本文為您介紹如何建立物化表,以及進行歷史資料回刷、修改新鮮度、查看物化表血緣關係。
使用限制
僅Realtime Compute引擎VVR 8.0.10及以上版本支援。
目前僅支援中繼資料存放區類型為Filesystem或DLF的Paimon Catalog,自訂的Paimon Catalog不支援建立物化表。
需要具備開發及部署作業許可權,詳情請參見開發控制台授權。
暫不支援引用臨時對象,如temporary table/temporary function/temporary view。
建立物化表
文法結構
CREATE MATERIALIZED TABLE [catalog_name.][db_name.]table_name
-- 主鍵約束
[([CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED)]
[COMMENT table_comment]
-- 分區鍵
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
-- With選項
[WITH (key1=val1, key2=val2, ...)]
-- 資料新鮮度
FRESHNESS = INTERVAL '<num>' { SECOND | MINUTE | HOUR | DAY }
-- 重新整理模式
[REFRESH_MODE = { CONTINUOUS | FULL }]
AS <select_statement>參數說明
參數 | 是否必填 | 說明 |
FRESHNESS | 是 | 用於指定物化表的資料新鮮度。定義了物化表資料相對於源表更新的最大延遲時間。 說明
|
AS <select_statement> | 是 | 該子句用於定義填充物化表資料的查詢。上遊表可以是物化表、表或視圖。SELECT語句支援所有Flink SQL查詢。 |
PRIMARY KEY | 否 | 定義了一組可選的列,用於唯一標識表中的每一行。被識別欄位列必須非空。 |
