本文為您介紹Hologres中的關鍵索引,如Distribution Key、Event Time Column(Segment Key)和Clustering Key,協助您在Hologres開發過程中快速上手使用索引,提升查詢效能。
分布式資料倉儲Hologres基本運行原理
Hologres是一個分布式資料倉儲,採用並行計算和向量計算技術實現秒級查詢響應,因此資料的分布特徵對效能有關鍵影響,包括資料在多個分布式節點間的分布均衡性(distribution_key),以及單個節點內檔案之間的分布有序性(event_time_column/segment_key)。同時Hologres在OLAP情境預設使用列儲存格式,因此資料在檔案內的有序性(clustering_key)也至關重要。掌握這三個概念,在效能最佳化時可以事半功倍。由於資料分布特徵是在資料寫入時確定,調整成本高,因此建議在建表時,設計與資料布局相關的三個屬性。而與資料布局無直接關聯的屬性,如位元影像索引(bitmap_columns),字典編碼(dictionary_columns)等,可以在建表之後,按需調整。
同時Hologres的中繼資料採用三級結構Database>Schema>Table,建議邏輯相關的表內聚在Schema下,避免跨庫查詢。Database是中繼資料隔離的基本單位,不是資源隔離的單位。
SQL最佳化的基本原理:減少IO,最佳化並發
建表時設計合適的資料分布,能夠使SQL在執行時快速命中資料,減少IO消耗,以更少的計算資源,實現更高的查詢效能,同時均衡的資料分布也使得並發資源可以充分發揮,避免單點瓶頸。下圖是一個SQL從發起到擷取資料的執行流程,可以通過下圖理解減少IO的流程。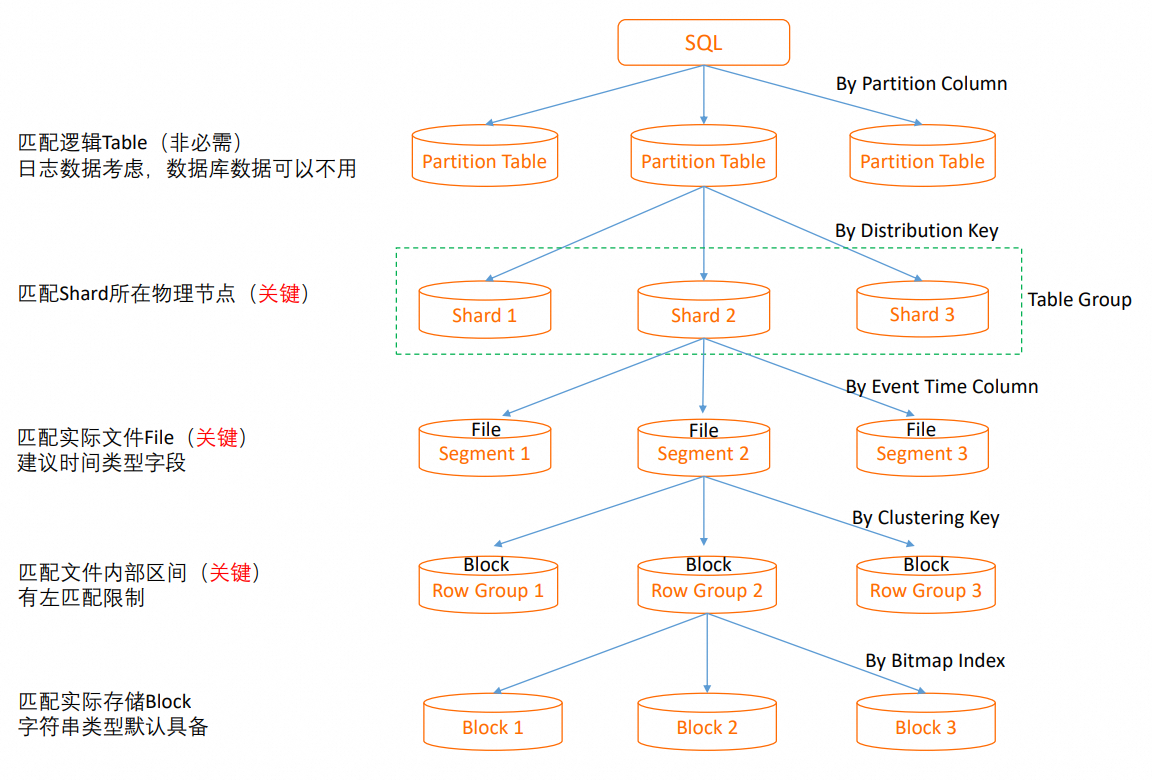
分區剪枝(Partition Pruning):SQL執行時,對於目標資料分割表,會通過分區裁剪,定位到所在分區。如果查詢條件和分區不匹配,需要遍曆所有分區,會引起過多的IO掃描,通常分區選擇日粒度比較合適。對於非分區表直接略過,不進行分區裁剪。
分區剪枝(Shard Pruning):通過分布鍵(distribution_key)快速定位到資料所在的資料分區,可以減少單個SQL執行時的資源消耗,對於並發SQL,滿足更高的吞吐能力;如果無法定位到某個分區,會通過分布式架構調度所有的分區參與計算,單個SQL的並行度更高,資源使用更多,但並發能力會降低,部分需要集中化執行的運算元會帶來額外的Shuffle開銷。通常分布鍵選擇訂單ID、使用者ID、事件ID等分布比較均衡的欄位,多個需要JOIN的表使用相同的分布鍵,可以使相關的資料分區到同一個Shard,通過Local JOIN實現更高的JOIN效率。
檔案剪枝(Segment Key Pruning):通過分段鍵(event_time_column/segment_key),快速定位到單個節點內部多個檔案中的資料所在檔案位置,避免開啟不需要訪問的檔案。如果無法過濾,則需要遍曆所有的檔案。
聚簇剪枝(Clustering Key Pruning):通過聚簇鍵(clustering_key),快速定位單個檔案內部的資料區段,提高範圍查詢和欄位排序的效率。
SQL最佳化實踐
此處以TPC-H的部分Query為例,為您介紹如何設定Hologres的索引,以獲得更好的查詢效能。關於TPC-H的詳細介紹,請參見測試方案介紹。
TPCH SQL參考實踐
TPC-H Q1 Query
TPC-H Q1主要是對lineitem表的部分欄位做彙總查詢和過濾篩選。其中:
l_shipdate <= :過濾查詢。需要設定索引以支援範圍過濾,可快速過濾出所需資料。
--TPC-H Q1
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM
