本文圍繞Flink SQL即時資料處理中的Changelog事件亂序問題,分析了Flink SQL中Changelog事件亂序問題的原因,並提供瞭解決方案以及處理Changelog事件亂序的建議。以協助您更好地理解Changelog的概念和應用,更加高效地使用Flink SQL進行即時資料處理。
Flink SQL中的Changelog
Changelog介紹
在關聯式資料庫領域,MySQL使用binlog(二進位日誌)記錄資料庫中所有修改操作,包括INSERT、UPDATE和DELETE操作。類似地,Flink SQL中的Changelog主要記錄資料變化,以實現增量資料處理。
在MySQL中,binlog可以用於資料備份、恢複、同步和複製。通過讀取和解析binlog中的操作記錄,可以實現增量資料同步和複製。變更資料擷取(CDC)作為一種常用的資料同步技術,常被用於監控資料庫中的資料變化,並將其轉換為事件流進行即時處理。CDC工具可用於將關聯式資料庫中的資料變化即時傳輸到其他系統或資料倉儲,以支援即時分析和報告。當前常用的CDC工具包括Debezium和Maxwell。Flink通過FLINK-15331支援了CDC,可以即時地整合外部系統的CDC資料,並實現即時資料同步和分析。
Changelog事件產生和處理
Changelog介紹中提到的binlog和CDC是與Flink整合的外部Changelog資料來源,Flink SQL內部也會產生Changelog資料。為了區分事件是否為更新事件,我們將僅包含INSERT類型事件的Changelog稱為追加流或非更新流,而同時包含其他類型(例如UPDATE)事件的Changelog稱為更新流。Flink中的一些操作(如分組彙總和去重)可以產生更新事件,產生更新事件的操作通常會使用狀態,這類操作被稱為狀態運算元。需要注意的是,並非所有狀態運算元都支援處理更新流。例如,Over視窗彙總和Interval Join暫不支援更新流作為輸入。
Realtime Compute引擎VVR 6.0及以上版本的Query操作,對應的運行時運算元、是否支援處理更新流消費以及是否產生更新,詳情請參見Query操作運行時資訊說明。
Changelog的事件類型
FLINK-6047引入了回撤機制,使用INSERT和DELETE兩種事件類型(儘管資料來源僅支援INSERT事件),實現了流SQL運算元的累加式更新演算法。FLINK-16987以後,Changelog事件類型被重構為四種類型(如下),形成一個完整的Changelog事件類型體系,便於與CDC生態系統串連。
/**
* A kind of row in a Changelog.
*/
@PublicEvolving
public enum RowKind {
/**
* Insertion operation.
*/
INSERT,
/**
* Previous content of an updated row.
*/
UPDATE_BEFORE,
/**
