本文介紹如何通過建立Tablestore Sink Connector,將資料從雲訊息佇列 Kafka 版執行個體的資料來源Topic匯出至Table Store(Tablestore)。
前提條件
雲訊息佇列 Kafka 版
已為執行個體開啟Connector。具體操作,請參見開啟Connector。
已為執行個體建立資料來源Topic。更多資訊,請參見步驟一:建立Topic。
Table Store
已開通Table Store服務並建立執行個體。具體操作,請參見開通服務並建立執行個體。
注意事項
操作流程
使用Tablestore Sink Connector將資料從雲訊息佇列 Kafka 版執行個體的資料來源Topic匯出至Table Store操作流程如下:
可選:建立Tablestore Sink Connector依賴的Topic和Group
如果您不需要自訂Topic和Group,您可以直接跳過該步驟,在下一步驟選擇自動建立。
重要部分Tablestore Sink Connector依賴的Topic的儲存引擎必須為Local儲存,大版本為0.10.2的雲訊息佇列 Kafka 版執行個體不支援手動建立Local儲存的Topic,只支援自動建立。
結果驗證
建立Tablestore Sink Connector依賴的Topic
您可以在雲訊息佇列 Kafka 版控制台手動建立Tablestore Sink Connector依賴的5個Topic,包括:任務位點Topic、任務配置Topic、任務狀態Topic、無效信件佇列Topic以及異常資料Topic。每個Topic所需要滿足的分區數與儲存引擎會有差異,具體資訊,請參見配置源服務參數列表。
在概览頁面的资源分布地區,選擇地區。
重要Topic需要在應用程式所在的地區(即所部署的ECS的所在地區)進行建立。Topic不能跨地區使用。例如Topic建立在華北2(北京)這個地區,那麼訊息生產端和消費端也必須運行在華北2(北京)的ECS。
在实例列表頁面,單擊目標執行個體名稱。
在左側導覽列,單擊Topic 管理。
在Topic 管理頁面,單擊创建 Topic。
在创建 Topic面板,設定Topic屬性,然後單擊確定。
參數
說明
樣本
名称
Topic名稱。
demo
描述
Topic的簡單描述。
demo test
分区数
Topic的分區數量。
12
存储引擎
說明當前僅非Serverless專業版執行個體支援選擇儲存引擎類型,其他執行個體暫不支援選擇,預設為雲端儲存類型。
Topic訊息的儲存引擎。
雲訊息佇列 Kafka 版支援以下兩種儲存引擎。
云存储:底層接入阿里雲雲端硬碟,具有低時延、高效能、持久性、高可靠等特點,採用分布式3副本機制。執行個體的规格类型為标准版(高写版)時,儲存引擎只能為云存储。
Local 存储:使用原生Kafka的ISR複製演算法,採用分布式3副本機制。
云存储
消息类型
Topic訊息的類型。
普通消息:預設情況下,保證相同Key的訊息分布在同一個分區中,且分區內訊息按照發送順序儲存。叢集中出現機器宕機時,可能會造成訊息亂序。當存储引擎選擇云存储時,預設選擇普通消息。
分区顺序消息:預設情況下,保證相同Key的訊息分布在同一個分區中,且分區內訊息按照發送順序儲存。叢集中出現機器宕機時,仍然保證分區內按照發送順序儲存。但是會出現部分分區發送訊息失敗,等到分區恢複後即可恢複正常。當存储引擎選擇Local 存储時,預設選擇分区顺序消息。
普通消息
日志清理策略
Topic日誌的清理策略。
當存储引擎選擇Local 存储(當前僅專業版執行個體支援選擇儲存引擎類型為Local儲存,標準版暫不支援)時,需要配置日志清理策略。
雲訊息佇列 Kafka 版支援以下兩種日誌清理策略。
