DataWorks提供任務搬站功能,支援將Oozie、Azkaban、Airflow、DolphinScheduler等開源調度引擎的任務快速遷移至DataWorks。本文為您介紹匯出任務的檔案要求等相關資訊。
背景資訊
您需要先匯出開源調度引擎的任務至本地或OSS,再匯入至DataWorks。匯入的詳情請參見匯入開源引擎任務。
匯出Oozie任務
匯出要求
匯出的檔案需包含XML和配置項等資訊,匯出後即為一個Zip格式檔案。
匯出結構
Oozie的任務描述在HDFS的某個Path下。以Oozie官方的Examples為例,Examples包中的apps目錄下,每個子目錄都是一個Oozie的Workflow Job。該子目錄包含Workflow的定義XML和配置項等資訊。匯出檔案的結構如下。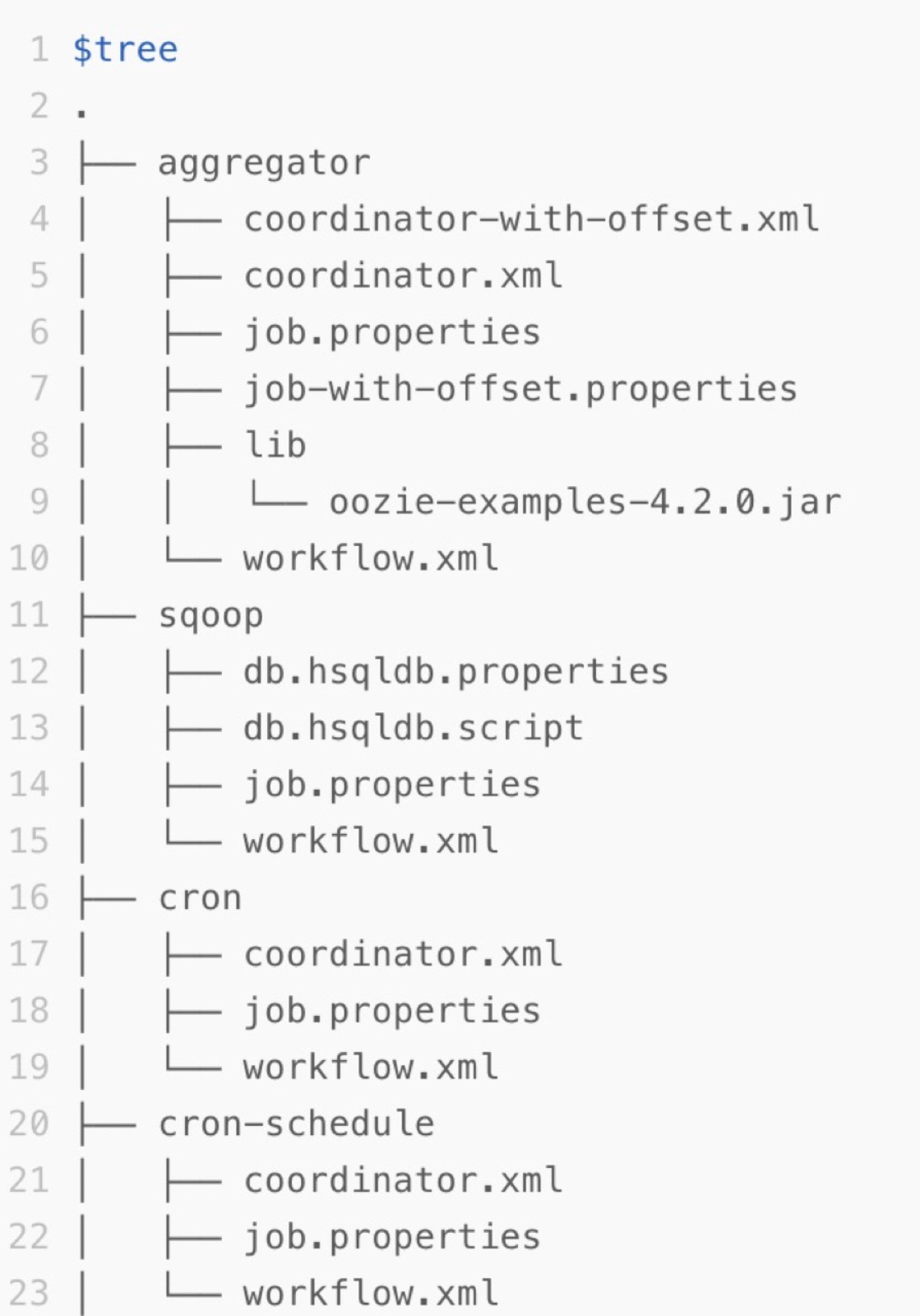
匯出Azkaban任務
下載工作流程
Azkaban擁有自己的Web控制台,支援在介面下載某個工作流程(Flow)。
登入Azkaban控制台的Projects頁面。
進入相應的Project頁面,單擊Flows,為您展示該Project下所有的工作流程。
單擊頁面右上方的Download,下載Project的匯出檔案。
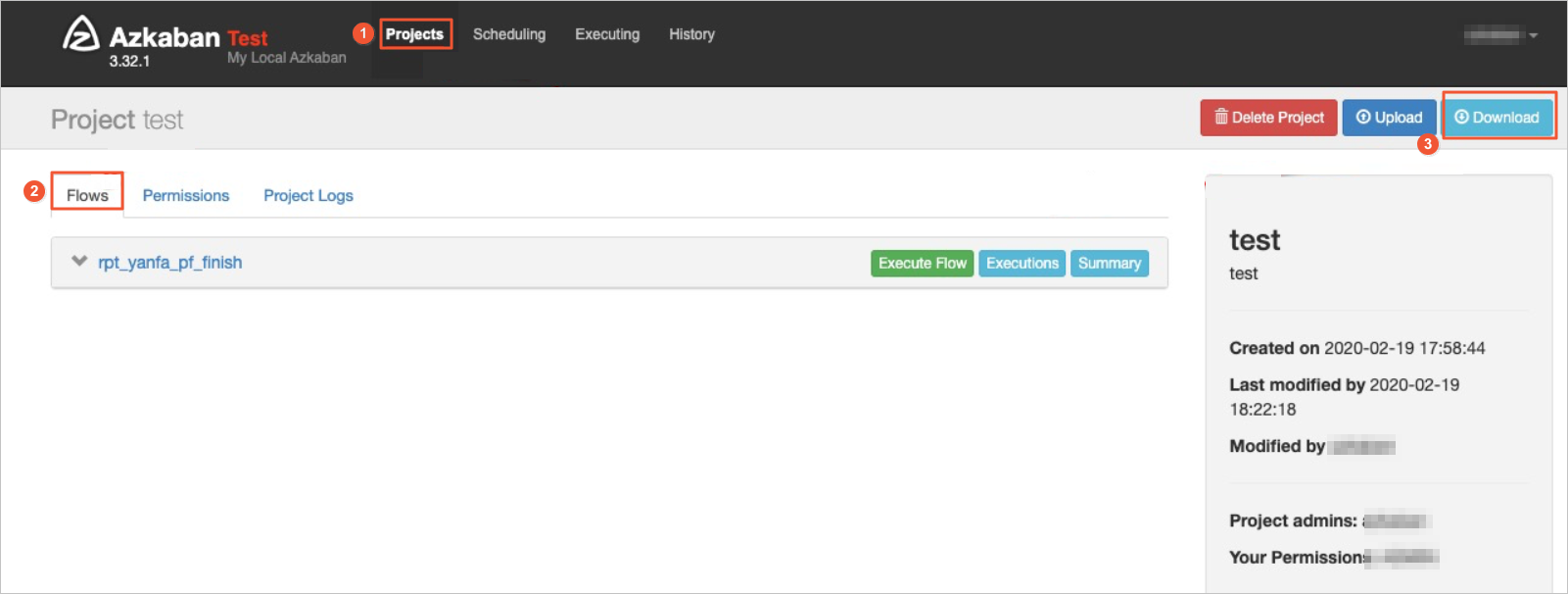 Azkaban匯出包的格式無特別限制,是原生Azkaban即可。匯出的Zip檔案包含Azkaban的某個Project下所有任務(Job)及其關係的資訊。Azkaban頁面匯出的Zip檔案可直接在調度引擎作業匯入頁面上傳匯入。
Azkaban匯出包的格式無特別限制,是原生Azkaban即可。匯出的Zip檔案包含Azkaban的某個Project下所有任務(Job)及其關係的資訊。Azkaban頁面匯出的Zip檔案可直接在調度引擎作業匯入頁面上傳匯入。
轉換邏輯
Azkaban與DataWorks轉換項的對應關係及邏輯說明如下。
Azkaban轉換項 | DataWorks轉換項 | 說明 |
Flow | 資料開發(DataStudio)的商務程序 | Flow裡的Job作為節點會放至Flow對應的商務程序目錄下。 嵌套Flow的內部Flow也會單獨轉換為一個商務程序,通過Flow轉換後的商務程序會自動建立節點間的依賴關係。 |
Command類型的Job | Shell節點 | 若使用DataWorks on EMR模式,則轉換為EMR SHELL節點。可在匯入任務的進階設定進行配置。 若Command命令列調用其他指令碼,會自動分析具體是哪個指令檔。分析到的指令檔會註冊為DataWorks的資源檔,轉換後的Shell代碼裡會引用該資源檔。 |
