本文介紹SQL開發中涉及的重要參數說明和使用樣本。
table.exec.sink.keyed-shuffle
為解決向帶有主鍵的表中寫入資料時出現的分布式亂序問題,您可以通過table.exec.sink.keyed-shuffle參數來進行Hash Shuffle操作,這將確保相同主鍵的資料被發送到運算元的同一個並發,減少分布式亂序問題。
注意事項
僅在上遊運算元能夠確保更新記錄在主鍵欄位上的順序性時,Hash Shuffle操作才起作用;否則,Hash Shuffle操作不能解決問題。
在作業專家模式時,修改運算元並發度,不適用下面的並發度判定規則。
取值說明
AUTO(預設值):表示在Sink的並發度不為1,且Sink的並發度與上遊運算元不同時,當資料流向Sink時,Flink會自動對主鍵欄位進行Hash Shuffle操作。
FORCE:表示在Sink並發度不為1時,當資料流向Sink時,Flink會強制對主鍵欄位進行Hash Shuffle操作。
NONE:表示Flink不會根據Sink和上遊運算元的並發度資訊進行Hash Shuffle操作。
使用樣本
參數值為AUTO
建立SQL流作業,複製如下測試SQL(顯式指定Sink並發度為2),部署作業。
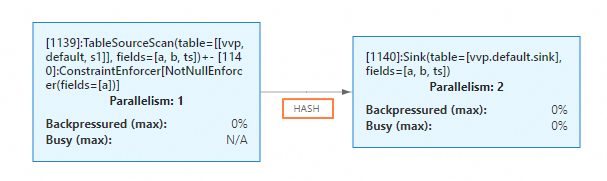
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print', --您可以通過sink.parallelism參數直接指定Sink並發度。 'sink.parallelism'='2' ); INSERT INTO sink SELECT * FROM s1; --您也可以通過動態表選項的方式指定Sink並發度。 --INSERT INTO sink /*+ OPTIONS('sink.parallelism' = '2') */ SELECT * FROM s1;在作業營運頁面的部署詳情頁簽資源配置地區,將並發度設定為1,在運行參數配置地區其他配置中,不設定
table.exec.sink.keyed-shuffle參數或顯式添加table.exec.sink.keyed-shuffle: AUTO(兩者效果一致)。
啟動作業。在狀態總覽頁簽下,您可以看到Sink節點和上遊的資料連線方式為HASH。
參數值為FORCE
建立SQL流作業,複製如下測試SQL(不再顯式指定Sink並發度),部署作業。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT * FROM s1;在作業營運頁面的部署詳情頁簽資源配置地區,將並發度設定為2。在運行參數配置地區其他配置中添加
table.exec.sink.keyed-shuffle: FORCE。
啟動作業後,在狀態總覽頁簽下,您可以看到Sink節點和上遊節點的並發度都為2,並且資料連線方式變成了HASH。
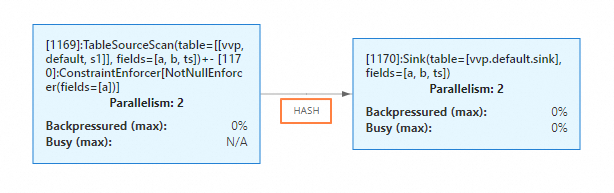
table.exec.mini-batch.size
該參數控制了相關的計算節點進行微批操作所緩衝的最巨量資料條數,達到該值後觸發最終的計算和資料輸出。該參數只有與table.exec.mini-batch.enabled、table.exec.mini-batch.allow-latency同時使用時才會生效。有關MiniBatch相關的最佳化請參見MiniBatch Aggregation和MiniBatch 雙流Join。
注意事項
在作業啟動前,如果未在運行參數配置地區顯式設定該參數,在MiniBatch處理模式下,將使用Managed Memory快取資料,在以下幾種條件下都會觸發最終計算和資料輸出:
收到MiniBatchAssigner節點發送的watermark訊息
Managed Memory已滿
進行Checkpoint前
作業停止時
取值說明
-1(預設值):表示使用Managed Memory快取資料。
其他Long類型的負值:同預設設定。
其他Long類型的正值:表示使用Heap Memory來快取資料。當緩衝的資料量達到N條時,會自動觸發輸出操作。
使用樣本
建立SQL流作業,複製如下測試SQL,部署作業。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED, WATERMARK FOR ts AS ts - INTERVAL '1' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random', 'fields.ts.max-past'='5s', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b BIGINT, PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT a, sum(b) FROM s1 GROUP BY a;在作業營運頁面的部署詳情頁運行參數配置地區其他配置中,設定
