本文主要介紹Serverless Spark如何配置資料來源網路來訪問使用者VPC網路中的資料。這些資料包括RDS系列、ADB系列、PolarDB系列、MongoDB、Elasticsearch、HBase、E-MapReduce、Kafka以及使用者在ECS上自建的各種資料服務等。
背景資訊
Serverless Spark進程(Driver和Executor)運行在安全容器中,安全容器可以動態掛載使用者VPC網路的虛擬網卡,就如同運行在使用者VPC網路內的ECS上一樣,可以直接存取使用者的資料來源網路。虛擬網卡的生命週期跟Spark進程的生命週期一致,作業結束後,所有網卡也會被釋放。
Serverless Spark要掛載使用者VPC網路的虛擬網卡,只需要在Spark作業配置中配置VPC網路中的安全性群組ID和虛擬交換器ID即可。如果使用者的ECS本來就可以訪問目標資料,只需要在Spark作業配置中配置該ECS所在的安全性群組ID和虛擬交換器ID即可。
說明 Spark的計算容器,Driver和每個Executor都會佔用所配置的虛擬交換器下面的一個IP,提交作業前,請確保虛擬交換器網段的剩餘IP數充足。
注意事項
訪問服務型雲產品中的資料,無需進行本文檔中的配置,這些服務包括OSS、MaxCompute、TableStore、SLS等,這些服務一般都需要配置使用者AK訪問公用服務地址。
操作步驟
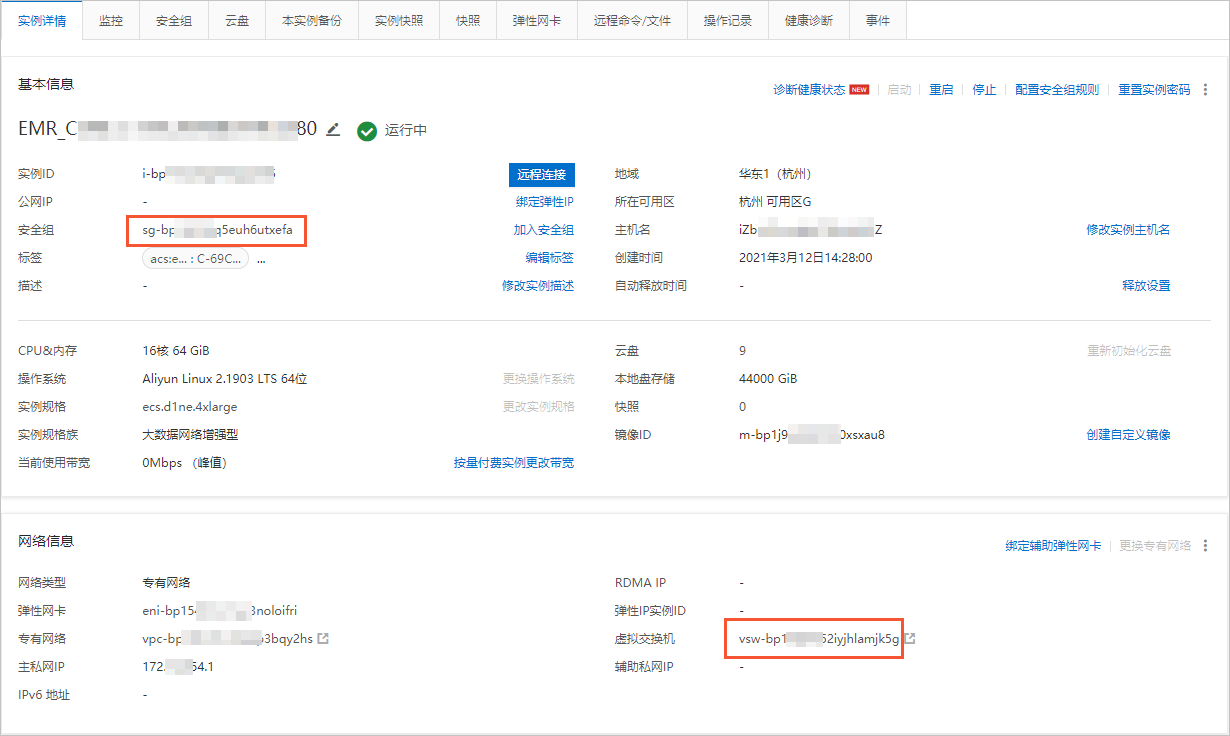
- 準備虛擬交換器和安全性群組。DLA提供了三種方法來準備虛擬交換器和安全性群組。如果您的某個ECS通過VPC內網訪問過目標資料來源,那麼推薦您直接選取該ECS的安全性群組和虛擬交換器,這個方法最簡單,請參考下面的方法1;如果您的ECS不能訪問目標資料來源,您可以在資料來源基礎資訊頁面中擷取相應資訊,參考方法2;您也可以選擇建立新的安全性群組和虛擬交換器,參考方法3。
- 為配置的交換器網段添加白名單。
- 提交Spark作業。在Serverless Spark中編寫Spark-Submit的指令碼,具體操作請參見建立和執行Spark作業。
{ "name": "SparkPi", "file": "local:///tmp/spark-examples.jar", "className": "org.apache.spark.examples.DriverSubmissio*****", "args": [ "100000" ], "conf": { "spark.driver.resourceSpec": "small", "spark.executor.resourceSpec": "medium", "spark.executor.instances": 1, "spark.dla.eni.enable": "true", "spark.dla.eni.vswitch.id": "vsw-bp17jqw3lrrobn6y*****", "spark.dla.eni.security.group.id": "sg-bp163uxgt4zandx*****", } }說明spark.dla.eni.enable取值為true時,表示啟用訪問使用者VPC功能,掛載使用者資料來源網路虛擬網卡。spark.dla.eni.vswitch.id和spark.dla.eni.security.group.id配置為步驟一中擷取的虛擬交換器ID和安全性群組ID。