PARTITIONED BY | 否 | 定義了一組可選的列,用於對物化表進行分區。 |
WITH Options | 否 | 可以定義建立物化表所需的表屬性和分區欄位的時間格式參數。 例如,分區欄位的時間格式參數 |
REFRESH_MODE | 否 | 用於指定物化表的重新整理模式。指定的重新整理模式比架構根據新鮮度自動推導的模式具有更高的優先順序,以滿足特定情境的需求。
|
操作步驟
單擊目標工作空間操作列下的控制台。
在左側導覽列選擇資料管理,單擊目標Paimon Catalog。
單擊目標資料庫後,單擊建立物化表。
假設有一張基礎資料表orders(主鍵order_id,類目名稱order_name,日期ds)。下面將展示基於該表建立物化表:
基於orders表構建物化表mt_order,查詢所有欄位結果為表欄位,資料新鮮度為5秒。
CREATE MATERIALIZED TABLE mt_order FRESHNESS = INTERVAL '5' SECOND AS SELECT * FROM `paimon`.`db`.`orders` ;基於物化表mt_order建立物化表mt_id,查詢order_id、ds為表欄位,且設定order_id為主鍵,ds為分區欄位,資料新鮮度為30分鐘。
CREATE MATERIALIZED TABLE mt_id ( PRIMARY KEY (order_id) NOT ENFORCED ) PARTITIONED BY(ds) FRESHNESS = INTERVAL '30' MINUTE AS SELECT order_id,ds FROM mt_order ;建立物化表mt_ds,基礎資料表為物化表mt_order,為
ds分區欄位列指定了date-formatter(時間格式)。每次調度時,調度時間減去新鮮度將轉換為相應的ds分區值。例如,設定資料新鮮度為1小時的情況下,在2024-01-01 00:00:00的調度時間,則計算出來的ds=20231231,只有分區ds = '20231231'的資料會被重新整理。