Delete:預設的訊息清理策略。在磁碟容量充足的情況下,保留在最長保留時間範圍內的訊息;在磁碟容量不足時(一般磁碟使用率超過85%視為不足),將提前刪除舊訊息,以保證服務可用性。
Compact:使用Kafka Log Compaction日誌清理策略。Log Compaction清理策略保證相同Key的訊息,最新的value值一定會被保留。主要適用於系統宕機後恢複狀態,系統重啟後重新載入緩衝等情境。例如,在使用Kafka Connect或Confluent Schema Registry時,需要使用Kafka Compact Topic儲存系統狀態資訊或配置資訊。
重要Compact Topic一般只用在某些生態組件中,例如Kafka Connect或Confluent Schema Registry,其他情況的訊息收發請勿為Topic設定該屬性。具體資訊,請參見雲訊息佇列 Kafka 版Demo庫。
Compact
标签
Topic的標籤。
demo
建立完成後,在Topic 管理頁面的列表中顯示已建立的Topic。
建立Tablestore Sink Connector依賴的Group
您可以在雲訊息佇列 Kafka 版控制台手動建立Tablestore Sink Connector資料同步任務使用的Group。該Group的名稱必須為connect-任務名稱,具體資訊,請參見配置源服務參數列表。
在概览頁面的资源分布地區,選擇地區。
在实例列表頁面,單擊目標執行個體名稱。
在左側導覽列,單擊Group 管理。
在Group 管理頁面,單擊创建 Group。
在创建 Group面板的Group ID文字框輸入Group的名稱,在描述文字框簡要描述Group,並給Group添加標籤,單擊確定。
建立完成後,在Group 管理頁面的列表中顯示已建立的Group。
建立並部署Tablestore Sink Connector
建立並部署將資料從雲訊息佇列 Kafka 版同步至Table Store的Tablestore Sink Connector。
在概览頁面的资源分布地區,選擇地區。
在左側導覽列,單擊Connector 任务列表。
在Connector 任务列表頁面,從选择实例的下拉式清單選擇Connector所屬的執行個體,然後單擊创建 Connector。
在创建 Connector設定精靈頁面,完成以下操作。
在配置基本信息頁簽,按需配置以下參數,然後單擊下一步。
參數
描述
樣本值
名称
Connector的名稱。命名規則:
可以包含數字、小寫英文字母和短劃線(-),但不能以短劃線(-)開頭,長度限制為48個字元。
同一個雲訊息佇列 Kafka 版執行個體內保持唯一。
Connector的資料同步任務必須使用名稱為connect-任務名稱的Group。如果您未手動建立該Group,系統將為您自動建立。
kafka-ts-sink
实例
預設配置為執行個體的名稱與執行個體ID。
demo alikafka_post-cn-st21p8vj****
在配置源服务頁簽,選擇資料來源為訊息佇列Kafka版,並配置以下參數,然後單擊下一步。
說明如果您已建立好Topic和Group,那麼請選擇手動建立資源,並填寫已建立的資源資訊。否則,請選擇自動建立資源。
表 1. 配置源服務參數列表
參數
描述
樣本值
数据源 Topic
需要同步資料的Topic。
ts-test-input
消费线程并发数
資料來源Topic的消費線程並發數。預設值為6。取值說明如下:
1
2
3
6
12
6
消费初始位置
開始消費的位置。取值說明如下:
最早位点:從最初位點開始消費。
最近位点:從最新位點開始消費。
最早位点
VPC ID
資料同步任務所在的VPC。單擊配置运行环境顯示該參數。預設為雲訊息佇列 Kafka 版執行個體所在的VPC,您無需填寫。
