通過本文您可以瞭解即時推理情境以及如何利用淺休眠(原閑置)GPU執行個體構建低延遲、低成本的即時推理服務。
應用情境
即時推理應用的工作負載的特點
在即時推理應用情境中,工作負載具有以下一個或多個特徵。
低延遲
單次請求的處理時效性要求高,RT(Response Time)延遲要求嚴格,90%的長尾延時普遍在百毫秒層級。
主鏈路
普遍位於業務核心鏈路,推理成功率要求高,不接受長時間重試。樣本如下。
開屏廣告推薦/首頁產品推薦:根據使用者的行為喜好,在應用開屏時進行使用者行為的推薦,並即時地展現在使用者終端上。
即時資料流程媒體生產:在互動連麥、直播帶貨、超低延時播放等情境下,音視頻流均需要以極低的延遲在端到端之間進行傳播,AI視頻超分、AI視頻識別的即時性需要保證。
峰波峰穀
業務流量具有明顯的潮汐特徵,普遍與終端使用者使用習慣高度相關。
資源使用率
由於GPU資源規劃普遍根據業務高峰評估,峰穀時存在較大資源浪費,資源使用率普遍低於30%。
Function Compute為即時推理工作負載提供的優勢
淺休眠(原閑置)GPU執行個體
Function Compute平台提供了淺休眠(原閑置)GPU執行個體,如果您希望消除冷啟動延時的影響,滿足即時推理業務低延遲響應的要求,可以通過配置淺休眠(原閑置)GPU執行個體來實現,詳情請參見執行個體類型和規格。使用淺休眠(原閑置)GPU執行個體,將帶來如下優勢:
執行個體快速喚醒:Function Compute平台會根據您的即時負載水平,自動將GPU執行個體進行凍結。凍結的執行個體接受請求前,平台會自動將其喚醒。要注意,喚醒過程會存在2-3秒的延遲。
兼顧服務品質與服務成本:淺休眠(原閑置)GPU執行個體的計費周期不同於按量GPU執行個體,淺休眠(原閑置)GPU執行個體會在執行個體淺休眠(原閑置)與活躍期間以不同的單價進行計費,詳情請參見使用Function Compute即時推理情境的成本如何計算?。總體使用成本,相較於按量GPU執行個體高,相較於長期自建GPU叢集低,降本幅度達50%以上。
針對推理情境最佳化的請求調度機制
Function Compute平台提供內建的智能調度機制,可以做到函數下多個GPU執行個體的負載平衡。您可以通過使用Function Compute平台,藉助平台側調度,將業務的推理請求均勻地分發至後端的GPU執行個體上,以達到綜合提升推理叢集利用率的目的。
淺休眠(原閑置)GPU執行個體
當GPU函數部署完成後,您可以通過啟用淺休眠(原閑置)GPU執行個體提供即時推理應用情境所需的基礎設施能力。Function Compute平台將根據您的工作負載,在請求達到時,對配置的伸縮指標策略進行預留GPU執行個體的HPA,請求將優先分配至預留GPU執行個體進行推理服務,平台完全遮蔽冷啟動,業務保持低延遲響應。
淺休眠(原閑置)GPU執行個體降本優勢