table.exec.mini-batch.enabled: true和table.exec.mini-batch.allow-latency: 2s參數,不設定table.exec.mini-batch.size(取預設值-1)。啟動作業。在狀態總覽頁簽下,您可以看到作業包含了MiniBatchAssigner節點、LocalGroupAggregate節點和GlobalGroupAggregate節點。

table.exec.agg.mini-batch.output-identical-enabled
在開啟State TTL的情況下,MinibatchGlobalAgg節點和MinibatchAgg節點在消費資料後,如果彙總結果未發生變化,預設將不會向下遊發送重複的資料,這可能導致下遊的有狀態節點由於長時間未收到上遊發送的資料,自身State到期的問題。該參數控制了開啟StateTTL且彙總結果未發生變化的情況下,是否仍然向下遊發送重複資料。您可以設定該參數為true,使得MinibatchGlobalAgg和MinibatchAgg兩個節點在這種情況下,仍然下發資料。如果您的作業彙總結果變化周期小於State TTL設定時間,則無需手動設定此參數。具體社區Issues詳情請參考FLINK-33936。
注意事項
該參數僅在VVR-8.0.8及以上版本生效,在VVR-8.0.8前的版本,其行為等同於取值為false的行為。
當取值從false修改為true時,可能會導致MinibatchGlobalAgg節點和MinibatchAgg節點向下遊發送的資料量增加,對下遊運算元造成壓力。
取值說明
false(預設值):表示在開啟State TTL的情況下,MinibatchGlobalAgg節點和MinibatchAgg節點在消費資料後,如果彙總結果未發生變化,就不向下遊下發資料。
true:表示在開啟State TTL的情況下,MinibatchGlobalAgg節點和MinibatchAgg節點在消費資料後,如果彙總結果未發生變化,仍然向下遊發送更新的(重複的)資料。
使用樣本
建立SQL流作業,複製如下測試SQL,部署作業。
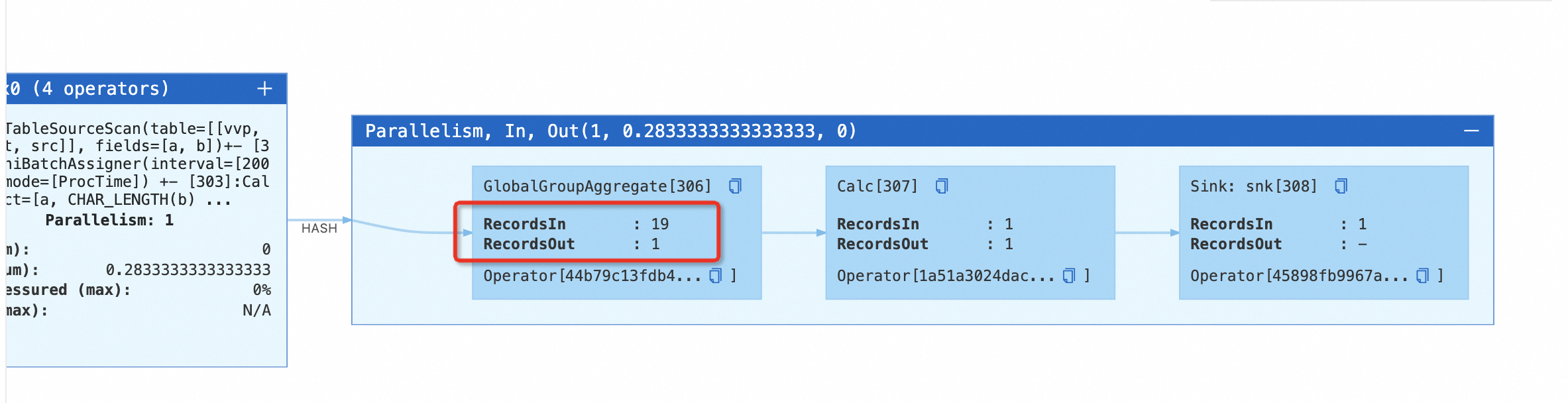
create temporary table src( a int, b string ) with ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.a.min' = '1', 'fields.a.max' = '1', 'fields.b.length' = '3' ); create temporary table snk( a int, max_length_b bigint ) with ( 'connector' = 'blackhole' ); insert into snk select a, max(CHAR_LENGTH(b)) from src group by a;在作業營運頁面的部署詳情頁運行參數配置地區其他配置中,設定
table.exec.mini-batch.enabled: true和table.exec.mini-batch.allow-latency: 2s參數,啟用Minibatch Aggregate最佳化。啟動作業。在狀態總覽頁簽下,您可以看到作業包含了MinibatchGlobalAggregate節點,點擊該節點上的“+”號,可以觀察到GlobalGroupAggregate節點在彙總結果不變的情況下,不向下遊發送資料。
停止該作業,在作業營運頁面的部署詳情頁運行參數配置地區其他配置中,添加參數
table.exec.agg.mini-batch.output-identical-enabled: true啟動作業。在狀態總覽頁簽下,您可以看到作業包含了MinibatchGlobalAggregate節點,點擊該節點上的“+”號,可以觀察到GlobalGroupAggregate節點在彙總結果不變的情況下,仍然向下遊發送資料。

table.exec.async-lookup.key-ordered-enabled
業務情境在通過維表Join做資料打寬時,通過開啟非同步模式通常可以獲得更好的吞吐效能。當前在維表Join中設定table.exec.async-lookup.output-mode參數和處理的輸入是否為更新流最終會對應到非同步I/O如下結果順序:
output-mode\處理的輸入 | 更新流 | 非更新流 |
ORDERED | 有序模式 | 有序模式 |