vpc-bp1xpdnd3l***
vSwitch ID
資料同步任務所在的交換器。單擊配置运行环境顯示該參數。該交換器必須與雲訊息佇列 Kafka 版執行個體處於同一VPC。預設為部署雲訊息佇列 Kafka 版執行個體時填寫的交換器。
vsw-bp1d2jgg81***
失败处理
訊息發送失敗後,是否繼續訂閱出現錯誤的Topic的分區。單擊配置运行环境顯示該參數。取值說明如下。
继续订阅:繼續訂閱出現錯誤的Topic的分區,並列印錯誤記錄檔。
停止订阅:停止訂閱出現錯誤的Topic的分區,並列印錯誤記錄檔
說明如何查看日誌,請參見Connector相關操作。
如何根據錯誤碼尋找解決方案,請參見錯誤碼。
继续订阅
创建资源方式
選擇建立Connector所依賴的Topic與Group的方式。單擊配置运行环境顯示該參數。
自动创建
手动创建
自动创建
Connector 消费组
Connector的資料同步任務使用的Group。單擊配置运行环境顯示該參數。該Group的名稱必須為connect-任務名稱。
connect-cluster-kafka-ots-sink
任务位点 Topic
用於儲存消費位點的Topic。單擊配置运行环境顯示該參數。
Topic:建議以connect-offset開頭。
分區數:Topic的分區數量必須大於1。
儲存引擎:Topic的儲存引擎必須為Local儲存。
cleanup.policy:Topic的日誌清理策略必須為compact。
connect-offset-kafka-ots-sink
任务配置 Topic
用於儲存任務配置的Topic。單擊配置运行环境顯示該參數。
Topic:建議以connect-config開頭。
分區數:Topic的分區數量必須為1。
儲存引擎:Topic的儲存引擎必須為Local儲存。
cleanup.policy:Topic的日誌清理策略必須為compact。
connect-config-kafka-ots-sink
任务状态 Topic
用於儲存任務狀態的Topic。單擊配置运行环境顯示該參數。
Topic:建議以connect-status開頭。
分區數:Topic的分區數量建議為6。
儲存引擎:Topic的儲存引擎必須為Local儲存。
cleanup.policy:Topic的日誌清理策略必須為compact。
connect-status-kafka-ots-sink
死信队列 Topic
用於儲存Connect架構的異常資料的Topic。單擊配置运行环境顯示該參數。該Topic可以和異常資料Topic為同一個Topic,以節省Topic資源。
Topic:建議以connect-error開頭。
分區數:Topic的分區數量建議為6。
儲存引擎:Topic的儲存引擎可以為Local儲存或雲端儲存。
connect-error-kafka-ots-sink
异常数据 Topic
用於儲存Sink的異常資料的Topic。單擊配置运行环境顯示該參數。該Topic可以和無效信件佇列Topic為同一個Topic,以節省Topic資源。
Topic:建議以connect-error開頭。
分區數:Topic的分區數量建議為6。
儲存引擎:Topic的儲存引擎可以為Local儲存或雲端儲存。
connect-error-kafka-ots-sink
在配置目标服务頁簽,選擇目標服務為Table Store,並配置以下參數,然後單擊创建。
參數
描述
樣本值
实例名称
Table Store的執行個體名稱。
k00eny67****
自动创建目标表
是否在Table Store中自動建立表。
是:在Table Store中根據配置的表名自動建立一個儲存同步資料的表。
