本文為您介紹近即時數倉方案可解決的業務痛點和主要架構功能。
背景資訊
企業依賴巨量資料平台快速地從海量資料中獲得洞察從而更及時和有效地決策的同時,也對處理資料的新鮮度和處理本身的即時性要求越來越高。巨量資料平台普遍採用離線、即時、流三種引擎組合的方式以滿足使用者即時性和高性價比的需求。但是很多業務情境並不要求延時秒級更新可見或者行級更新,更多的需求是分鐘級或者小時級的近即時資料處理疊加海量資料批處理情境,MaxCompute在原有的離線批處理引擎基礎上升級架構,推出了近即時數倉解決方案。
MaxCompute近即時數倉,基於Delta table實現了增全量資料一體化儲存和管理,並且推出了豐富的增量計算能力,同時升級了MaxCompute短查詢加速(MCQA2.0)以支援查詢秒級返回。
現狀分析
典型的資料處理業務情境:
對於時效性要求低的大規模資料全量批處理的單一情境,直接使用MaxCompute足以很好的滿足業務需求。
對於時效性要求很高的秒級即時資料處理或者流處理,則需要使用即時系統或流系統來滿足需求。
綜合業務情境:對於時效性要求為分鐘級或者小時級的近即時資料處理情境和海量資料批處理情境的解決方案,使用單一或者聯邦多引擎都會存在一些問題。
當前架構分析如下:
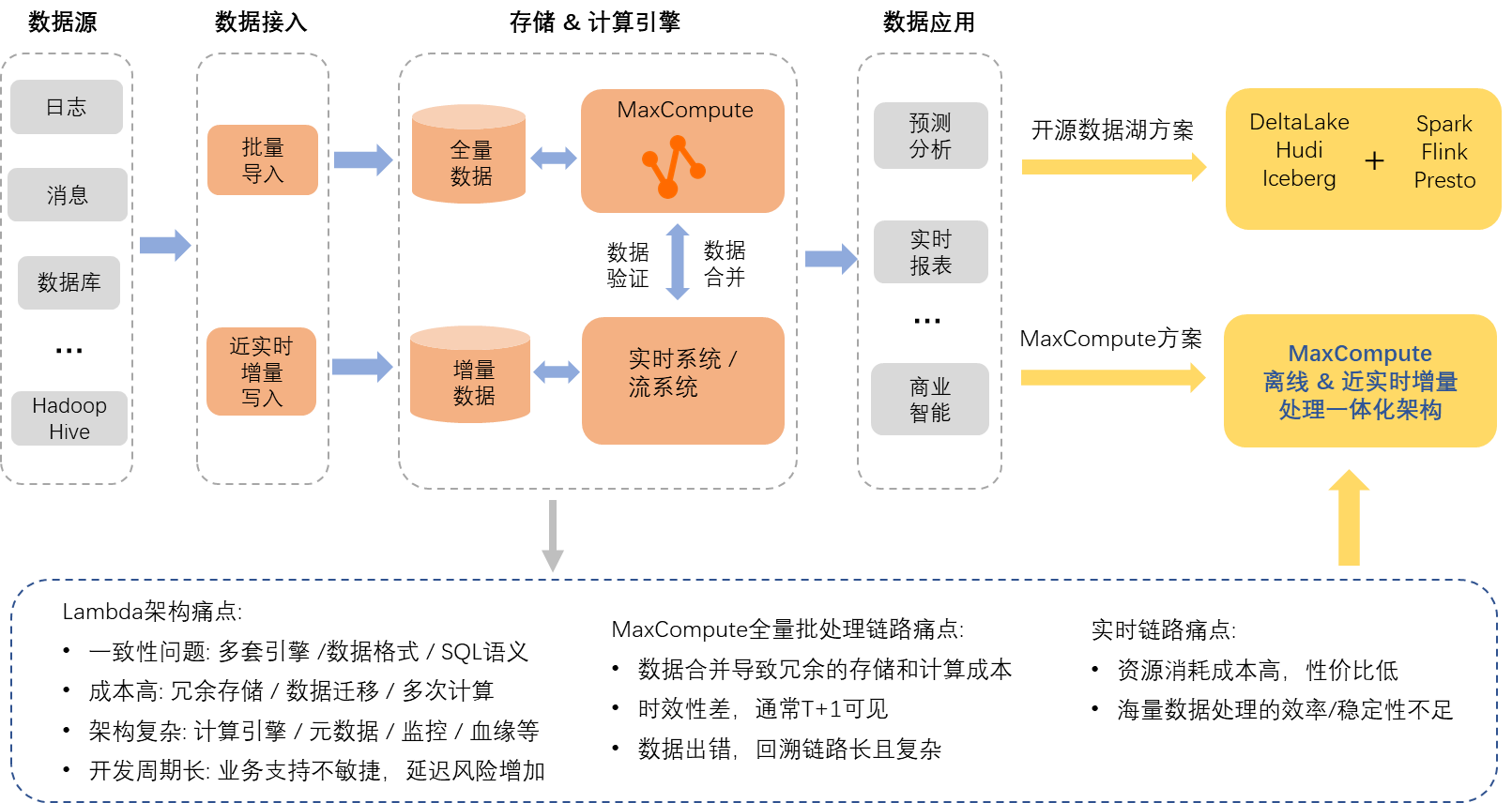
如果使用單一的MaxCompute離線批量處理鏈路,有些情境需持續將使用者分鐘級增量資料和全量資料做合并處理和儲存,產生冗餘的計算和儲存成本,也有情境需要將各種複雜的一些鏈路和處理邏輯轉化成T+1的批次處理,極大增加鏈路複雜度,且時效性也較差。
如果使用單一的即時系統,資源消耗的成本比較高,性價比也較低,並且大規模資料批處理的穩定性也不足。因此當前比較典型的解決方案是Lambda架構,全量批處理使用MaxCompute鏈路,時效性要求比較高的增量處理使用即時系統鏈路,但該架構也存在大家所熟知的一些固有缺陷,比如多套處理和儲存引擎引發的資料不一致問題,多份資料冗餘儲存和計算引入的額外成本,架構複雜以及開發週期長等。
針對這些問題近幾年巨量資料開源生態也推出了各種解決方案,最流行的就是Spark/Flink/Presto開來源資料處理引擎,深度整合開來源資料湖Hudi、Delta Lake和Iceberg三劍客,踐行統一的計算引擎和統一的資料存放區思想來綜合提供解決方案,解決Lambda架構帶來的一系列問題。