* New content of an updated row.
*/
UPDATE_AFTER,
/**
* Deletion operation.
*/
DELETE
}Flink不使用包含UPDATE_BEFORE和UPDATE_AFTER的複合UPDATE事件類型的原因主要有兩個方面:
拆分的事件無論是何種事件類型(僅RowKind不同)都具有相同的事件結構,這使得序列化更簡單。如果使用複合UPDATE事件,那麼事件要麼是異構的,要麼是INSERT或DELETE事件對齊UPDATE事件(例如,INSERT事件僅含有UPDATE_AFTER,DELETE事件僅含有UPDATE_BEFORE)。
在分布式環境下,經常涉及資料shuffle(例如Join、彙總)。即使使用複合UPDATE事件,有時仍需將其拆分為單獨的DELETE和INSERT事件進行shuffle,例如下面的樣本。
樣本
下面是一個複合UPDATE事件必須拆分為DELETE和INSERT事件的情境樣本。本文後續也將圍繞此SQL作業樣本討論Changelog事件亂序問題並提供相應的解決方案。
-- CDC source tables: s1 & s2
CREATE TEMPORARY TABLE s1 (
id BIGINT,
level BIGINT,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
CREATE TEMPORARY TABLE s2 (
id BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
-- sink table: t1
CREATE TEMPORARY TABLE t1 (
id BIGINT,
level BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
)WITH (...);
-- join s1 and s2 and insert the result into t1
INSERT INTO t1
SELECT
s1.*, s2.attr
FROM s1 JOIN s2
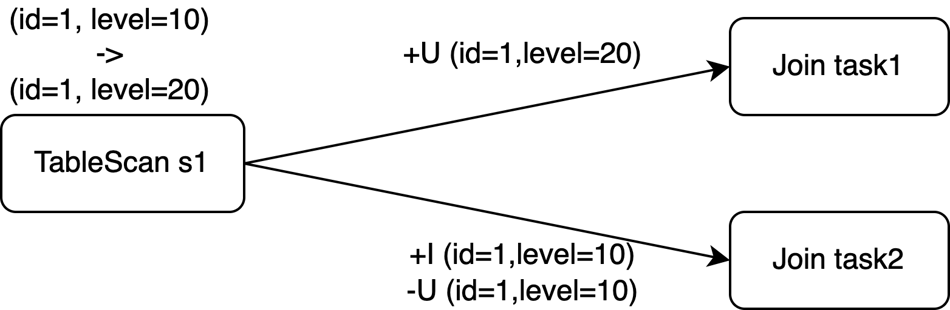
ON s1.level = s2.id;假設源表s1中id為1的記錄的Changelog在時間t0插入(id=1, level=10),然後在時間t1將該行更新為(id=1, level=20)。這對應三個拆分事件:
s1 | 事件類型 |
+I(id=1,level=10) | INSERT |
-U(id=1,level=10) | UPDATE_BEFORE |
+U(id=1,level=20) | UPDATE_AFTER |
源表s1的主鍵是id,但Join操作需要按level列進行shuffle(見子句ON)。
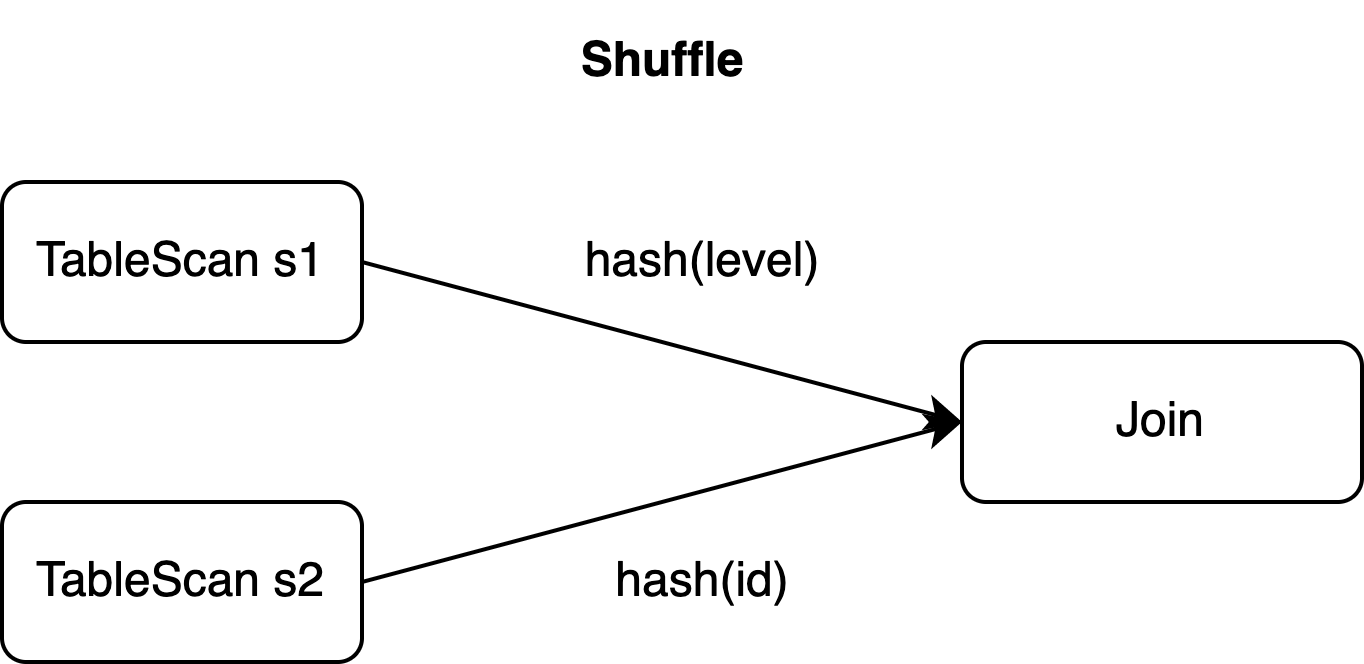
