和c2)。
在具體的查詢樣本中,例如,begin是t1-1,end是t1,只需讀取t1時間段對應的Delta Data File(d1)進行輸出;如果end是t2,會讀取兩個Delta Data File(d1和d2);如果begin是t1,end是t2-1,即查詢的時間範圍為t1和t2,這個時間段沒有任何增量資料插入的,將返回空行。
Compact、Merge服務產生的資料(c1和c2)不會作為新增資料重複輸出。
PK主鍵點查-DataSkipping查詢最佳化
Delta Table的資料分布和索引基本是按照PK列值進行構建的,當查詢Delta Table時,通過指定PK值進行過濾,可以顯著降低資料讀取量和查詢時間,從而極大地減少資源消耗,效率可能提升數百到數千倍。DataSkipping最佳化實施過程中涵蓋多個層級的精確篩選,以高效定位並讀取指定PK值的資料。例如:Delta Table表的資料記錄為一億條,按照PK值進行過濾,真正從資料檔案中讀取的資料記錄可能只有一萬條,資料查詢過程如下圖所示。
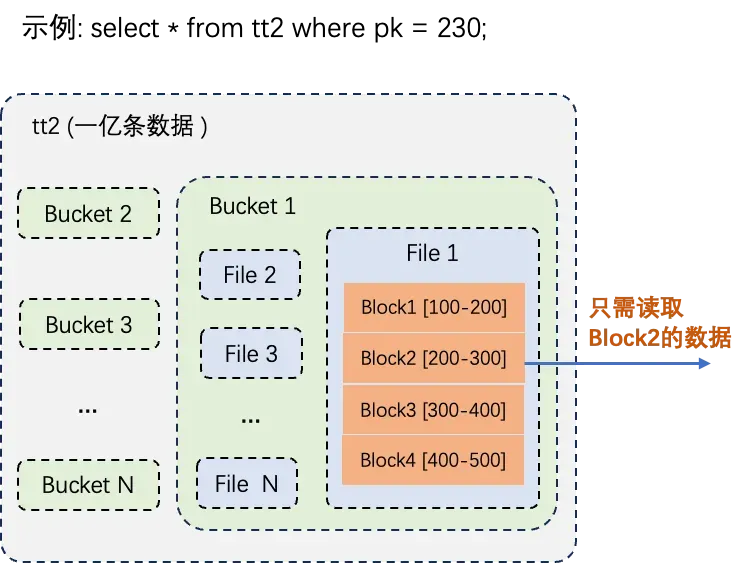
具體過程如下:
Bucket裁剪:首先鎖定含有目標主索引值的特定Bucket,避免對無關的Bucket進行掃描。
資料檔案內部裁剪:在已確定的Bucket內,進一步篩選僅包含所需主索引值的資料檔案,以確保讀取操作的針對性。
Block級主索引值域過濾:深入到檔案內部的Block層面,依據Block中主索引值的分布範圍進行精確過濾,確保僅提取包含指定主索引值的Block進行處理。
SQL查詢分析Plan最佳化
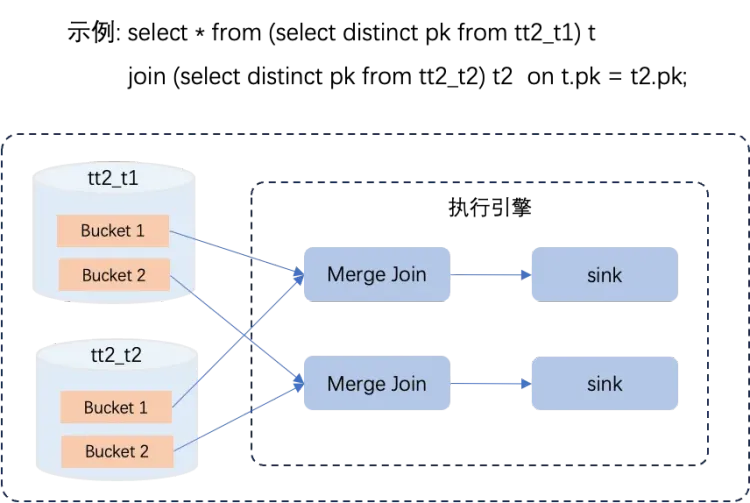
如上圖所示,Delta Table表資料已根據其PK值進行了分桶分布處理,且各桶內資料具有唯一性(Unique)和有序性(Sort),基於這些屬性SQL Optimizer主要做了以下最佳化:
利用PK列的Unique屬性避免了去重(Distinct)操作。由於查詢涉及的PK列本身就保證了唯一性,SQL Optimizer能夠識別並省略Distinct運算步驟,從而避免了額外計算開銷。
應用Bucket Local Join可避免全域Shuffle。由於Join操作依據的關鍵字段與PK列相同,SQL Optimizer能夠選擇執行Bucket Local Join策略,避免全域Shuffle過程。這極大地降低了資料在節點間大規模交換的需要,減少了資源消耗,從而提升了處理速度和系統的整體效能。
基於資料的有序性採用Merge Join演算法替代Sort。由於每個分桶內的資料是有序的,SQL Optimizer可以選擇高效的Merge Join演算法進行串連操作,無需預先對資料進行排序,從而降低計算複雜度,節省了計算資源。
通過消除Distinct、Sort和全域Shuffle等高資源消耗的運算元,實現了查詢效能超過一倍的提升,充分展現了對Delta Table表特性的有效利用及其對查詢效率的重大影響。