持久記憶體支援的使用方式和執行個體規格有關,本文介紹如何將持久記憶體配置為本地碟以及可以配置為本地碟的持久記憶體型執行個體(ecs.re6p規格和ecs.i4p規格)使用llpl庫分配記憶體池失敗的解決方案。
前提條件
持久記憶體適用於特定的執行個體規格和鏡像版本,要求如下:
執行個體規格
作為記憶體使用量的規格:ecs.re6p-redis
重要作為記憶體使用量時:
購買後無需進行初始化即可使用。
無持久化特性,停機或重啟後,資料會丟失。
作為本地碟使用的規格:ecs.re6p、ecs.i4p
重要作為本地碟使用時:
購買後需要進行盤的初始化,具體操作,請參見將持久記憶體配置為一塊本地碟。
具備持久化特性,但作為本地碟儲存資料有遺失資料的風險,建議您做好必要的資料備份。關於本地碟的更多資訊,請參見本地碟。
鏡像:
Alibaba Cloud Linux 2
CentOS 7.6及更高版本
Ubuntu 18.04、Ubuntu 20.04
背景資訊
持久記憶體的訪問速度比普通記憶體慢,但性價比更高,可以作為本機存放區使用。作為本機存放區使用時,在停機或重啟後,持久記憶體中的資料不會丟失。持久記憶體的使用方式:
作為記憶體使用量:您可以將部分原本存放在普通記憶體中的資料存放到持久記憶體中,例如對訪問速度要求較低的非熱點資料。持久記憶體容量大,單GiB價格更實惠,可以協助您大幅降低單GiB記憶體的整體擁有成本(TCO)。
作為本地碟使用:支援塊資料讀寫,IO效能極高,讀寫延時低至170 ns。因此,您可以為需要更高穩定RT(回應時間)的核心應用程式資料庫選用持久記憶體。您也可以將原有的NVMe SSD盤換成基於持久記憶體的本地碟,提升IOPS和頻寬、降低延時,解決效能瓶頸。
持久記憶體中資料的可靠性取決於物理伺服器和持久記憶體裝置的可靠性,因此存在單點故障風險。建議您在應用程式層做好資料冗餘,將需要長期儲存的業務資料存放區到雲端硬碟上,以保證應用資料的可靠性。
將持久記憶體配置為一塊本地碟
本文樣本中使用的配置如下:
執行個體規格:ecs.re6p.2xlarge
鏡像:Alibaba Cloud Linux 2.1903 LTS 64位
登入已建立的ECS執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
分別執行以下命令,安裝持久記憶體管理工具並清理namespace和label配置。
sudo yum install -y ndctl daxctl sudo ndctl disable-namespace all && sudo ndctl destroy-namespace all #清理namespace sudo ndctl disable-region all && sudo ndctl zero-labels all && sudo ndctl enable-region all #清理label配置查看持久記憶體大小。
ndctl list -R如下圖所示,size值即為持久記憶體大小。

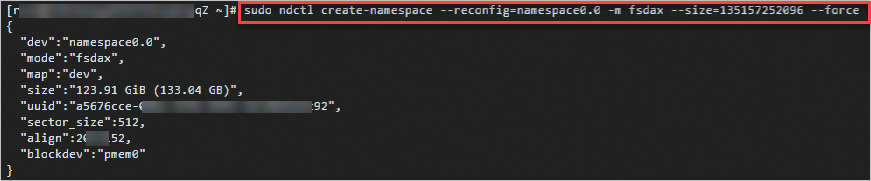
將使用模式配置為fsdax。
sudo ndctl create-namespace --reconfig=namespace0.0 -m fsdax --size={region-size} --force說明{region-size}請替換成上一步查詢的size值。
分別執行以下命令,格式化並掛載磁碟。
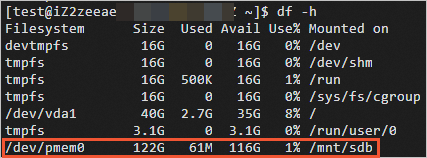
sudo mkfs -t ext4 /dev/pmem0 sudo mkdir /mnt/sdb sudo mount -o dax,noatime /dev/pmem0 /mnt/sdb查看已掛載的磁碟。
測試i4p執行個體本地碟效能
本文樣本中使用的配置如下:
執行個體規格:ecs.i4p.2xlarge
鏡像:Alibaba Cloud Linux 2.1903 LTS 64位
測試載入器:fio,FIO(Flexible I/O Tester)是一個開源的、強大的I/O效能測試工具,可以用來對存放裝置進行隨機讀寫、順序讀寫等負載測試。
直接使用FIO壓測會導致資料丟失。因此在測試本地碟效能前,請確保不要將含有資料的本地碟作為測試對象。
在測試本地碟效能前,請確保已經對測試對象進行資料備份。具體操作,請參見備份本地碟檔案。
遠端連線ECS執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
運行以下命令,安裝測試載入器FIO。
sudo yum install -y ndctl daxctl ipmctl libpmem librpmem libpmemblk libpmemlog libpmemobj libpmempool pmempool fio測試本地碟效能。
測試命令樣本,請參見測試IOPS,測試輸送量,測試訪問時延。
重要如果連續測試,請在每次測試後執行
sudo rm /mnt/sdb/* -rf命令清理本地碟上一輪遺留的測試結果,以便為下一輪測試準備乾淨的環境。基於持久記憶體的本地碟與本地NVMe SSD盤、ESSD雲端硬碟的效能對比如下表所示。
說明表中列出的效能層級供您參考,單次測試的具體結果請以您自行測試時的結果為準。
指標
持久記憶體(容量128 GiB)
NVMe SSD(容量1788 GiB)
ESSD雲端硬碟(容量800 GiB,效能層級PL1)
讀頻寬
8~10 GByte/s層級
2~3 GByte/s層級
0.2~0.3 GByte/s層級
讀寫頻寬
8~10 GByte/s層級
1~2 GByte/s層級
0.2~0.3 GByte/s層級
寫頻寬
2~3 GByte/s層級
1~2 GByte/s層級
0.2~0.3 GByte/s層級
讀IOPS
100萬層級
