本文介紹了常用的記憶體查詢命令和記憶體相關指標的含義。
Linux記憶體簡介
由於BIOS和Kernel啟動過程消耗了部分記憶體,因此MemTotal值(free命令擷取)小於RAM容量。
dmesg | grep Memory
Memory: 131604168K/134217136K available (14346K kernel code, 9546K rwdata, 9084K rodata, 2660K init, 7556K bss, 2612708K reserved, 0K cma-reserved)Linux記憶體查詢命令:
通過查詢到的記憶體資料可以得到Linux記憶體計算公式如下:
total = used + free + buff/cache //總記憶體=已使用記憶體+空閑記憶體+緩衝其中,已使用記憶體資料包括Kernel消耗的記憶體和所有進程消耗的記憶體。
kernel used=Slab + VmallocUsed + PageTables + KernelStack + HardwareCorrupted + Bounce + X
進程記憶體
進程消耗的記憶體包括:
虛擬位址空間映射的實體記憶體。
讀寫磁碟產生PageCache消耗的記憶體。
虛擬位址映射的實體記憶體
實體記憶體:硬體安裝的記憶體(記憶體條)。
虛擬記憶體:作業系統為程式運行提供的記憶體。程式Runspace包括使用者空間(使用者態)和核心空間(核心態)。
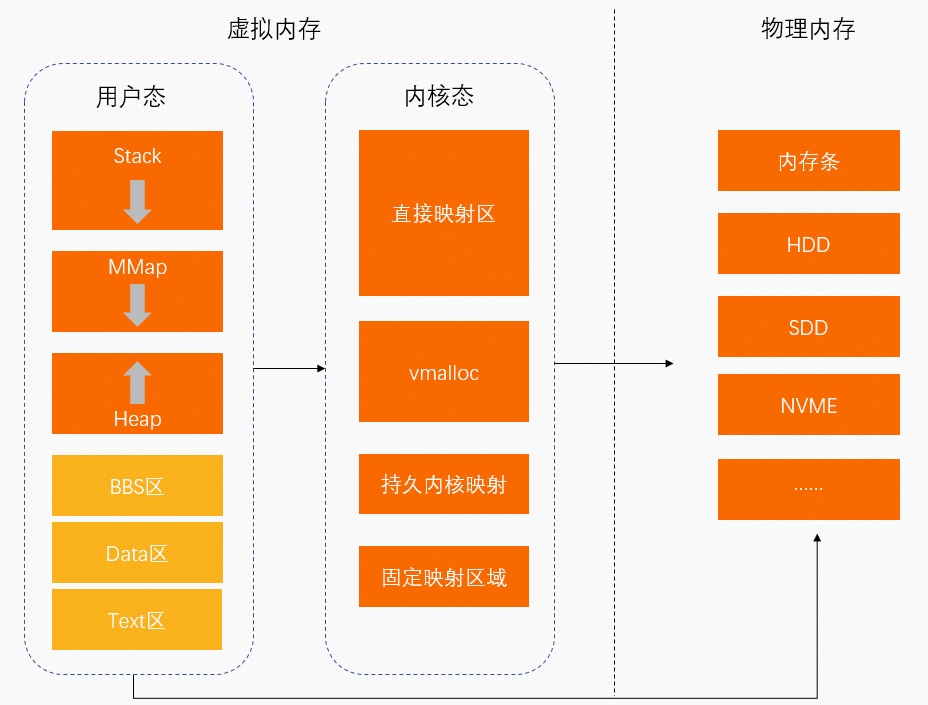
使用者態:低提高權限執行程式。
資料存放區空間包括:
棧(Stack):函數調用的函數棧
MMap(Memory Mapping Segment):記憶體映射區
堆(Heap):動態分配記憶體
BBS區:未初始化的靜態變數存放區
Data區:已初始化的靜態常量存放區
Text區:二進位可執行代碼存放區
使用者態中啟動並執行程式通過MMap將虛擬位址映射至實體記憶體中。
核心態:啟動並執行程式需要訪問作業系統核心資料。
資料存放區空間包括:
直接映射區:通過簡易對應將虛擬位址映射至實體記憶體中。
VMALLOC:核心動態映射空間,用於將連續的虛擬位址映射至不連續的實體記憶體中。
持久核心映射區:將虛擬位址映射至實體記憶體的高端記憶體中。
固定映射區:用於滿足特殊映射需求。
虛擬位址映射的實體記憶體可以區分為共用實體記憶體和獨佔實體記憶體。如下圖所示,實體記憶體1和3由進程A獨佔,實體記憶體2由進程B獨佔,實體記憶體4由進程A和進程B共用。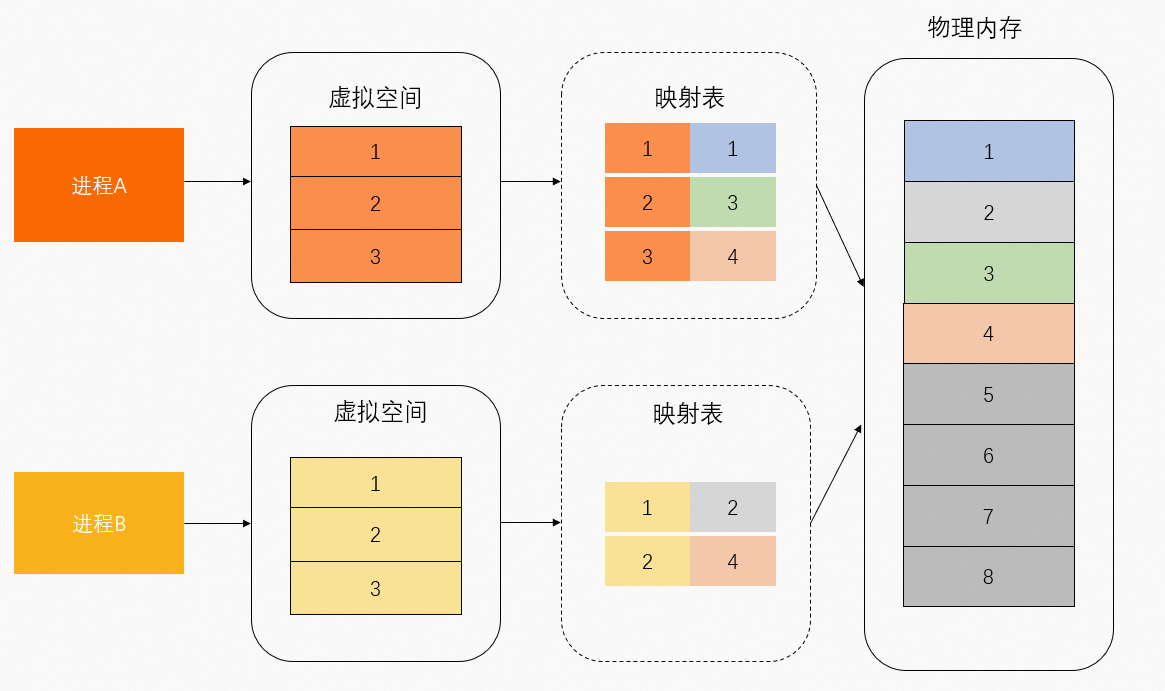
PageCache