Hive類型的Job | EMR_HIVE節點 | 若使用DataWorks on MaxCompute模式,則轉換為ODPS SQL節點。可在匯入任務的進階設定進行配置。 |
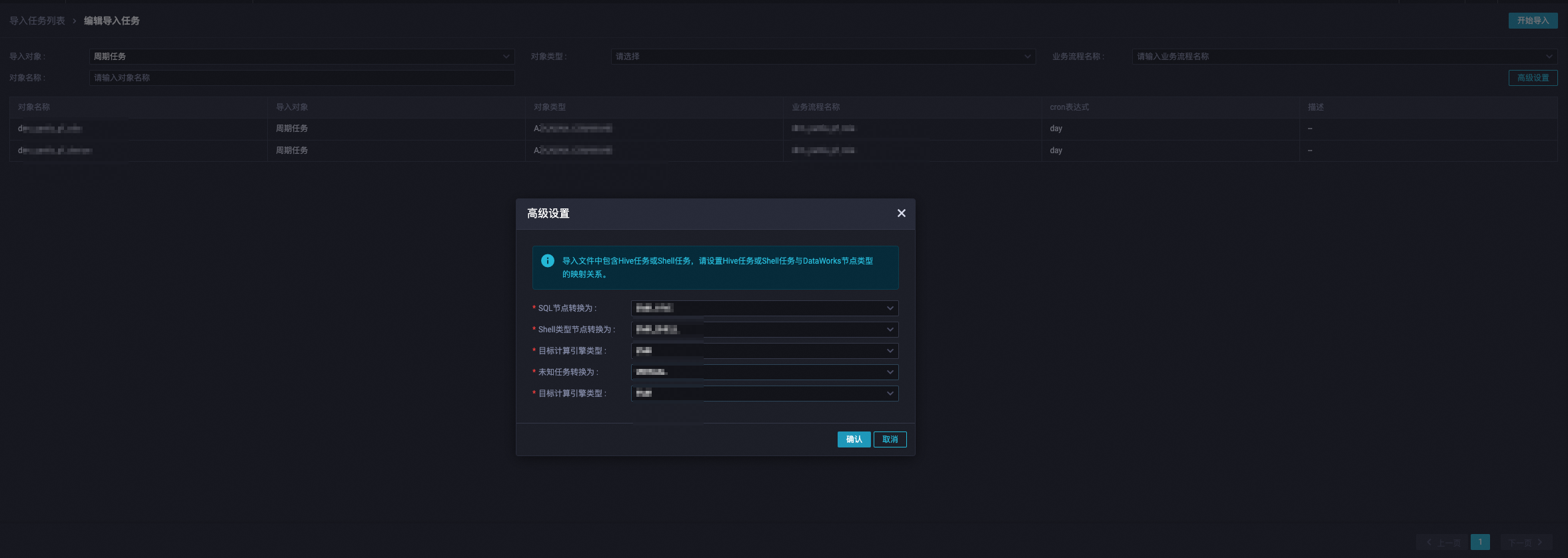
其他DataWorks不支援的節點 | 虛擬節點或Shell節點 | 可在匯入任務的進階設定進行配置。 |
匯出Airflow任務
使用限制
匯出Airflow任務僅支援Airflow 1.10.x,且依賴Python 3.6及以上版本。
操作步驟
進入Airflow的執行環境。
使用Airflow的Python庫,載入在Airflow上調度的Dag Folder。Dag Folder為您的Dag Python檔案所在的目錄。
使用匯出工具,在記憶體中通過Airflow的Python庫讀取Dag Python檔案的內部任務資訊及其依賴關係,將產生的Dag資訊寫入JSON檔案進行匯出。
您可進入DataWorks的頁面,下載匯出工具。進入調度引擎作業匯出的步驟請參考進入引擎作業匯出。
工具操作說明
匯出工具操作說明如下:
使用如下語句解壓airflow-exporter.tgz。
tar zxvf airflow-exporter.tgz設定PYTHONPATH為Airflow的Python lib目錄。樣本語句如下。
export PYTHONPATH=/usr/local/lib/python3.6/site-packages匯出Airflow任務。樣本語句如下。
cd airflow-exporter python3.6 ./parser -d /path/to/airflow/dag/floder/ -o output.json使用如下語句,將匯出的output.json檔案產生Zip檔案。
zip out.zip output.json
Zip檔案產生後,您可進入DataWorks頁面匯入任務,詳情請參見匯入開源引擎任務。
匯出DolphinScheduler任務
支援將任務匯入到(舊版)資料開發(DataStudio)和(新版)資料開發(Data Studio)。
原理介紹
DataWorks匯出工具通過調用DolphinScheduler的大量匯出工作流程定義API來擷取工作流程定義的JSON配置,並產生一個Zip檔案。然後,使用dolphinscheduler_to_dataworks轉換器將該Zip檔案轉換為DataWorks支援的檔案/任務類型,並通過建立的DolphinScheduler匯入任務解析和轉換Zip檔案中的代碼和依賴關係,最終將其匯入到DataWorks空間中。
使用限制
版本限制:只能將1.3.x、2.x、3.x版本的DolphinScheduler任務通過任務匯出工具匯入到DataWorks。
