Service Mesh (ASM)支援為特定服務之間和特定路由上的東西向調用流量配置熔斷規則,通過配置使網格代理主動拒絕出現故障上遊服務的請求,實現無侵入式的流量熔斷能力。本文介紹如何使用ASMCircuitBreaker CRD為東西向調用流量配置熔斷規則。
背景資訊
流量熔斷是一種過載保護機制,主要用於防止系統因為短時間內過大的流量而崩潰。在雲原生服務之間存在東西向調用流量的情況下,如果某個服務發生故障(例如:響應過慢或者失敗率升高),可能會導致該服務所在調用鏈路上的一系列服務也發生連鎖崩潰。
通過為服務間的東西向調用流量配置熔斷規則,可以實現當流量失敗率或響應逾時次數達到閾值時,主動“切斷”來自上遊服務的請求。在保護上遊服務的同時,也有效防止故障在整個調用鏈路中擴散,造成整個系統雪崩。
配置熔斷規則後,每個網格代理將基於其代理的請求分別計算流量失敗率或響應逾時次數。因此,對於同一個發生故障的上遊服務、用戶端網格代理髮生熔斷的時機可能略有不同。
前提條件
已建立ASM專業版執行個體,且版本為v1.14.3及以上。具體操作,請參見建立ASM執行個體。
已完成sleep和httpbin樣本應用的部署。具體操作,請參見在資料面叢集中部署httpbin應用和在資料面叢集部署sleep服務。
步驟一:為服務調用的東西向調用流量配置請求路徑路由
登入ASM控制台,在左側導覽列,選擇。
選擇下方兩種方式的任意一種配置虛擬服務。
控制台手動建立
在網格管理頁面,單擊目標執行個體名稱,然後在左側導覽列,選擇,然後單擊建立。
填寫命名空間和服務名稱,開啟作用範圍>作用於所有Sidecar。
在所屬服務框中單擊添加所屬服務,添加httpbin服務。
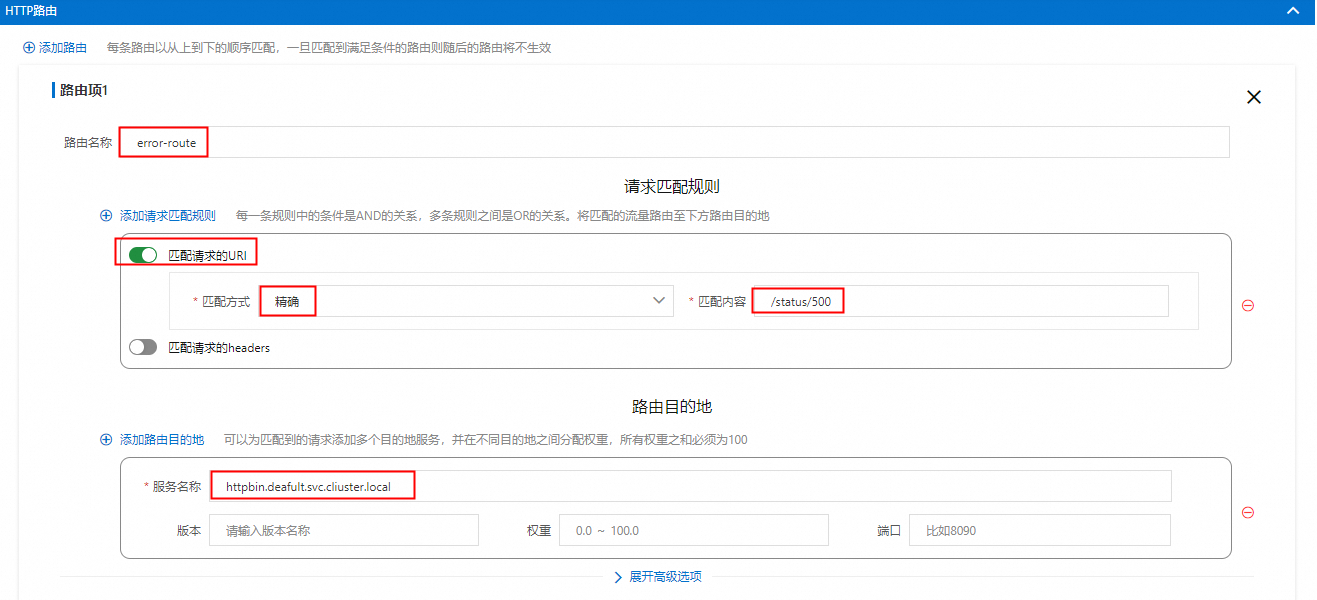
配置HTTP路由>添加路由,資訊填寫請參見下圖紅框標註。

使用YAML建立
在網格管理頁面,單擊目標執行個體名稱,然後在左側導覽列,選擇,然後單擊使用YAML建立。
在YAML輸入框中輸入如下內容,點擊建立。
下表為請求與路徑的對應關係以及具體說明。
請求路徑
匹配類型
路由項
說明
/status/500精確匹配
error-route固定響應500狀態代碼。
/delay首碼匹配
delay-route指定的時間後響應200狀態代碼;/delay請求的具體使用方法參見delay。
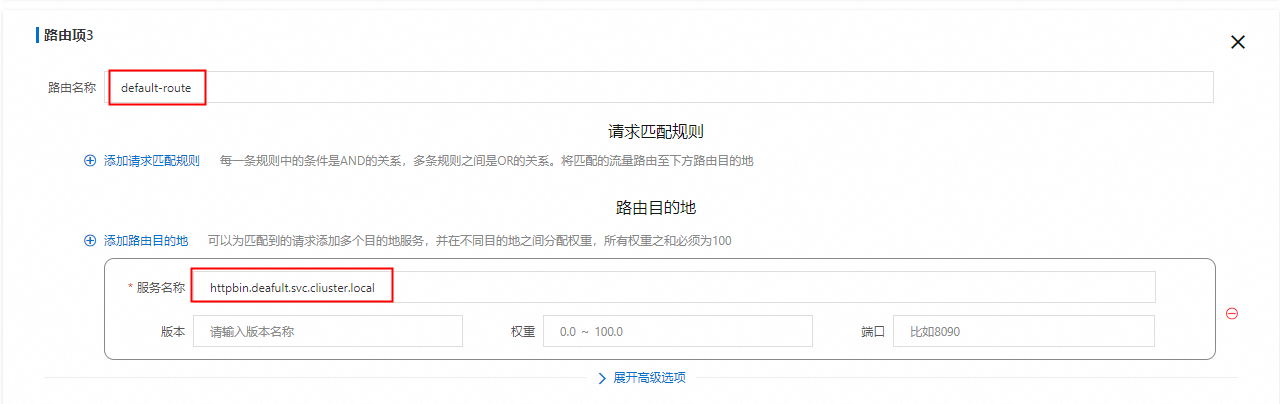
/*任意路徑
default-route預設路由項。
步驟二:配置熔斷
本節將分別介紹錯誤率熔斷和慢請求熔斷的具體配置步驟以及測試結果。
基於錯誤率熔斷
基於錯誤率的熔斷是指在給定的時間視窗內檢測伺服器響應的錯誤率,並在錯誤率超過一定閾值時觸發熔斷。
登入ASM控制台,在左側導覽列,選擇。
在網格管理頁面,單擊目標執行個體名稱,然後在左側導覽列,選擇。
在建立頁面,在YAML輸入框處輸入以下內容,然後單擊建立。
熔斷配置中使用的參數說明如下:
參數
說明
workloadSelector.labels
熔斷配置的下遊服務工作負載,在本例中是sleep服務,因此用
app: sleep標籤選中該工作負載。break_duration
熔斷髮生後到恢複對服務訪問之間的時間長度。本例中配置為60s。
