MaxCompute資料來源作為資料中樞,為您提供讀取和寫入資料至MaxCompute的雙向通道。
功能介紹
DataWorks的MaxCompute資料來源可使用Tunnel Endpoint地址訪問相應MaxCompute專案的Tunnel服務,從而通過上傳、下載等方式同步該專案的資料,使用Tunnel服務時的上傳與下載會涉及DownloadTable操作。
2023年12月11日之後建立的MaxCompute資料來源,若資料來源所在的DataWorks服務與需要訪問的MaxCompute專案不在同一地區,則無法直接通過Tunnel Endpoint地址同步MaxCompute專案的資料。該情境下,您需先購買雲企業網,連通DataWorks服務與MaxCompute專案的網路,網路連通後才可跨地區執行資料同步操作。雲企業網的介紹及相關操作,請參見雲企業網。
離線讀
MaxCompute Reader支援讀取分區表、非分區表,不支援讀取虛擬視圖,也不支援同步外部表格。
離線讀MaxCompute分區表時,不支援直接對分區欄位進列欄位映射配置,如需同步分區欄位值,可添加一行自訂欄位,並通過手動填寫分區名稱的方式,再進列欄位映射。
分區指定方式支援通過調度參數進行自動替換,滿足按調度時間同步對應分區的情境。
例如,分區表t0的欄位包含id、name兩個欄位,一級分區為pt,二級分區為ds。讀取t0的pt=<業務日期>,ds=hangzhou分區資料時,您需要在配置資料來源時指定分區值為pt=${調度參數},ds=hangzhou,後續欄位對應配置時進行id、name欄位的映射配置。
支援將分區欄位通過添加一行自訂欄位的方式,寫入目標表。
MaxCompute Reader支援使用WHERE進行資料過濾。
離線寫
當資料有null值時,MaxCompute Writer不支援VARCHAR類型。
如果寫入的表為
DeltaTable,請將同步完成才可見設為是,否則在並發大於1的情境下,任務將會報錯。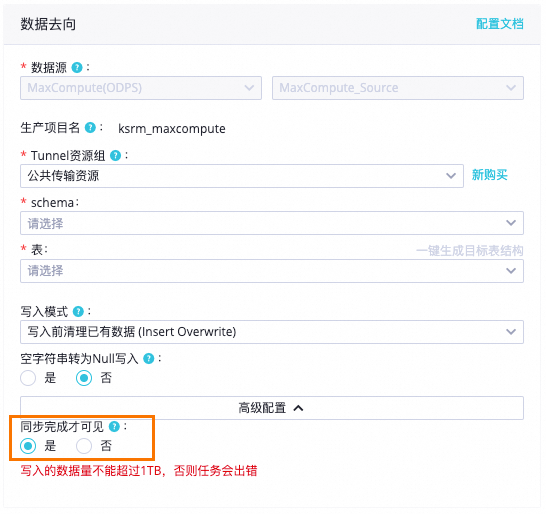
即時寫
即時資料同步任務支援使用Serverless資源群組(推薦)和獨享Data Integration資源群組。
即時資料同步任務暫不支援同步沒有主鍵的表。
當即時同步至MaxCompute預設資料來源(一般為
odps_first)時,預設使用臨時AK進行同步,臨時AK超過7天會自動到期,同時,將導致任務運行失敗。平台檢測到臨時AK導致任務失敗時會自動重啟任務,如果任務配置了該類型的監控警示,您將會收到警示資訊。一鍵即時同步至MaxCompute任務配置當天僅能查詢歷史全量資料,增量資料需要等待第二天merge完成後才可在MaxCompute查詢。
一鍵即時同步至MaxCompute任務每天會產生一個全量分區,為避免資料過多佔用儲存資源,本方案任務自動建立的MaxCompute表,預設生命週期為30天。如果時間長度不滿足您的業務需求,可以在配置同步任務時單擊對應的MaxCompute表名修改生命週期。
Data Integration使用MaxCompute引擎同步資料通道進行資料上傳和下載(同步資料通道SLA詳情請參見Data Transmission Service(上傳)情境與工具),請根據MaxCompute引擎同步資料通道SLA評估資料同步業務技術選型。
一鍵即時同步至MaxCompute,按執行個體模式同步時,獨享Data Integration資源群組規格最低需要為8C16G。
僅支援與當前工作空間同地區的自建MaxCompute資料來源,跨地區的MaxCompute專案在測試資料來源服務連通性時可以正常連通,但同步任務執行時,在MaxCompute建表階段會報引擎不存在的錯誤。
MaxCompute作為整庫同步的目標端時,若表類型為普通表,僅支援使用整庫全增量(准即時)任務,若表類型為Delta Table,整庫即時和整庫全增量(准即時)任務均可支援。
說明使用自建MaxCompute資料來源時,DataWorks專案仍然需要綁定MaxCompute引擎,否則將無法建立MaxCompute SQL節點,導致全量同步標記done節點建立失敗。
注意事項
如果目標表列沒有配置和源端的列映射,則同步任務執行完成後,此列值為空白,即使此目標列建表時指定了預設值,列值仍為空白。
支援的欄位類型
