Realtime ComputeFlink版支援基於DataStream作業運行動態更新規則的Flink CEP任務。本文結合即時營銷中的情境,為您介紹如何基於Realtime ComputeFlink版快速構建一個動態載入最新規則來處理上遊Kafka資料的Flink CEP作業。
應用情境
在實際應用中,Flink CEP基於Flink的分布式特性、毫秒級處理延遲以及其豐富的規則表達能力有著非常廣泛的應用情境。以下我們將展示三個典型情境:
即時風控:Flink CEP可應用於風險使用者識別,例如,通過讀取並分析客戶行為日誌,將在5分鐘內轉賬次數超過10次且金額大於10000的客戶識別為異常使用者。
即時營銷:Flink CEP可用於最佳化營銷策略,例如,通過檢測使用者行為日誌,在電商促銷期間識別出“在10分鐘內添加超過3次商品至購物車但最終未付款”的使用者,以便針對性地調整營銷策略。此外,在即時營銷的反作弊情境中,Flink CEP同樣可發揮作用。
物聯網:Flink CEP可用於檢測異常狀態並發出警報,例如,在共用單車被騎出指定地區且15分鐘內未返回指定地區時發出風險提示。若與物聯網感應器結合,還可以用於檢測工業生產中的流水線異常。例如,若在三個時間周期內,溫度感應器持續反饋溫度超過設定閾值,則應發布警示等措施。
案例示範
本文為您示範如何使用Flink動態CEP解決上述問題。我們假設客戶的行為日誌會被存放入訊息佇列Kafka中,Flink CEP作業會消費Kafka資料,同時會去輪詢RDS資料庫中的規則表,拉取策略人員添加到資料庫的最新規則,並用最新規則去匹配事件。針對匹配到的事件,Flink CEP作業會發出警示或將相關資訊寫入其他資料存放區中。樣本中整體資料鏈路如下圖所示。
實際示範中,我們會先啟動Flink CEP作業,然後插入規則1:連續3條action為0的事件發生後,下一條事件的action仍非1(業務含義為連續3次訪問產品後未購買)。還有針對事件具有時效性的處理規則展示,修改規則1為:連續3條的action為0事件發生時,其對應的時間間隔不能超過15分鐘(業務含義為在30分鐘內連續訪問產品3次後仍未購買)。
前提條件
已建立Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
如果您使用RAM使用者或RAM角色等身份訪問,需要確認已具有Flink控制台相關許可權,詳情請參見許可權管理。
上下遊儲存
已建立RDS MySQL執行個體,詳情請參見建立RDS MySQL執行個體。
已建立訊息佇列Kafka執行個體,詳情請參見訊息佇列Kafka。
操作流程
本文將介紹如何編寫Flink CEP作業,以監測行為日誌中符合特定規則的使用者並將其記錄下來,同時示範如何?規則的動態更新。具體的操作流程如下:
步驟一:準備測試資料
準備上遊Kafka Topic
建立一個名稱為demo_topic的Topic,存放類比的使用者行為日誌。
操作詳情請參見步驟一:建立Topic。
準備RDS資料庫
在Data Management控制台上,準備RDS MySQL的測試資料。
使用高許可權帳號登入RDS MySQL。
詳情請參見通過DMS登入RDS MySQL執行個體。
建立rds_demo規則表,用來記錄Flink CEP作業中需要應用的規則。建立match_results結果表,來記錄規則匹配到的結果資料。
在已登入的SQLConsole視窗,輸入如下命令後,單擊執行。
CREATE DATABASE cep_demo_db; USE cep_demo_db; CREATE TABLE rds_demo ( `id` VARCHAR(64), `version` INT, `pattern` VARCHAR(4096), `function` VARCHAR(512) ); CREATE TABLE match_results ( rule_id INT, rule_version INT, user_id INT, user_name VARCHAR(255), production_id INT, PRIMARY KEY (rule_id,rule_version,user_id,production_id) );rds_demo規則表每行代表一條規則,包含id、version等用於區分不同規則與每個規則不同版本的欄位、描述CEP API中的模式對象的pattern欄位,以及描述如何處理匹配模式的事件序列的function欄位。