lineitem
WHERE
l_shipdate <= DATE '1998-12-01' - INTERVAL '120' DAY
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;TPC-H Q4 Query
TPC-H Q4主要是對lineitem和orders表進行關聯查詢。其中:
o_orderdate >= DATE '1996-07-01':過濾查詢。需要設定索引以支援範圍過濾,可快速過濾出所需資料。l_orderkey = o_orderkey:兩表JOIN。需要為兩個表設定同一個索引,最好能進行Local JOIN,以減少資料在兩表互動時的Shuffle操作。--TPC-H Q4 Query SELECT o_orderpriority, COUNT(*) AS order_count FROM orders WHERE o_orderdate >= DATE '1996-07-01' AND o_orderdate < DATE '1996-07-01' + INTERVAL '3' MONTH AND EXISTS ( SELECT * FROM lineitem WHERE l_orderkey = o_orderkey AND l_commitdate < l_receiptdate ) GROUP BY o_orderpriority ORDER BY o_orderpriority;
建表建議
在上述的Q1和Q4查詢中,主要涉及lineitem和orders兩張表,分別如下:
hologres_dataset_tpch_100g.lineitem
Q1和Q4中均涉及對lineitem表的查詢,其中使用的欄位和查詢條件不同。
對於Q1 Query:主要用l_shipdate做範圍過濾篩選。clustering_key可以利用檔案內的有序性加速範圍過濾,因此我們可將l_shipdate設定為Clustering Key。segment_key(event_time_column)用於保持檔案間的有序性,對於單調遞增/遞減的日期欄位,也建議設定為Segment Key,可以有效進行檔案層過濾,因此也可將l_shipdate設定為Segment Key。
對於Q4 Query :主要用lineitem表的l_orderkey欄位與orders表的o_orderkey欄位進行關聯查詢(JOIN)。distribution_key用於指定資料的分布策略,系統會根據distribution_key,將相同的資料存放在同一個Shard上,當兩張表在同一個Table Group內,並且JOIN的欄位是Distribution Key時,在進行資料寫入時,會自動將兩張表重相同Key的記錄分發到同一個Shard上,當表進行JOIN時,只需要在當前節點進行Local JOIN,無需按照JOIN Key進行資料Shuffle,避免了運行時資料打散和重分發,可以顯著提高執行效率。因此,我們將l_orderkey設定為Distribution Key。
最終lineitem表的表結構如下:
BEGIN; CREATE TABLE hologres_dataset_tpch_100g.lineitem ( l_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER) ) WITH ( distribution_key = 'L_ORDERKEY',--在join時可以實現local join clustering_key = 'L_SHIPDATE',--加速範圍過濾 event_time_column = 'L_SHIPDATE'--加速檔案裁剪 ); COMMIT;
hologres_dataset_tpch_100g.orders