淺休眠(原閑置)GPU執行個體在淺休眠(原閑置)狀態和活躍狀態對應淺休眠(原閑置)GPU使用單價和活躍GPU使用單價,Function Compute會根據執行個體的狀態,自動進行計量統計與計費。
如下圖所示,從執行個體的建立到銷毀,經歷了T0 - T4四個時間視窗,其中T1和T3時間視窗內執行個體活躍,其餘T0、T2、T4執行個體均為淺休眠(原閑置)狀態。則該時間段的總價為(T0、T2、T4 x 淺休眠(原閑置)GPU使用單價)+(T1、T3 x 活躍GPU使用單價)。關於淺休眠(原閑置)GPU使用單價和活躍GPU使用單價,請參見計費概述。
淺休眠(原閑置)GPU執行個體工作原理
Function Compute平台藉助先進的自研技術,實現了GPU執行個體的即時凍結和恢複機制。當GPU執行個體處於非活躍狀態時,Function Compute平台會自動將其轉入凍結狀態,並以淺休眠(原閑置)單價進行計費,以最佳化資源利用效率,同時為客戶降低成本。一旦有新的計算請求,平台迅速喚醒該執行個體,無縫執行所需的推理任務,自動以活躍單價進行計費。
此過程對使用者完全透明,不影響使用體驗。同時,Function Compute確保即便在執行個體凍結的情況下,推理服務的準確性和可靠性不受影響,為使用者提供了一個穩定、經濟的計算環境。
淺休眠(原閑置)GPU執行個體喚醒延遲
由於業務負載的不同,以下列舉典型推理負載的喚醒時間供參考。
推理負載類型 | 淺休眠(原閑置)GPU執行個體喚醒時間(秒) |
OCR/NLP | 0.5 - 1 |
Stable Diffusion | 2 |
LLM | 3 |
由於模型體積各異,存在喚醒延遲差異,請以實際使用為準。
淺休眠(原閑置)GPU執行個體使用約束
CUDA版本
推薦使用CUDA 12.2以及更早的版本。
鏡像許可權
推薦在容器鏡像中以預設的root使用者權限運行。
執行個體登入
淺休眠(原閑置)GPU執行個體中,由於GPU凍結等原因,暫不支援登入執行個體。
執行個體優雅輪轉
Function Compute平台會根據系統負載對淺休眠(原閑置)GPU執行個體進行優雅輪轉。為確保服務品質,建議在函數執行個體中加入模型預熱/預推理生命週期回調功能,以便新執行個體上線後可立即提供推理服務,詳情請參見模型服務預熱。
模型預熱/預推理
淺休眠(原閑置)GPU執行個體中,為保證執行個體的首次喚醒延遲符合預期,建議您在業務代碼中使用
initialize生命週期回調功能來進行模型預熱/預推理,詳情請參見模型服務預熱。預留配置
切換淺休眠(原閑置)模式開關時會使該函數現有的GPU預留執行個體優雅下線,預留執行個體數短暫歸零,直到新的預留執行個體出現。
關閉推理架構內建的Metrics Server
為提升淺休眠(原閑置)GPU的相容性和效能,建議關閉推理架構(如NVIDIA Triton Inference Server、TorchServe等)內建的Metrics Server。