match_results結果表每行代表某使用者針對某產品的行為符合特定規則所產生的匹配結果。後續可基於該條記錄製定相應的銷售策略,例如發送相應商品的優惠券。
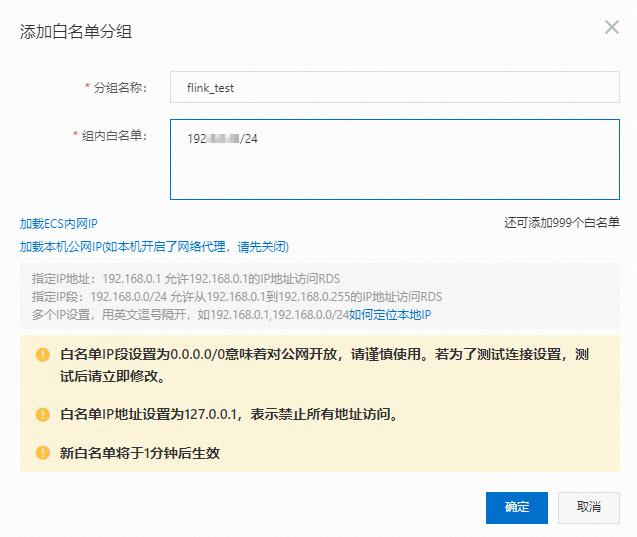
步驟二:配置IP白名單
為了讓Flink能訪問RDS MySQL執行個體,您需要將Realtime ComputeFlink版的網段添加到RDS MySQL的白名單中。
擷取Realtime ComputeFlink版工作空間的VPC網段。
在目標工作空間右側操作列,選擇。
在工作空間詳情對話方塊,查看Flink全託管虛擬交換器的網段資訊。

在RDS MySQL的IP白名單中,添加Flink全託管網段資訊。
操作步驟詳情請參見設定IP白名單。
步驟三:開發並啟動Flink CEP作業
本文中提及的所有代碼均可在Github倉庫中下載。為便於示範,本文中的範例代碼在timeOrMoreAndWindow分支上進行了部分修改,您可以直接下載ververica-cep-demo-master.zip壓縮包以進行查看和參考。
在作業的Maven POM檔案中添加flink-cep作為專案依賴。
其他Flink相關的Jar包處理和衝突解決,詳情請參見配置Flink環境依賴。
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-cep</artifactId> <version>1.17-vvr-8.0.8</version> <scope>provided</scope> </dependency>開發作業代碼。
構建Kafka Source。
代碼編寫詳情,請參見Kafka DataStream Connector。
構建CEP.dynamicPatterns() API。
為支援CEP規則動態變更與多規則匹配,阿里雲Realtime ComputeFlink版定義了CEP.dynamicPatterns() API。該API定義代碼如下。
public static <T, R> SingleOutputStreamOperator<R> dynamicPatterns( DataStream<T> input, PatternProcessorDiscovererFactory<T> discovererFactory, TimeBehaviour timeBehaviour, TypeInformation<R> outTypeInfo)使用該API時,所需參數如下。您可以根據實際使用方式,更新相應的參數取值。
參數
說明
DataStream<T> input
輸入事件流。
PatternProcessorDiscovererFactory<T> discovererFactory
工廠對象。工廠對象負責構造一個探查器(PatternProcessorDiscoverer),探查器負責擷取最新規則,即構造一個PatternProcessor介面。
TimeBehaviour timeBehaviour
描述Flink CEP作業如何處理事件的時間屬性。參數取值如下:
TimeBehaviour.ProcessingTime:代表按照Processing Time處理事件。
TimeBehaviour.EventTime:代表按照Event Time處理事件。
TypeInformation<R> outTypeInfo
描述輸出資料流的類型資訊。
關於DataStream、TimeBehaviour、TypeInformation等Flink作業常見概念詳情,請參見DataStream、TimeBehaviour和TypeInformation。