如果定時調度時間為2024-01-01 01:00:00,計算出來的ds=20240101,則分區ds = '20240101'的資料會被重新整理。CREATE MATERIALIZED TABLE mt_ds PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR AS SELECT order_id,order_name,ds FROM mt_order ;說明partition.fields.#.date-formatter中的'#'欄位必須是有效字串類型分區欄位。partition.fields.#.date-formatter指定物化表的時間分區格式化,其中'#'為字串類型的分區欄位名稱,可以提示系統在重新整理資料時,重新整理哪個分區的資料。
開始/停止更新物化表。
單擊對應Catalog下的目標物化表。
單擊右側開始更新/停止更新。
說明在停止更新時,如果最近一次更新進行中,將在此次資料更新完成後停止。
查詢物化表作業詳情。
在表結構詳情頁簽中,查看基本資料,單擊資料更新作業或工作流程對應的作業ID,即可查看詳情。
修改物化表查詢語句
使用限制
僅Realtime Compute引擎VVR 11.1及以上版本支援建立的物化表修改Query。
修改Query時僅支援追加列和修改計算邏輯,不支援調整現有列的順序或修改已有列的定義。
操作類型
是否支援
說明
追加新列
支援
可保持列順序的同時,在schema後添加新列。
修改現有列的計算邏輯(不改變列名和類型)
支援
例如修改計算邏輯,但列名和資料類型需保持一致。
修改現有列的順序
不支援
列順序固定,需刪除並重新建立物化表。
修改現有列的名稱或資料類型
不支援
需刪除並重新建立物化表。
修改樣本
單擊編輯表,修改對應的Query。樣本參考如下:
ALTER MATERIALIZED TABLE `paimon`.`default`.`mt-orders` AS SELECT *, price * quantity AS total_price FROM orders WHERE price * quantity > 1000 ;點擊預覽,查看前後對比。
