配置Kafka JSON Catalog後,您可以在Realtime ComputeFlink版作業開發中直接存取Kafka叢集中格式為JSON的Topic,無需再定義Schema。本文為您介紹如何建立、查看及刪除Kafka JSON Catalog。
背景資訊
Kafka JSON Catalog通過自動解析JSON格式的訊息來推導Topic的Schema,您無需在Flink SQL中聲明Kafka表的Schema便可以擷取訊息的具體欄位資訊。Kafka JSON Catalog具有以下功能特點:
Kafka JSON Catalog的表名對應Kafka Topic名,無需再通過DDL語句手動註冊Kafka表,提升開發效率和正確性。
Kafka JSON Catalog提供的表可以直接作為Flink SQL作業中的源表使用。
Kafka JSON Catalog可以配合CREATE TABLE AS(CTAS)語句完成Schema變更的資料同步。
本文將從以下方面為您介紹如何管理Kafka JSON Catalog:
使用限制
Kafka JSON Catalog僅支援訊息格式為JSON的Topic,暫不支援其他格式。
僅Flink計算引擎VVR 6.0.2及以上版本支援配置Kafka JSON Catalog。
說明如果您使用的是VVR 4.x版本,建議升級作業至VVR 6.0.2及以上版本後使用Kafka JSON Catalog。
不支援通過DDL語句修改已有的Kafka JSON Catalog。
僅支援查詢資料表,不支援建立、修改和刪除資料庫和表。
說明CDAS或CTAS的Kafka JSON Catalog情境下,可以自動建立Topic。
Kafka JSON Catalog不支援讀取或寫入開啟了SSL或SASL認證的Kafka。
Kafka JSON Catalog提供的表可以直接作為Flink SQL作業中的源表,不支援作為結果表和Lookup維表。
由於雲訊息佇列 Kafka 版暫不支援採用開源版Kafka相同的介面刪除Group,建立Kafka JSON Catalog時需要指定aliyun.kafka.instanceId、aliyun.kafka.accessKeyId、aliyun.kafka.accessKeySecret、aliyun.kafka.endpoint和aliyun.kafka.regionId才能自動刪除Group ID,詳情請參見開源對比。
注意事項
Kafka JSON Catalog通過取樣資料解析產生表的Schema,對於資料格式不一致的Topic,預設保留全部列返回最寬的Schema。如果Topic的資料格式出現變化,Kafka JSON Catalog在不同時間得到的表的Schema會出現不一致。當在作業重啟前後推斷的Schema不同時,可能出現作業運行問題。
例如,Flink SQL作業中引用了Kafka JSON Catalog中的一張表,運行一段時間後從Savepoint重啟,可能會重新擷取到與上一次運行不一樣的Schema。SQL作業的執行計畫會用之前的Schema產生的版本,從而導致下遊比如過濾條件、欄位取值不匹配。因此建議在Flink SQL 作業中使用Create Temporary Table的方式建立Kakfka表,通過固定的Schema使用。
建立Kafka JSON Catalog
在資料查詢文本編輯地區,輸入以下配置Kafka JSON Catalog的命令。
自建Kafka叢集或EMR Kafka叢集
CREATE CATALOG <YourCatalogName> WITH( 'type'='kafka', 'properties.bootstrap.servers'='<brokers>', 'format'='json', 'default-database'='<dbName>', 'key.fields-prefix'='<keyPrefix>', 'value.fields-prefix'='<valuePrefix>', 'timestamp-format.standard'='<timestampFormat>', 'infer-schema.flatten-nested-columns.enable'='<flattenNestedColumns>', 'infer-schema.primitive-as-string'='<primitiveAsString>', 'infer-schema.parse-key-error.field-name'='<parseKeyErrorFieldName>', 'infer-schema.compacted-topic-as-upsert-table'='true', 'max.fetch.records'='100' );CREATE CATALOG <YourCatalogName> WITH( 'type'='kafka', 