本文將基於物化表,帶您快速體驗如何構建流批一體的湖倉分析處理鏈路,以及通過修改物化表新鮮度,完成由批到流的切換,實現資料的即時更新。
物化表簡介
物化表(Materialized Table)是Flink SQL引入的一種新的表類型,旨在簡化批處理和流處理資料管道,提供流批一體化的開發體驗。建立物化表時無需聲明欄位與類型,通過指定資料新鮮度和查詢語句,Flink引擎將從查詢語句自動推導物化表的Schema,並建立相應的資料重新整理管道,以達到指定的資料新鮮度。詳情請參見物化表管理。
即時湖倉鏈路實踐圖
Flink將資料來源寫入Paimon,形成ODS層。
Flink將ODS層資料關聯打寬進行加工,寫入物化表,形成DWD層。
通過設定不同的資料新鮮度,構建多個物化表,進行多維度業務統計,形成DWS層,以對外提供應用查詢。
前提條件
已建立Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
如果您使用RAM使用者或RAM角色等身份訪問,需要確認已具有Flink控制台相關許可權,詳情請參見許可權管理。
步驟一:準備測試資料
(可選)建立Paimon Catalog。
基於Apache Paimon提供了物化表能力,需要建立中繼資料存放區類型為Filesystem的Paimon Catalog,如果已經建立,可以跳過此步驟。更多詳情請參見建立Paimon Catalog。
單擊目標工作空間操作列下的控制台。
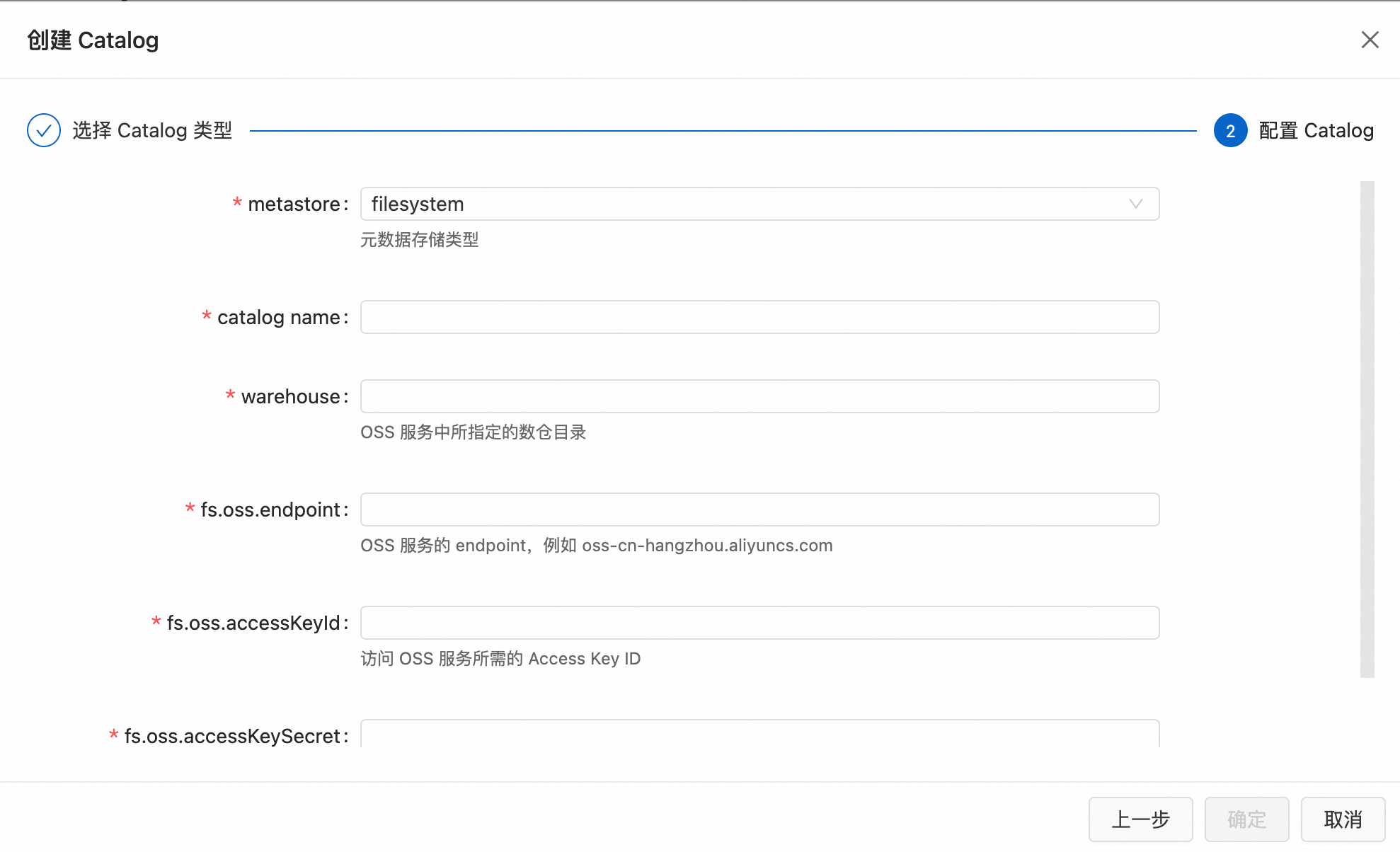
在左側導覽列選擇資料管理,單擊建立Catalog。選擇Apache Paimon,單擊下一步。
參數說明:
配置項
說明
備忘
metastore
中繼資料存放區類型。
本樣本採用filesystem為中繼資料存放區類型。
catalog name