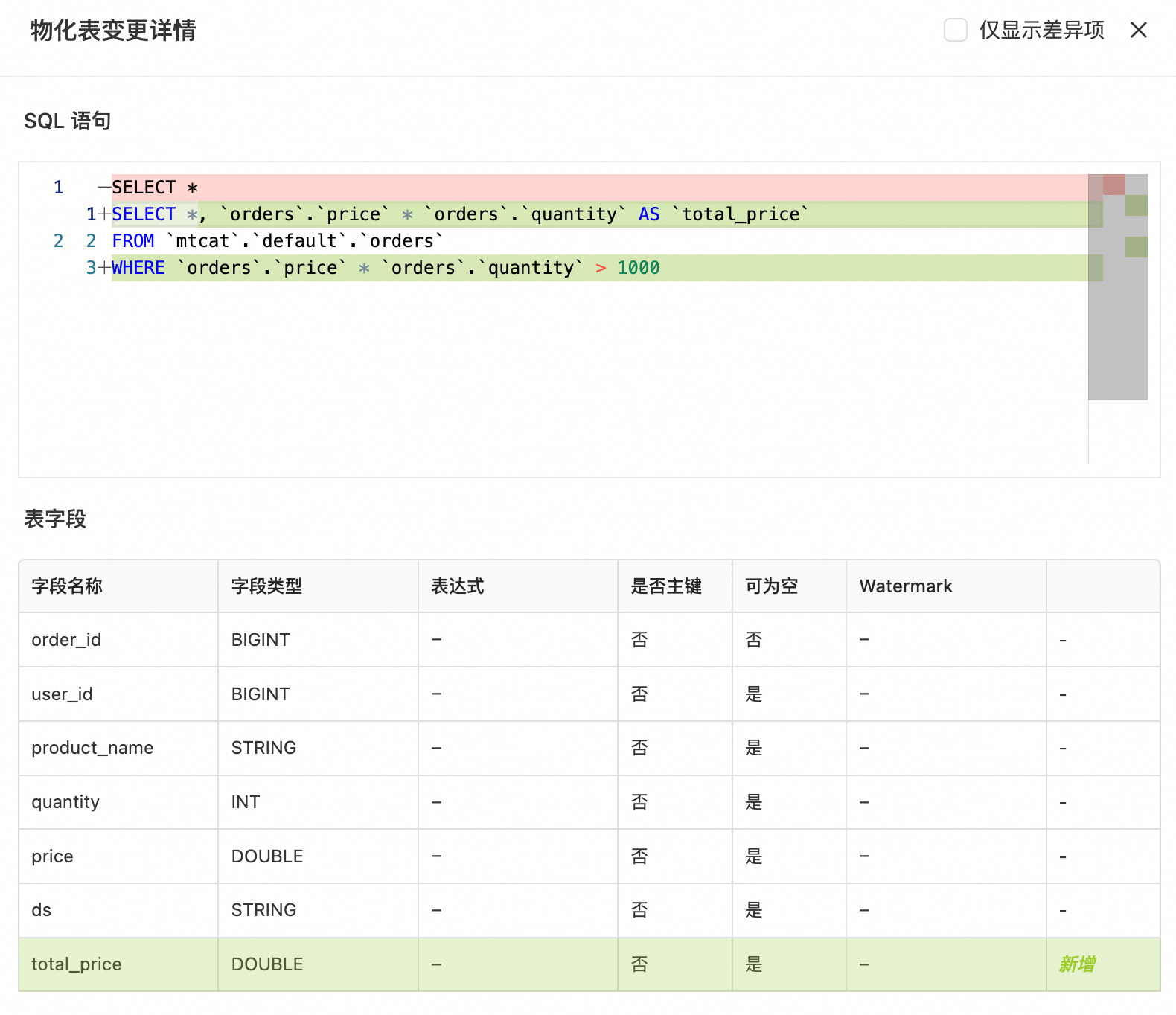
單擊確認後,可在表結構詳情看到新增的對應列和查詢邏輯。
新增欄位通常不會影響下遊,但如果下遊使用動態解析(如 SELECT * 或自動對應欄位)同步上遊物化表,可能導致同步任務失敗或出現資料格式不匹配的報錯。建議盡量避免動態解析,優先使用固定欄位,並在上遊變更時及時同步更新下遊表結構。
物化表累加式更新
使用限制
僅Realtime Compute引擎VVR 8.0.11及以上版本支援。
物化表的更新模式
物化表提供三種更新模式:流更新模式、全量批更新模式、增量批更新模式。
物化表的流批模式由資料新鮮度決定(小於30分鐘為流模式,大於等於30分鐘為批模式)。在批處理模式下,全量更新或累加式更新由引擎自動判斷。累加式更新僅計算自上次更新以來的增量資料,並將其合并至物化表中;而全量更新則會計算整個表或整個分區的資料,並對物化表中的資料進行覆蓋。批模式下引擎優先考慮使用累加式更新,當累加式更新無法支援此物化表時,才會使用全量更新。
累加式更新條件
僅當物化表滿足以下條件時,才會使用累加式更新。
在定義物化表時,未配置
partition.fields.#.date-formatter參數指定分區欄位的時間格式。源表未定義主鍵。
物化表中的查詢語句支援累加式更新情況如下:
SQL語句
支援情況
SELECT
支援選擇列以及純量涵式運算式(包括使用者自訂函數),暫不支援彙總函式。
FROM
支援表名或子查詢。
WITH
支援通用資料表運算式Common Table Expression(CTE)。
WHERE
支援過濾條件包括各種純量涵式運算式(包括使用者自訂函數),不支援包含子查詢(如 WHERE [NOT] EXISTS <子查詢>、WHERE <列名> [NOT] IN <子查詢> 等)。
UNION
僅支援UNION ALL。
JOIN
支援INNER JOIN。