支援MaxCompute的1.0資料類型、2.0資料類型、Hive相容資料類型。不同資料類型版本支援的欄位類型詳情如下。
1.0資料類型支援的欄位
欄位類型 | 離線讀 | 離線寫 | 即時寫 |
BIGINT | 支援 | 支援 | 支援 |
DOUBLE | 支援 | 支援 | 支援 |
DECIMAL | 支援 | 支援 | 支援 |
STRING | 支援 | 支援 | 支援 |
DATETIME | 支援 | 支援 | 支援 |
BOOLEAN | 支援 | 支援 | 支援 |
ARRAY | 支援 | 支援 | 支援 |
MAP | 支援 | 支援 | 支援 |
STRUCT | 支援 | 支援 | 支援 |
2.0資料類型、Hive相容資料類型支援的欄位
欄位類型 | 離線讀(MaxCompute Reader) | 離線寫(MaxCompute Writer) | 即時寫 |
TINYINT | 支援 | 支援 | 支援 |
SMALLINT | 支援 | 支援 | 支援 |
INT | 支援 | 支援 | 支援 |
BIGINT | 支援 | 支援 | 支援 |
BINARY | 支援 | 支援 | 支援 |
FLOAT | 支援 | 支援 | 支援 |
DOUBLE | 支援 | 支援 | 支援 |
DECIMAL(pecision,scale) | 支援 | 支援 | 支援 |
VARCHAR(n) | 支援 | 支援 | 支援 |
CHAR(n) | 不支援 | 支援 | 支援 |
STRING | 支援 | 支援 | 支援 |
DATE | 支援 | 支援 | 支援 |
DATETIME | 支援 | 支援 | 支援 |
TIMESTAMP | 支援 | 支援 | 支援 |
BOOLEAN | 支援 | 支援 | 支援 |
ARRAY | 支援 | 支援 | 支援 |
MAP | 支援 | 支援 | 支援 |
STRUCT | 支援 | 支援 | 支援 |
資料類型轉換說明
MaxCompute Reader針對MaxCompute的類型轉換列表,如下所示。
類型分類 | Data Integration配置類型 | 資料庫資料類型 |
整數類 | LONG | BIGINT、INT、TINYINT和SMALLINT |
布爾類 | BOOLEAN | BOOLEAN |
日期時間類 | DATE | DATETIME、TIMESTAMP和DATE |
浮點類 | DOUBLE | FLOAT、DOUBLE和DECIMAL |
二進位類 | BYTES | BINARY |
複雜類 | STRING | ARRAY、MAP和STRUCT |
如果資料轉換失敗,或資料寫入至目的端資料來源失敗,則將資料視為髒資料,您可以配合髒資料限制閾值使用。
資料同步前準備
讀取或寫入MaxCompute表資料時,您可以根據需要選擇是否開啟相關屬性。
串連MaxCompute並開啟專案級配置
登入MaxCompute用戶端,詳情請參見使用本地用戶端(odpscmd)串連。
開啟MaxCompute專案級相關配置:請確認是否已擁有對應的操作許可權,您可使用Project Owner帳號執行相關操作,關於MaxCompute許可權說明,詳情請參見角色規劃。
開啟ACID屬性
您可以使用Project Owner帳號在用戶端執行以下命令開啟acid屬性,關於MaxCompute ACID語義說明,詳情請參見ACID語義。
setproject odps.sql.acid.table.enable=true;(可選)開啟2.0資料類型
如果需要使用MaxCompute資料2.0類型中的timestamp類型,您需要使用Project Owner帳號在用戶端執行以下命令開啟資料2.0。
setproject odps.sql.type.system.odps2=true;(可選)帳號授權
工作空間綁定MaxCompute計算資源時,預設將在DataWorks產生一個MaxCompute資料來源,在當前工作空間可使用該資料來源進行資料同步。如果您需要在其他工作空間同步當前工作空間的MaxCompute資料來源,您需要確保其他工作空間的資料來源所指定的訪問帳號具有對該MaxCompute的存取權限。若涉及到跨主帳號授權,可參考:跨帳號授權(MaxCompute、Hologres)。
建立MaxCompute資料來源