除了通過MMap檔案直接映射外,進程檔案還可以通過系統調用Buffered I/O相關的Syscall將資料寫入到PageCache,因此,PageCache也會佔用一部分記憶體。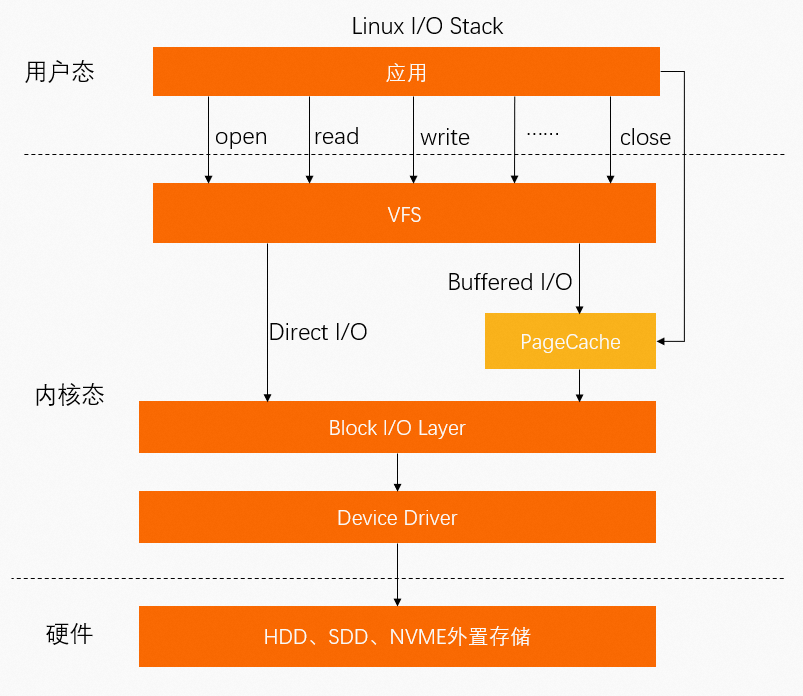
進程記憶體統計指標
單進程記憶體統計指標
進程資源儲存類型如下:
Anonymous(匿名頁):程式自行使用的堆棧空間,在磁碟上沒有對應檔案。
File-backed(檔案頁):資源存放在磁碟檔案中,檔案內包含程式碼片段、字型資訊等內容。
相關指標:
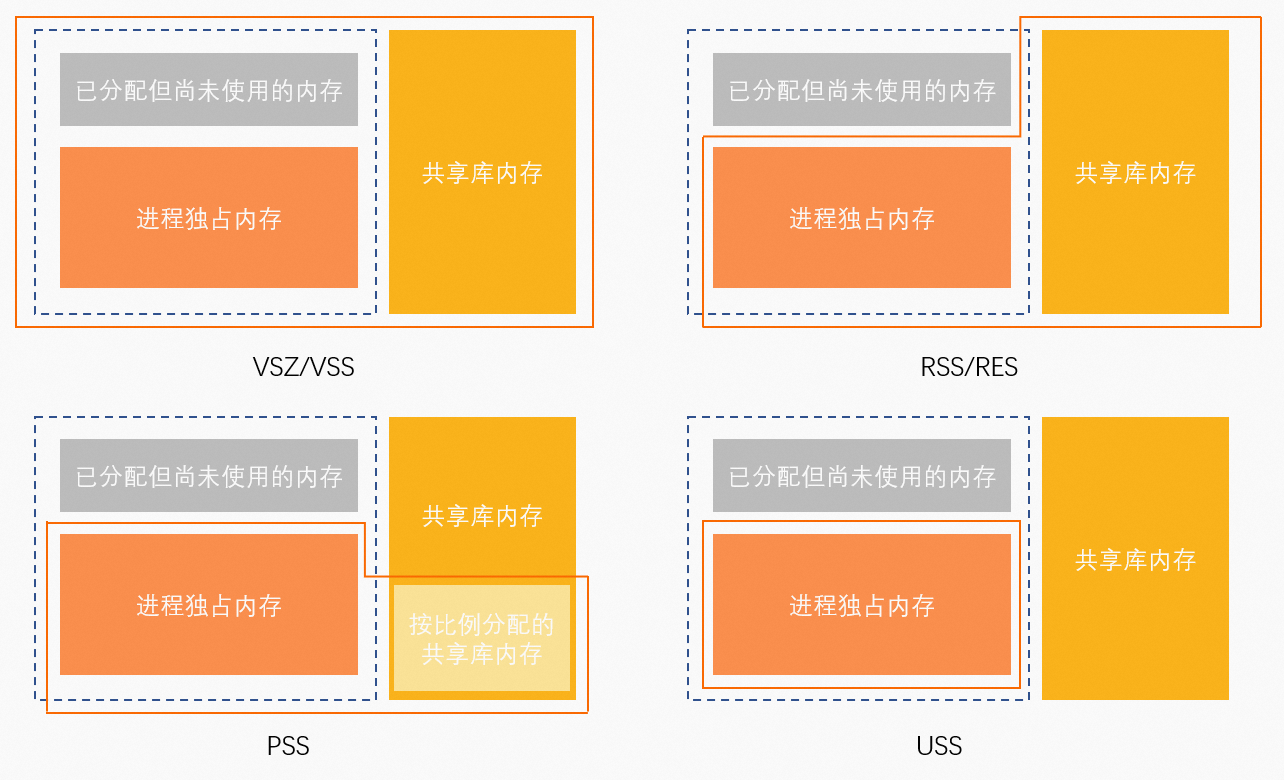
anno_rss(RSan):所有類型資源的獨佔記憶體。
file_rss(RSfd):File-backed資源佔用的所有記憶體。
shmem_rss(RSsh):Anonymous資源的共用記憶體。
指標查詢命令如下:
命令 | 查詢指標 | 說明 | 計算公式 |
| VIRT | 虛擬位址空間。 | 無 |
RES | RSS映射的實體記憶體。 | anno_rss + file_rss + shmem_rss | |
SHR | 共用記憶體。 | file_rss + shmem_rss | |
MEM% | 記憶體使用量率。 | RES / MemTotal | |
| VSZ | 虛擬位址空間。 | 無 |
RSS | RSS映射的實體記憶體。 | anno_rss + file_rss + shmem_rss | |
MEM% | 記憶體使用量率。 | RSS / MemTotal | |
| USS | 獨佔記憶體。 | anno_rss |
PSS | 按比例分配記憶體。 | anno_rss + file_rss/m + shmem_rss/n | |
RSS | RSS映射的實體記憶體。 | anno_rss + file_rss + shmem_rss |
WSS(Memoy Working Set Size)指標:一種更為合理評估進程記憶體真實使用記憶體的計算方式。但是受限於Linux Page Reclaim機制,這個概念目前還只是概念,並沒有哪一個工具可以正確統計出WSS,只能是趨近。
進程式控制制組記憶體統計指標
控制組(Cgroup)用於對Linux的一組進程資源進行限制、管理和隔離。更多資訊,請參見官方文檔。
Cgroup按層級管理,每個節點都包含一組檔案,用於統計由這個節點包含的控制組的某些方面的指標。例如,Memory Control Group(memcg)統計記憶體相關指標。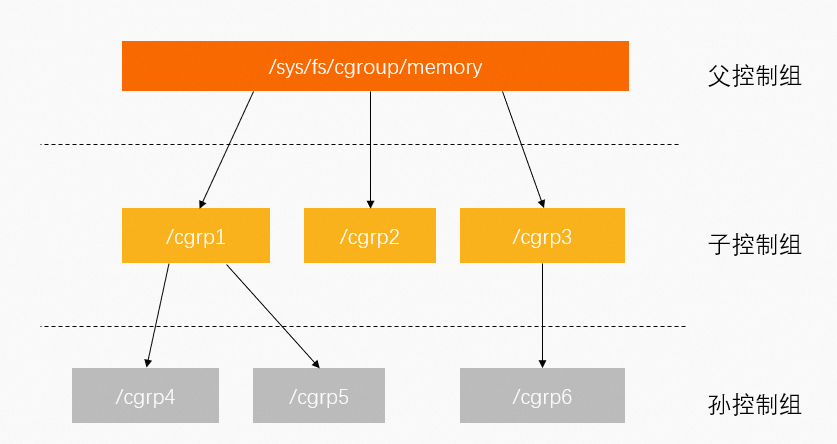
Memory Cgroup檔案包含以下指標:
cgroup.event_control #用於eventfd的介面