如果Join運算元的並發數為2,那麼以上三個事件可能會被發送到兩個任務中。即使使用複合UPDATE事件,它們也需要在shuffle階段拆分,來保證資料的平行處理。
Changelog事件亂序問題
亂序原因
假設樣本中表s2已有兩行資料進入Join運算元(+I(id=10,attr=a1),+I(id=20,attr=b1)),Join運算子從表s1新接收到三個Changelog事件。在分布式環境中,實際的Join在兩個任務上平行處理,下遊運算元(樣本中為Sink任務)接收的事件序列可能情況如下所示。
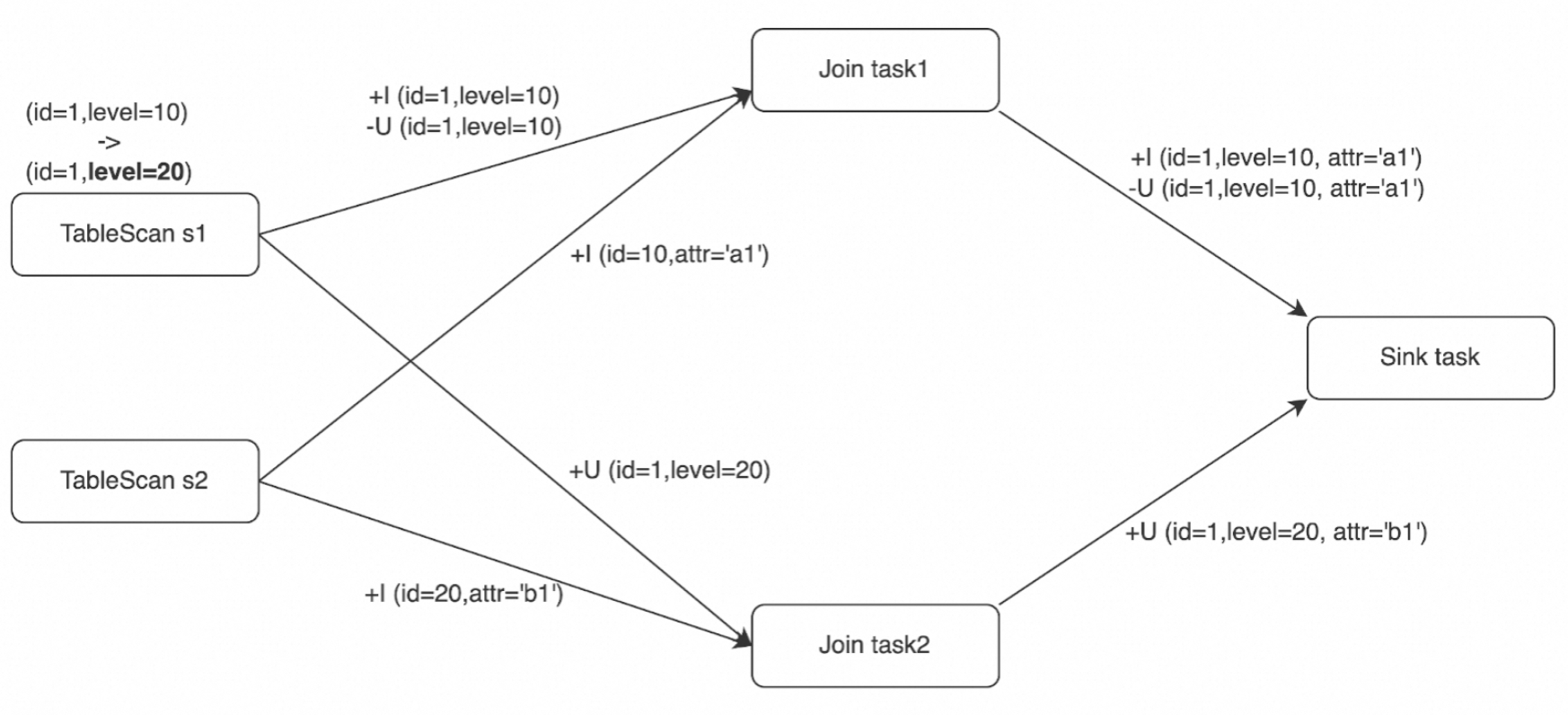
情況1 | 情況2 | 情況3 |
+I (id=1,level=10,attr='a1') -U (id=1,level=10,attr='a1') +U (id=1,level=20,attr='b1') | +U (id=1,level=20,attr='b1') +I (id=1,level=10,attr='a1') -U (id=1,level=10,attr='a1') | +I (id=1,level=10,attr='a1') +U (id=1,level=20,attr='b1') -U (id=1,level=10,attr='a1') |
情況1的事件序列與順序處理中的事件序列相同。情況2和情況3顯示了Changelog事件在Flink SQL中到達下遊運算元時的亂序情況。亂序情況可能會導致不正確的結果。在樣本中,結果表聲明的主鍵是id,外部儲存進行upsert更新時,在情況2和3中,如果沒有其他措施,將從外部儲存不正確地刪除id=1的行,而期望的結果是(id=1, level=20, attr='b1')。
使用SinkUpsertMaterializer解決
在樣本中,Join操作產生更新流,其中輸出包含INSERT事件(+I)和UPDATE事件(-U和+U),如果不正確處理,亂序可能會導致正確性問題。
唯一鍵與upsert鍵
唯一鍵是指SQL操作後滿足唯一約束的列或列組合。在本樣本中(s1.id)、(s1.id, s1.level)和(s1.id, s2.id)這三組都是唯一鍵。
Flink SQL的Changelog參考了binlog機制,但實現方式更加簡潔。Flink不再像binlog一樣記錄每個更新的時間戳記,而是通過planner中的全域分析來確定主鍵接收到的更新記錄的排序。如果某個鍵維護了唯一鍵的排序,則對應的鍵稱為upsert鍵。對於存在upsert鍵的情況,下遊運算元可以正確地按照更新記錄的順序接收upsert鍵的值。如果shuffle操作破壞了唯一鍵的排序,upsert鍵將為空白,此時下遊運算元需要使用一些演算法(例如計數演算法)來實現最終的一致性。
在樣本中,表s1中的行根據列level進行shuffle。Join產生多個具有相同s1.id的行,因此Join輸出的upsert鍵為空白(即Join後唯一鍵上不存在排序)。此時,Flink需儲存所有輸入記錄,然後檢查比較所有列以區分更新和插入。