這裡重點介紹PatternProcessor介面,一個PatternProcessor包含一個確定的模式(Pattern)用於描述如何去匹配事件,以及一個PatternProcessFunction用於描述如何處理一個匹配(例如發送警報)。除此之外,還包含id與version等用於標識PatternProcessor的資訊。因此一個PatternProcessor既包含規則本身,又指明了規則引發時,Flink作業應如何響應。更多背景請參見提案。
而patternProcessorDiscovererFactory用於構造一個探查器去擷取最新的PatternProcessor,我們在範例程式碼中提供了一個預設的周期性掃描外部儲存的抽象類別。它描述了如何啟動一個Timer去定時輪詢外部儲存拉取最新的PatternProcessor。
public abstract class PeriodicPatternProcessorDiscoverer<T> implements PatternProcessorDiscoverer<T> { ... @Override public void discoverPatternProcessorUpdates( PatternProcessorManager<T> patternProcessorManager) { // Periodically discovers the pattern processor updates. timer.schedule( new TimerTask() { @Override public void run() { if (arePatternProcessorsUpdated()) { List<PatternProcessor<T>> patternProcessors = null; try { patternProcessors = getLatestPatternProcessors(); } catch (Exception e) { e.printStackTrace(); } patternProcessorManager.onPatternProcessorsUpdated(patternProcessors); } } }, 0, intervalMillis); } ... }Realtime ComputeFlink版提供了JDBCPeriodicPatternProcessorDiscoverer的實現,用於從支援JDBC協議的資料庫(例如RDS或者Hologres等)中拉取最新的規則。在使用時,您需要指定如下參數。
參數
說明
jdbcUrl
資料庫JDBC串連地址。
jdbcDriver
資料庫驅動類類名。
tableName
資料庫表名。
initialPatternProcessors
當資料庫的規則表為空白時,使用預設的PatternProcessor。
intervalMillis
輪詢資料庫的時間間隔。
在實際代碼中您可以按如下方式使用,作業將會匹配到的規則列印到Flink TaskManager的輸出中。
// import ...... public class CepDemo { public static void main(String[] args) throws Exception { ...... // DataStream Source DataStreamSource<Event> source = env.fromSource( kafkaSource, WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner((event, ts) -> event.getEventTime()), "Kafka Source"); env.setParallelism(1); // keyBy userId and productionId // Notes, only events with the same key will be processd to see if there is a match KeyedStream<Event, Tuple2<Integer, Integer>> keyedStream = source.assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forGenerator(ctx -> new