memory.usage_in_bytes #顯示當前已用的記憶體
memory.limit_in_bytes #設定/顯示當前限制的記憶體額度
memory.failcnt #顯示記憶體使用量量達到限制值的次數
memory.max_usage_in_bytes #歷史記憶體最大使用量
memory.soft_limit_in_bytes #設定/顯示當前限制的記憶體軟額度
memory.stat #顯示當前cgroup的記憶體使用量情況
memory.use_hierarchy #設定/顯示是否將子cgroup的記憶體使用量情況統計到當前cgroup裡面
memory.force_empty #觸發系統立即儘可能的回收當前cgroup中可以回收的記憶體
memory.pressure_level #設定記憶體壓力的通知事件,配合cgroup.event_control一起使用
memory.swappiness #設定和顯示當前的swappiness
memory.move_charge_at_immigrate #設定當進程移動到其他cgroup中時,它所佔用的記憶體是否也隨著移動過去
memory.oom_control #設定/顯示oom controls相關的配置
memory.numa_stat #顯示numa相關的記憶體其中需要關注以下3個指標:
memory.limit_in_bytes:限制當前控制組可以使用的記憶體大小。對應K8s、Docker下memory limit指標。
memory.usage_in_bytes:當前控制組裡所有進程實際使用的記憶體總和,約等於memory.stat檔案下的RSS+Cache指標值。
memory.stat:當前控制組的記憶體統計詳情。
memory.stat檔案欄位
說明
cache
PageCache快取頁面大小。
rss
控制組中所有進程的anno_rss記憶體之和。
mapped_file
控制組中所有進程的file_rss和shmem_rss記憶體之和。
active_anon
活躍LRU(least-recently-used,最近最少使用)列表中所有Anonymous進程使用記憶體和Swap緩衝,包括
tmpfs(shmem),單位為位元組。inactive_anon
不活躍LRU列表中所有Anonymous進程使用記憶體和Swap緩衝,包括
tmpfs(shmem),單位為位元組。active_file
活躍LRU列表中所有File-backed進程使用記憶體,以位元組為單位。
inactive_file
不活躍LRU列表中所有File-backed進程使用記憶體,以位元組為單位。
unevictable
無法再生的記憶體,以位元組為單位。
以上指標中如果帶有