否:使用已建立的表格儲存體同步資料。
是
目标表名
儲存同步資料的表名稱。如果自动创建目标表選擇否,表名稱需與Table Store執行個體中已有表名稱相同。
kafka_table
表格存储
儲存同步資料的表類型。
寬表模型
時序模型
寬表模型
消息 Key 格式
訊息Key的輸入格式。支援String和JSON兩種格式,預設值為JSON。當表格存储選擇寬表模型時顯示該參數。
String:直接將訊息的Key作為字串解析。
JSON:訊息的Key必須符合JSON格式。
String
消息 Value 格式
訊息值的輸入格式。支援String和JSON兩種格式。預設值為JSON。當表格存储選擇寬表模型時顯示該參數。
String:直接將訊息的Value作為字串解析。
JSON:訊息的Value必須符合JSON格式。
String
JSON消息字段转化
JSON訊息的欄位處理方式。消息 Key 格式或消息 Value 格式選擇JSON時顯示該參數。取值範圍如下:
全部作為String寫入:將所有欄位轉化為Table Store中對應的String。
自動識別欄位類型:將JSON訊息體中的String和Boolean欄位分別轉化為Table Store中對應的String和Boolean欄位。JSON訊息體中的Integer和Float資料類型,將被轉化為Table Store中的Double類型。
全部作為String寫入
主键模式
指定主鍵模式。支援從雲訊息佇列 Kafka 版訊息記錄的不同部分提取資料表主鍵,包括訊息記錄的Coordinates(Topic,Partition,Offset),Key和Value。當表格存储選擇寬表模型時顯示該參數。預設值為kafka。
kafka:表示以<connect_topic>_<connect_partition>和 <connect_offset>作為資料表的主鍵。
record_key:表示以Record Key中的欄位作為資料表的主鍵。
record_value:表示以 Record Value 中的欄位作為資料表的主鍵。
kafka
主键列名配置
資料表的主鍵列名和對應的資料類型。支援string和Integer兩種資料類型,表示從Record Key或Record Value中提取與配置的主鍵列名相同的欄位作為資料表的主鍵。
消息 Key 格式選擇JSON,且主键模式選擇record_key,或消息 Value 格式選擇JSON,且主键模式選擇record_value,顯示該參數。
單擊添加可以增加列名。最多支援配置四個列名。
無
写入模式
指定寫入模式,支援put和update兩種寫入模式,預設值為put。當表格存储選擇寬表模型時顯示該參數。
put:表示覆蓋寫。
update:表示更新寫。
put
删除模式
當雲訊息佇列 Kafka 版訊息記錄出現空值時,您可以選擇是否進行刪除行或刪除屬性列的操作。主键模式選擇record_key顯示該參數。取值範圍如下:
none:預設值,不允許進行任何刪除。
row:允許刪除行。
column:允許刪除屬性列。
row_and_column:允許刪除行和屬性列。
刪除操作與寫入模式的配置相關。具體如下:
如果写入模式為put,選擇任意一種刪除模式,當Value中存在空值時,資料均覆蓋寫入Table Store資料表。
如果写入模式為update,選擇none或row刪除模式,當Value所有欄位值均為空白值時,資料作為髒資料處理。當Value部分欄位值為空白值時,自動忽略空值,將非空值寫入Table Store資料表。選擇column或row_and_column刪除模式,當Value存在空值時,刪除行和屬性列後,將資料寫入Table Store資料表。
無
度量名称字段