Paimon Catalog名稱。
請填寫為自訂的英文名。本樣本為paimon。
warehouse
OSS服務中所指定的數倉目錄。
格式為
oss://<bucket>/<object>。其中:<bucket>:表示您建立的OSS Bucket名稱。
<object>:表示您存放資料的路徑。
請在OSS管理主控台上查看您的bucket和object名稱。
fs.oss.endpoint
OSS服務的串連地址。
如果Flink與OSS位於同一地區,則使用內網Endpoint,否則使用外網Endpoint。詳情請參見OSS地區和訪問網域名稱。
fs.oss.accessKeyId
擁有讀寫OSS許可權的阿里雲帳號或RAM帳號的Accesskey ID。
擷取方法請參見建立AccessKey。為了防止清除金鑰泄露,建議使用變數寫入,詳情請參見變數管理。
fs.oss.accessKeySecret
擁有讀寫OSS許可權的阿里雲帳號或RAM帳號的Accesskey secret。
建立使用者行為日誌表ods_user_log和商品資訊表ods_dim_product。
單擊目標工作空間操作列下的控制台。
在左側導覽列選擇。複製並粘貼以下代碼建立源表。
本範例已經建立名為paimon的Paimon Catalog,使用預設資料庫default。
CREATE TABLE `paimon`.`default`.`ods_user_log` ( item_id INT NOT NULL, user_id INT NOT NULL, vtime TIMESTAMP(6), ds VARCHAR(10) NOT NULL ) PARTITIONED BY(ds) WITH ( 'bucket' = '4', --指定分桶數為4 'bucket-key' = 'item_id' --指定確定資料分桶的鍵。