total_首碼則表示當前控制組及其下所有子孫控制組對應指標之和。例如total_rss指標表示當前控制組及其下所有子孫控制組的RSS指標之和。
總結
單進程和進程式控制制組指標區別:
指標 | 單進程 | 進程式控制制組(memcg) |
RSS | anon_rss + file_rss + shmem_rss | anon_rss |
mapped_file | 無 | file_rss + shmem_rss |
cache | 無 | PageCache |
控制組的RSS指標只包含anno_rss,對應單進程下的USS指標,因此控制組的mapped_file+RSS則對應單進程下的RSS指標。
單進程中PageCache需單獨統計,控制組中memcg檔案統計的記憶體已包含PageCache。
Docker和K8s中的記憶體統計
Docker和K8s中的記憶體統計即Linux memcg進程統計,但兩者記憶體使用量率的定義不同。
docker stat命令
返回樣本如下:
docker stat命令查詢原理,請參見官方文檔。
func calculateMemUsageUnixNoCache(mem types.MemoryStats) float64 {
return float64(mem.Usage - mem.Stats["cache"])
}LIMIT對應控制組的memory.limit_in_bytes。
MEM USAGE對應控制組的memory.usage_in_bytes - memory.stat[total_cache]。
kubectl top pod命令
kubectl top命令通過Metric-server和Heapster擷取Cadvisor中working_set的值,表示Pod執行個體使用的記憶體大小(不包括Pause容器)。Petrics-server中Pod記憶體擷取原理如下,更多資訊,請參見官方文檔。
func decodeMemory(target *resource.Quantity, memStats *stats.MemoryStats) error {
if memStats == nil || memStats.WorkingSetBytes == nil {
return fmt.Errorf("missing memory usage metric")
}
*target = *uint64Quantity(*memStats.WorkingSetBytes, 0)
target.Format = resource.BinarySI
return nil
}Cadvisor記憶體workingset演算法如下,更多資訊,請參見官方文檔。
func setMemoryStats(s *cgroups.Stats, ret *info.ContainerStats) {