淺休眠(原閑置)GPU執行個體規格
淺休眠(原閑置)GPU執行個體當前要求整卡使用GPU。關於GPU執行個體規格的詳情請參見執行個體規格。
針對推理情境最佳化的請求調度機制
調度原理
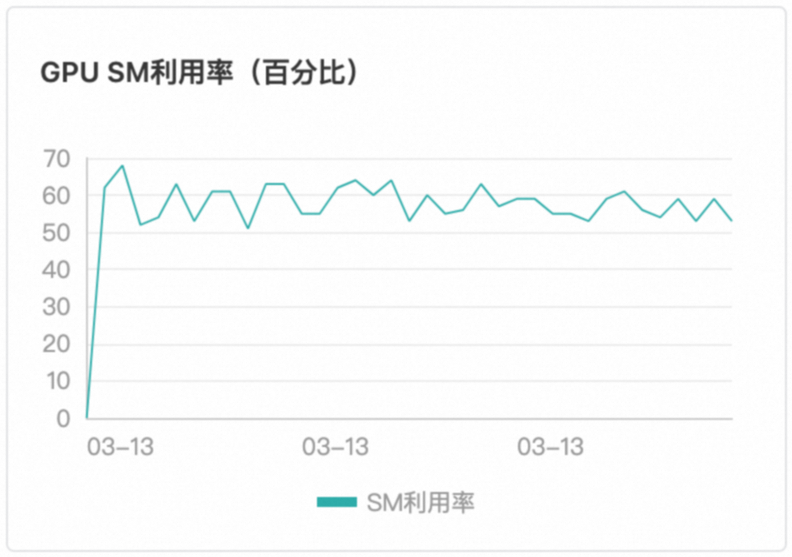
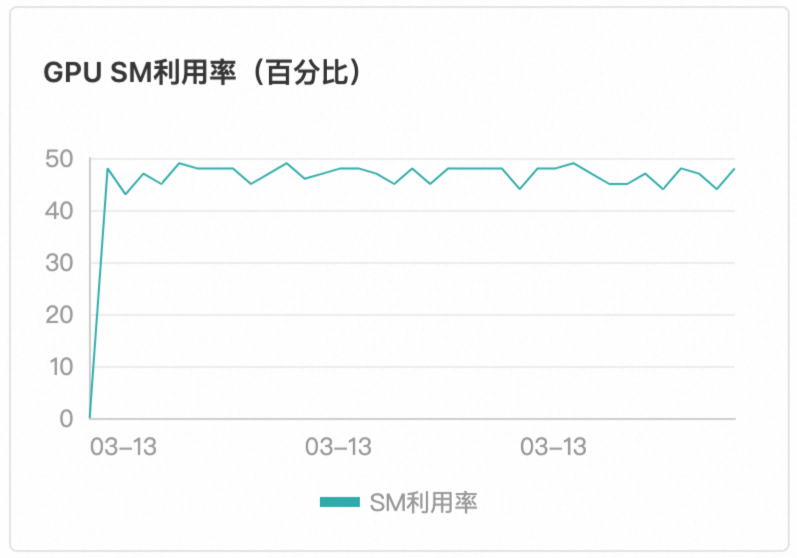
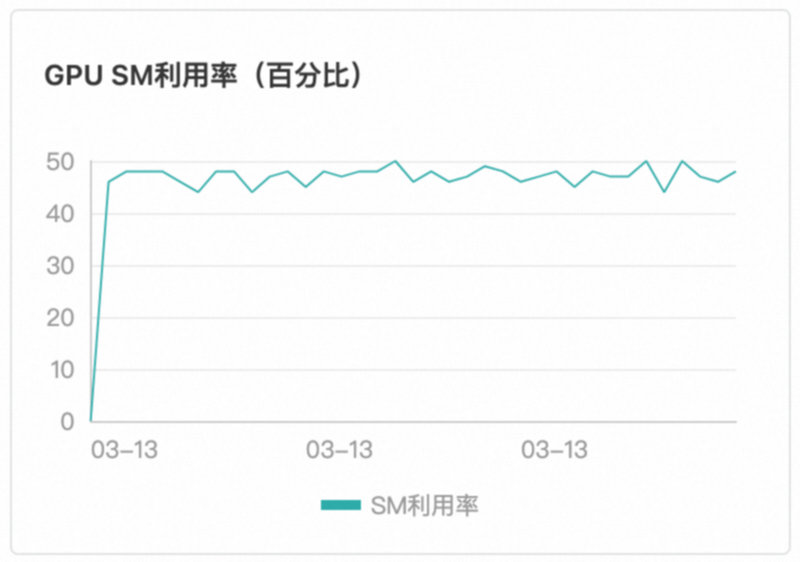
Function Compute平台採用基於請求負載的智能感知調度,這一策略明顯優於傳統的輪詢調度方法。平台能夠即時監測當前GPU執行個體的任務執行狀態,並在檢測到空閑時,立即將新的請求分配至該執行個體。確保了GPU資源的高效利用,無空轉現象、無熱點現象。保證了GPU執行個體負載平衡與GPU算力利用率一致。如下圖所示,本文以T4卡型為例。
調度效果
使用者無需感知調度邏輯,即可藉助Function Compute內建的調度邏輯,在多個GPU執行個體中負載平衡。
執行個體1 | 執行個體2 | 執行個體3 |
|
|
|
容器支援
Function ComputeGPU情境下,當前僅支援以Custom Container(自訂容器運行環境)進行交付。關於Custom Container的使用詳情,請參見自訂鏡像簡介。
Custom Container函數要求在鏡像內攜帶Web Server,以滿足執行不同代碼路徑、通過事件或HTTP觸發函數的需求。適用於AI學習推理等多重路徑請求執行情境。
部署方式
您可以使用多種方式將您的模型部署在Function Compute。
通過Function Compute控制台部署。具體操作,請參見在控制台建立函數。
通過調用SDK部署。更多資訊,請參見API概覽。
通過Serverless devs工具部署。更多資訊,請參見Serverless Devs常用命令。
更多部署樣本,請參見start-fc-gpu。
模型服務預熱
為瞭解決模型上線後初次請求耗時較長的問題,Function Compute為您提供了模型預熱的功能。模型預熱的目的是使模型上線後即可進入正常的服務狀態。
Function Compute推薦您配置執行個體的initialize生命週期回調功能來實現模型預熱,Function Compute會在您的執行個體啟動後自動執行initialize裡的商務邏輯來進行模型服務預熱。更多資訊,請參見函數執行個體生命週期回調。
在您構建的HTTP Server中添加POST方法的
/initialize的調用Path,並將模型預熱的邏輯放在/initialize的Path下。通常可以讓模型服務來執行簡單的推理來實現預熱的效果。下面是Python語言的範例程式碼。
