本文介紹如何在資料湖分析控制台建立和執行Spark作業。
準備事項
您需要在提交作業之前先建立虛擬叢集。
說明建立虛擬叢集時注意選擇引擎類型為Spark。
如果您是子帳號登入,需要配置子帳號提交作業的許可權,具體請參考細粒度配置RAM子帳號許可權。由於SparkPi不需要訪問外部資料源,您只需要配置文檔中的前兩個步驟:”DLA子帳號關聯RAM子帳號“和”為子帳號授予訪問DLA的許可權“。
操作步驟
頁面左上方,選擇DLA所在地區。
單擊左側導覽列中的Serverless Spark -> 作業管理。
在作業編輯頁面,單擊建立工作範本。
在建立工作範本頁面,按照頁面提示進行參數配置。
參數名稱
參數說明
檔案名稱
設定檔案或者檔案夾的名字。檔案名稱不區分大小寫。
檔案類型
可以設定為檔案或者檔案夾。
父級
設定檔案或者檔案夾的上層目錄。
作業列表相當於根目錄,所有的作業都在作業列表下建立。
您可以在作業列表下建立檔案夾,然後在檔案夾下建立作業;也可以直接在作業列表根目錄下建立作業。
作業類型
您可以選擇為SparkJob或SparkSQL。
SparkJob:Python/Java/Scala類型的Spark作業,需要填寫JSON配置作業。
SparkSQL:SQL類型的Spark配置, 通過set命令配置作業,詳情請就參見Spark SQL。
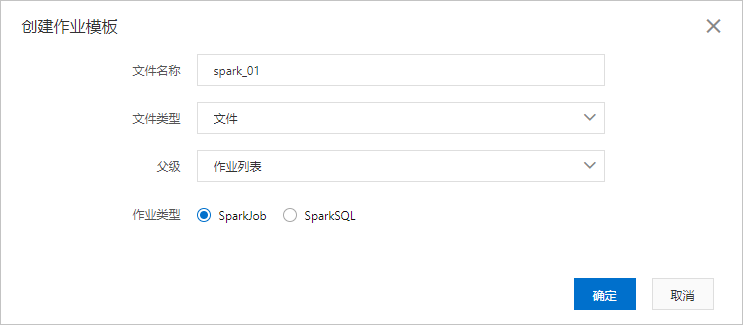
完成上述參數配置後,單擊確定建立Spark作業。
建立Spark作業後,您可以根據作業配置指南編寫Spark作業。
Spark作業編寫完成後,您可以進行以下操作:
單擊儲存,儲存Spark作業,便於後續複用作業。
單擊執行,執行Spark作業,作業列表即時顯示作業的執行狀態。
單擊樣本,右側作業編輯框顯示DLA為您提供的SparkPi樣本作業,單擊執行,執行SparkPi樣本。

(可選)在作業列表中,查看作業狀態或對作業執行操作。

配置
說明
作業ID
Spark任務ID,由系統產生。
狀態
Spark任務的運行狀態。
STARTING:任務正在提交。
RUNNING:任務運行中。
SUCCESS:Spark作業執行成功。
DEAD:任務出錯,可通過查看日誌進行排錯處理。
KILLED:任務被主動終止。
作業名稱
建立Spark作業時設定的作業名稱,由name參數指定。
提交時間
當前Spark作業的提交時間。
啟動時間
當前Spark作業的啟動時間。
更新時間
當前Spark作業狀態發生變化時的更新時間。
期間
運行當前Spark作業所花費的時間。
操作
操作中有5個參數,分別為:
日誌,當前作業的日誌,只擷取最新的300行日誌。
SparkUI,當前作業的Spark Job UI 地址,如果Token到期需要單擊重新整理擷取最新的地址。
詳情,當前作業提交時填寫的JSON指令碼。
kill,終止當前的作業。
歷史,查看當前作業的作業嘗試列表。
監控,查看當前作業的監控資料。
(可選)單擊作業嘗試列表,查看所有作業的作業嘗試。
說明預設情況下,一個作業只會進行一次作業嘗試。如需進行多次作業嘗試,請配置作業重設參數。更多資訊,請參見。
在作業嘗試列表中,選中單個作業,單擊,可以查看該作業的嘗試列表。

附錄
資料湖分析提供了開發Spark作業的Demo,您可以參考開源專案Aliyun DLA Demo。您可以直接進行下載,執行mvn進行打包。建議您參考本專案進行pom配置和開發。
使用DMS進行Spark作業編排和任務周期調度,請參考文檔DMS任務編排調度Spark任務訓練機器學習模型。
DLA Spark作業配置,請參考文檔作業配置指南。