ret.Memory.Usage = s.MemoryStats.Usage.Usage
ret.Memory.MaxUsage = s.MemoryStats.Usage.MaxUsage
ret.Memory.Failcnt = s.MemoryStats.Usage.Failcnt
if s.MemoryStats.UseHierarchy {
ret.Memory.Cache = s.MemoryStats.Stats["total_cache"]
ret.Memory.RSS = s.MemoryStats.Stats["total_rss"]
ret.Memory.Swap = s.MemoryStats.Stats["total_swap"]
ret.Memory.MappedFile = s.MemoryStats.Stats["total_mapped_file"]
} else {
ret.Memory.Cache = s.MemoryStats.Stats["cache"]
ret.Memory.RSS = s.MemoryStats.Stats["rss"]
ret.Memory.Swap = s.MemoryStats.Stats["swap"]
ret.Memory.MappedFile = s.MemoryStats.Stats["mapped_file"]
}
if v, ok := s.MemoryStats.Stats["pgfault"]; ok {
ret.Memory.ContainerData.Pgfault = v
ret.Memory.HierarchicalData.Pgfault = v
}
if v, ok := s.MemoryStats.Stats["pgmajfault"]; ok {
ret.Memory.ContainerData.Pgmajfault = v
ret.Memory.HierarchicalData.Pgmajfault = v
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats["total_inactive_file"]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet
}通過以上命令演算法可以得出,kubectl top pod命令查詢到的Memory Usage = Memory WorkingSet = memory.usage_in_bytes - memory.stat[total_inactive_file]。
總結
命令 | 生態 | Memory Usage計算方式 |
