雲原生AI套件支援通過Kubeflow Pipelines構建和部署基於容器的可移植、可擴充的機器學習工作流程。本文介紹如何通過Kubeflow Pipelines建立及查看工作流程。
前提條件
已建立Kubernetes叢集。本文以包含GPU的Kubernetes叢集為例。具體操作,請參見使用Kubernetes預設GPU調度。
叢集節點可以訪問公網。具體操作,請參見為叢集開啟訪問公網的能力。
已建立PV和PVC。具體操作,請參見配置NAS共用儲存或使用OSS靜態儲存卷。
已建立Notebook。具體操作,請參見建立並使用Notebook。
背景資訊
Kubeflow Pipelines是一個用於構建端到端機器學習工作流程的平台,主要由以下三個組件構成:
Kubeflow Pipelines UI:用於Experiments,Pipelines和Runs的建立和查看。
Kubeflow Pipelines SDK:用於定義和構建Components和Pipelines。
Workflow Engine:工作流程的執行引擎。
通過Kubeflow Pipelines可以實現如下功能:
藉助Pipelines的Workflow能力,構建符合您業務情境的機器學習CI/CD流水線,加速演算法的商業化落地。
藉助Pipelines的Experiments能力,對比和分析不同參數或資料下Pipelines的運行情況。
藉助Pipelines中的Tracking能力,記錄每一次上線模型的Data、Code、Config、Input和Output等資訊。
關於Kubeflow Pipelines的更多資訊,請參見Kubeflow Pipelines。
操作步驟
本文以使用KFP SDK和KFP Arena SDK構建一個機器學習工作流程為例,安裝Python SDK、編寫並提交工作流程均在Notebook環境下進行。關於KFP SDK的更多資訊,請參見Introduction to the Pipelines SDK。
安裝Kubeflow Pipelines。
未安裝雲原生AI套件:安裝雲原生AI套件時,工作流程需選中Kubeflow Pipelines。具體操作,請參見安裝雲原生AI套件。
已安裝雲原生AI套件:
登入Container Service管理主控台,在左側導覽列單擊叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在組件列表的操作列下,升級ack-ai-dashboard和ack-ai-dev-console,並部署ack-ai-pipeline。
組件
說明
ack-ai-dashboard
需升級到1.0.7及以上版本。
ack-ai-dev-console
需升級到1.0.13及以上版本。
ack-ai-pipeline
部署ack-ai-pipeline時,控制台會判斷系統中是否存在kubeai-oss Secret,若存在則使用阿里雲OSS作為Artifact的儲存,若不存在則使用叢集內建MinIO作為Artifact的儲存。
執行以下命令,安裝Python SDK。
本文需要安裝兩個Python SDK,包括KFP SDK和KFP Arena SDK。
KFP SDK:提供Pipelines編排和提交的能力。
pip install https://kube-ai-ml-pipeline.oss-cn-beijing.aliyuncs.com/sdk/kfp-1.8.10.5.tar.gzKFP Arena SDK:提供開箱即用的Component。
pip install https://kube-ai-ml-pipeline.oss-cn-beijing.aliyuncs.com/sdk/kfp-arena-0.1.3.tar.gz
使用以下Python檔案,編寫並提交Pipelines工作流程。
Pipelines工作流程包含兩部分:執行資料下載的操作、根據下載的資料執行模型訓練。