'properties.bootstrap.servers'='<brokers>', 'format'='json', 'default-database'='<dbName>', 'key.fields-prefix'='<keyPrefix>', 'value.fields-prefix'='<valuePrefix>', 'timestamp-format.standard'='<timestampFormat>', 'infer-schema.flatten-nested-columns.enable'='<flattenNestedColumns>', 'infer-schema.primitive-as-string'='<primitiveAsString>', 'infer-schema.parse-key-error.field-name'='<parseKeyErrorFieldName>', 'infer-schema.compacted-topic-as-upsert-table'='true', 'max.fetch.records'='100', 'aliyun.kafka.accessKeyId'='<aliyunAccessKeyId>', 'aliyun.kafka.accessKeySecret'='<aliyunAccessKeySecret>', 'aliyun.kafka.instanceId'='<aliyunKafkaInstanceId>', 'aliyun.kafka.endpoint'='<aliyunKafkaEndpoint>', 'aliyun.kafka.regionId'='<aliyunKafkaRegionId>' );
參數
類型
說明
是否必填
備忘
YourCatalogName
String
Kafka JSON Catalog名稱。
是
請填寫為自訂的英文名。
重要參數替換為您的Catalog名稱後,需要去掉角括弧(<>),否則語法檢查會報錯。
type
String
Catalog類型。
是
固定值為kafka。
properties.bootstrap.servers
String
Kafka Broker地址。
是
格式為
host1:port1,host2:port2,host3:port3。以英文逗號(,)分割。
format
String
Kafka訊息格式。
是
目前只支援配置為JSON。Flink會解析JSON格式的Kafka訊息,來擷取Schema。
default-database
String
Kafka叢集名稱。
否
預設值為kafka。Catalog要求三層結構定位一張表,即catalog_name.db_name.table_name。此處是配置預設的db_name,由於Kafka沒有Database的概念,您可以在此處使用任一字元串指代Kafka叢集作為database的定義。
key.fields-prefix
String
自訂添加到訊息鍵(Key)解析出欄位名稱的首碼,來避免Kafka訊息鍵解析後的命名衝突問題。
否
預設值為key_。例如,如果您的key欄位名為a,則系統預設解析key後的欄位名稱為key_a。
說明key.fields-prefix的配置值不可以是value.fields-prefix的配置值的首碼。例如value.fields-prefix配置為test1_value_,則key.fields-prefix不可以配置為test1_。
value.fields-prefix
String
自訂添加到訊息體(Value)解析出欄位名稱的首碼,來避免Kafka訊息體解析後的命名衝突問題。
否
預設值為value_。例如,如果您的value欄位名為b,則系統預設解析value後的欄位名稱為value_b。
說明value.fields-prefix的配置值不可以是key.fields-prefix的配置值的首碼。例如key.fields-prefix配置為test2_value_,則value.fields-prefix不可以配置為test2_。
timestamp-format.standard
String
解析JSON格式訊息中Timestamp類型欄位的格式,首先嘗試通過您配置的格式去解析,解析失敗後再自動嘗試使用其他格式解析。
否
可配置的值有以下兩種:
SQL(預設值)
ISO-8601
infer-schema.flatten-nested-columns.enable
Boolean
解析JSON格式訊息體(Value)時,是否遞迴式地展開JSON中的嵌套列。
否
參數取值如下:
true:遞迴式展開。
對於被展開的列,Flink使用索引該值的路徑作為名字。例如,對於
{"nested": {"col": true}}中的列col,它展開後的名字為nested.col。說明設定為true時,建議和CREATE TABLE AS(CTAS)語句配合使用,目前暫不支援其它DML語句自動延伸嵌套列。