def prewarm_inference(): res = model.inference() @app.route('/initialize', methods=['POST']) def initialize(): request_id = request.headers.get("x-fc-request-id", "") print("FC Initialize Start RequestId: " + request_id) # Prewarm model and perform naive inference task. prewarm_inference() print("FC Initialize End RequestId: " + request_id) return "Function is initialized, request_id: " + request_id + "\n"在函數詳情頁面,選擇,然後單擊編輯,配置執行個體生命週期回調資訊。
配置即時推理的Auto Scaling
通過Serverless Devs工具配置GPUAuto Scaling
前提條件
在GPU執行個體所在地區,完成以下操作:
建立Container Registry的企業版執行個體或個人版執行個體,推薦您建立企業版執行個體。具體操作步驟,請參見使用企業版執行個體推送和拉取鏡像。
建立命名空間鏡像倉庫。具體操作步驟,請參見使用企業版執行個體構建鏡像和使用企業版執行個體構建鏡像。
1.部署函數
執行以下命令,複製工程。
git clone https://github.com/devsapp/start-fc-gpu.git執行以下命令,進入專案目錄。
cd /root/start-fc-gpu/fc-http-gpu-inference-paddlehub-nlp-porn-detection-lstm/src/專案結構如下所示。
. ├── hook │ └── index.js └── src ├── code │ ├── Dockerfile │ ├── app.py │ ├── hub_home │ │ ├── conf │ │ ├── modules │ │ └── tmp │ └── test │ └── client.py └── s.yaml執行以下命令,通過Docker構建鏡像,並向您的鏡像倉庫進行推送。
export IMAGE_NAME="registry.cn-shanghai.aliyuncs.com/fc-gpu-demo/paddle-porn-detection:v1" # sudo docker build -f ./code/Dockerfile -t $IMAGE_NAME . # sudo docker push $IMAGE_NAME重要由於PaddlePaddle架構自身體積較大,首次構建鏡像耗時較長,約1個小時,因此,此處為您提供一個VPC地址的公用鏡像供您直接使用。使用公用鏡像時,無需執行上述docker build和docker push命令。
