雲原生AI套件支援安裝在ACK Pro版叢集、ACK Serverless叢集Pro版、ACK Edge叢集Pro版,且叢集版本為1.18及以上。本文介紹如何安裝雲原生AI套件,以及如何安裝配置雲原生AI營運控制台和開發控制台。
前提條件
已建立ACK Pro版叢集、ACK Serverless叢集Pro版、ACK Edge叢集Pro版,且叢集版本為1.18及以上。具體操作,請參見建立ACK Pro版叢集、建立ACK Serverless Pro叢集、建立ACK Edge叢集Pro版。
如需安裝配置雲原生AI營運控制台,需在建立叢集的組件配置頁面,選中監控外掛程式和Log Service;或在已建立叢集的營運管理頁面,安裝Prometheus監控和Logtail組件。具體操作,請參見使用阿里雲Prometheus監控和採集ACK叢集容器日誌。
部署雲原生AI套件
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在雲原生AI套件頁面,單擊一鍵部署,然後在部署頁面,按需選中相應的組件。
控制台配置說明、組件說明以及不同叢集類型的組件支援情況說明如下。
控制台配置
組件配置
叢集支援情況
配置項
配置說明
組件名稱及說明
命名空間
ACK託管叢集Pro版
ACK Serverless叢集Pro版
ACK Edge叢集Pro版
彈性
是否開啟彈性控制器功能。更多資訊,請參見基於Kubernetes部署運行模型訓練作業、容器化彈性推理。
ack-alibaba-cloud-metrics-adapter,Auto Scaling組件。
kube-system


資料訪問加速
是否開啟Fluid功能。更多資訊,請參見彈性資料集。
ack-fluid,資料緩衝加速組件。
fluid-system
調度
是否開啟調度策略擴充(批量任務調度、GPU共用、GPU拓撲感知)功能。單擊進階配置,可自訂參數配置。
ack-ai-installer,調度組件。
kube-system
是否開啟Kube Queue任務隊列功能。更多資訊,請參見使用任務隊列ack-kube-queue管理AI/ML工作負載。
ack-kube-queue,擴充的Kubernetes任務隊列調度組件。
kube-queue
生態工具
Kubeflow,Arena:如需使用命令列工具Arena(需要單獨安裝配置Arena用戶端),則必須在此勾選Arena。安裝後,可以使用Arena命令列工具整合的Kubeflow的多種訓練Operator。單擊進階配置,可自訂參數配置。
若同時勾選Kube Queue、控制台、工作流程,則預設必選Arena。更多資訊,請參見配置Arena用戶端。
ack-arena(生態工具),機器學習命令列工具。
kube-system
控制台:部署輕量化Platform for AI平台。單擊進階配置,可自訂參數配置。
ack-pai,輕量化Platform for AI平台。推薦使用。
安裝此組件後可以直接使用PAI平台提供的深度最佳化的演算法與引擎,以及沉澱的最佳實務,此外DSW、DLC、EAS等服務也為AI模型開發、訓練和推理帶來了更好的彈性和效率,極大地最佳化訓練與推理的效果,降低了AI開發的門檻。
pai-system
控制台:AI套件控制台。
說明阿里雲提供的AI控制台(包括開發控制台、營運控制台)於2025年01月22日起以白名單功能的形式開放,官網涉及AI控制台的文檔僅適用於白名單使用者。如果在白名單開放前已部署開發控制台或營運控制台,使用將不會受到影響。未加入白名單的使用者,可以按照開源社區指引自行安裝配置AI控制台。關於開源配置的詳細操作,請參見開源AI控制台。
ack-ai-dashboard(生態工具),可視化營運控制台。
kube-ai
ack-ai-dev-console(生態工具),深度學習開發控制台。
kube-ai
控制台資料存放區
選擇互動方式為控制台後,需選擇控制台資料存放區方式為叢集內建MySQL或阿里雲RDS。關於配置詳情,請參見安裝配置雲原生AI控制台。
ack-mysql,MySQL資料庫組件。
kube-ai
Kubeflow Pipelines
選中Kubeflow Pipelines後,可以選擇工作流程資料存放區方式為叢集內建MinIO或阿里雲OSS。關於配置詳情,請參見安裝配置工作流程。
ack-ai-pipeline(生態工具),構建端到端的機器學習工作流程平台。
kube-ai
監控
是否安裝Arena 監控。更多資訊,請參見使用雲原生AI監控大盤。
ack-arena-exporter,叢集監控組件。
kube-ai