import kfp from kfp import compiler from arena import standalone_job_op, pytorch_job_op def mnist_train_pipeline(): #資料下載OP,將資料下載到PVC中。 download_op = standalone_job_op(namespace="default-group", name="download-mnist-dataset", image="kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/download-mnist-dataset:demo", working_dir="/root", data=["training-data:/mnt"], command="/root/code/mnist-pytorch/download_mnist_dataset.sh /mnt/pytorch_data") #模型訓練OP,從PVC中讀取download_op的資料進行訓練,並將結果寫入到PVC中。 train_op = pytorch_job_op(namespace="default-group", annotation="kubai.pipeline:test", name="pytorch-dist-step", gpus=1, workers=3, working_dir="/root", image="registry.cn-beijing.aliyuncs.com/ai-samples/pytorch-with-tensorboard:1.5.1-cuda10.1-cudnn7-runtime", sync_mode="git", sync_source='https://code.aliyun.com/370272561/mnist-pytorch.git', data=["training-data:/mnt"], logdir="/mnt/pytorch_data/logs", command="python /root/code/mnist-pytorch/mnist.py --epochs 10 --backend nccl --dir /mnt/pytorch_data/logs --data /mnt/pytorch_data/") train_op.after(download_op) #建立Client並提交資料。 client = kfp.Client() client.create_run_from_pipeline_func(mnist_train_pipeline, namespace="default-group", arguments={})參數解釋如下表。
參數
是否必選
解釋
預設值
name
必選
指定提交的作業名字,全域唯一,不能重複。
無
working_dir
可選
指定當前執行命令所在的目錄。
/root
gpus
可選
指定作業Worker節點需要使用的GPU卡數。
0
image
必選
指定訓練環境的鏡像地址。
無
sync_mode
可選
同步代碼的模式,您可以指定git、rsync。本文使用Git模式。
無
sync_source
可選
同步代碼的倉庫地址,需要和--sync-mode一起使用,本文樣本使用Git模式,該參數可以為任何GitHub專案地址。阿里雲Code專案地址等支援Git的代碼託管地址。專案代碼將會被下載到--working-dir下的code/目錄中。本文樣本即為:/root/code/tensorflow-sample-code。
無
data
可選
掛載共用儲存卷PVC到運行環境中。它由兩部分組成,通過冒號
:分割。冒號左側是您已經準備好的PVC名稱。您可以通過arena data list查看當前叢集可用的PVC列表;冒號右側是您想將PVC的掛載到運行環境中的路徑,也是您訓練代碼要讀取資料的本地路徑。這樣通過掛載的方式,您的代碼就可以訪問PVC的資料。說明執行
arena data list查看本文樣本當前叢集可用的PVC列表。NAME ACCESSMODE DESCRIPTION OWNER AGE training-data ReadWriteMany 35m如果沒有可用的PVC,您可建立PVC。具體操作,請參見配置NAS共用儲存。
無
tensorboard
可選
為訓練任務開啟一個TensorBoard服務,用作資料視覺效果,您可以結合--logdir指定TensorBoard要讀取的event路徑。不指定該參數,則不開啟TensorBoard服務。
無
logdir
可選
需要結合--tensorboard一起使用,該參數表示TensorBoard需要讀取event資料的路徑。
/training_logs
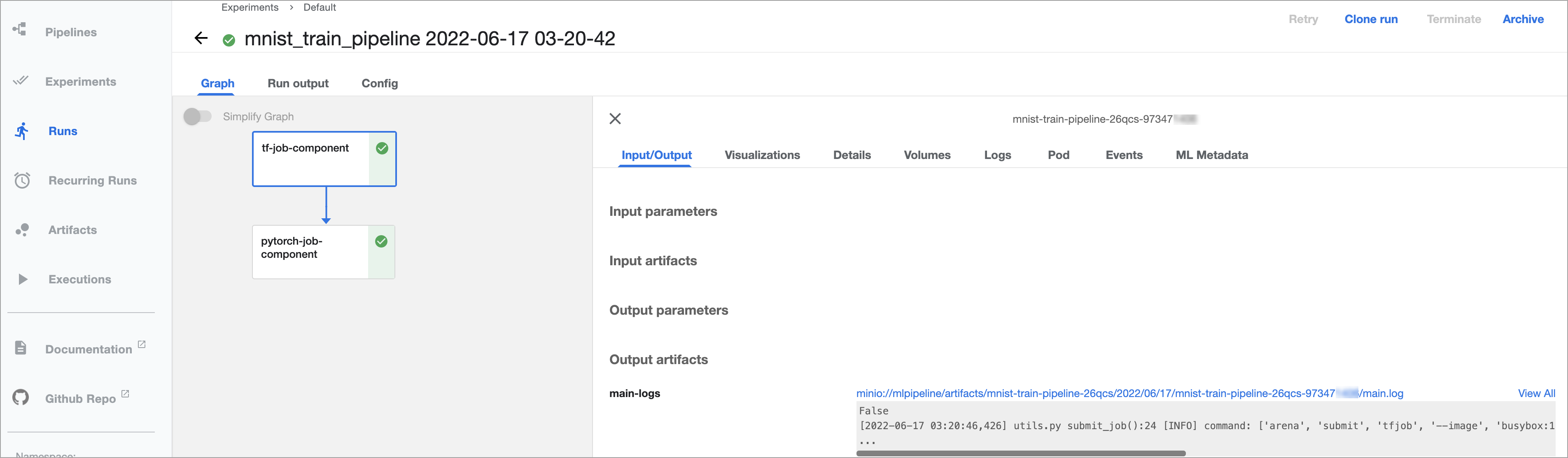
成功運行如圖所示。

查看Kubeflow Pipelines。
在AI開發控制台的左側導覽列中,單擊Kubeflow Pipelines。
在左側導覽列單擊Runs,然後單擊Active頁簽,查看啟動並執行Pipelines。

單擊目標Run,查看運行詳情。