相同的item_id會被放到一個桶裡。 ); CREATE TABLE `paimon`.`default`.`ods_dim_product` ( item_id INT NOT NULL, title VARCHAR(255), pict_url VARCHAR(255), brand_id INT, seller_id INT, PRIMARY KEY(item_id) NOT ENFORCED ) WITH ( 'bucket' = '4', 'bucket-key' = 'item_id' );單擊右上方運行,建立相應的資料表。
在左側導覽列選擇資料管理,單擊對應的Paimon Catalog後,單擊重新整理查看新增表。
使用類比資料產生Faker連接器產生類比資料,並寫入Paimon表中。
在左側導覽列選擇。
單擊建立,選擇空白的流作業草稿,單擊下一步,單擊建立。
將如下SQL語句複製到SQL編輯器。
CREATE TEMPORARY TABLE `user_log` ( item_id INT, //商品ID user_id INT, //使用者ID vtime TIMESTAMP, ds AS DATE_FORMAT(CURRENT_DATE,'yyyyMMdd') ) WITH ( 'connector' = 'faker', --faker連接器 'fields.item_id.expression'='#{number.numberBetween ''0'',''1000''}', --產生0-1000其中一個隨機數 'fields.user_id.expression'='#{number.numberBetween ''0'',''100''}', 'fields.vtime.expression'='#{date.past ''5'',''HOURS''}', --基於當前日期時間前5小時產生資料 'rows-per-second' = '3' --每秒產生3條資料 ); CREATE TEMPORARY TABLE `dim_product` ( item_id INT NOT NULL, title VARCHAR(255), pict_url VARCHAR(255), brand_id INT, seller_id INT, PRIMARY KEY(item_id) NOT ENFORCED ) WITH ( 'connector' = 'faker', --faker連接器 'fields.item_id.expression'='#{number.numberBetween ''0'',''1000''}', 'fields.title.expression'='#{book.title}', 'fields.pict_url.expression'='#{internet.domainName}', 'fields.brand_id.expression'='#{number.numberBetween ''1000'',''10000''}', 'fields.seller_id.expression'='#{number.numberBetween ''1000'',''10000''}', 'rows-per-second' = '3' --每秒產生3條資料 ); BEGIN STATEMENT SET; INSERT INTO `paimon`.`default`.`ods_user_log` SELECT item_id, user_id, vtime, CAST(ds AS VARCHAR(10)) AS ds FROM `user_log`; INSERT INTO `paimon`.`default`.`ods_dim_product` SELECT item_id, title, pict_url, brand_id, seller_id FROM `dim_product`; END;單擊右上方的部署,進行作業部署。
單擊左側導覽列的,單擊目標作業操作列的啟動,選擇無狀態啟動後單擊啟動。
查詢類比資料。
在左側導覽列選擇。將如下SQL語句複製到SQL編輯器後,單擊右上方的運行。
SELECT * FROM `paimon`.`default`.ods_dim_product LIMIT 10; SELECT * FROM `paimon`.`default`.ods_user_log LIMIT 10;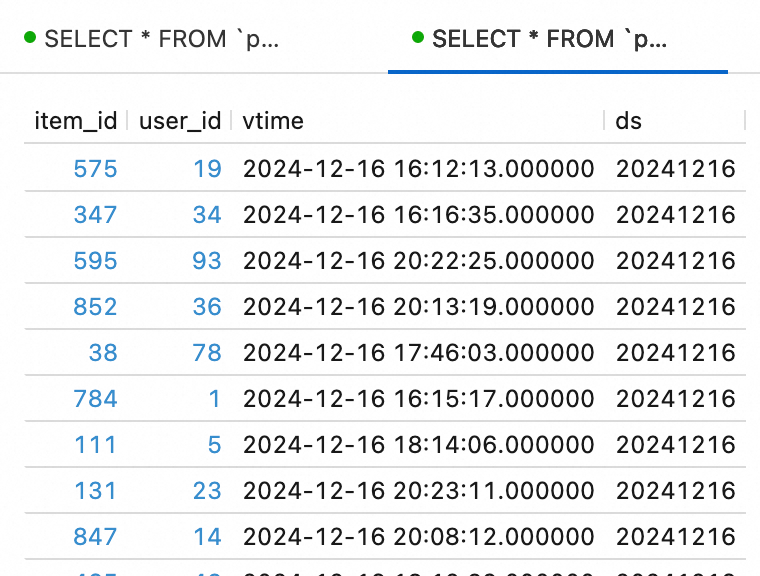
步驟二:建立物化表
本部分通過將源表進行打寬,構建了DWD層的物化表dwd_user_log_product,並基於該物化表進一步構建下遊物化表以進行業務統計,完成了DWS層的構建。
構建資料倉儲的DWD層,建立dwd_user_log_product物化表。
在左側導覽列選擇資料管理,單擊目標Paimon Catalog。
單擊目標資料庫(本樣本為default)後,單擊建立物化表。將如下SQL語句複製到SQL編輯器,單擊建立。
-- DWD 層打寬邏輯 CREATE MATERIALIZED TABLE dwd_user_log_product( PRIMARY KEY (item_id) NOT ENFORCED ) PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR --1小時重新整理 AS SELECT l.ds, l.item_id, l.user_id, l.vtime, r.brand_id, r.seller_id FROM `paimon`.