EventBoundedOutOfOrdernessWatermarks(Duration.ofSeconds(5))) ).keyBy(new KeySelector<Event, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> getKey(Event value) throws Exception { return Tuple2.of(value.getId(), value.getProductionId()); } }); SingleOutputStreamOperator<String> output = CEP.dynamicPatterns( keyedStream, new JDBCPeriodicPatternProcessorDiscovererFactory<>( params.get(JDBC_URL_ARG), JDBC_DRIVE, params.get(TABLE_NAME_ARG), null, Long.parseLong(params.get(JDBC_INTERVAL_MILLIS_ARG))), Boolean.parseBoolean(params.get(USING_EVENT_TIME)) ? TimeBehaviour.EventTime : TimeBehaviour.ProcessingTime, TypeInformation.of(new TypeHint<String>() {})); output.print(); // Compile and submit the job env.execute("CEPDemo"); } }說明為了方便示範,我們在Demo代碼裡將輸入資料流按照id和product id做了一步keyBy,再與
CEP.dynamicPatterns()串連使用。這意味著只有具有相同id和product id的事件會被納入到規則匹配的考慮中,不同Key的事件之間不會產生匹配。
在Realtime Compute控制台上,上傳JAR包並部署JAR作業,具體操作詳情請參見部署作業。
為了讓您可以快速測試使用,您需要下載Realtime ComputeFlink版測試cep-demo.jar。部署時需要配置的參數填寫說明如下表所示。
說明由於目前我們上遊的Kafka Source暫無資料,並且資料庫中的規則表為空白。因此作業運行起來之後,暫時會沒有輸出。
配置項
說明
部署模式
選擇為流模式。
部署名稱
填寫對應的JAR作業名稱。
引擎版本
引擎版本詳情請參見引擎版本介紹和生命週期策略。建議您使用推薦版本或穩定版本,版本戳記含義詳情如下:
推薦版本:當前最新大版本下的最新小版本。
穩定版本:還在產品服務期內的大版本下最新的小版本,已修複歷史版本缺陷。
普通版本:還在產品服務期內的其他小版本。
EOS版本:超過產品服務期限的版本。
JAR URI
上傳打包好的JAR包,或者直接上傳我們提供的測試JAR包。
Entry Point Class
填寫為
com.alibaba.ververica.cep.demo.CepDemo。Entry Point Main Arguments
如果您是自己開發的作業,已經配置了相關上下遊儲存的資訊,則此處可以不填寫。但是,如果您使用的是我們提供的測試JAR包,則需要配置該參數。代碼資訊如下。
--kafkaBrokers YOUR_KAFKA_BROKERS --inputTopic YOUR_KAFKA_TOPIC --inputTopicGroup YOUR_KAFKA_TOPIC_GROUP --jdbcUrl jdbc:mysql://YOUR_DB_URL:port/DATABASE_NAME?user=YOUR_USERNAME&password=YOUR_PASSWORD --tableName YOUR_TABLE_NAME --jdbcIntervalMs 3000 --usingEventTime false其中涉及的參數及含義如下:
kafkaBrokers:Kafka Broker地址。
inputTopic:Kafka Topic名稱。
inputTopicGroup:Kafka消費組。
