Spark是一個通用的巨量資料分析引擎,具有高效能、易用和普遍性等特點,可用於進行複雜的記憶體分析,構建大型、低延遲的資料分析應用。DataWorks為您提供CDH Spark節點,便於您在DataWorks上進行Spark任務的開發和周期性調度。本文為您介紹如何建立及使用CDH Spark節點。
前提條件
資料開發(DataStudio)中已建立商務程序。
資料開發(DataStudio)基於商務程序對不同開發引擎進行具體開發操作,所以您建立節點前需要先建立商務程序,操作詳情請參見建立商務程序。
已建立阿里雲CDH叢集,並註冊CDH叢集至DataWorks。
建立CDH相關節點並開發CDH任務前,您需要先將CDH叢集註冊至DataWorks工作空間,操作詳情請參見註冊CDH叢集至DataWorks。
(可選,RAM帳號需要)進行任務開發的RAM帳號已被添加至對應工作空間中,並具有開發或空間管理員(許可權較大,謹慎添加)角色許可權,新增成員的操作詳情請參見為工作空間增加空間成員。
已購買Serverless資源群組並完成資源群組配置,包括綁定工作空間、網路設定等,詳情請參見新增和使用Serverless資源群組。
使用限制
支援Serverless資源群組(推薦)或舊版獨享調度資源群組運行該類型任務。
準備工作:開發Spark任務並擷取JAR包
在使用DataWorks調度CDH Spark任務前,您需要先在CDH中開發Spark任務代碼並完成任務代碼的編譯,產生編譯後的任務JAR包,CDH Spark任務的開發指導詳情請參見Spark概述。
後續您需要將任務JAR包上傳至DataWorks,在DataWorks中周期性調度CDH Spark任務。
步驟一:建立CDH Spark節點
進入資料開發頁面。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
按右鍵某個商務程序,選擇。
在建立節點對話窗中,配置節點的引擎執行個體、路徑、名稱等資訊。
單擊確認 ,完成節點建立,後續您可在建立的節點中進行對應任務的開發與配置操作。
步驟二:建立並引用CDH JAR資源
您可以在建立的CDH Spark節點中引用JAR包資源,並編寫CDH Spark節點代碼,通過Spark Submit命令提交任務。具體操作如下:
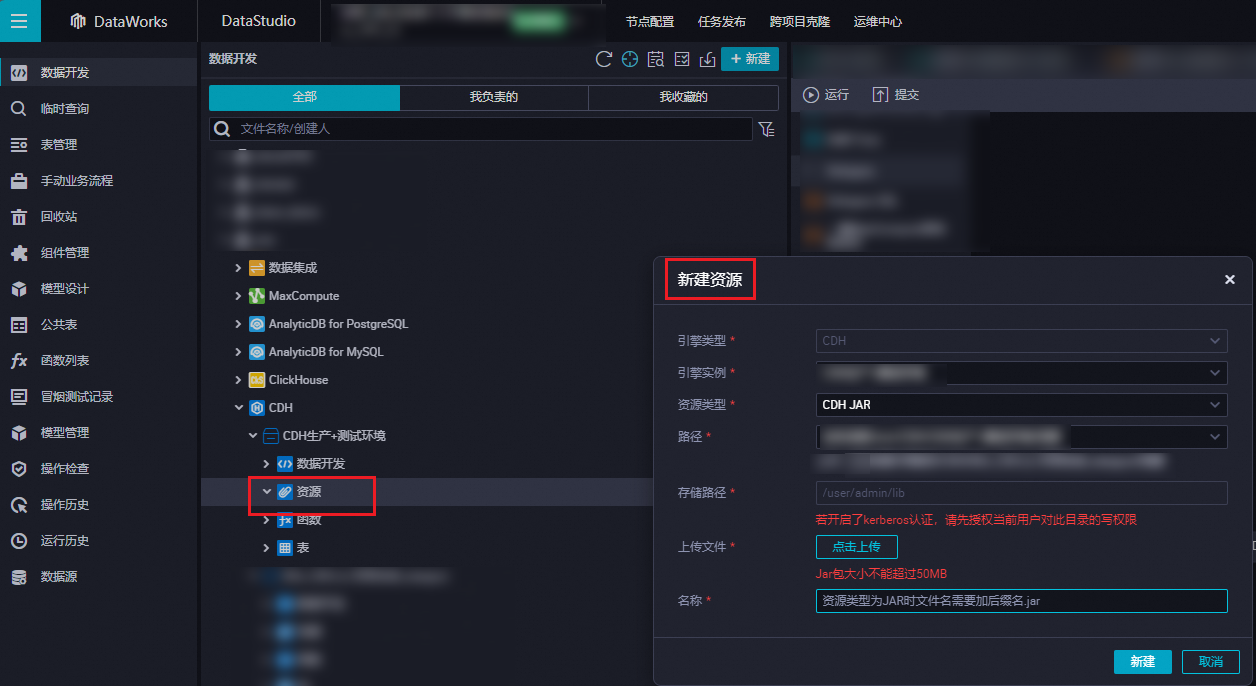
建立CDH JAR資源。
在對應商務程序中,按右鍵,選擇,在建立資源對話方塊中點擊上傳,選擇需要上傳的檔案。
引用CDH JAR資源。
開啟建立的CDH節點,停留在編輯頁面。
在 中,找到待引用的資源(樣本為
spark-examples_2.11_2.4.0.jar),按右鍵資源名稱,選擇引用資源。
引用資源後,若CDH節點的代碼編輯頁面出現