window_size
進行熔斷檢測的時間視窗。本例中配置為10s,代表在10秒內若路由中的請求錯誤率超過指定閾值,則開始熔斷,拒絕請求。
error_percent
在時間視窗內,判斷是否達到熔斷所需的請求錯誤率。本例中配置為60,代表在時間視窗的10s內若路由中的請求錯誤率超過60%,則發生熔斷,拒絕請求。
min_request_amount
時間視窗內觸發熔斷所需的最小請求數。配置該參數的目的是防止因請求量過小而誤判觸發熔斷。
本例中配置為5,代表在時間視窗的10s內若路由已經發送了5次以上請求,且錯誤率超過60%時,才發生熔斷。
custom_response
熔斷髮生時,網格代理拒絕請求時返回的自訂響應內容。
body配置為
error break!,代表響應體為error break!header_to_add配置為
x-envoy-overload: 'true',代表熔斷的回應標頭中將添加x-envoy-overload: 'true'status_code配置為
499,代表熔斷後請求的響應碼為499。
match.vhost
熔斷的路由條目配置,該路由條目必須與虛擬服務中聲明的具體路由條目匹配。
name:需要配置為調用鏈路中的上遊服務服務網域名稱。在本例中,配置為sleep服務的上遊服務httpbin服務的網域名稱
httpbin.default.svc.cluster.local。port:需要配置為上遊服務的Service連接埠。在本例中,配置為httpbin服務的Service連接埠
8000。route.name_match:需要配置為虛擬服務中實際的路由項名稱,熔斷配置將在該段路由中生效。在本例中,配置為步驟二中編寫的路由項
error-route,此路由項對應的請求將固定響應500狀態代碼,確保能夠觸發熔斷。
使用kubectl串連ACK叢集,執行以下命令。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/status/500 -I | grep 'HTTP'; echo ''; sleep 0.1; done;預期輸出:
可以看到,當發送第6條請求時,熔斷被觸發,可以觀察到後續請求都返回自訂的499響應碼,熔斷將持續60s。
在熔斷期間,可以嘗試對httpbin服務的其他路徑進行訪問。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/status/503 -I | grep 'HTTP'; echo ''; sleep 0.1; done;預期輸出:
可以看到發往服務其他路徑的請求並不受
error-route路由項上的熔斷配置影響,仍然可以正常返回httpbin服務的響應內容。
基於慢請求熔斷
基於慢請求數的熔斷是指檢測在給定的時間視窗內回應時間超過給定閾值的請求數量(這種請求被稱作慢請求),並在慢請求數量超過一定閾值時觸發熔斷。
登入ASM控制台,在左側導覽列,選擇。
在網格管理頁面,單擊目標執行個體名稱,然後在左側導覽列,選擇。
在建立頁面,在YAML輸入框中輸入以下內容,然後單擊建立。
熔斷配置中使用的參數說明如下:
參數
說明
workloadSelector.labels
熔斷配置的下遊服務工作負載,在本例中是sleep服務,因此用