false(預設值):將巢狀型別當作String處理。
infer-schema.primitive-as-string
Boolean
解析JSON格式訊息體(Value)時,是否推導所有基本類型為String類型。
否
參數取值如下:
true:推導所有基本類型為String。
false(預設值):按照基本規則進行推導。
infer-schema.parse-key-error.field-name
String
解析JSON格式訊息鍵(Key)時,如果訊息鍵不為空白,且解析失敗,會添加key.fields-prefix首碼拼接此配置項的值為列名,類型為VARBINARY的欄位到表Schema,表示訊息鍵部分的資料。
否
預設值為col。如:訊息體解析出的欄位為value_name,訊息鍵不為空白但解析失敗,則預設返回的Schema包含兩個欄位:key_col,value_name。
infer-schema.compacted-topic-as-upsert-table
Boolean
當Kafka topic的日誌清理策略為compact且訊息鍵(Key)不為空白時,是否作為Upsert Kafka表使用。
否
預設值為true。使用CTAS或CDAS文法同步資料到阿里雲訊息佇列Kafka版時需要配置為true。
說明僅Realtime Compute引擎VVR 6.0.2及以上版本支援該參數。
max.fetch.records
Int
解析JSON格式訊息時,最多嘗試消費的訊息數量。
否
預設值為100。
aliyun.kafka.accessKeyId
String
阿里雲帳號AccessKey ID,詳情請參見建立AccessKey。
否
使用CTAS或CDAS文法同步資料到阿里雲訊息佇列Kafka版時需要配置。
說明僅Realtime Compute引擎VVR 6.0.2及以上版本支援該參數。
aliyun.kafka.accessKeySecret
String
阿里雲帳號AccessKey Secret,詳情請參見建立AccessKey。
否
使用CTAS或CDAS文法同步資料到阿里雲訊息佇列Kafka版時需要配置。
說明僅Realtime Compute引擎VVR 6.0.2及以上版本支援該參數。
aliyun.kafka.instanceId
String
阿里雲Kafka訊息佇列執行個體ID,可在訊息佇列Kafka執行個體詳情介面查看。
否
使用CTAS或CDAS文法同步資料到阿里雲訊息佇列Kafka版時需要配置。
說明僅Realtime Compute引擎VVR 6.0.2及以上版本支援該參數。
aliyun.kafka.endpoint
String
阿里雲Kafka API服務接入地址,詳情請參見服務存取點。
否
使用CTAS或CDAS文法同步資料到阿里雲訊息佇列Kafka版時需要配置。
說明僅Realtime Compute引擎VVR 6.0.2及以上版本支援該參數。
aliyun.kafka.regionId
String
Topic所在執行個體的地區ID,詳情請參見服務存取點。
否
使用CTAS或CDAS文法同步資料到阿里雲訊息佇列Kafka版時需要配置。
說明僅Realtime Compute引擎VVR 6.0.2及以上版本支援該參數。
選中建立Catalog的代碼後,單擊左側程式碼數上的運行。

在左側中繼資料地區,查看建立的Catalog。
查看Kafka JSON Catalog
在資料查詢文本編輯地區,輸入以下命令。
DESCRIBE `${catalog_name}`.`${db_name}`.`${topic_name}`;參數
說明
${catalog_name}
Kafka JSON Catalog名稱。
${db_name}
Kafka叢集名稱。
${topic_name}
Kafka Topic名稱。
選中查看Catalog的代碼後,單擊左側程式碼數上的運行。
運行成功後,可以在運行結果中查看錶的具體資訊。

使用Kafka JSON Catalog
作為源表,從Kafka Topic中讀取資料。
INSERT INTO ${other_sink_table} SELECT... FROM `${kafka_catalog}`.`${db_name}`.`${topic_name}`/*+OPTIONS('scan.startup.mode'='earliest-offset')*/;說明如果Kafka JSON Catalog的表使用時需要指定其他WITH參數,則建議使用SQL Hints的方式來添加其他參數。例如,如上SQL使用了SQL Hints指定從最早的資料開始消費。其他參數詳情請參見訊息佇列Kafka源表和訊息佇列Kafka結果表。
作為源表,使用CREATE TABLE AS(CTAS)語句將Kafka Topic中的資料同步至目標表中。