MaxCompute在離線批處理計算引擎架構上,自研設計開發的增量資料存放區和處理架構,同樣可提供離線與近即時增量處理一體化解決方案,在保持經濟高效的批處理優勢下,同時具備分鐘級的增量資料讀寫和處理的業務需求,另外,可提供Upsert,Time travel等一系列實用功能來擴充業務情境,可有效地節省資料計算,儲存和遷移成本,切實提高使用者體驗。
MaxCompute近即時架構
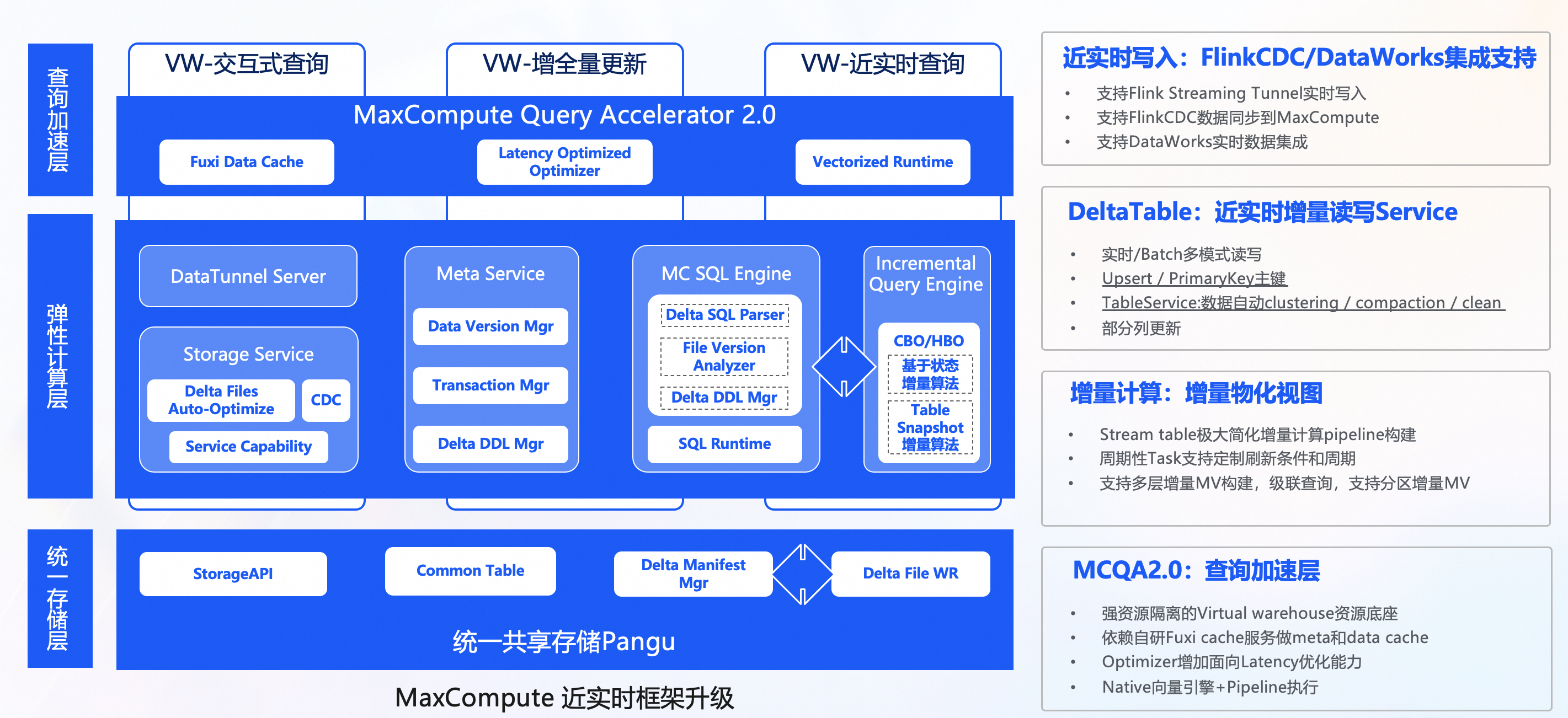
上圖所示即為MaxCompute高效支援上述綜合業務情境的全新架構,支援豐富的資料來源方便地通過定製開發的接入工具實現增量和離線批量資料匯入到統一的儲存中,由後台資料管理服務自動最佳化編排資料存放區結構,使用統一的計算引擎支援近即時增量處理鏈路和大規模離線批量處理鏈路,而且由統一的中繼資料服務支援事務和檔案中繼資料管理。
該架構帶來的優勢非常顯著,比如,可有效解決純離線系統處理增量資料導致的冗餘計算和儲存、時效低等問題,也能避免即時或流系統高昂的資源消耗成本,同時可消除Lambda架構多套系統的不一致問題和減少冗餘多份儲存成本以及系統間的資料移轉成本。
SQL Optimizer針對增量查詢也做了針對性的最佳化,尤其是MV增量重新整理情境,Optimizer基於Cost估計重新整理操作選取基於狀態的增量演算法、還是基於錶快照的增量演算法。查詢加速層(MCQA2.0)基於VW強隔離的資源底座,提升查詢效能的同時也能很好的保證查詢效能的穩定性。依賴自研的FDC,加速層做了全鏈路的Cache最佳化,Optimizer增加了面向Latency最佳化模式,Runtime也進一步最佳化向量化執行以避免執行階段Codegen相關的開銷。
總體而言,使用該全鏈路一體化架構既可以滿足增量處理鏈路的計算儲存最佳化以及分鐘級的時效性,又能保證批處理的整體高效性,還能有效節省資源使用成本。
核心功能
MaxCompute近即時數倉主要提供以下三個方面功能:支援分鐘級匯入的MC Delta Table,更好平衡Latency和Throughput的增量計算功能,全新升級的支援查詢秒級返回的MCQA2.0。