app: sleep標籤選中該工作負載。break_duration
熔斷髮生後到恢複對服務訪問之間的時間長度。本例中配置為60s。
window_size
進行熔斷檢測的時間視窗。本例中配置為10s,代表在10秒內若路由中慢請求數量超過指定閾值,則發生熔斷,拒絕請求。
slow_request_rt
慢請求的判斷基準回應時間。本例中配置為0.5s,代表回應時間超過0.5s的請求將被視作慢請求。
max_slow_requests
時間視窗內觸發熔斷所需的慢請求數量。本例中配置為5,代表時間視窗的10s內若出現了超過5次慢請求,則發生熔斷,拒絕請求。
min_request_amount
時間視窗內觸發熔斷所需的最小請求數量。配置該參數的目的是防止因請求量過小而被誤判觸發熔斷。
本例中配置為5,代表在時間視窗的10s內若路由上已經發送了5次以上請求、且慢請求數超過5時,才會發生熔斷。
custom_response
熔斷髮生時,網格代理拒絕請求時返回的自訂響應內容。
body配置為
delay break!,代表響應體為delay break!header_to_add配置為
x-envoy-overload: 'true',代表熔斷的回應標頭中將添加x-envoy-overload: 'true'status_code配置為
498,代表熔斷後請求的響應碼為498。
match.vhost
熔斷的路由條目配置,該路由條目必須與虛擬服務中聲明的具體路由條目匹配。
name:需要配置為調用鏈路中上遊服務的服務網域名稱。在本例中,配置為sleep服務的上遊服務httpbin服務的網域名稱
httpbin.default.svc.cluster.local。port:需要配置為上遊服務的Service連接埠。在本例中,配置為httpbin服務的Service連接埠
8000。route.name_match:需要配置為虛擬服務中實際配置的路由項名稱,熔斷配置將在該段路由中生效。在本例中,配置為步驟二中編寫的路由項
delay-route,此路由項對應的請求能夠以人工方式指定超過0.5秒響應,確保能夠觸發熔斷。
使用kubectl串連ACK叢集,執行以下命令。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/delay/1 -I | grep 'HTTP'; echo ''; sleep 0.1; done;預期輸出:
可以看到,當發送第6次請求時,熔斷被觸發。可以觀察到後續的請求都返回了自訂498響應碼,熔斷將持續60s。
在熔斷觸發期間,可以執行以下命令對步驟三中配置的基於錯誤率的熔斷進行測試。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/status/500 -I | grep 'HTTP'; echo ''; sleep 0.1; done;預期輸出:
上述輸出說明在不同路由項上配置的熔斷規則彼此之間互不影響,您可以靈活地針對服務之間不同特徵的東西向調用流量配置各自的熔斷規則,靈活地實現流量熔斷策略。
相關操作
查看服務級熔斷相關指標
在1.22.6.28及以上的ASM版本中,您可以查看和使用ASMCircuitBreaker的服務級熔斷相關指標。