單表同步,即時同步資料。
CREATE TABLE IF NOT EXISTS `${target_table_name}` WITH(...) AS TABLE `${kafka_catalog}`.`${db_name}`.`${topic_name}` /*+OPTIONS('scan.startup.mode'='earliest-offset')*/;在一個作業中同步多張表。
BEGIN STATEMENT SET; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table0` AS TABLE `kafka-catalog`.`kafka`.`topic0` /*+ OPTIONS('scan.startup.mode'='earliest-offset') */; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table1` AS TABLE `kafka-catalog`.`kafka`.`topic1` /*+ OPTIONS('scan.startup.mode'='earliest-offset') */; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table2` AS TABLE `kafka-catalog`.`kafka`.`topic2` /*+ OPTIONS('scan.startup.mode'='earliest-offset') */; END;結合Kafka JSON Catalog,您可以在同一個任務中同步多張Kafka表。但需要滿足以下條件:
所有Kafka表均未配置topic-pattern參數。
每張表關於Kafka的配置必須完全相同,即properties.*配置的屬性完全相同,包括properties.bootstrap.servers和properties.group.id。
每張表的 scan.startup.mode配置必須完全相同,且只能配置為group-offsets、latest-offset或earliest-offset,不能配置為其他值。
例如,下圖中上面兩張表滿足條件,下面兩張表違反了以上三個條件。

完整的端到端的Kafka JSON Catalog使用樣本詳情請參見日誌即時入倉快速入門。
刪除Kafka JSON Catalog
刪除Kafka JSON Catalog不會影響已啟動並執行作業,但會導致使用該Catalog下表的作業,在上線或重啟時報無法找到該表的錯誤,請您謹慎操作。
在資料查詢文本編輯地區,輸入以下命令。
DROP CATALOG ${catalog_name};其中${catalog_name}為您要刪除的目標Kafka JSON Catalog名稱。
選中刪除Catalog的命令,滑鼠右鍵選擇運行。
在左側中繼資料地區,查看目標Catalog是否已刪除。
從Kafka JSON Catalog擷取的表資訊詳解
為了方便使用Kafka JSON Catalog擷取的表,Kafka JSON Catalog會在推導的表上添加預設的配置參數、中繼資料和主鍵資訊。Kafka JSON Catalog擷取的表的詳細資料如下:
Kafka表的Schema推導
Kafka JSON Catalog在解析JSON格式訊息擷取Topic的Schema時,Catalog會嘗試消費最多max.fetch.records條訊息,解析每條資料的Schema,解析規則與Kafka作為CTAS資料來源時的基本規則相同,再將這些Schema合并作為最終的Schema。
重要Kafka JSON Catalog在推導Schema時,會建立消費組消費該Topic的資料,消費組名稱使用首碼表明是Catalog建立的。
對於阿里雲訊息佇列Kafka版,建議在6.0.7及以上的版本使用Kafka JSON Catalog。6.0.7版本以前不會自動刪除消費組,將導致使用者收到消費組資料堆積警示。
Schema主要包含以下幾個部分:
推導的物理列(Physical Columns)
Kafka JSON Catalog會從Kafka訊息的訊息鍵(Key)和訊息體(Value)推匯出訊息的物理列,列名添加對應的首碼。
如果訊息鍵不為空白但解析失敗,會返回列名為key.fields-prefix首碼和infer-schema.parse-key-error.field-name參數配置值的拼接結果,類型為VARBINARY的列。
當拉取到一組Kafka訊息後,Catalog會逐條解析Kafka訊息並按以下規則合并解析出的物理列,從而作為整個Topic的Schema。合并規則如下:
如果解析出的物理列中包含結果Schema中沒有的欄位,則Kafka JSON Catalog會自動將這些欄位加入到結果Schema。