轉換限制:
SQL任務:僅支援轉換部分引擎的SQL節點,具體請以實際使用為準。並且轉換過程中SQL代碼不做文法轉換、不進行修改。
Cron運算式:部分情境存在運算式剪裁或運算式功能不支援等情況,您需自行檢查調度配置的定時時間是否滿足要求。調度時間介紹,詳情請參見時間屬性配置說明。
Python節點:DataWorks沒有單獨的Python節點,Python節點目前是轉換為Python檔案資源和一個調用該Python資源的Shell節點,調度參數傳遞可能存在問題,您需自行調試檢查。調度參數介紹,詳情請參見調度參數配置。
Depend節點:暫不支援轉換跨周期依賴。定義的相依性屬性轉換為DataWorks同周期調度依賴的本節點輸入、本節點輸出。同周期依賴配置,詳情請參見配置同周期調度依賴。
配置任務類型映射
您可以通過以下步驟完成DataWorks匯出工具的下載及任務類型映射的配置。
下載匯出工具。
配置任務類型映射。
進入到匯出工具目錄下,可看到
lib、bin、conf目錄。您需在conf目錄的dataworks-transformer-config.json檔案中修改映射關係。配置參數說明:
以下將以轉換為
ODPS類型為例,為您說明dataworks-transformer-config.json檔案中的參數資訊。{ "format": "WORKFLOW", "locale": "zh_CN", "skipUnSupportType": true, "transformContinueWithError": true, "specContinueWithError": true, "processFilter": { "releaseState": "ONLINE", "includeSubProcess": true } "settings": { "workflow.converter.shellNodeType": "DIDE_SHELL", "workflow.converter.commandSqlAs": "ODPS_SQL", "workflow.converter.sparkSubmitAs": "ODPS_SPARK", "workflow.converter.target.unknownNodeTypeAs": "DIDE_SHELL", "workflow.converter.mrNodeType": "ODPS_MR", "workflow.converter.target.engine.type": "ODPS", "workflow.converter.dolphinscheduler.sqlNodeTypeMapping": { "POSTGRESQL": "POSTGRESQL", "MYSQL": "MYSQL" } }, "replaceMapping": [ { "taskType": "SHELL", "desc": "$[yyyyMMdd-1]", "pattern": "\$\[yyyyMMdd-1\]", "target": "\${dt}", "param": "dt=$[yyyyMMdd-1]" }, { "taskType": "PYTHON", "desc": "$[yyyyMMdd-1]", "pattern": "\$\[yyyyMMdd-1\]", "target": "\${dt}", "param": "dt=$[yyyyMMdd-1]" } ] }配置參數
配置說明
format
在進行資料移轉時,需要根據目標環境的版本設定相應的參數。具體規則如下:
如果目標環境是參加資料開發(Data Studio)(新版)公測的工作空間,需將該參數設定為
WORKFLOW。如果目標環境是未參加資料開發(Data Studio)(新版)公測的工作空間,需將該參數設定為
SPEC。
基本配置項,必填。
locale
指定語言環境,預設為
zh_CN。skipUnSupportType
任務類型轉換遇到不支援的類型時是否跳過。
設定為
true,則跳過不支援的類型。設定為
false,則失敗退出。
transformContinueWithError
在轉換過程中遇到錯誤時是否繼續執行。
設定為
true,則繼續執行。設定為
false,則停止執行。
specContinueWithError
任務類型轉換失敗時是否繼續轉換。
設定為
true,則繼續轉換。設定為
false,則停止轉換。
processFilter
releaseState
過濾條件,處理狀態為線上的工作流程。
支援轉換過濾,若要對遷移任務進行過濾匯入,請配置該參數。
includeSubProcess
過濾條件,是否包含狀態為線上的子流程。
settings
workflow.converter.shellNodeType
源系統中的Shell節點映射到目標系統的類型(如DIDE_SHELL)。
配置映射資訊,必填。
workflow.converter.commandSqlAs
SQL命令節點在目標系統中的執行引擎(如ODPS_SQL)。
workflow.converter.sparkSubmitAs
Spark提交任務的目標執行引擎(如ODPS_SPARK)。
workflow.converter.target.unknownNodeTypeAs
未知節點類型的預設映射(如DIDE_SHELL)。
workflow.converter.mrNodeType
MapReduce節點的目標執行引擎(如ODPS_MR)。