暫不支援LEFT/RIGHT/FULL [OUTER] JOIN,除了以下LATERAL JOIN及Lookup Join的情況。
支援[LEFT [OUTER]] JOIN LATERAL table函數運算式(包括使用者自訂函數)。
Lookup Join僅支援A [LEFT [OUTER]] JOIN B FOR SYSTEM_TIME AS OF PROCTIME()。
說明支援不帶JOIN關鍵字的JOIN,例如SELECT * FROM a, b WHERE a.id = b.id。
當前INNER JOIN的增量計算仍然會讀取兩個源表的全量資料。
GROUP BY
暫不支援。
累加式更新樣本
樣本一:對源表orders資料使用純量涵式進行處理。
CREATE MATERIALIZED TABLE mt_shipped_orders (
PRIMARY KEY (order_id) NOT ENFORCED
)
FRESHNESS = INTERVAL '30' MINUTE
AS
SELECT
order_id,
COALESCE(customer_id, 'Unknown') AS customer_id,
CAST(order_amount AS DECIMAL(10, 2)) AS order_amount,
CASE
WHEN status = 'shipped' THEN 'Completed'
WHEN status = 'pending' THEN 'In Progress'
ELSE 'Unknown'
END AS order_status,
DATE_FORMAT(order_ts, 'yyyyMMdd') AS order_date,
UDSF_ProcessFunction(notes) AS notes
FROM
orders
WHERE
status = 'shipped';樣本二:對源表orders資料使用Lateral Join以及Lookup Join進行資訊補充。
CREATE MATERIALIZED TABLE mt_enriched_orders (