如果兩者出現了同名列,則按照以下情境進行處理:
當類型相同且精度不同時,會取兩者中較大的精度的類型。
當類型不同時,會按照如下圖的樹型結構找到最小父節點,作為該同名列的類型。但當Decimal和Float類型合并時,為了保留精度會合并為Double類型。
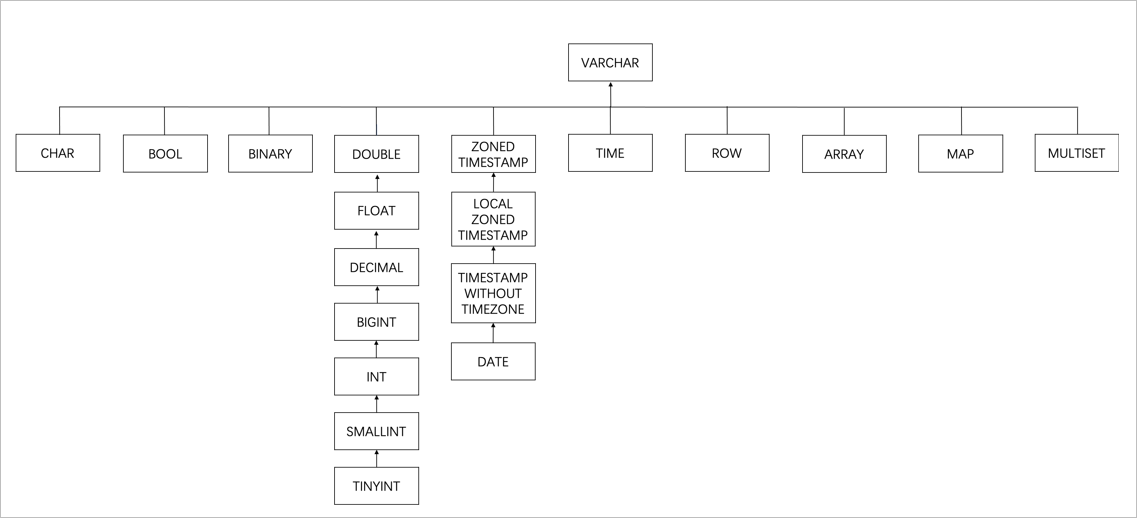
例如,對於下麵包含三條資料的一個Kafka topic,Kafka JSON Catalog得到的Schema如下圖所示。

預設添加的中繼資料列(Metadata Column)
Kafka JSON Catalog會預設添加partition,offset和timestamp三個有用的中繼資料列。詳情如下表所示。
中繼資料名
列名稱
類型
說明
partition
partition
INT NOT NULL
分區值。
offset
offset
BIGINT NOT NULL
位移量。
timestamp
timestamp
TIMESTAMP_LTZ(3) NOT NULL
訊息時間戳記。
預設添加的主鍵約束
從Kafka JSON Catalog擷取的表,在作為源表消費時,會預設把中繼資料列partition和offset列作為主鍵,確保資料不重複。
說明如果Kafka JSON Catalog推匯出來的表Schema不符合預期,您可以通過CREATE TEMPORARY TABLE ... LIKE文法聲明暫存資料表來指定期望的表Schema。比如JSON資料中存在欄位ts,欄位格式是'2023-01-01 12:00:01',Kafka JSON Catalog會將ts欄位自動推導成TIMESTAMP類型,如果希望ts欄位作為STRING類型使用,可以通過CREATE TEMPORARY TABLE ... LIKE文法聲明該表進行使用。如下所示,由於預設配置中訊息Value部分欄位添加了value_首碼,此處欄位名為value_ts。
CREATE TEMPORARY TABLE tempTable ( value_name STRING, value_ts STRING ) LIKE `kafkaJsonCatalog`.`kafka`.`testTopic`;預設添加的表參數
參數
說明
備忘
connector
Connector類型。
固定值為kafka或upsert-kafka。
topic
對應的Topic名稱。
聲明的表名。
properties.bootstrap.servers
Kafka Broker地址。
對應Catalog的properties.bootstrap.servers參數配置值。
value.format
Flink Kafka Connector在序列化或還原序列化Kafka的訊息體(Value)時使用的格式。
固定值為json。
value.fields-prefix
為所有Kafka訊息體(Value)指定自訂首碼,以避免與訊息鍵(Key)或Metadata欄位重名。
對應Catalog的value.fields-prefix參數配置值。
value.json.infer-schema.flatten-nested-columns.enable
Kafka訊息體(Value)是否遞迴式地展開JSON中的嵌套列。
對應Catalog的infer-schema.flatten-nested-columns.enable參數配置值。
value.json.infer-schema.primitive-as-string
Kafka訊息體(Value)是否推導所有基本類型為String類型。
對應Catalog的infer-schema.primitive-as-string參數配置值。
value.fields-include
定義訊息體在處理訊息鍵欄位時的策略。
固定值為EXCEPT_KEY。表示訊息體中不包含訊息鍵的欄位。
訊息鍵(Key)不為空白時配置該參數,訊息鍵(Key)為空白時不配置該參數。
key.format
Flink Kafka Connector在序列化/還原序列化Kafka的訊息鍵(Key)時使用的格式。
固定值為json或raw。
訊息鍵(Key)不為空白時配置該參數,訊息鍵(Key)為空白時不配置該參數。
當訊息鍵(Key)不為空白但解析失敗時,配置為raw;解析成功時,配置為json。
key.fields-prefix
為所有Kafka訊息鍵(Key)指定自訂首碼,以避免與訊息體(Value)格式欄位重名。
對應Catalog的key.fields-prefix參數配置值。
訊息鍵(Key)不為空白時配置該參數,訊息鍵(Key)為空白時不配置該參數。
key.fields
Kafka訊息鍵(Key)解析出來的資料存放的欄位。
自動填寫解析出來的Key欄位列表。
訊息鍵(Key)不為空白且不是Upsert Kafka表時配置該參數,否則不配置該參數。