進行資料同步任務開發前,您需要在DataWorks上將MaxCompute專案建立為MaxCompute資料來源。建立MaxCompute資料來源的詳情操作,請參見綁定MaxCompute計算資源。
標準模式的工作空間支援資料來源隔離功能,您可以分別添加並隔離開發環境和生產環境的資料來源,以保護您的資料安全。詳情請參見資料來源開發和生產環境隔離。
若工作空間中名為odps_first的MaxCompute資料來源非人為在資料來源介面建立,則該資料來源為資料來源改版前,您當前工作空間綁定的第一個MaxCompute引擎預設建立的資料來源。進行資料同步時,如選擇此資料來源,則表示您要將資料讀取或寫入至該MaxCompute引擎專案中。
您可在資料來源配置頁面,查看資料來源使用的MaxCompute專案名稱,確認資料最終讀取或寫入至哪一個MaxCompute專案。詳情請參見資料來源管理。
資料同步任務開發
資料同步任務的配置入口和通用配置流程可參見下文的配置指導。
單表離線同步任務配置指導
指令碼模式配置的全量參數和指令碼Demo請參見下文的附錄:指令碼Demo與參數說明。
單表即時同步任務配置指導
整庫同步任務配置指導
操作流程請參見整庫離線同步任務、整庫即時同步任務、整庫全增量(准即時)任務。
常見問題
更多其他Data Integration常見問題請參見Data Integration。
附錄:指令碼Demo與參數說明
離線任務指令碼配置方式
如果您配置離線任務時使用指令碼模式的方式進行配置,您需要按照統一的指令碼格式要求,在任務指令碼中編寫相應的參數,詳情請參見指令碼模式配置,以下為您介紹指令碼模式下資料來源的參數配置詳情。
Reader指令碼Demo
實際運行時,請刪除下述代碼中的注釋。
{
"type":"job",
"version":"2.0",
"steps":[
{
"stepType":"odps",//外掛程式名。
"parameter":{
"partition":[],//讀取資料所在的分區。
"isCompress":false,//是否壓縮。
"datasource":"",//資料來源。
"column":[//源頭表的列資訊。
"id"
],
"where": "",//使用WHERE資料過濾時,填寫具體WHERE子句內容。
"enableWhere":false,//是否使用WHERE進行資料過濾。
"table":""//表名。
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"stream",
"parameter":{
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//錯誤記錄數。
},
"speed":{
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1, //作業並發數。
"mbps":"12"//限流,此處1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}如果您需要指定MaxCompute的Tunnel Endpoint,可以通過指令碼模式手動設定資料來源。將上述樣本中的"datasource":"",替換為資料來源的具體參數,樣本如下。
"accessId":"*******************",
"accessKey":"*******************",
"endpoint":"http://service.eu-central-1.maxcompute.aliyun-inc.com/api",
"odpsServer":"http://service.eu-central-1.maxcompute.aliyun-inc.com/api",
"tunnelServer":"http://dt.eu-central-1.maxcompute.aliyun.com",
"project":"*****", Reader指令碼參數
參數 | 描述 | 是否必選 | 預設值 |
datasource | 資料來源名稱。指令碼模式支援添加資料來源,該配置項填寫的內容必須與添加的資料來源名稱保持一致。 | 是 | 無 |
table | 讀取資料表的表名稱(大小寫不敏感)。 | 是 | 無 |