jdbcUrl:資料庫JDBC串連地址。
說明本樣本所使用的JDBC URL中對應的帳號和密碼需要為普通帳號和密碼,且密碼僅支援英文字母和數字。在實際情境中,您可根據您的需求在作業中使用不同的鑒權方式。
tableName:目標表名稱。
jdbcIntervalMs:輪詢資料庫的時間間隔。
usingEventTime:是否使用事件時間處理(true/false)。
說明需要將以上參數的取值修改為您實際業務上下遊儲存的資訊。
生產環境應避免使用純文字密碼,建議使用變數管理功能。詳情請參見變數管理。
在部署詳情頁簽中的其他配置,添加如下作業運行參數。
在實際應用中,
flink-cep的jar依賴於系統類別載入器進行載入,而aviator相關的類通常打包在使用者jar中,使用使用者類載入器載入。通過下面兩個配置,可以確保系統類別載入器在嘗試載入類時,能夠訪問到使用者jar中的類,從而避免類載入失敗的問題。kubernetes.application-mode.classpath.include-user-jar: 'true' classloader.resolve-order: parent-first運行參數配置步驟詳情請參見運行參數配置。
在頁面,單擊目標作業操作列下的啟動。
作業啟動參數配置詳情請參見作業啟動。
步驟四:插入規則
啟動Flink CEP作業,然後插入規則1:連續3條action為0的事件發生後,下一條事件的action仍非1,其業務含義為連續3次訪問產品後沒有購買。
登入RDS MySQL控制台。
插入動態更新規則。
將JSON字串與id、version、function類名等拼接後插入到RDS中。
INSERT INTO rds_demo ( `id`, `version`, `pattern`, `function` ) values( '1', 1, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}', 'com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction') ;為了方便您使用並提高資料庫中的Pattern欄位的可讀性,Realtime ComputeFlink版定義了一套JSON格式的規則描述,詳情請參見動態CEP中規則的JSON格式定義。上述SQL語句中的pattern欄位的值就是按照JSON格式的規則,給出的序列化後的pattern字串。它的物理意義是去匹配這樣的模式:連續3條action為0的事件發生後,下一條事件的action仍為非1。
說明在EndCondtion相關代碼中,定義的條件為“action != 1"。
對應的CEP API描述如下。
Pattern<Event, Event> pattern = Pattern.<Event>begin("start", AfterMatchSkipStrategy.skipPastLastEvent()) .where(new StartCondition("action == 0")) .timesOrMore(3) .followedBy("end") .where(new EndCondition());可以通過CepJsonUtils中的方法將其轉換為對應的JSON字串。
public void printTestPattern(Pattern<?, ?> pattern) throws JsonProcessingException { System.out.println(CepJsonUtils.convertPatternToJSONString(pattern)); }對應的JSON字串如下。
通過Kafka Client向demo_topic中發送訊息。
在本Demo中,您也可以使用訊息佇列Kafka提供的快速體驗訊息收發頁面發送測試訊息。
1,Ken,0,1,1662022777000 1,Ken,0,1,1662022778000 1,Ken,0,1,1662022779000 1,Ken,0,1,1662022780000
demo_topic欄位說明如下表所示。
欄位
說明
id
使用者ID。
username
使用者名稱。