此外,結果表的主鍵為列id。Join輸出的upsert鍵與結果表的主鍵不匹配,需要進行一些處理將Join輸出的行進行正確轉換為結果表所需的行。
SinkUpsertMaterializer
根據唯一鍵與upsert鍵的內容,當Join輸出的是更新流且其upsert鍵與結果表主鍵不匹配時,需要一個中間步驟來消除亂序帶來的影響,以及基於結果表的主鍵產生新的主鍵對應的Changelog事件。Flink在Join運算元和下遊運算元之間引入了SinkUpsertMaterializer運算元(FLINK-20374)。
結合亂序原因中的Changelog事件,可以看到Changelog事件亂序遵循著一些規則。例如,對於一個特定的upsert鍵(或upsert鍵為空白則表示所有列),事件ADD(+I、+U)總是在事件RETRACT(-D、-U)之前發生;即使涉及到資料shuffle,相同upsert鍵的一對匹配的Changelog事件也總是被相同的任務處理。這些規則也說明了為什麼樣本僅存在亂序原因中三個Changelog事件的組合。
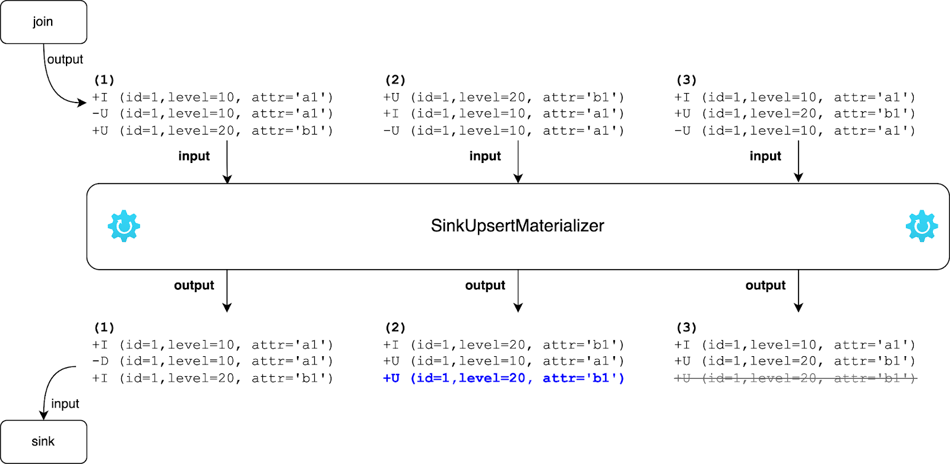
SinkUpsertMaterializer就是基於上述規則實現的,其工作原理如下圖所示。SinkUpsertMaterializer在其狀態中維護了一個RowData列表。當SinkUpsertMaterializer被觸發,在處理輸入行時,它根據推斷的upsert鍵或整個行(如果upsert鍵為空白)檢查狀態列表中是否存在相同的行。在ADD的情況下添加或更新狀態中的行,在RETRACT的情況下從狀態中刪除行。最後,它根據結果表的主鍵產生Changelog事件,更多詳細資料請參見SinkUpsertMaterializer原始碼。
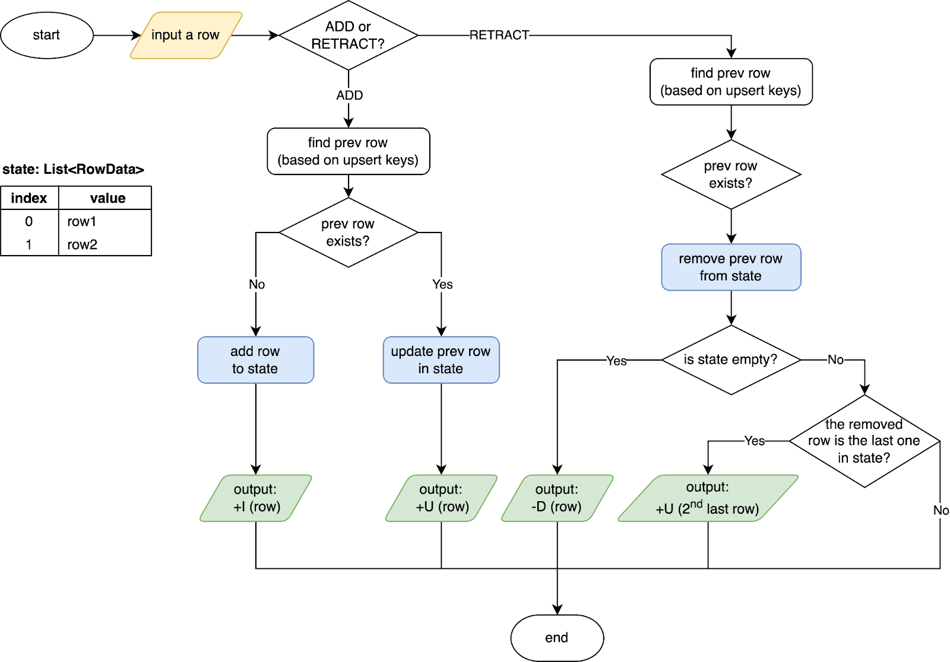
通過SinkUpsertMaterializer,將樣本中Join運算元輸出的Changelog事件處理並轉換為結果表主鍵對應的Changelog事件,結果如下圖所示。根據SinkUpsertMaterializer的工作原理,在情況2中,處理-U(id=1,level=10,attr='a1')時,會將最後一行從狀態中移除,並向下遊發送倒數第二行;在情況3中,當處理+U (id=1,level=20,attr='b1')時,SinkUpsertMaterializer會將其原樣發出,而當處理-U(id=1,level=10,attr='a1')時,將從狀態中刪除行而不發出任何事件。最終,通過SinkUpsertMaterializer運算元情況2和3也會得到期望結果 (id=1,level=20,attr='b1')。
常見情境
觸發 SinkUpsertMaterializer運算元的常見情境如下:
結果表定義主鍵,而寫入該結果表的資料丟失了唯一性。通常包括但不限於以下操作:
源表缺少主鍵,而結果表卻設定了主鍵。
向結果表插入資料時,忽略了主鍵列的選擇,或錯誤地使用了源表的非主鍵資料填充結果表的主鍵。