編輯s.yaml檔案。
edition: 3.0.0 name: container-demo access: default vars: region: cn-shanghai resources: gpu-best-practive: component: fc3 props: region: ${vars.region} description: This is the demo function deployment handler: not-used timeout: 1200 memorySize: 8192 cpu: 2 gpuMemorySize: 8192 diskSize: 512 instanceConcurrency: 1 runtime: custom-container environmentVariables: FCGPU_RUNTIME_SHMSIZE: '8589934592' customContainerConfig: image: >- registry.cn-shanghai.aliyuncs.com/serverless_devs/gpu-console-supervising:paddle-porn-detection port: 9000 internetAccess: true logConfig: enableRequestMetrics: true enableInstanceMetrics: true logBeginRule: DefaultRegex project: z**** logstore: log**** functionName: gpu-porn-detection gpuConfig: gpuMemorySize: 8192 gpuType: fc.gpu.tesla.1 triggers: - triggerName: httpTrigger triggerType: http triggerConfig: authType: anonymous methods: - GET - POST執行以下命令,部署函數。
sudo s deploy --skip-push true -t s.yaml執行成功後,在執行輸出中返回一個URL地址,格式如
https://gpu-poretection-****.cn-shanghai.fcapp.run,複製此地址用於後續測試函數。
2.測試函數並查看監控結果
執行Curl命令調用函數,格式如下,其中網域名稱為上一步擷取的URL。
curl https://gpu-poretection-gpu-****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"返回以下結果,表示測試通過。