ALLOW_UNORDERED | 有序模式 | 無序模式 |
表格中更新流和ALLOW_UNORDERED的組合通過有序模式確保了正確性,但在一定程度上犧牲了吞吐效能。為最佳化該情境,推出了table.exec.async-lookup.key-ordered-enabled參數,既兼顧更新流的正確性語義,又保證非同步I/O的吞吐效能。對於流中具備相同更新鍵(可視為變更日誌主鍵)的訊息,將按照訊息進入運算元的先後順序進行處理。
有序(Ordered)模式:這種模式保持了流的順序,發出結果訊息的順序與觸發非同步請求的順序(訊息進入運算元的順序)相同。
無序(Unordered)模式:非同步請求一結束就立刻發出結果訊息。流中訊息的順序在經過非同步I/O運算元之後發生了改變。詳情請詳見非同步 I/O | Apache Flink。
應用情境
一段時間內流上相同更新鍵的訊息量較少(比如更新鍵為主鍵的情境,相同主鍵的資料更新頻率不高),同時在維表join時對基於更新鍵的處理有處理順序的需求。該最佳化可以保證基於更新鍵的資料處理順序。
在包含主鍵的CDC流中,通過維表join打寬寫入Sink(Sink的主鍵與Source的主鍵保持一致),且維表join的join key和主鍵不一致,維表側join key為主鍵。該最佳化會根據CDC主鍵(被推導為更新鍵)進行shuffle。相比同情境開啟SHUFFLE_HASH最佳化,在多並發的情況下,可以避免在Sink前產生SinkMaterializer 節點,從而消除因該節點引起的潛在效能問題,尤其可以消除長期運行時該節點產生的大state。有關SinkUpsertMaterializer請參見使用建議。
維表join的join key和主鍵不一致,維表側join key為主鍵,且之後存在rank節點,該最佳化會根據CDC主鍵(被推導為更新鍵)進行shuffle。相比同情境開啟SHUFFLE_HASH最佳化,可以避免UpdateFastRank退化為RetractRank。RetractRank如何能最佳化成UpdateFastRank請參見TopN最佳化技巧。
注意事項
當流上不存在更新鍵時,會將整行資料作為key。
在短時間內同一個更新鍵存在較頻繁的更新時輸送量會降低,因為針對同一個更新鍵的資料是嚴格按照順序處理的。
Key-Ordered模式相比原有非同步維表Join新增了Keyed State,開啟或關閉該模式會影響狀態相容性。
僅適用於VVR 8.0.10及以上版本且維表Join的輸入是更新流,配置
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'、table.exec.async-lookup.key-ordered-enabled='true'時才會生效。
取值說明
false(預設值):表示不開啟Key-Ordered模式。
true:表示開啟Key-Ordered模式。
使用樣本
以使用Hologres非同步維表Join為例,建立SQL流作業,複製如下測試SQL,部署作業。
Hologres連接器詳情請參見即時數倉Hologres。
create TEMPORARY table bid_source( auction BIGINT, bidder BIGINT, price BIGINT, channel VARCHAR, url VARCHAR, dateTime TIMESTAMP(3), extra VARCHAR, proc_time as proctime(), WATERMARK FOR dateTime AS dateTime - INTERVAL '4' SECOND ) with ( 'connector' = 'kafka', -- 非insert only流連接器 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' ); CREATE TEMPORARY TABLE users ( user_id STRING PRIMARY KEY NOT ENFORCED, -- 定義主鍵 user_name VARCHAR(255) NOT NULL, age INT NOT NULL ) WITH ( 'connector' = 'hologres', -- 支援非同步lookup功能連機器 'async' = 'true', 'dbname' = 'holo db name', --Hologres的資料庫名稱 'tablename' = 'schema_name.table_name', --Hologres用於接收資料的表名稱 'username' = 'access id', --當前阿里雲帳號的AccessKey ID 'password' = 'access key', --當前阿里雲帳號的AccessKey Secret 