| Docker | memory.usage_in_bytes - memory.stat[total_cache] |
| K8s | memory.usage_in_bytes - memory.stat[total_inactive_file] |
如果使用Top、PS命令查詢記憶體,則進程式控制制組下的Memory Usage指標需對Top、PS命令查詢到的指標進行以下計算:
進程組生態 | 計算公式 |
Memcg | rss + cache(active cache + inactive cache) |
Docker | rss |
K8s | rss + active cache |
Java記憶體統計
Java進程的虛擬位址空間
Java進程虛擬位址空間中資料存放區地區分布如下: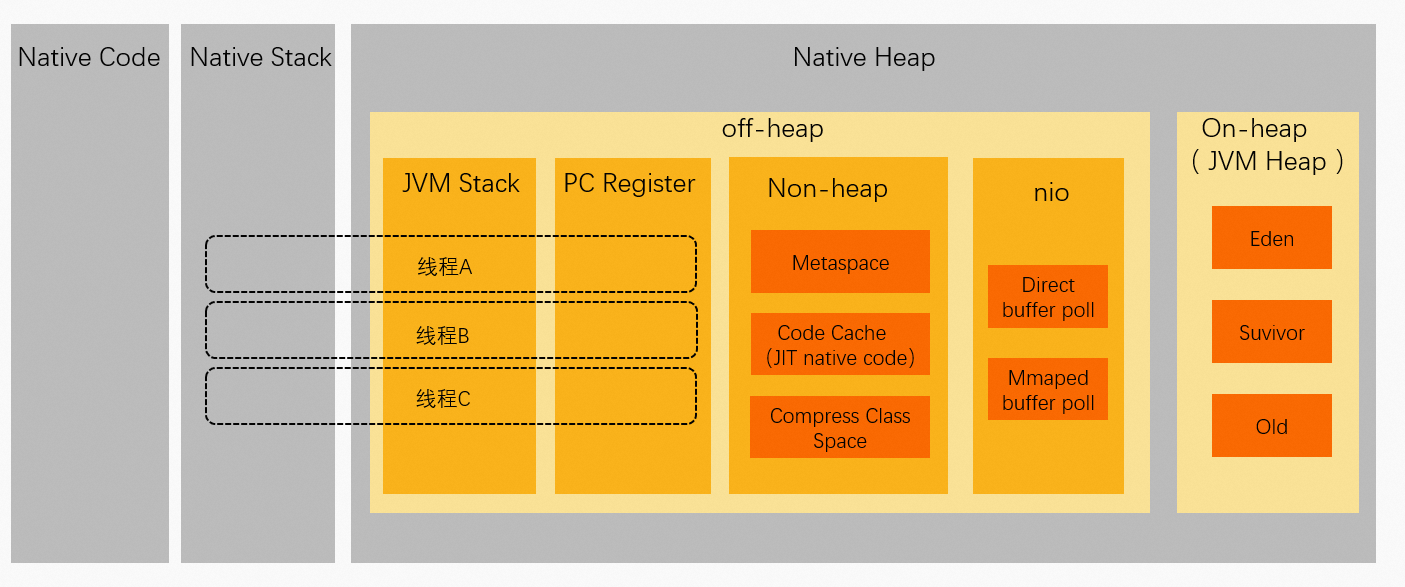
通過JMX擷取記憶體指標
Java進程可以通過JMX暴露的資料擷取記憶體指標,例如通過Jconsole擷取記憶體指標。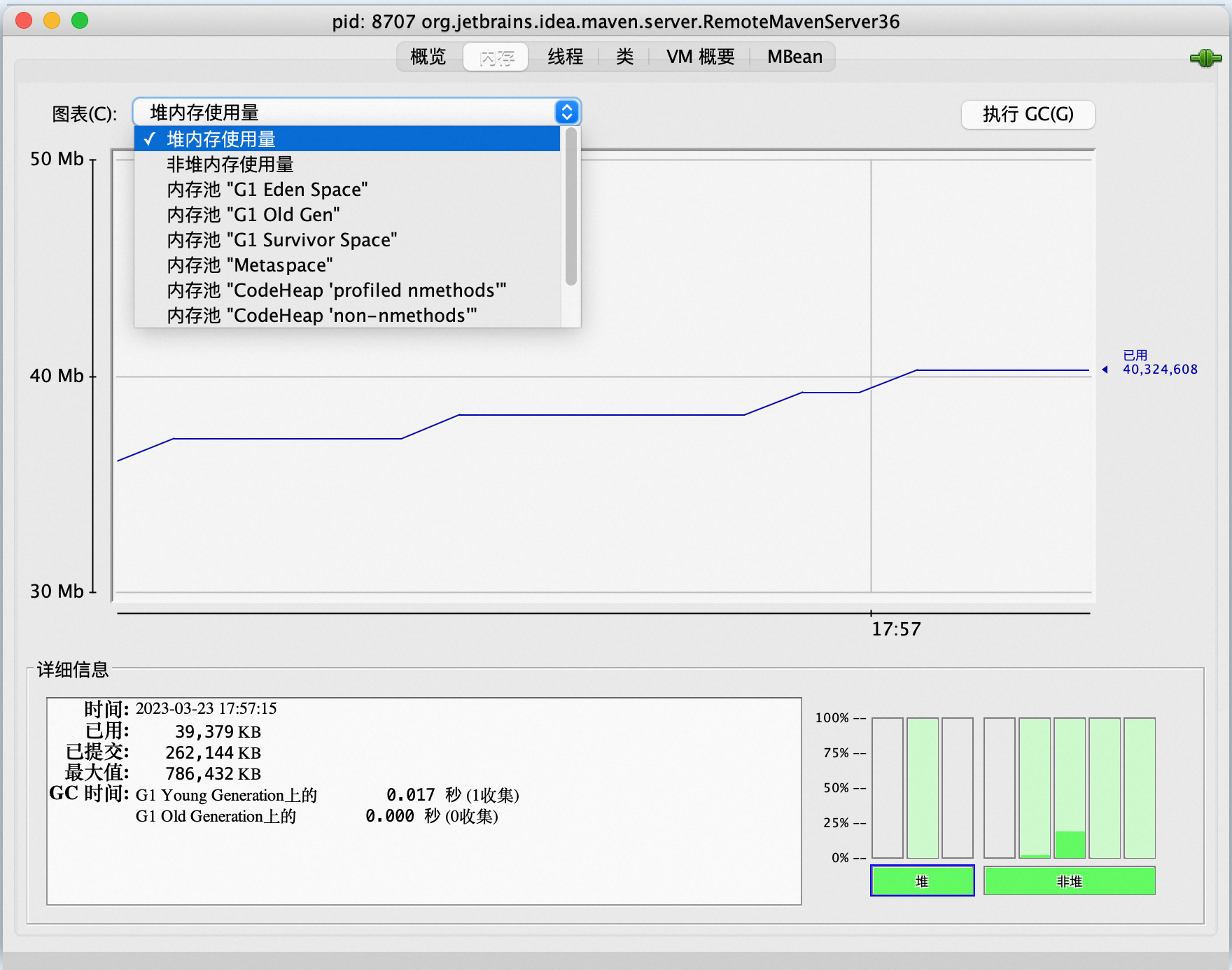
記憶體相關的資料通過MBean透出。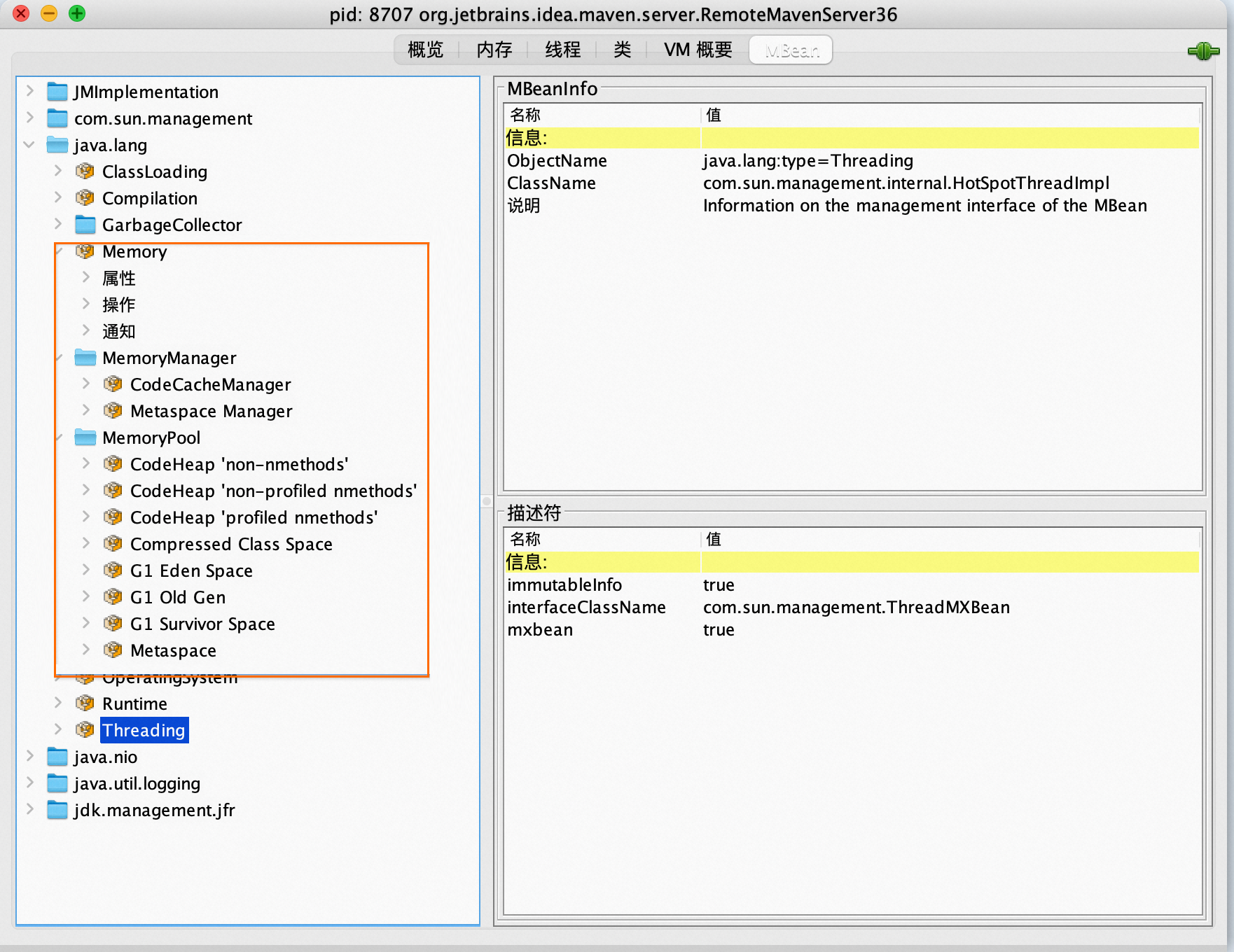
JMX暴露的指標並未展示JVM進程全部的記憶體指標,例如,Java Thread消耗的記憶體就未展示。因此,JMX暴露的記憶體Usage資料累加得出的結果並不等於JVM進程的RSS值。
JMX MemoryUsage工具
JMX通過MemoryPool的MBean透出了MemoryUsage的概念,更多資訊,請參見官方文檔。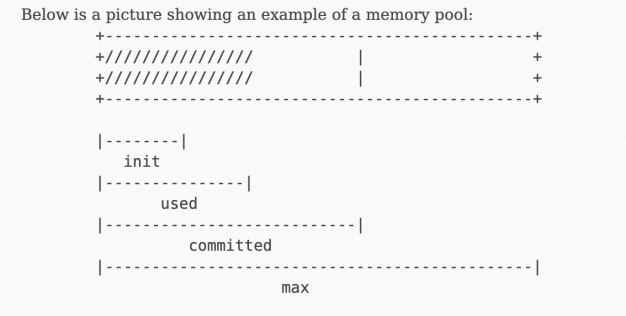
其中,used為實體記憶體消耗。
NMT工具
Java Hotspot VM提供了一個跟蹤記憶體的工具Native Memory Tracking (NMT),具體使用方法,請參見官方文檔。
NMT本身有額外的OverHead,並不適合在生產環境使用。
通過NMT擷取的記憶體指標如下:
jcmd 7 VM.native_memory
Native Memory Tracking:
Total: reserved=5948141KB, committed=4674781KB
- Java Heap (reserved=4194304KB, committed=4194304KB)
(mmap: reserved=4194304KB, committed=4194304KB)
- Class (reserved=1139893KB, committed=104885KB)
(classes #21183)
( instance classes #20113, array classes #1070)