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%登入Function Compute控制台,左側導覽列選擇函數,選擇地區,找到目標函數,然後在函數詳情頁,選擇,查看GPU相關指標的變化。
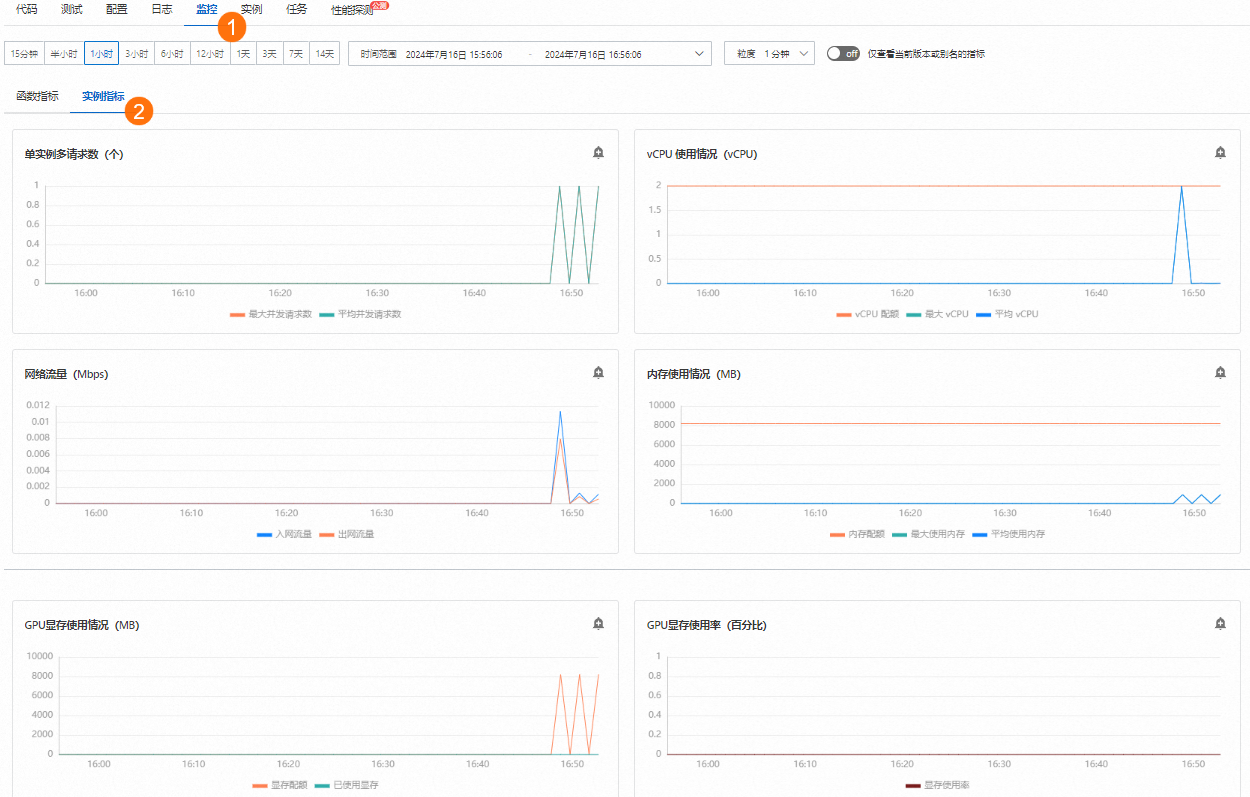
3.配置彈性預留策略
在s.yaml檔案所在目錄下,建立彈性配置的模板provision.json。
樣本如下。該模板使用了執行個體並發度作為追蹤指標,最小執行個體數為2,最大執行個體數為30。
{ "targetTrackingPolicies": [ { "name": "scaling-policy-demo", "startTime": "2024-07-01T16:00:00.000Z", "endTime": "2024-07-30T16:00:00.000Z", "metricType": "ProvisionedConcurrencyUtilization", "metricTarget": 0.3, "minCapacity": 2, "maxCapacity": 30 } ] }執行以下命令,進行彈性策略的部署。
sudo s provision put --target 1 --targetTrackingPolicies ./provision.json --qualifier LATEST -t s.yaml -a {access}執行
sudo s provision list進行驗證,可以看到如下輸出。其中target和current的數值相等,表示預留執行個體正確拉起,彈性規則部署正確。[2023-05-10 14:49:03] [INFO] [FC] - Getting list provision: gpu-best-practive-service gpu-best-practive: - serviceName: gpu-best-practive-service qualifier: LATEST functionName: gpu-porn-detection resource: 143199913651****#gpu-best-practive-service#LATEST#gpu-porn-detection target: 1 current: 1 scheduledActions: null targetTrackingPolicies: - name: scaling-policy-demo startTime: 2024-07-01T16:00:00.000Z endTime: 2024-07-30T16:00:00.000Z metricType: ProvisionedConcurrencyUtilization metricTarget: 0.3 minCapacity: 2 maxCapacity: 30 currentError: alwaysAllocateCPU: true在預留執行個體拉起成功後,您的模型已成功部署並準備好提供服務。