'endpoint' = 'holo vpc endpoint', --當前Hologres執行個體VPC網路的Endpoint ); CREATE TEMPORARY TABLE bh ( auction BIGINT, age int ) WITH ( 'connector' = 'blackhole' ); insert into bh SELECT bid_source.auction, u.age FROM bid_source JOIN users FOR SYSTEM_TIME AS OF bid_source.proc_time AS u ON bid_source.channel = u.user_id;在作業營運頁面的部署詳情頁簽運行參數配置地區其他配置中,設定
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'和table.exec.async-lookup.key-ordered-enabled='true'參數。啟動作業。在狀態總覽頁簽下,您可以看到作業async屬性KEY_ORDERED:true。
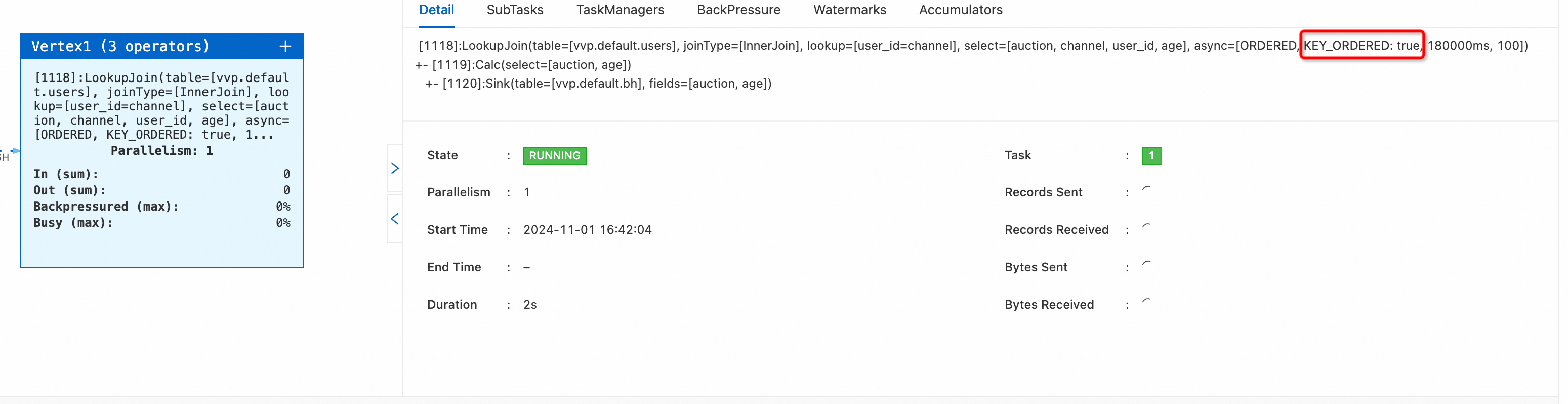
table.optimizer.window-join-enabled
該參數用於控制是否啟用視窗關聯操作。啟用後,Flink會按照視窗關聯方式最佳化對應的執行計畫,在視窗較小時,可以減少狀態開銷提升效能,另外相比於雙流JOIN,啟用視窗關聯可以避免對下遊輸出更新訊息,適用於業務情境中需要通過較小的時間視窗條件進行關聯的情境。
注意事項
取值說明
使用樣本
建立SQL流作業,複製如下測試SQL,直接通過SET語句設定table.optimizer.window-join-enabled參數為true,然後選中SQL文本右鍵執行,查看執行計畫結果。
SET 'table.optimizer.window-join-enabled' = 'true'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;可以看到執行計畫中Optimized Execution Plan部分包含了WindowJoin節點。
== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- WindowJoin(leftWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], rightWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], joinType=[InnerJoin], where=[(num = num0)], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0]) :- Exchange(distribution=[hash[num]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])修改SQL中的SET語句,設定table.optimizer.window-join-enabled參數為false或刪除該SET語句,然後選中SQL文本右鍵執行,查看修改後的執行計畫結果。
-- set to 'false' or remove this setting clause SET 'table.optimizer.window-join-enabled' = 'false'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;可以看到執行計畫中Optimized Execution Plan部分不再包含WindowJoin節點,變成了雙流Join。
== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- Join(joinType=[InnerJoin], where=[((num = num0) AND (window_start = window_start0) AND (window_end = window_end0))], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]) :- Exchange(distribution=[hash[num, window_start, window_end]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num, window_start, window_end]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])