50萬層級
2~3萬層級
讀寫IOPS
100萬層級
30萬層級
2~3萬層級
寫IOPS
100萬層級
30萬層級
2~3萬層級
讀延時
300~400納秒層級
100000納秒層級
250000納秒層級
寫延時
300~400納秒層級
20000納秒層級
150000納秒層級
測試IOPS
順序讀
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=8 --iodepth=1 --rw=read --bs=4k --size=8GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split順序寫
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=8 --iodepth=1 --rw=write --bs=4k --size=1GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split隨機讀
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=8 --iodepth=1 --rw=randread --bs=4k --size=8GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split隨機寫
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=8 --iodepth=1 --rw=randwrite --bs=4k --size=1GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split
測試輸送量
順序讀
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=96 --iodepth=1 --rw=read --bs=64k --size=1GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split順序寫
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=1 --numjobs=8 --iodepth=1 --rw=write --bs=64k --size=1GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split隨機讀
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=96 --iodepth=1 --rw=randread --bs=64k --size=1GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split隨機寫
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=8 --numjobs=96 --iodepth=1 --rw=randwrite --bs=64k --size=1GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split
測試訪問時延
順序讀
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=1 --numjobs=1 --iodepth=1 --rw=read --bs=4k --size=8GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split順序寫
sudo fio --name=test --directory=/mnt/sdb --ioengine=libpmem --direct=1 --thread=1 --numjobs=1 --iodepth=1 --rw=write --bs=4k --size=8GB --norandommap=1 --randrepeat=0 --invalidate=1 --iodepth_batch=1 --sync=1 --scramble_buffers=0 --numa_cpu_nodes=0 --numa_mem_policy=bind:0 --cpus_allowed_policy=split
使用llpl庫分配記憶體池失敗
問題現象
可以配置為本地碟的ECS持久記憶體型執行個體(ecs.re7p規格和ecs.i4p規格)使用llpl庫分配記憶體池失敗,提示Failed to create heap. Cannot read unsafe shutdown count**錯誤資訊。
可能原因
llpl源碼預設啟用unsafe shutdown detection,而非易失性儲存空間NVM虛擬化後不支援啟用,導致問題出現。更多資訊,請參見llpl。
解決方案
在llpl源碼中關閉unsafe shutdown detection,操作步驟如下:
在llpl源碼的src/main/cpp/com_intel_pmem_llpl_AnyHeap.cpp檔案中添加如下代碼。
int sds_write_value=0; pmemobj_ctl_set(NULL,"sds.at_create",&sds_write_value)代碼添加完畢後,結果如下圖所示。

登入ECS執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
執行如下命令,使用llpl庫運行測試案例。
mvn clean && mvn test -Dtest.heap.path=/mnt/sdb如果未出現該錯誤提示,表示您可以繼續分配記憶體池。