##@resource_reference{""}格式的語句,表明已成功引用代碼資源。樣本如下:##@resource_reference{"spark_examples_2.11_2.4.0.jar"} spark_examples_2.11_2.4.0.jar修改CDH Spark節點代碼,補充Spark Submit命令,修改後的樣本如下。
重要CDH Spark節點編輯代碼時不支援備註陳述式,請務必參考如下樣本改寫任務代碼,不要隨意添加註釋,否則後續運行節點時會報錯。
##@resource_reference{"spark-examples_2.11-2.4.0.jar"} spark-submit --class org.apache.spark.examples.SparkPi --master yarn spark-examples_2.11-2.4.0.jar 100其中:
org.apache.spark.examples.SparkPi:為您實際編譯的JAR包中的任務主Class。
spark-examples_2.11-2.4.0.jar:為您實際上傳的CDH JAR資源名稱。
步驟三:配置任務調度
如果您需要周期性執行建立的節點任務,可以單擊節點編輯頁面右側的調度配置,根據業務需求配置該節點任務的調度資訊:
步驟四:調試代碼任務
(可選)選擇運行資源群組、賦值自訂參數取值。
在工具列單擊
 表徵圖,在參數對話方塊選擇已調試運行需要使用的資源群組。
表徵圖,在參數對話方塊選擇已調試運行需要使用的資源群組。如果您的任務代碼中有使用調度參數變數,可在此處為變數賦值,用於調試。參數賦值邏輯詳情請參見運行,進階運行和開發環境煙霧測試 (Smoke Test)賦值邏輯有什麼區別。
儲存並運行SQL語句。
在工具列,單擊
 表徵圖,儲存編寫的SQL語句,單擊
表徵圖,儲存編寫的SQL語句,單擊 表徵圖,運行建立的SQL任務。
表徵圖,運行建立的SQL任務。(可選)煙霧測試 (Smoke Test)。
如果您希望在開發環境進行煙霧測試 (Smoke Test),可在執行節點提交,或節點提交後執行,煙霧測試 (Smoke Test),操作詳情請參見執行煙霧測試 (Smoke Test)。
後續步驟
相關情境
DataWorks平台提供了完善的作業調度和監控功能,確保您的Spark作業能夠順利提交到CDH叢集執行。這種方式不僅簡化了作業的營運流程,還使得資源管理更為高效,以下是一些Spark任務的應用情境:
資料分析:利用Spark SQL、Dataset以及DataFrame API進行複雜的資料彙總、篩選和轉換,快速洞察資料。
流處理:利用Spark Streaming處理即時資料流,並進行即時分析和決策。
機器學習任務:使用Spark MLlib進行資料預先處理、特徵提取、模型訓練和評估。
大規模ETL任務:進行巨量資料集的抽取、轉換和載入,為資料倉儲或其他儲存系統準備資料。