partition | 讀取的資料所在的分區資訊。
例如,分區表test包含pt=1,ds=hangzhou、pt=1,ds=shanghai、pt=2,ds=hangzhou、pt=2,ds=beijing四個分區,則讀取不同分區資料的配置如下:
此外,您還可以根據實際需求設定分區資料的擷取條件:
說明
| 如果表為分區表,則必填。如果表為非分區表,則不能填寫。 | 無 |
column | 讀取MaxCompute源頭表的列資訊。例如表test的欄位為id、name和age:
| 是 | 無 |
enableWhere | 是否適用WHERE子句進行資料過濾。 | 否 | false |
where | 使用WHERE資料過濾時,填寫具體的WHERE子句內容。 | 否 | 無 |
Writer指令碼Demo
指令碼配置範例如下。
{
"type":"job",
"version":"2.0",//版本號碼。
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"odps",//外掛程式名。
"parameter":{
"partition":"",//分區資訊。
"truncate":true,//清理規則。
"compress":false,//是否壓縮。
"datasource":"odps_first",//資料來源名。
"column": [//源端列名。
"id",
"name",
"age",
"sex",
"salary",
"interest"
],
"table":""//表名。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//錯誤記錄數,表示髒資料的最大容忍條數。
},
"speed":{
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1, //作業並發數。
"mbps":"12"//限流,此處1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}如果您需要指定MaxCompute的Tunnel Endpoint,可以通過指令碼模式手動設定資料來源:將上述樣本中的"datasource":"",替換為資料來源的具體參數,樣本如下。
"accessId":"<yourAccessKeyId>",
"accessKey":"<yourAccessKeySecret>",
"endpoint":"http://service.eu-central-1.maxcompute.aliyun-inc.com/api",
"odpsServer":"http://service.eu-central-1.maxcompute.aliyun-inc.com/api",
"tunnelServer":"http://dt.eu-central-1.maxcompute.aliyun.com",
"project":"**********", Writer指令碼參數
參數 | 描述 | 是否必選 | 預設值 |
datasource | 資料來源名稱,指令碼模式支援添加資料來源,該配置項填寫的內容必須與添加的資料來源名稱保持一致。 | 是 | 無 |
table | 寫入的資料表的表名稱(大小寫不敏感),不支援填寫多張表。 | 是 | 無 |
partition | 需要寫入資料表的分區資訊,必須指定到最後一級分區。例如把資料寫入一個三級分區表,必須配置到最後一級分區,例如
| 如果表為分區表,則必填。如果表為非分區表,則不能填寫。 | 無 |
column | 需要匯入的欄位列表。當匯入全部欄位時,可以配置為
| 是 | 無 |
truncate | 通過配置 因為利用MaxCompute SQL進行資料清理工作,SQL無法保證原子性,所以truncate選項不是原子操作。當多個任務同時向一個Table或Partition清理分區時,可能出現並發時序問題,請務必注意。 針對該類問題,建議您盡量不要多個作業DDL同時操作同一個分區,或者在多個並發作業啟動前,提前建立分區。 | 是 | 無 |
emptyAsNull | Null 字元串是否轉為NULL寫入。 | 否 | false |
consistencyCommit | 同步完成才可見。
| 否 | false |