`default`.`ods_user_log` l INNER JOIN `paimon`.`default`.`ods_dim_product` r ON l.item_id = r.item_id;
構建資料倉儲DWS層,基於dwd_user_log_product物化表進行多維度業務統計。
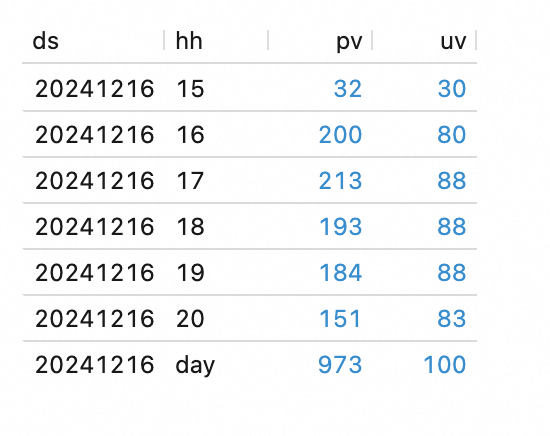
本文以按天統計每小時PV/UV數建立dws_overall物化表為例,參考上一步建立dws_overall物化表。
//按天維度統計 PV/UV CREATE MATERIALIZED TABLE dws_overall( PRIMARY KEY(ds, hh) NOT ENFORCED ) PARTITIONED BY(ds) WITH ( 'partition.fields.ds.date-formatter' = 'yyyyMMdd' ) FRESHNESS = INTERVAL '1' HOUR --1小時重新整理 AS SELECT ds, COALESCE(hh, 'day') AS hh, count(*) AS pv, count(distinct user_id) AS uv FROM (SELECT ds, date_format(vtime, 'HH') AS hh, user_id FROM `paimon`.`default`.`dwd_user_log_product`) tmp GROUP BY GROUPING SETS(ds, (ds, hh));
步驟三:更新物化表
開始更新
本樣本的資料新鮮度為1小時,單擊開始更新後,資料更新相對於基礎資料表更新至少會滯後1小時。