將該欄位對應為Table Store時序模型中的度量名稱欄位(_m_name),表示時序資料所度量的物理量或者監控指標的名稱,比如temperature、speed等,不可為空。當表格存储選擇時序模型時顯示該參數。
measurement
数据源字段
將該欄位對應為Table Store時序模型中的資料來源欄位(_data_source),作為產生某個時間序列資料的資料來源標識,比如機器名或者裝置ID等,可以為空白。當表格存储選擇時序模型時顯示該參數。
source
标签字段
將一個或多個欄位作為Table Store時序模型中的標籤欄位(_tags)。每個標籤是一個字串類型的Key和Value,Key為配置的欄位名,Value為欄位內容。標籤作為時間軸中繼資料的一部分,度量名稱、資料來源、標籤共同標識一條時間軸,可以為空白。當表格存储選擇時序模型時顯示該參數。
tag1, tag2
时间戳字段
將該欄位對應為Table Store時序模型中的時間戳記欄位(_time)。表示該行時序資料所對應的時間點,比如產生物理量的時刻等。在資料寫入Table Store時,會將時間戳記欄位轉換成微秒單位進行寫入和儲存。當表格存储選擇時序模型時顯示該參數。
time
时间戳单位
視時間戳記欄位實際情況進行配置。當表格存储選擇時序模型時顯示該參數。取值範圍如下:
SECONDS(秒)
MILLISECONDS(毫秒)
MICROSECONDS(微秒)
NANOSECONDS(納秒)
MILLISECONDS
是否映射全部非主键字段
是否將非主鍵欄位(主鍵欄位為已經映射為度量名稱、資料來源、標籤或時間戳記的欄位)全部映射為資料欄位。當表格存储選擇時序模型時顯示該參數。取值範圍如下:
是:會自動對應欄位並判斷資料類型,數實值型別會全部轉換為Double類型。
否:需要指定需要映射的欄位和類型。
是
配置映射全部非主键字段
時序表的非主鍵欄位名稱對應的欄位類型。支援Double、Integer、String、Binary和Boolean五種資料類型。當是否映射全部非主键字段選擇否時顯示該參數。
String
建立完成後,在Connector 任务列表頁面,查看建立的Connector 。
建立完成後,在Connector 任务列表頁面,找到建立的Connector ,單擊其操作列的部署。
單擊確認。
發送測試訊息
部署Tablestore Sink Connector後,您可以向雲訊息佇列 Kafka 版的資料來源Topic發送訊息,測試資料能否被同步至Table Store。
在Connector 任务列表頁面,找到目標Connector,在其右側操作列,單擊测试。
在发送消息面板,發送測試訊息。
发送方式選擇控制台。
在消息 Key文字框中輸入訊息的Key值,例如demo。
在消息内容文字框輸入測試的訊息內容,例如 {"key": "test"}。
設定发送到指定分区,選擇是否指定分區。
單擊是,在分区 ID文字框中輸入分區的ID,例如0。如果您需查詢分區的ID,請參見查看分區狀態。
單擊否,不指定分區。
发送方式選擇Docker,執行运行 Docker 容器生产示例消息地區的Docker命令,發送訊息。
发送方式選擇SDK,根據您的業務需求,選擇需要的語言或者架構的SDK以及接入方式,通過SDK發送訊息。
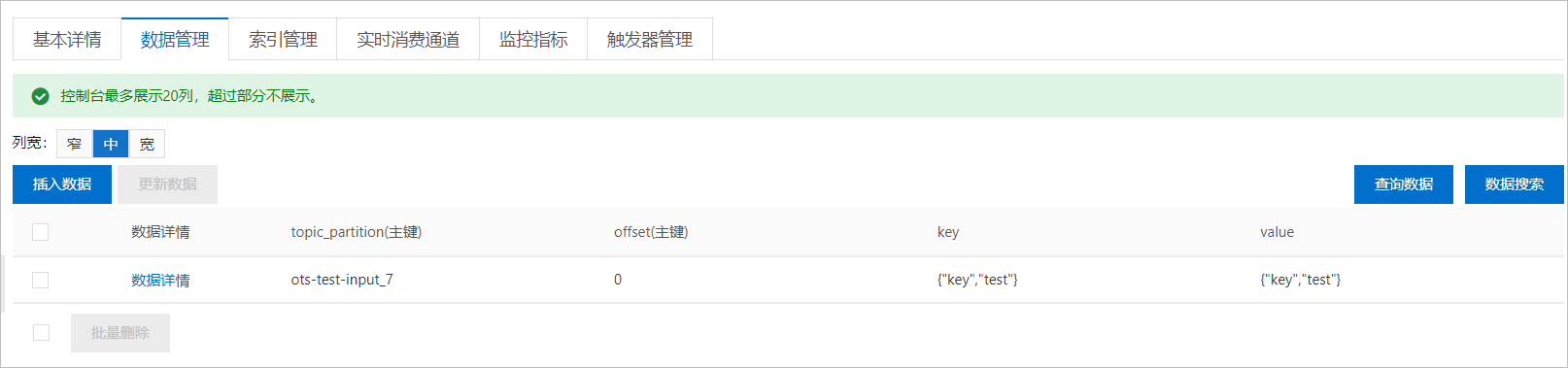
查看錶資料
向雲訊息佇列 Kafka 版的資料來源Topic發送訊息後,在Table Store控制台查看錶資料,驗證是否收到訊息。
在概覽頁面,單擊執行個體名稱或在操作列單擊執行個體管理。
在執行個體詳情頁簽,資料表列表地區,查看對應的資料表。

單擊資料表名稱,在表管理頁面的資料管理頁簽,查看錶資料。