本文將介紹如何使用Data Management任務編排(老)調度Spark MLLib任務。
前提條件
背景資訊
如下內容以任務編排(老)功能操作樣本。任務編排(老)功能已下線,詳細資料,請參見【通知】下線任務編排(老)和數倉開發(老)功能。
近年來,隨著巨量資料的興起與算力的提升,機器學習和深度學習得到了廣泛的應用,如千人千面的推薦系統、人臉支付、自動駕駛汽車等。MLlib是Spark的機器學習庫,包括分類、迴歸、聚類、協同過濾、降維等演算法,本文介紹的是Kmeans聚類演算法。
建立Spark虛擬叢集
建立虛擬叢集,詳情請參見建立虛擬叢集。
授予ADB刪除OSS檔案的許可權。
上傳資料和代碼
登入OSS管理主控台。
本樣本將準備如下資料,並儲存至data.txt檔案。
0.0 0.0 0.0 0.1 0.1 0.1 0.2 0.2 0.2 9.0 9.0 9.0 9.1 9.1 9.1 9.2 9.2 9.2準備如下spark MLLib代碼,並將該代碼打包成FatJar檔案。
說明範例程式碼功能:讀取data.txt檔案中的資料,訓練Kmeans模型。
package com.aliyun.spark import org.apache.spark.SparkConf import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.sql.SparkSession object SparkMLlib { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Spark MLlib Kmeans Demo") val spark = SparkSession .builder() .config(conf) .getOrCreate() val rawDataPath = args(0) val data = spark.sparkContext.textFile(rawDataPath) val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))) val numClusters = 2 val numIterations = 20 val model = KMeans.train(parsedData, numClusters, numIterations) for (c <- model.clusterCenters) { println(s"cluster center: ${c.toString}") } val modelOutputPath = args(1) model.save(spark.sparkContext, modelOutputPath) } }將以上步驟的data.txt檔案和FatJar檔案上傳至OSS中,操作詳情可參見控制台上傳檔案。
使用DMS任務編排調度Spark任務
在頂部功能表列中,選擇。
單擊新增任務流。
在建立任務流對話方塊,將任務流名稱設定為
Just_Spark,將描述設定為Just_Spark demo.,單擊確認。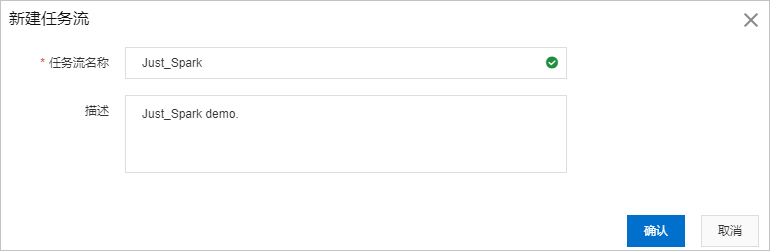
在任務編排頁面中,將左側任務類型中的DLA Serverless Spark拖拽到畫布的空白地區。
在畫布中雙擊DLA Serverless Spark節點,配置以下資訊。
從地區列表中,選擇目標Spark叢集所在的地區。
從Spark 叢集列表中,選擇目標Spark叢集。
在作業配置文字框中,輸入以下代碼。
{ "name": "spark-mllib-test", "file": "oss://oss-bucket-name/kmeans_demo/spark-mllib-1.0.0-SNAPSHOT.jar", "className": "com.aliyun.spark.SparkMLlib", "args": [ "oss://oss-bucket-name/kmeans_demo/data.txt", "oss://oss-bucket-name/kmeans_demo/model/" ], "conf": { "spark.driver.resourceSpec": "medium", "spark.executor.instances": 2, "spark.executor.resourceSpec": "medium", "spark.dla.connectors": "oss" } }說明file為FatJar檔案在OSS中的絕對路徑。args為data.txt與model在OSS中的絕對路徑。
完成以上配置後,單擊儲存按鈕。
單擊頁面左上方的試運行按鈕進行測試。
如果執行日誌的最後一行出現
status SUCCEEDED,表明任務試運行成功。如果執行日誌的最後一行出現
status FAILED,表明任務試運行失敗,在執行日誌中查看執行失敗的節點和原因,修改配置後重新嘗試。
發布任務流。具體操作,請參見發布或下線任務流。
查看任務流的執行狀態
在頂部功能表列中,選擇。
單擊任務流名稱,進入任務流詳情頁面。
單擊畫布右上方前往營運,在任務流營運頁面查看。
在任務流營運頁面上方,查看任務流的建立時間、修改時間、調度配置情況、是否發布狀態等基本資料。
單擊運行記錄頁簽,選擇調度觸發或手動觸發,查看任務流程執行記錄。
說明調度觸發:通過調度或指定時間的方式運行任務流。
手動觸發:通過手動單擊試啟動並執行方式運行任務流。
單擊狀態列前的
 ,查看任務流程執行日誌。
,查看任務流程執行日誌。在操作列中,單擊執行歷史,查看任務流的操作時間、操作人員和操作內容。
在操作列中,對不同執行狀態的任務流進行終止、重跑、暫停、恢複和置成功的操作。
說明對於執行成功的任務流,可以進行重跑操作。
對於執行失敗的任務流,可以將該任務流程執行記錄的狀態置為成功。
對於執行中的任務流,可以終止或暫停任務流程執行。
單擊發布列表頁簽,查看任務流的版本ID,發布人,發布時間、版本詳情和DAG圖。
您還可以選中任意2個版本ID,單擊版本對比,查看版本的對比資訊。