在左側導覽列選擇資料血緣,搜尋目標物化表。
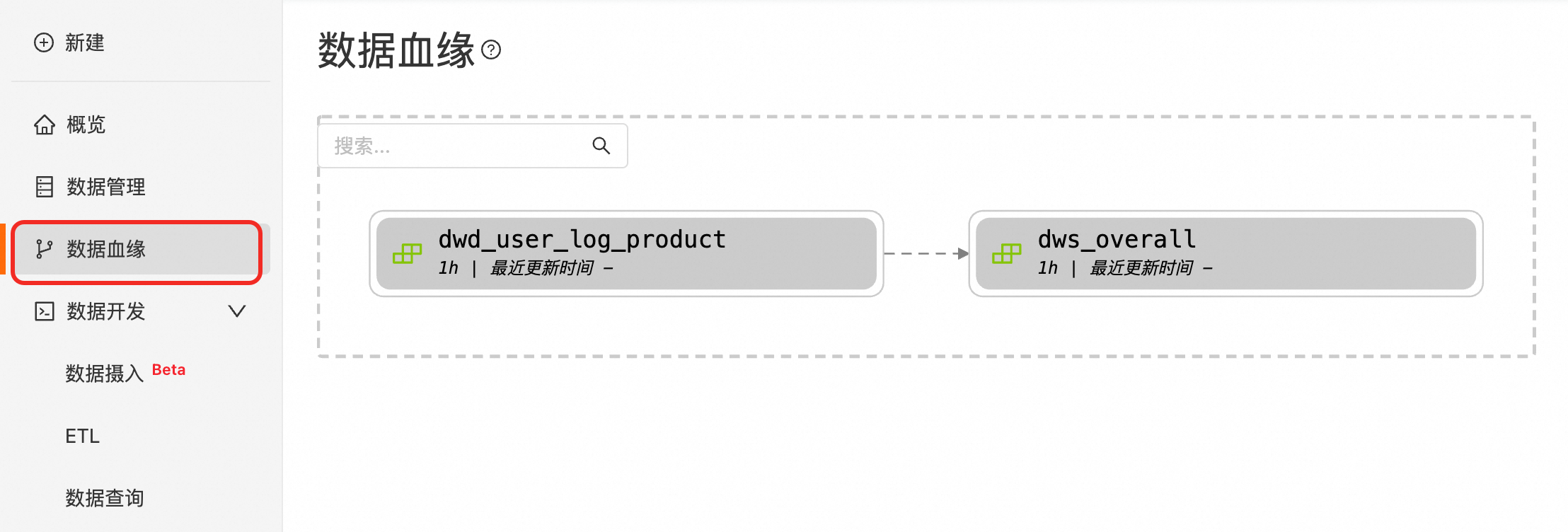
單擊對應物化表視圖,在頁面右下角單擊開始更新。
資料回刷
資料回刷可以將歷史資料重新寫入相應的分區或者整張表,以修正一些流處理結果,或者對於未到調度時間的批作業,也可以進行資料回刷,立即進行資料更新寫入。
選中物化表dwd_user_log_product視圖,單擊頁面右下角手動更新,分區名稱填寫已耗用時間當天的日期,如20241216,勾選串聯更新下遊關聯物化表,單擊確認,彈框確認立即覆蓋相應資料,即可馬上更新。
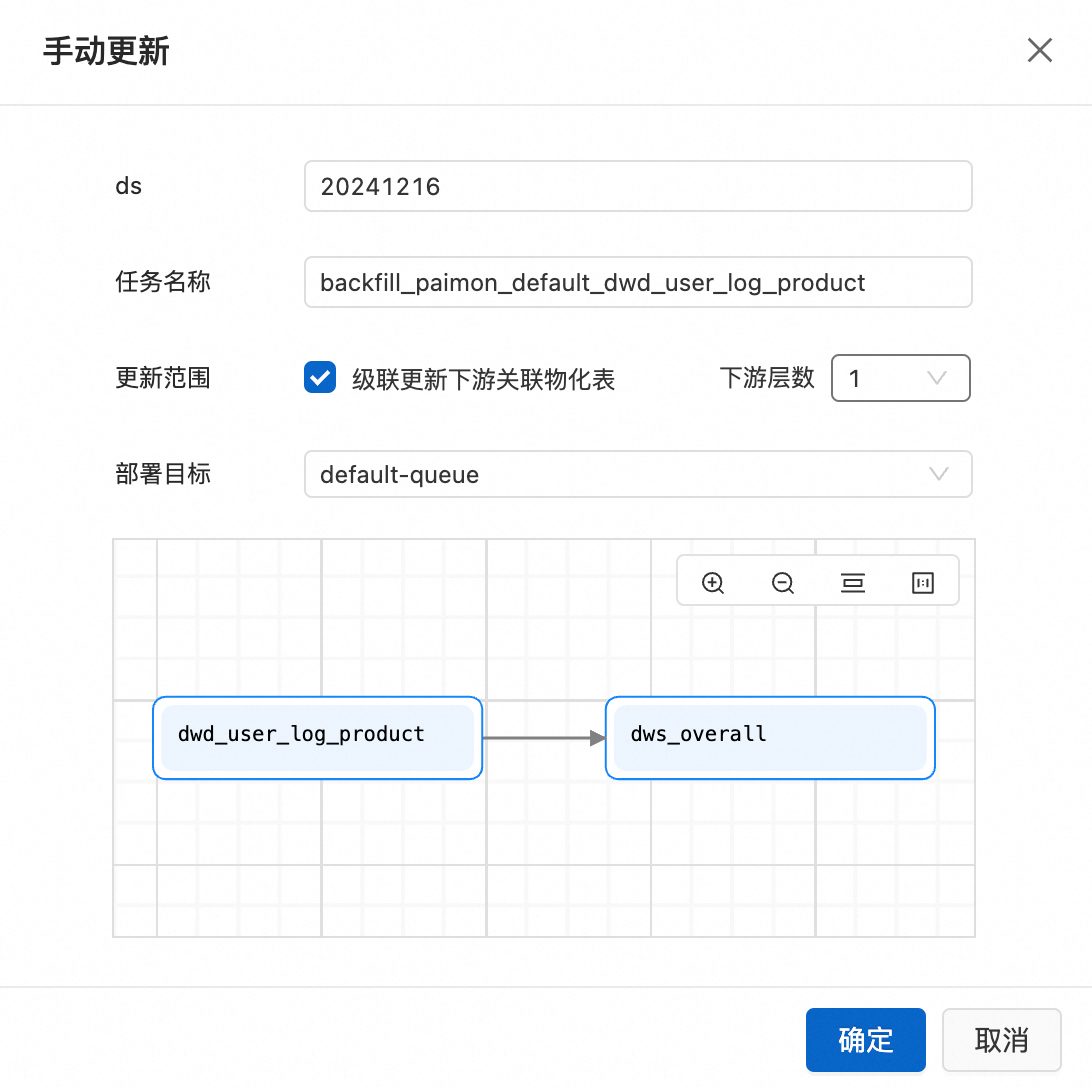
更多資料回刷的使用詳情請參見歷史資料回刷。
修改資料新鮮度
您可以根據業務需要,將資料新鮮度修改為按天級、小時級、分鐘級或秒級更新物化表。
依次修改物化表dwd_user_log_product和物化表dws_overall的資料新鮮度。單擊對應物化表視圖,單擊頁面右下角修改資料新鮮度,將資料新鮮度調整為分鐘級,進行即時更新。
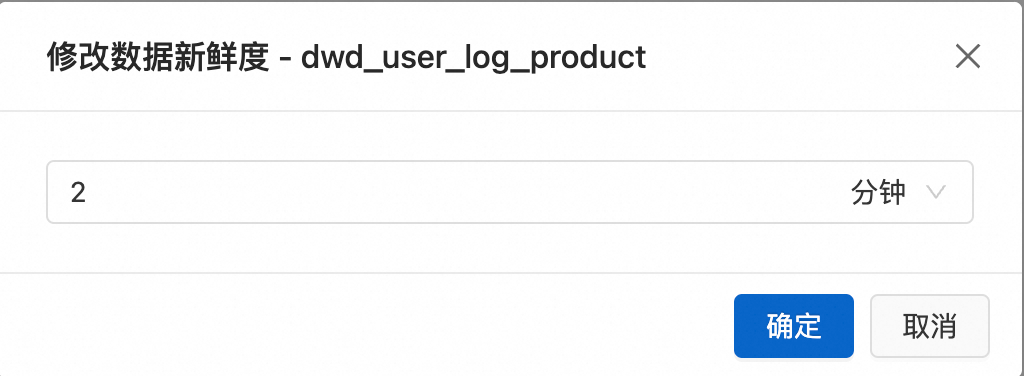
更多修改資料新鮮度的使用詳情請參見修改資料新鮮度。
步驟四:查詢物化表
資料預覽
可以預覽物化表最新的100條資料。
在左側導覽列選擇資料血緣,搜尋目標物化表。
單擊目標物化表視圖,在頁面右下角單擊詳情。
在物化表資料預覽頁簽,單擊查詢表徵圖。
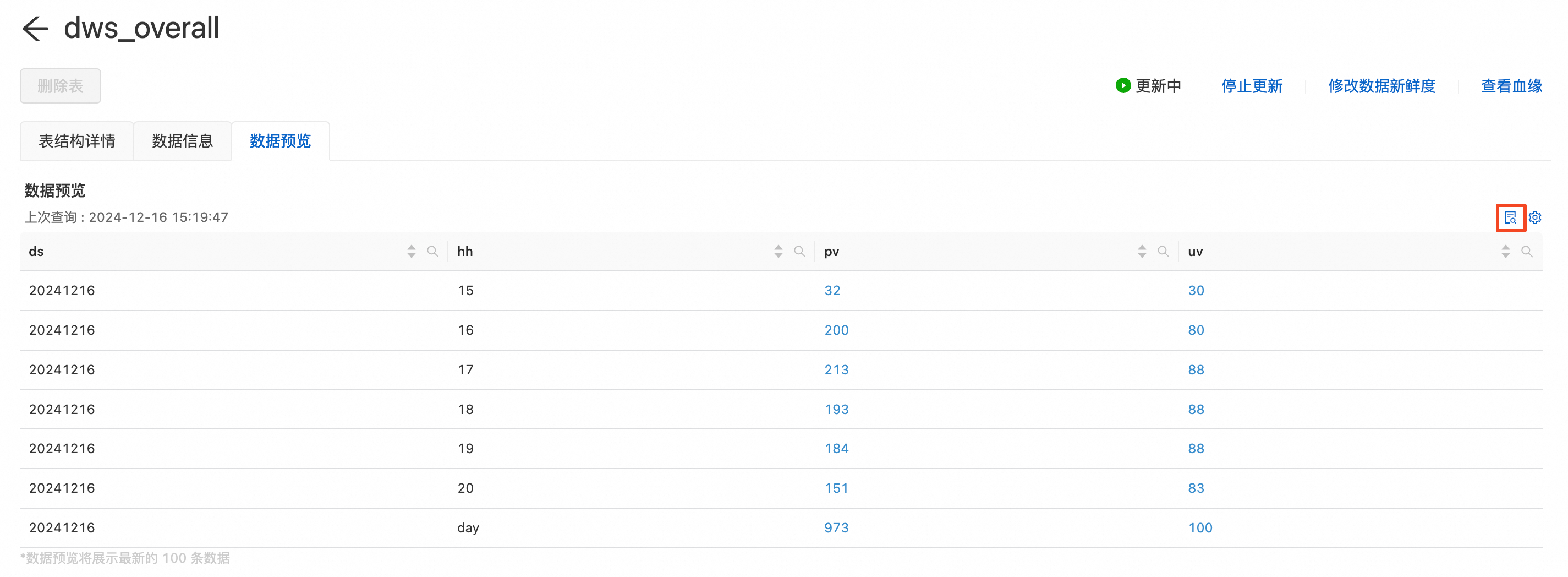
資料查詢
在左側導覽列選擇,將如下SQL語句複製到SQL編輯器後,選中程式碼片段,單擊運行,可以查詢dws_overall物化表。
SELECT * FROM `paimon`.`default`.dws_overall ORDER BY hh;