action
使用者動作,取值如下:
0代表瀏覽操作。
1代表購買動作。
product_id
商品ID。
event_time
該行為發生的事件時間。
查看JobManager日誌中列印的最新規則和TaskManager日誌中列印的匹配。
在JobManager日誌中,通過JDBCPeriodicPatternProcessorDiscoverer關鍵詞搜尋,查看最新的規則。
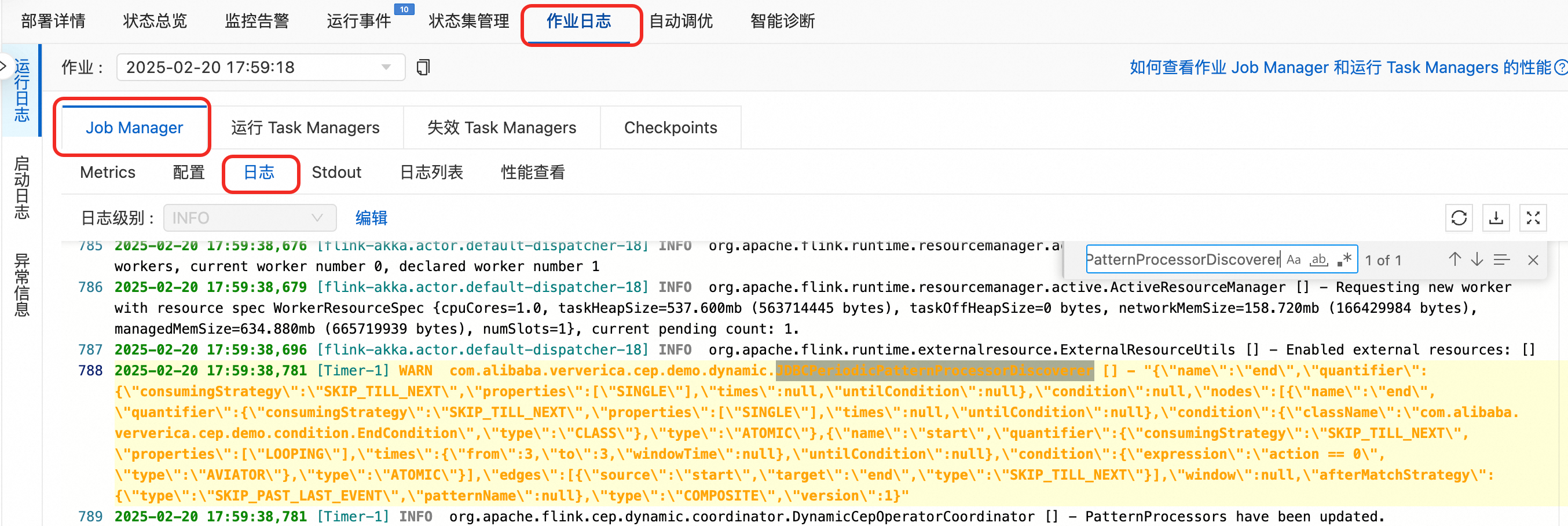
在TaskManager中以.out結尾的記錄檔中,通過
A match for Pattern of (id, version): (1, 1)關鍵詞搜尋,查看日誌中列印的匹配。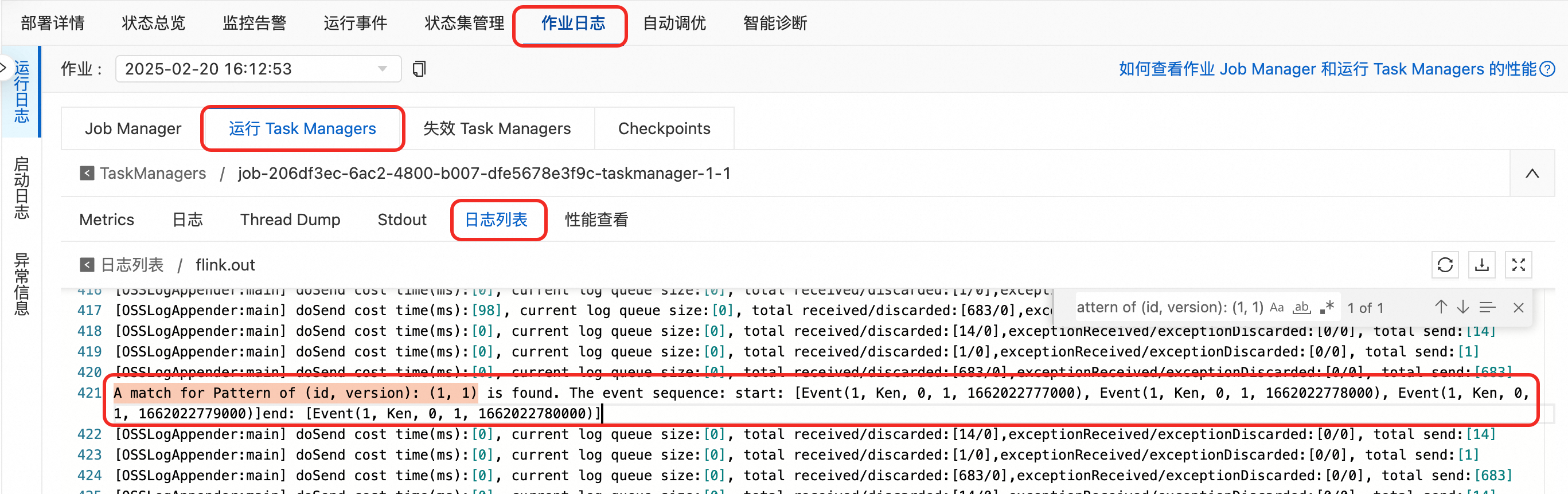
查看match_results結果表,
SELECT * FROM `match_results` ;查詢規則所匹配到的結果資訊。
步驟五:更新匹配規則
在實際應用中,針對使用者制定對應的營銷策略時,往往需要具有時效性,我們將規則更新為:連續3條的action為0事件發生時,其相應的時間間隔不能超過15分鐘。
設定usingEventTime參數為true。
在頁面,單擊目標作業操作列下的停止。
在中編輯,修改
usingEventTime參數為true後,點擊儲存。重新啟動作業。
插入新規則。
對應的CEP API描述如下。
Pattern<Event, Event> pattern = Pattern.<Event>begin("start", AfterMatchSkipStrategy.skipPastLastEvent()) .where(new StartCondition("action == 0")) .timesOrMore(3,Time.minutes(15)) .followedBy("end") .where(new EndCondition()); printTestPattern(pattern);向rds_demo表中插入新規則。
# 為避免規則相同影響示範效果,我們先刪除之前的規則 DELETE FROM `rds_demo` WHERE `id` = 1; # 插入新規則:連續3條的action為0事件發生時,其相應的時間間隔不能超過15分鐘,下一條事件的action仍為非1。規則版本為(1,2)。 INSERT INTO rds_demo (`id`,`version`,`pattern`,`function`) values('1',2,'{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":{"unit":"MINUTES","size":15}},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}','com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction');在Kafka控制台上發送8條簡單的訊息,來觸發匹配。
8條簡單的訊息樣本如下。
2,Tom,0,1,1739584800000 #10:00 2,Tom,0,1,1739585400000 #10:10 2,Tom,0,1,1739585700000 #10:15 2,Tom,0,1,1739586000000 #10:20 3,Ali,0,1,1739586600000 #10:30 3,Ali,0,1,1739588400000 #11:00 3,Ali,0,1,1739589000000 #11:10 3,Ali,0,1,1739590200000 #11:30查看match_results結果表,
SELECT * FROM `match_results` ;查詢規則所匹配到的結果資訊。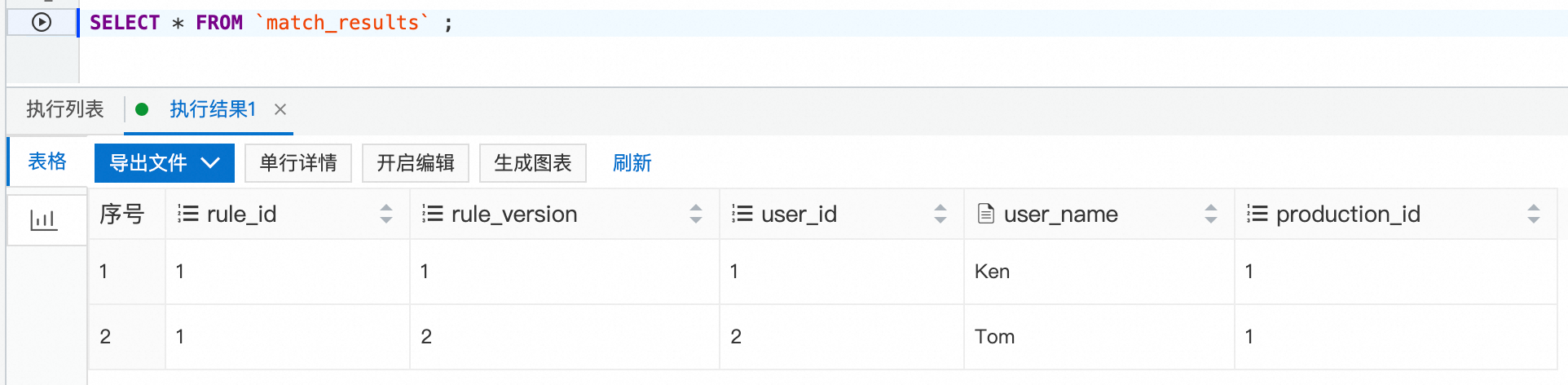
從結果來看,僅有使用者Tom的行為符合規則匹配,由於Ali的行為周期超過15分鐘,未滿足相應的規則。在某些限時促銷活動中,針對在規定時間內多次訪問特定產品的使用者,可以向其發放優惠券等,以引導使用者進行消費。