本樣本中,orders表參與Q4 Query的計算。
將orders表的o_orderkey欄位設定為Distribution Key,可有效利用Local JOIN的能力,提升關聯(JOIN)查詢的效率。
o_orderdate欄位主要用於日期欄位的過濾查詢,所以將其設定為Segment Key,加速檔案的裁剪。
最終orders表的表結構如下:
BEGIN; CREATE TABLE hologres_dataset_tpch_100g.orders ( O_ORDERKEY BIGINT NOT NULL PRIMARY KEY, O_CUSTKEY INT NOT NULL, O_ORDERSTATUS TEXT NOT NULL, O_TOTALPRICE DECIMAL(15,2) NOT NULL, O_ORDERDATE timestamptz NOT NULL, O_ORDERPRIORITY TEXT NOT NULL, O_CLERK TEXT NOT NULL, O_SHIPPRIORITY INT NOT NULL, O_COMMENT TEXT NOT NULL ) WITH ( distribution_key = 'O_ORDERKEY',--在join時可以實現local join event_time_column = 'O_ORDERDATE'--加速檔案裁剪 ); COMMIT;
範例資料匯入
通過HoloWeb一鍵匯入公用資料集功能,將TPC-H 100 GB的資料快速匯入至Hologres執行個體中,詳情請參見一鍵匯入公用資料集。
效能測試結果對比
為表設定了合適的屬性(索引)後,測試最佳化前後的效能結果。
測試環境
執行個體規格:32 Core。
網路類型:VPC網路。
使用PSQL用戶端執行兩次Query,取第二次執行的時間。
測試結論
對於單表的過濾查詢,將過濾欄位設定為Clustering Key,可以有效加速查詢。
對於多表關聯的查詢,將JOIN欄位設定為Distribution Key,可以顯著加速JOIN效率。
Query
Hologres設定索引的Latency
Hologres未設定任何索引的Latency
Q1
48.293 ms
59.483 ms
Q4
822.389 ms
3027.957 ms
附錄資料參考
閱讀更多
技術原理篇
Hologres技術原理揭秘(架構、儲存引擎、計算引擎等核心原理揭秘):阿里巴巴雲原生即時數倉核心技術揭秘。
服務開通篇
如何選擇規格:執行個體規格概述。
子帳號必讀:RAM使用者權限授權快速入門。
資料匯入篇
Flink即時寫入、維表查詢:Flink全託管。
MySQL、Oracle、PolarDB等資料庫資料實現整庫即時同步:配置資料來源(來源為MySQL)。
匯入OSS資料:OSS資料湖加速。
資料寫入必讀:使用Fixed Plan可將資料寫入、更新效率提升10倍,詳情請參見Fixed Plan加速SQL執行。
資料查詢篇
基於情境建表建議:情境化建表調優指南。
建表必讀:掌握關鍵參數distribution_key、clustering_key、event_time_column及bitmap_index,瞭解文法和索引,設定合理的表結構效能提升N倍,詳情請參見CREATE TABLE。
內部表效能調優:最佳化查詢效能。
MaxCompute加速必讀:通過建立外部表格加速查詢MaxCompute資料。
營運監控篇
活躍Query(排查正在啟動並執行Query、當前是否存有鎖或者被鎖):Query管理。
慢Query(排查失敗、耗時較長的Query):慢Query日誌查看與分析。
讀寫分離、負載隔離:主從執行個體讀寫分離部署(共用儲存)。
實踐案例篇
實踐與案例集:行業典型情境最佳實務與經典使用者案例。