(malloc=5301KB #81169)
(mmap: reserved=1134592KB, committed=99584KB)
( Metadata: )
( reserved=86016KB, committed=84992KB)
( used=80663KB)
( free=4329KB)
( waste=0KB =0.00%)
( Class space:)
( reserved=1048576KB, committed=14592KB)
( used=12806KB)
( free=1786KB)
( waste=0KB =0.00%)
- Thread (reserved=228211KB, committed=36879KB)
(thread #221)
(stack: reserved=227148KB, committed=35816KB)
(malloc=803KB #1327)
(arena=260KB #443)
- Code (reserved=49597KB, committed=2577KB)
(malloc=61KB #800)
(mmap: reserved=49536KB, committed=2516KB)
- GC (reserved=206786KB, committed=206786KB)
(malloc=18094KB #16888)
(mmap: reserved=188692KB, committed=188692KB)
- Compiler (reserved=1KB, committed=1KB)
(malloc=1KB #20)
- Internal (reserved=45418KB, committed=45418KB)
(malloc=45386KB #30497)
(mmap: reserved=32KB, committed=32KB)
- Other (reserved=30498KB, committed=30498KB)
(malloc=30498KB #234)
- Symbol (reserved=19265KB, committed=19265KB)
(malloc=16796KB #212667)
(arena=2469KB #1)
- Native Memory Tracking (reserved=5602KB, committed=5602KB)
(malloc=55KB #747)
(tracking overhead=5546KB)
- Shared class space (reserved=10836KB, committed=10836KB)
(mmap: reserved=10836KB, committed=10836KB)