三部分核心功能如下:
Delta Table增量表格式:支援分鐘級資料匯入,這種表格式底層使用 AliORC 作為檔案格式,支援 UPSERT 語義,並能夠提供標準的 CDC(Change Data Capture)方式讀寫增量資料。它依賴於 MC 儲存服務和中繼資料服務,自動進行資料管理。
增量計算:基於Delta Table增量表格式,MaxCompute增加了增量物化視圖(Materialized View)、Time Travel 以及 Stream Table 等一系列的增量計算能力。同時增量 MV 和周期性調度Task提供了不同的觸發頻率,從而為使用者提供更多手段來平衡延遲(Latency)和輸送量(Throughput)。
MCQA2.0查詢加速:是對MaxCompute 查詢加速的全新升級,通過強隔離環境提升了效能的穩定性,並將 MCQA 1.0 僅支援 DQL SELECT 查詢擴充到了支援 SQL 全功能,包括 DDL 和 DML 等。此外,通過全鏈路緩衝(Cache)以及將作業提交鏈路多個步驟非同步化等最佳化手段,進一步提升了效能。
最重要的是,這些新能力都是基於 MaxCompute 原有的 SQL 引擎建設實現的。MaxCompute 使用者無需改變開發習慣,就能夠以更高的性價比分析海量資料。
優勢
新架構會盡量覆蓋開來源資料湖(HUDI / Iceberg)的一些通用功能,方便相關業務鏈路之間的遷移,此外,作為完全自研設計的新架構,在功能,效能,穩定性,整合等方面也具備很多獨特亮點:
統一的儲存、中繼資料、計算引擎一體化設計,做了非常深度和高效的整合,具備儲存成本低,資料檔案管理高效,查詢效率高,並且Time travel / 增量查詢可複用MaxCompute批量查詢的大量最佳化規則等優勢。
全套統一的SQL文法支援所有功能,非常便於使用者使用。
深度定製最佳化的資料匯入工具,支援很多複雜的業務情境。
無縫銜接MaxCompute現有的業務情境,可以減少遷移、儲存、計算成本。
完全自動化管理資料檔案,保證更好的讀寫穩定性和效能,自動最佳化儲存效率和成本。
基於MaxCompute平台完全託管,使用者可以開箱即用,沒有額外的接入成本,功能生效只需要建立一張Delta Table即可。
作為完全自研的架構,需求開發節奏完全自主可控。