PRIMARY KEY (order_id, order_tag) NOT ENFORCED
)
FRESHNESS = INTERVAL '30' MINUTE
AS
WITH o AS (
SELECT
order_id,
product_id,
quantity,
proc_time,
e.tag AS order_tag
FROM
orders,
LATERAL TABLE(UDTF_StringSplitFunction(tags, ',')) AS e(tag))
SELECT
o.order_id,
o.product_id,
p.product_name,
p.category,
o.quantity,
p.price,
o.quantity * p.price AS total_amount,
order_tag
FROM o
LEFT JOIN
product_info FOR SYSTEM_TIME AS OF PROCTIME() AS p
ON
o.product_id = p.product_id;歷史資料回刷
以往在使用流作業後,如需利用前一天的全量資料來訂正流處理的結果,則必須單獨開發一個批作業進行處理。而使用物化表後,可以直接選擇物化錶的歷史資料分區進行資料回刷。這一改變降低了開發和營運成本,實現了流批一體化的能力。
單擊目標Catalog下的物化表。
在資料資訊頁簽,進行資料回刷。
在建立物化表中,如果已聲明分區欄位,則為分區表;否則為非分區表。
分區表
查看資料分區,如果為首次回刷或沒有所需要的分區,單擊手動更新。如果已有分區,可以選擇對應的分區回刷,單擊回刷。
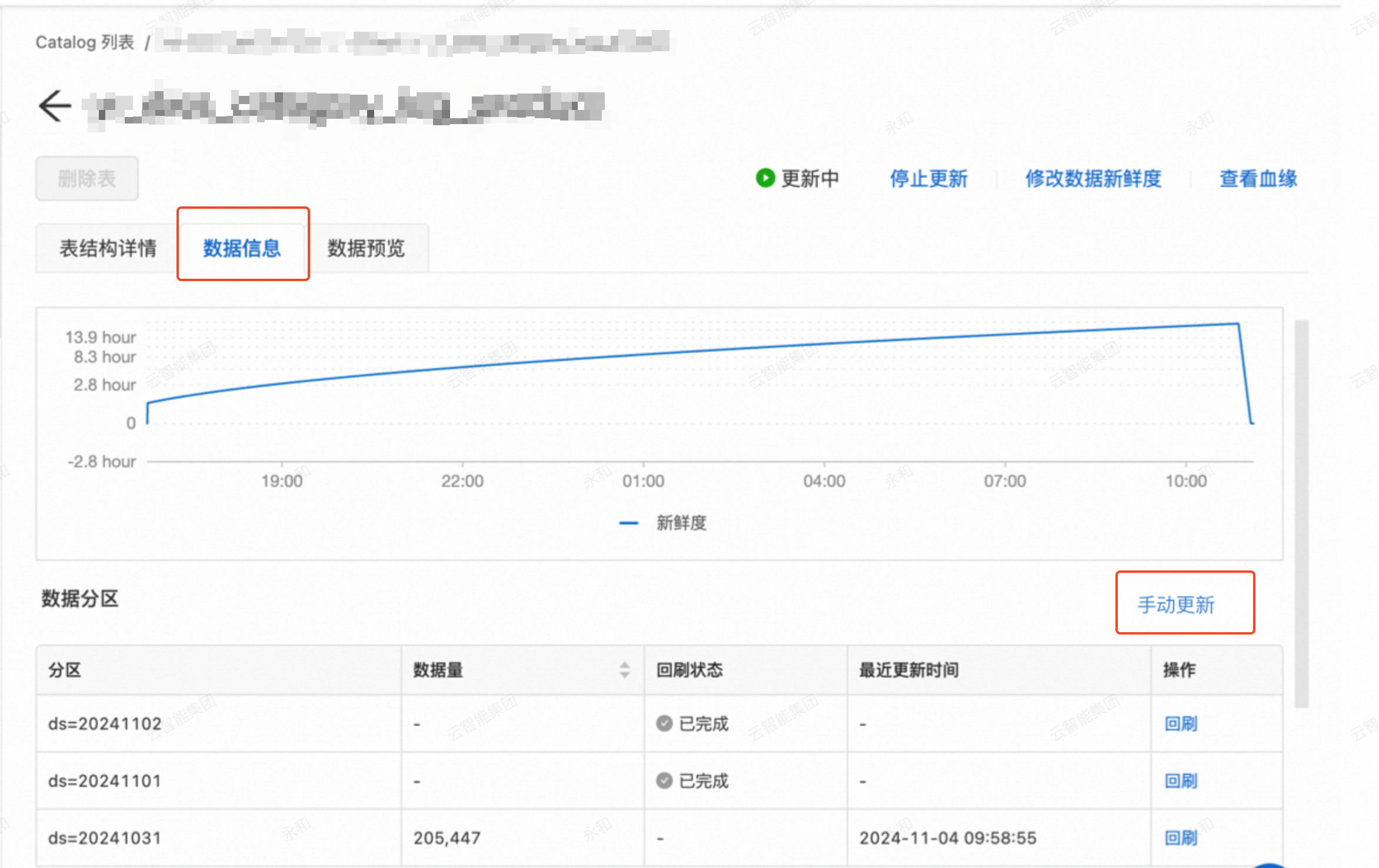
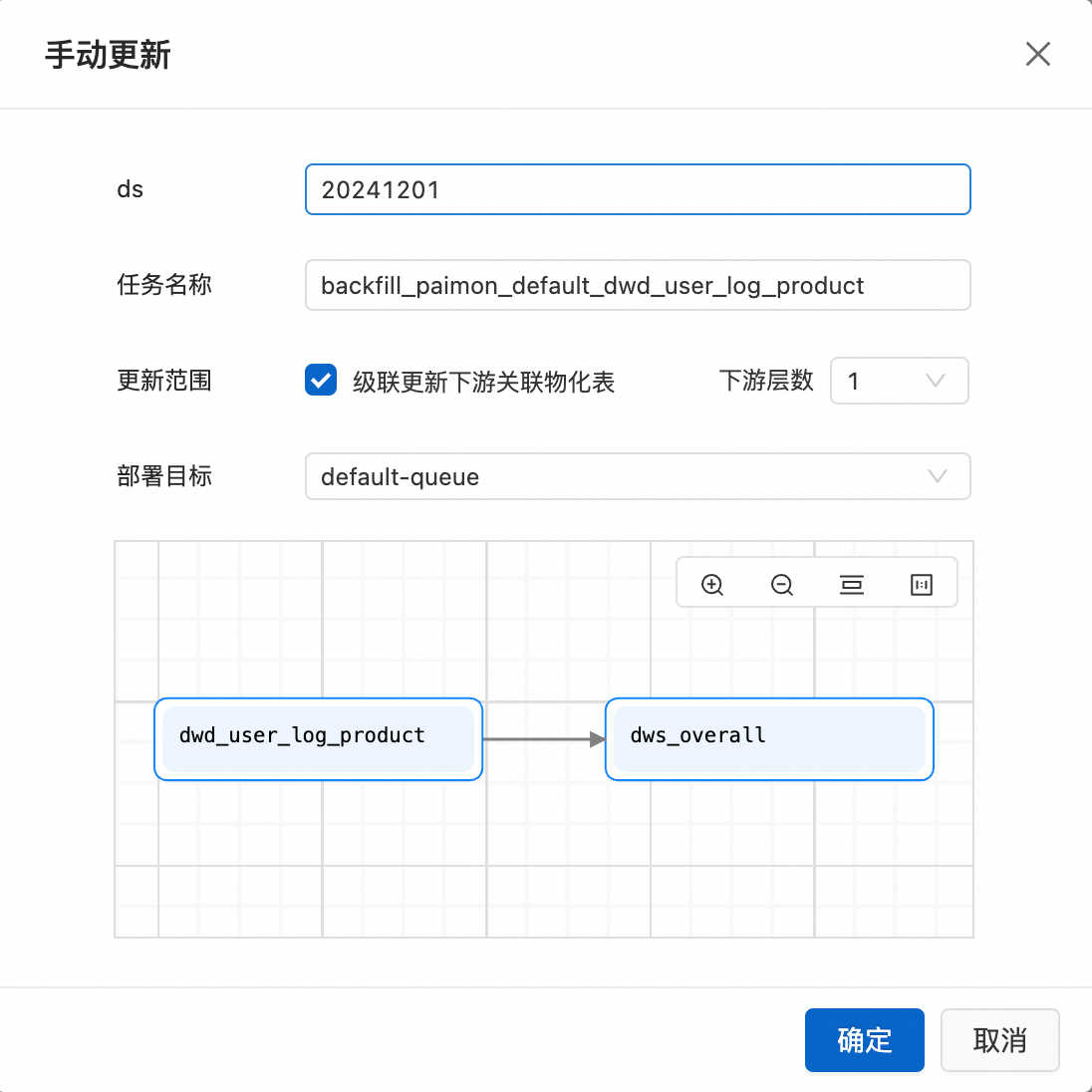
參數說明:
分區欄位:該參數為表分區欄位。例如填寫20241201,將會回刷所有ds=20241201的資料。
任務名稱:資料回刷任務名稱。