- Arena Chunk (reserved=169KB, committed=169KB)
(malloc=169KB)
- Tracing (reserved=16642KB, committed=16642KB)
(malloc=16642KB #2270)
- Logging (reserved=7KB, committed=7KB)
(malloc=7KB #267)
- Arguments (reserved=19KB, committed=19KB)
(malloc=19KB #514)
- Module (reserved=463KB, committed=463KB)
(malloc=463KB #3527)
- Synchronizer (reserved=423KB, committed=423KB)
(malloc=423KB #3525)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)通過上述輸出指標可以得知,JVM內部劃分了很多細分的用途不同的記憶體地區,例如Java Heap、Class等,但是還有很多額外的記憶體塊。另外,JMX並沒有暴露線程(Thread)的記憶體使用量資訊,但是實際Java程式大多都有數以萬計的線程,因此Thread也消耗了的大量記憶體。
Hotspot內部關於記憶體種類劃分的定義,請參見官方文檔。
Reserved和Committed指標
NMT的輸出統計透出了兩個概念:Reserved和Committed。但Reserved和Committed都無法映射已使用實體記憶體(Used)。
虛擬位址Reserved、Committed和物理地址映射關係如下圖所示,可以得出Committed總是大於Used(此處Used基本是等同於進程JVM的RSS)。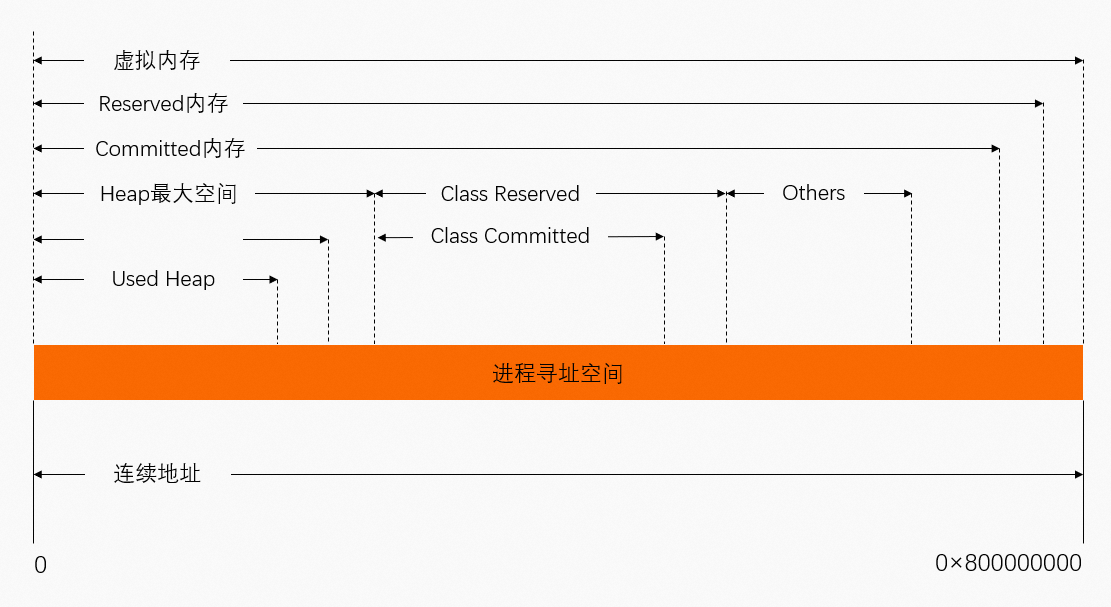
總結
常見Java應用工具統計出來的指標主要是由JMX暴露的,關於記憶體的統計,JMX暴露了一些JVM內部可跟蹤的MemoryPool,這些MemoryPool的總和並不能和JVM進程的RSS映射。
NMT暴露了JVM內部使用記憶體的細節,但是衡量結果並不是Used,而是Committed。因此,總Committed應該比RSS稍大。
NMT對JVM外的一些記憶體無法跟蹤。如果Java程式有額外的Molloc等行為,NMT是統計不到的,因此如果看到RSS比NMT大,也是正常的。
如果NMT的Committed和RSS相差非常多,那就要懷疑記憶體是否泄露。
您可以通過NMT的其他指標做進一步排查:
藉助NMT的baseline和diff排查是JVM內部哪個地區出現問題。
藉助NMT結合pmap排查JVM之外的記憶體問題。