JindoTable通過Native Engine,支援對Spark、Hive或Presto上ORC或Parquet格式檔案進行加速。本文為您介紹如何開啟native查詢加速,以提升Spark、Hive和Presto的效能。
前提條件
已建立叢集,且ORC或Parquet檔案已存放至JindoFS或OSS,建立叢集詳情,請參見建立叢集。
使用限制
不支援對Binary類型檔案進行加速。
不支援分區列的值儲存在檔案中的分區表。
不支援EMR-5.X系列及後續版本的E-MapReduce叢集。
不支援代碼spark.read.schema(userDefinedSchema)。
支援Date類型區間為1400-01-01到9999-12-31。
同一個表中查詢列不支援區分大小寫。例如,NAME和name兩個列在同一個表中無法使用查詢加速。
Spark、Hive和Presto服務支援的引擎和儲存格式如下所示。
引擎
ORC
Parquet
Spark2
支援
支援
Spark3
支援
支援
Presto
支援
支援
Hive2
不支援
支援
Hive3
不支援
支援
Spark、Hive和Presto服務支援的引擎和隱藏檔系統如下所示。
引擎
OSS
JFS
HDFS
Spark2
支援
支援
支援
Presto
支援
支援
支援
Hive2
支援
支援
不支援
Hive3
支援
支援
不支援
提升Spark效能
開啟JindoTable ORC或Parquet加速。
說明因為查詢加速使用的是堆外記憶體,所以在Spark任務中建議添加配置
--conf spark.executor.memoryOverhead=4g,提高Spark申請額外資源用來進行加速。Spark讀取ORC或Parquet時,需要使用DataFrame API或者Spark-SQL。
全域設定
進入詳情頁面。
在頂部功能表列處,根據實際情況選擇地區和資源群組。
單擊上方的叢集管理頁簽。
在叢集管理頁面,單擊相應叢集所在行的詳情。
修改配置。
在左側導覽列,選擇。
在Spark服務頁面,單擊配置頁簽。
在搜尋地區,搜尋參數spark.sql.extensions,修改參數值為io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtension。
儲存配置。
單擊儲存。
在確認修改對話方塊中,輸入執行原因,單擊確定。
重啟ThriftServer。
在右上方選擇。
在執行叢集操作對話方塊中,輸入執行原因,單擊確定。
在確認對話方塊中,單擊確定。
Job層級設定
使用spark-shell或者spark-sql時,可以添加Spark的啟動參數。
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtension作業詳情請參見Spark Shell作業配置或Spark SQL作業配置。
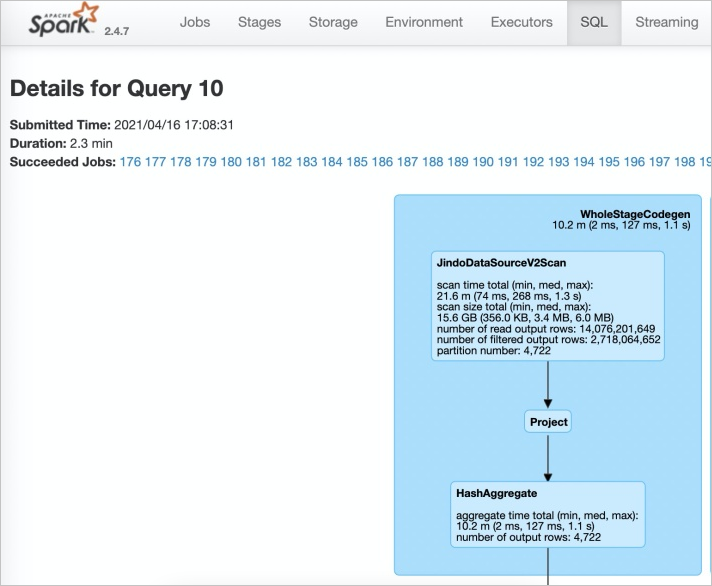
檢查開啟情況。
登入Spark History Server UI頁面。
在Spark的SQL頁面,查看執行任務。
當出現JindoDataSourceV2Scan時,表示開啟成功。否則,請排查步驟1中的操作。
提升Presto效能
Presto查詢並發較高,且查詢加速使用堆外記憶體,因此使用查詢加速時記憶體配置必須大於10 GB。
因為Presto已經內建JindoTable native加速的catalog: hive-acc,所以您可以直接使用catalog: hive-acc來啟用查詢加速。
樣本如下。
presto --server emr-header-1:9090 --catalog hive-acc --schema default目前使用Presto查詢加速功能時,暫不支援讀取複雜的資料類型,例如Map、Struct或Array。
提升Hive效能
如果您對作業穩定性要求較高時,建議不要開啟native查詢加速。
您可以通過以下兩種方式提升Hive效能:
控制台方式
在控制台Hive服務的配置頁面,搜尋並修改自訂參數hive.jindotable.native.enabled為true,儲存配置後,重啟服務使配置生效,此方式適用於Hive on MR和Hive on Tez。

命令列方式
您可以直接在命令列中設定
hive.jindotable.native.enabled為true來啟用查詢加速。因為EMR-3.35.0及後續版本已經內建JindoTable Parquet加速的外掛程式,所以您可以直接設定該參數。set hive.jindotable.native.enabled=true;
目前使用Hive查詢加速功能時,暫不支援讀取複雜的資料類型,例如Map、Struct或Array。