源表的主鍵資料在轉換或經過分組彙總後出現精度損失。例如,將BIGINT類型降為INT類型。
對源表的主鍵列或經過分組彙總之後的唯一鍵進行了運算,如資料拼接或將多個主鍵合并為單一欄位。
CREATE TABLE students ( student_id BIGINT NOT NULL, student_name STRING NOT NULL, course_id BIGINT NOT NULL, score DOUBLE NOT NULL, PRIMARY KEY(student_id) NOT ENFORCED ) WITH (...); CREATE TABLE performance_report ( student_info STRING NOT NULL PRIMARY KEY NOT ENFORCED, avg_score DOUBLE NOT NULL ) WITH (...); CREATE TEMPORARY VIEW v AS SELECT student_id, student_name, AVG(score) AS avg_score FROM students GROUP BY student_id, student_name; -- 將分組彙總後的key進行拼接當作主鍵寫入結果表,但實際上已經丟失了唯一性限制式 INSERT INTO performance_report SELECT CONCAT('id:', student_id, ',name:', student_name) AS student_info, avg_score FROM v;
結果表的確立依賴於主鍵的設定,然而在資料輸入過程中,其原有的順序性卻遭到破壞。例如本文的樣本,雙流Join時若一方資料未通過主鍵與另一方關聯,而結果表的主鍵列又是基於另一方的主鍵列產生的,這便可能導致資料順序的混亂。
明確配置了
table.exec.sink.upsert-materialize參數為'force',配置詳情請參見下方的參數設定。
使用建議
正如前面所提到的,SinkUpsertMaterializer在其狀態中維護了一個RowData列表。這可能會導致狀態過大並增加狀態訪問I/O的開銷,最終影響作業的輸送量。因此,應盡量避免使用它。
參數設定
SinkUpsertMaterializer可以通過table.exec.sink.upsert-materialize進行配置:
auto(預設值):Flink會從正確性的角度推斷出亂序是否存在,如果必要的話,則會添加SinkUpsertMaterializer。
none:不使用。
force:強制使用。即便結果表的DDL未指定主鍵,最佳化器也會插入SinkUpsertMaterializer狀態節點,以確保資料的物理化處理。