釋放函數預留執行個體。
執行以下命令關閉彈性規則,將預留執行個體配置為0。
sudo s provision put --target 0 --qualifier LATEST -t s.yaml -a {access}執行以下命令確認當前函數的Auto Scaling策略已被關閉。
s provision list -a {access}返回以下執行結果,表示Auto Scaling策略已成功關閉。
[2023-05-10 14:54:46] [INFO] [FC] - Getting list provision: gpu-best-practive-service End of method: provision
通過控制台配置GPUAuto Scaling
前提條件
已建立GPU函數。具體操作,請參見建立自訂鏡像函數。
操作步驟
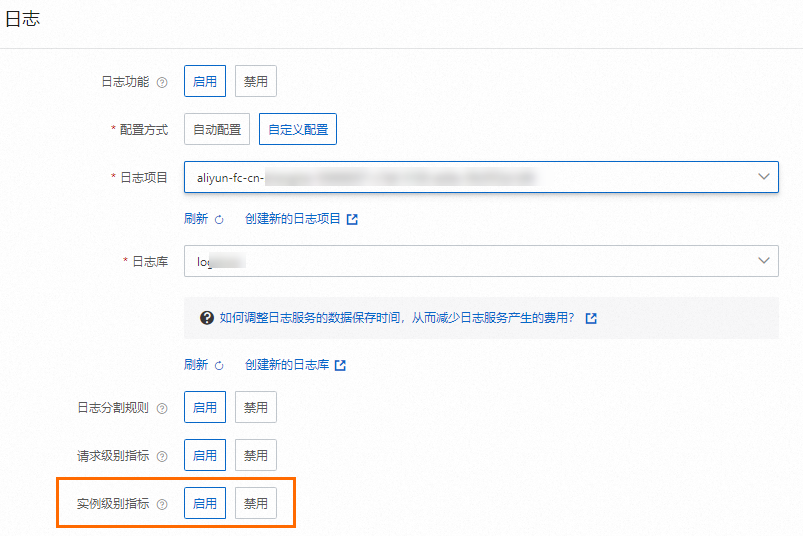
登入Function Compute控制台,左側導覽列選擇函數,選擇地區,找到目標函數,開啟目標函數的執行個體層級指標。
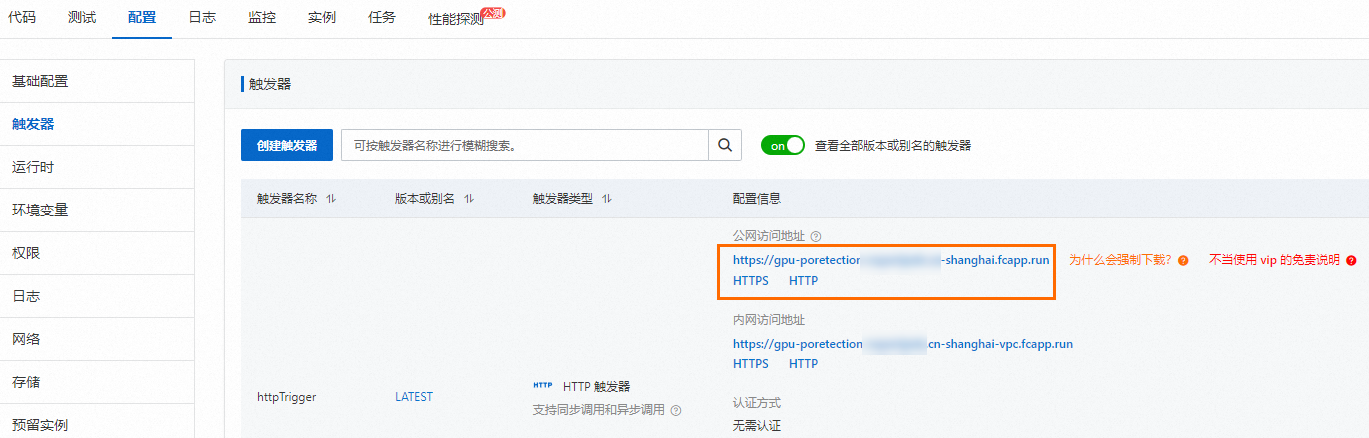
在函數詳情頁面,選擇,擷取HTTP觸發器的URL用於後續測試函數。
執行Curl命令測試函數,然後在函數詳情頁面,選擇,查看GPU相關指標的變化。
curl https://gpu-poretection****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"在函數詳情頁面,選擇,然後單擊建立預留執行個體數策略開始配置彈性預留策略。
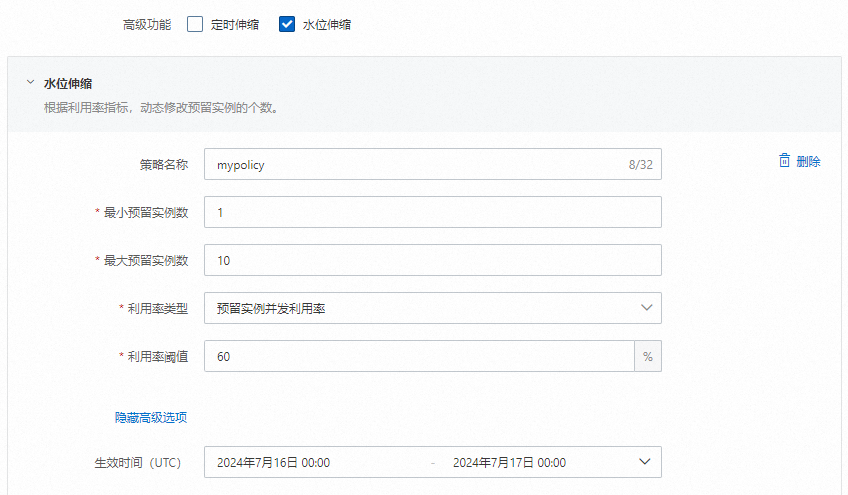
設定完成後,您可以在目標函數的詳情頁,選擇,查看函數預留執行個體數的變化。
後續如果沒有使用預留模式GPU執行個體的需求,請及時刪除添加的預留執行個體。
常見問題
使用Function Compute即時推理情境的成本如何計算?
關於Function Compute的計費詳情,請參見計費概述。預留模式區別於按量模式,請注意您的賬單詳情。
為什麼我配置了Auto Scaling策略,還是可以看到效能毛刺?
可以考慮使用更為激進的Auto Scaling策略,提前彈出節點來規避突發請求帶來的效能擠兌。
為什麼我所追蹤的指標已經上漲超過所配置的彈性策略水位,但是沒有看到執行個體數增長?
Function Compute統計的指標是分鐘層級,水位需要上漲並維持一段時間後,才會觸發擴容機制。