修改範圍(可選):是否串聯更新下遊關聯物化表。以該表為起點,更新鏈路上的所有物化表。(下遊層數最大為6)。
說明分區表更新,下遊的物化表在分區欄位上需與起始表完全一致,否則更新操作將失敗。
鏈路中某個物化表更新失敗時,下遊節點將會全部失敗。
部署目標:支援選擇queue和Session隊列。預設選擇default-queue。
非分區表
查看資料情況,單擊回刷。
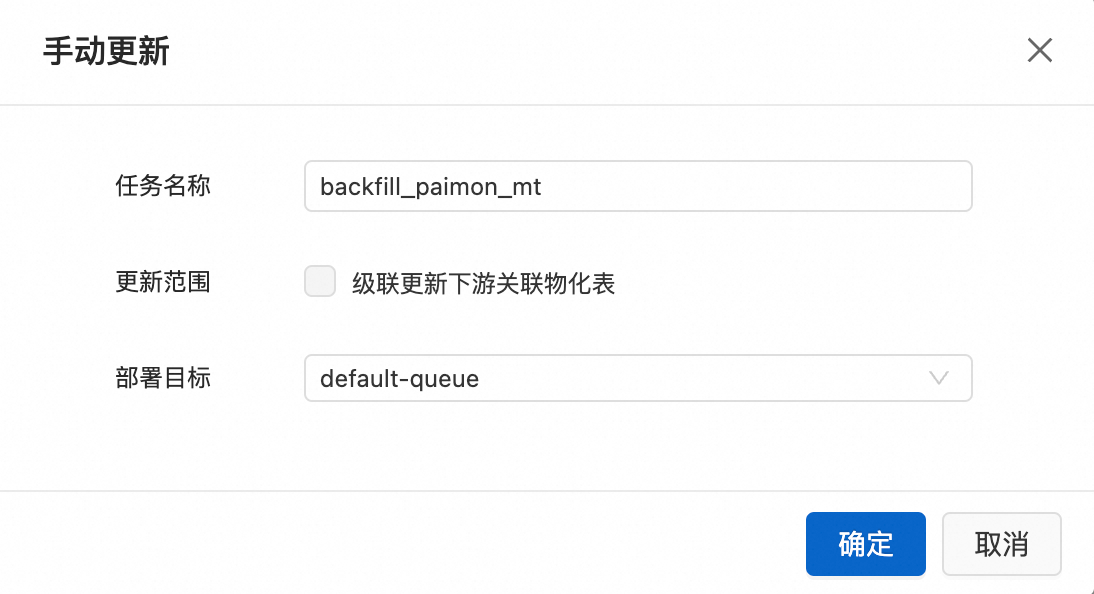
參數說明:
任務名稱:資料回刷任務名稱。
修改範圍:非分區表不可選。
說明更新時下遊資料將進行全量重新整理。
鏈路中某個物化表更新失敗時,下遊節點將會全部失敗。
起始表的新鮮度被系統判定為流任務且為非分區表時,不支援串聯更新。
部署目標:支援選擇queue和Session隊列。預設選擇default-queue。
定時回刷與批量回刷。
使用任務編排建立物化表工作流程,進行周期調度,從而實現定時回刷功能。同時,也可以通過工作流程的資料回刷功能,選擇時間範圍,進行資料批量回刷。
修改資料新鮮度
單擊對應Catalog下的materialized table庫,單擊對應的物化表。
單擊右側修改資料新鮮度。
當物化表為非主鍵表時,不允許更改任務的流批屬性。例如,若將資料新鮮度從2秒修改為1小時,此時Flink會把流作業轉變為批作業;反之亦然,不可進行此類操作。(小於30分鐘為流作業,大於等於30分鐘為批作業)
當基礎資料表為物化表時,需確保下遊的資料新鮮度是上遊的1~N倍(N為正整數)。
資料新鮮度最大不能超過1天。
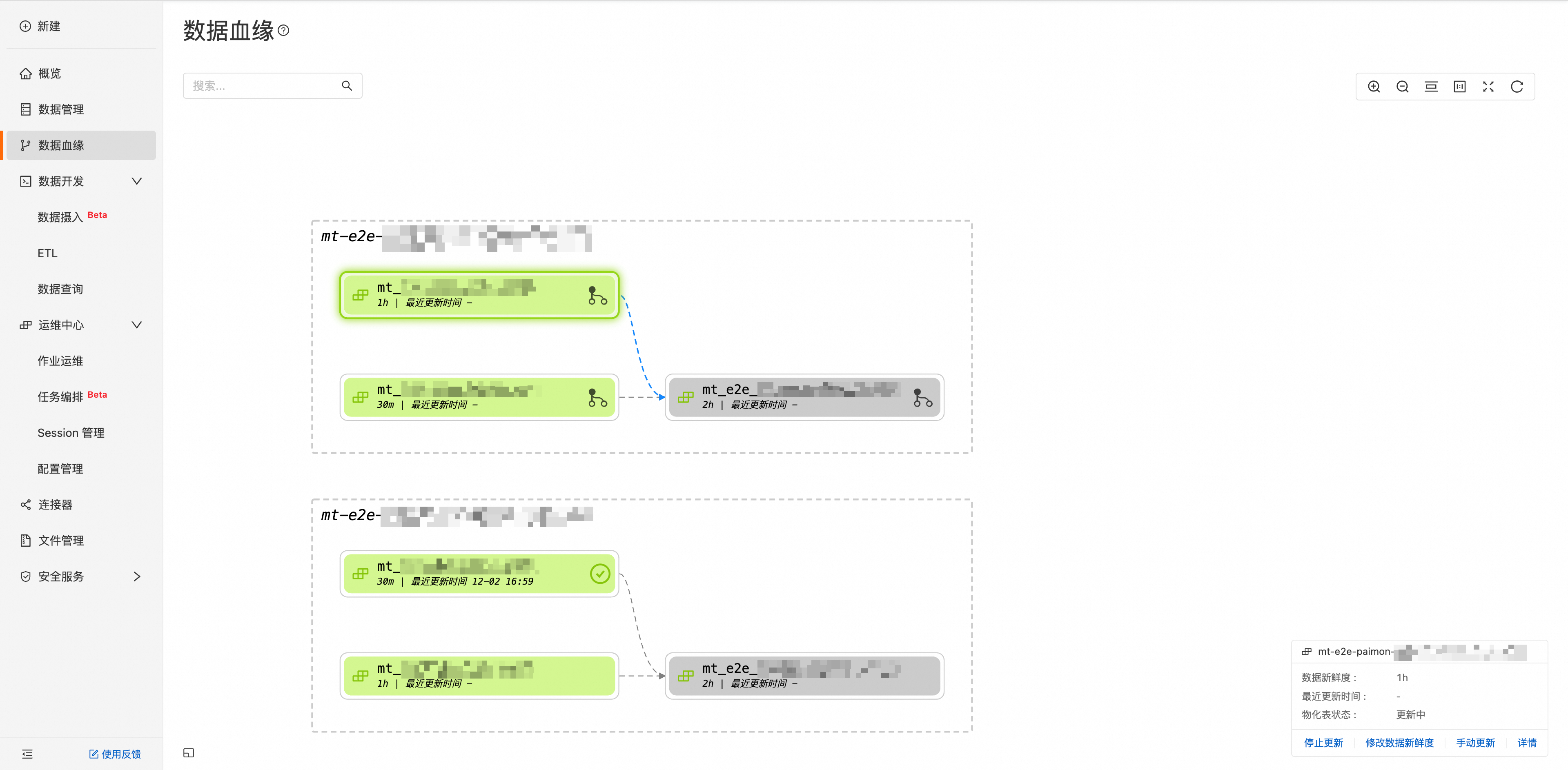
查看資料血緣
資料血緣頁面可以查詢所有物化表之間的血緣關係,並支援在該頁面直接對物化表進行開始/停止更新,修改資料新鮮度等操作,單擊詳情,即可跳轉到對應的物化表進行查看。
相關文檔
物化表介紹詳情請參見物化表管理。
基於Paimon和物化表,構建流批一體的湖倉分析處理鏈路,以及通過修改表資料新鮮度,完成由批到流的切換,實現資料即時更新,詳情請參見物化錶快速入門(構建流批一體湖倉)。