需要注意的是,設定為auto並不一定意味著實際資料是亂序的。例如,使用grouping sets文法結合coalesce轉換null值時,SQL planner可能無法確定由grouping sets與coalesce組合產生的upsert鍵是否與結果表的主鍵匹配。出於正確性的考慮,Flink將添加SinkUpsertMaterializer。如果一個作業可以在不使用SinkUpsertMaterializer的情況下產生正確的輸出,建議設定為none。
避免使用SinkUpsertMaterializer
為了避免使用SinkUpsertMaterializer,您可以:
確保在進行去重、分組彙總等操作時,所使用的分區鍵要與結果表的主鍵相同。
如果單並發可以處理對應的資料量,改成單並發可以避免處理過程中產生額外的亂序(原始輸入的亂序除外),此時在作業參數中設定table.exec.sink.upsert-materialize為 none 顯式關閉產生 SinkUpsertMaterializer 節點。
如果下遊運算元與上遊的去重、分組彙總或其他運算元相連,且在VVR 6.0以下版本中沒有出現資料準確性問題,那麼可以參考原資源配置,並將table.exec.sink.upsert-materialize更改為none,將作業遷移到Realtime Compute引擎VVR 6.0及以上版本,引擎升級請參見作業引擎版本升級。
若必須使用SinkUpsertMaterializer,需注意以下事項:
避免在寫入結果表時添加由非確定性函數(如CURRENT_TIMESTAMP、NOW)產生的列,可能會導致Sink輸入在沒有upsert鍵時,SinkUpsertMaterializer的狀態異常膨脹。
如果已出現SinkUpsertMaterializer運算元存在大狀態的情況並影響了效能,請考慮增加作業並發度,操作步驟請參見配置作業資源。
使用注意事項
SinkUpsertMaterializer雖然解決了Changelog事件亂序問題,但可能引起持續狀態增加的問題。主要原因有:
狀態有效期間過長(未設定或設定過長的狀態TTL)。但如果TTL設定過短,可能會導致FLINK-29225中描述的問題,即本應刪除的髒資料仍保留在狀態中。當訊息的DELETE事件與其ADD事件之間的時間間隔超過配置的TTL時會出現這種情況,此時,Flink會在日誌中產生一條如下警告資訊。
int index = findremoveFirst(values, row); if (index == -1) { LOG.info(STATE_CLEARED_WARN_MSG); return; }您可以根據業務需要設定合理的TTL,具體操作請參見運行參數配置,Realtime ComputeVVR 8.0.7及以上版本,支援為不同運算元設定不同TTL,進一步節約大狀態作業的使用資源,具體操作請參見配置運算元並發、Chain策略和TTL。
當SinkUpsertMaterializer輸入的更新流無法推匯出upsert鍵,並且更新流中存在非確定性列時,將無法正確刪除歷史資料,這會導致狀態持續增加。
相關文檔
Realtime Compute引擎版本和Apache Flink版本對應關係,詳情請參見功能發布記錄。