workflow.converter.target.engine.type
預設使用的計算引擎(如ODPS)。
workflow.converter.dolphinscheduler.sqlNodeTypeMapping
DolphinScheduler中SQL節點資料庫類型到目標系統的映射。
"POSTGRESQL": "POSTGRESQL"。"MYSQL": "MYSQL"。
replaceMapping
taskType
規則適用的任務類型(如Shell或Python)。
支援正則替換匹配到的節點內容。
desc
描述(資訊性欄位,不參與實際處理,可為空白)。
pattern
需要替換的Regex模式(如$[yyyyMMdd-1])。
target
替換後的目標字串(如${dt})。
param
為替換後的目標字串賦值。
例如:通過代碼變數為節點變數賦值。(如 dt=$[yyyyMMdd-1])。
匯出DolphinSchedule任務
您可以按照以下步驟,使用匯出工具將DolphinScheduler作業匯出為一個zip檔案。樣本命令如下,您需根據實際情況配置相應的參數資訊。執行該命令後,DolphinScheduler的資源將會按照-f指定的檔案名稱儲存在目前的目錄下。
python3 bin/reader.py \
-a dolphinscheduler \
-e http://xxx.xxx.xxx.xxx:12345 \
-t {token} \
-v 1.3.9 \
-p 123456,456256 \
-f project_dp01.zip\
-sr false;配置參數 | 配置說明 |
-a | 待讀取的系統類別型,此處為固定值 |
-e | DolphinScheduler公網訪問地址。 |
-t | DolphinScheduler應用 |
-v | 待匯出的DolphinScheduler版本。 |
-p | 待匯出的DolphinScheduler空間名稱,支援配置多個,可用逗號隔開。 |
-f | 匯出後的壓縮檔名稱,僅支援zip格式壓縮包。 |
-sr | 是否skip資源下載,預設不下載,參數值為 說明
|
轉換任務類型
您可以配置並執行以下指令碼,通過dolphinscheduler_to_dataworks轉換器,結合配置任務類型映射中定義的dataworks-transformer-config.json設定檔,將DolphinScheduler空間檔案轉換為對應的DataWorks檔案或任務類型。
python3 bin/transformer.py \
-a dolphinscheduler_to_dataworks \
-c conf/dataworks-transformer-config.json \
-s project_dp01.zip \