指標 | 指標類型 | 描述 |
envoy_asm_circuit_breaker_total_broken_requests | Counter | 被ASMCircuitBreaker熔斷的請求總數。 |
您可以通過配置Sidecar代理的proxyStatsMatcher來上報相關指標。
在配置proxyStatsMatcher時,選中正則匹配,配置為
.*circuit_breaker.*。具體操作,請參見proxyStatsMatcher。重新部署httpbin應用,使新的代理配置生效。具體操作,請參見重新部署工作負載。
執行以下命令,查看httpbin服務的服務級熔斷相關指標。
kubectl exec -it deploy/httpbin -c istio-proxy -- curl localhost:15090/stats/prometheus|grep asm_circuit_breaker預期輸出:
# TYPE envoy_asm_circuit_breaker_total_broken_requests counter envoy_asm_circuit_breaker_total_broken_requests{cluster="outbound|8000||httpbin.default.svc.cluster.local",uuid="af7cf7ad-67e8-49c5-b5fe-xxxxxxxxx"} 1430 # TYPE envoy_total_asm_circuit_breakers gauge envoy_total_asm_circuit_breakers{} 1
佈建服務級熔斷指標採集及警示
配置完成上報服務級熔斷指標後,您可以配置採集相關指標到Prometheus,並基於關鍵計量配置警示規則,實現熔斷髮生時的及時警示。以下以可觀測監控Prometheus版為例說明如何佈建服務級熔斷指標採集和警示。
在可觀測監控Prometheus版中,為資料面叢集接入阿里雲ASM組件或升級至最新版,以保證可觀測監控Prometheus版可以採集到暴露的熔斷指標。關於接入組件的具體操作,請參見接入組件管理。(如果您已經整合自建Prometheus實現網格監控來採集服務網格指標,則無需做額外操作。)
建立針對服務級熔斷的警示規則。具體操作,請參見通過自訂PromQL建立Prometheus警示規則。配置警示規則的關鍵參數的填寫樣本如下,其餘參數可參考上述文檔根據實際需求填寫。
參數
樣本
說明
自訂PromQL語句
(sum by(cluster, namespace) (increase(envoy_asm_circuit_breaker_total_broken_requests[1m]))) > 0
查詢最近1分鐘之內熔斷的請求數量,並根據觸發熔斷的服務所在命名空間以及服務名稱進行分組。當1分鐘內被熔斷的請求數量大於0時觸發警示。
警示內容
發生服務級熔斷!命名空間:{{$labels.namespace}},發生熔斷的目標服務:{{$labels.cluster}}。當前1分鐘內熔斷的請求數量:{{ $value }}
展示了觸發熔斷的服務所在命名空間以及服務名稱,以及最近1分鐘內發往該服務被熔斷的請求數量的警示資訊格式。