-t project_dw01.zip;配置參數 | 配置說明 |
-a | 轉換器名稱,預設為 |
-c | 指定的轉換設定檔。預設為配置任務類型映射時所配置的 |
-s | 待轉換的DolphinScheduler檔案名稱。匯出DolphinSchedule任務步驟中的匯出結果檔案。 |
-t | 轉換為DataWorks檔案格式後的結果檔案名稱。該檔案將以 |
匯入DolphinSchedule任務
您可通過配置執行以下指令碼任務,將轉換好的檔案匯入DataWorks空間。
python3 bin/writer.py \
-a dataworks \
-e dataworks.cn-shanghai.aliyuncs.com \
-i $ALIYUN_ACCESS_KEY_ID \
-k $ALIYUN_ACCESS_KEY_SECRET \
-p $ALIYUN_DATAWORKS_WORKSPACE_ID \
-r cn-shanghai \
-f project_dw01.zip \
-t SPEC;配置參數 | 配置說明 |
-a | 待寫入的系統類別型,此處預設為 |
-e | DataWorks OpenAPI的服務存取點Endpoint。您可在服務存取點Endpoint中根據您DataWorks工作空間所在地區擷取該參數資訊。 |
-i | 阿里雲Access ID,需要有匯入空間的許可權。 |
-k | 阿里雲Access Key,需要有匯入空間的許可權。 |
-p | DataWorks工作空間ID,即指定執行此py檔案資料寫入的工作空間。 |
-r | DataWorks工作空間所在地區ID,可通過服務存取點擷取所在地區ID。 |
-f | 具體要匯入DataWorks工作空間的本地檔案。轉換任務類型步驟中轉換結果檔案。 |
-t | 指定匯入環境,匯入目標為參加資料開發(Data Studio)(新版)公測的工作空間時,無需設定該參數。 |
完成上述操作後,您可前往目標DataWorks工作空間,查看任務的遷移情況。
匯出其它開源引擎任務
DataWorks為您提供標準模板便於匯出除Oozie、Azkaban、Airflow、DolphinScheduler外的開源引擎任務。匯出任務前,您需要下載標準格式模板並參考模板的檔案結構修改內容。下載模板及目錄結構的介紹請進入開源引擎匯出頁面進行查詢:
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
單擊左上方的
 表徵圖,選擇。
表徵圖,選擇。在左側導覽列,單擊,進入調度引擎匯出方案選擇頁面。
單擊標準模板。
在標準模板頁簽下,單擊標準格式模板進行下載。
根據模板中的格式修改內容後,即可產生匯出包。