單擊頁面下方的部署雲原生AI套件,開始檢查環境和依賴項,檢查通過後,自動部署所選擇的組件。
組件安裝成功後,在組件列表頁面:
可以看到當前叢集中已經安裝的組件名稱、版本等資訊,並能對組件進行部署和卸載操作。
如果已安裝的組件有新版本的話,還可以對組件進行升級操作。
如果已安裝雲原生AI營運控制台組件(ack-ai-dashboard)和雲原生AI開發控制台組件(ack-ai-dev-console)後,可以在雲原生AI套件頁面左上方看到營運控制台和開發控制台,單擊相應控制台可直接進行訪問。
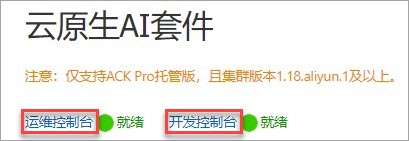
安裝完成後,可以在雲原生AI套件頁面左上方看到營運控制台和開發控制台,單擊相應控制台可直接進行訪問。
安裝配置雲原生AI控制台
阿里雲提供的AI控制台(包括開發控制台、營運控制台)於2025年01月22日起以白名單功能的形式開放。如果在白名單開放前已部署開發控制台或營運控制台,使用將不會受到影響。未加入白名單的使用者,可以從開源社區安裝配置AI套件控制台。關於開源配置的詳細操作,請參見開源AI控制台。
在雲原生AI套件部署頁面的互動方式地區,選中樣本控制台,彈出提示對話方塊。
建立自訂權限原則並對RAM角色進行授權。
建立自訂權限原則。
登入RAM控制台,在左側導覽列選擇許可權管理>權限原則。
單擊建立權限原則。
單擊指令碼編輯頁簽。添加以下策略資訊,單擊確定,在名稱文字框中輸入自訂權限原則的名稱,格式需設定為
k8sWorkerRolePolicy-{ClusterID},名稱設定完成後單擊確定即可。{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "cs:*", "log:GetProject", "log:GetLogStore", "log:GetConfig", "log:GetMachineGroup", "log:GetAppliedMachineGroups", "log:GetAppliedConfigs", "log:GetIndex", "log:GetSavedSearch", "log:GetDashboard", "log:GetJob", "ecs:DescribeInstances", "ecs:DescribeSpotPriceHistory", "ecs:DescribePrice", "eci:DescribeContainerGroups", "eci:DescribeContainerGroupPrice", "log:GetLogStoreLogs", "ims:CreateApplication", "ims:UpdateApplication", "ims:GetApplication", "ims:ListApplications", "ims:DeleteApplication", "ims:CreateAppSecret", "ims:GetAppSecret", "ims:ListAppSecretIds", "ims:ListUsers" ], "Resource": "*" } ] }
對目標容器叢集的RAM角色授權。
登入RAM控制台,在左側導覽列選擇身份管理>角色。
在文字框中輸入目標角色名稱,格式為
KubernetesWorkerRole-{ClusterID}。單擊目標角色名稱後操作列的新增授權。在權限原則地區,在文字框中輸入之前建立的自訂權限原則名稱,格式為
k8sWorkerRolePolicy-{ClusterID}。選中策略名稱稱後,單擊確認新增授權。
返回Container ServiceACK控制台的提示對話方塊,單擊授權檢測。如果授權成功,授權狀態顯示為已授權,且確定按鈕可用。請執行步驟3。

選擇營運控制台訪問方式和開發控制台訪問方式,然後單擊確定。
可以選擇使用私網IP、私網網域名稱或公網網域名稱訪問服務。
生產環境中,請使用私網IP或者私網網域名稱的方式。
公網網域名稱方式建議僅作為測試使用。如需使用公網網域名稱,請在本地Host檔案中將需要訪問的公網網域名稱和叢集的Nginx Ingress SLB的公網IP綁定。
說明選擇私網網路類型訪問時,在提示對話方塊中選中私網IP。
使用私網網域名稱、私網IP存取控制台的步驟,請參見訪問AI營運控制台。
選擇控制台資料存放區方式。
選中控制台後,在部署頁面互動方式下方會出現控制台資料存放區,可以選擇資料存放區的方式。
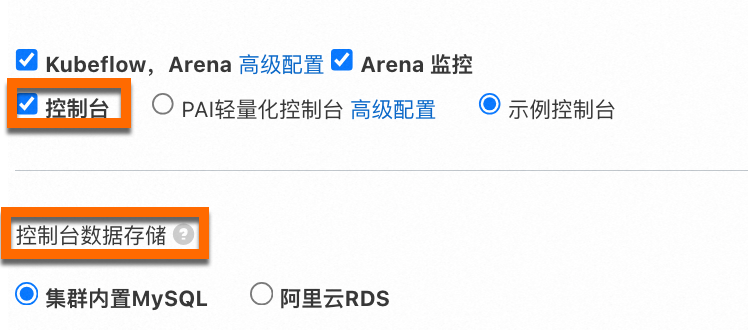
叢集內建MySQL
如果沒有選擇阿里雲RDS的儲存模式,則預設使用叢集內建MySQL。因為穩定性和SLA保障問題,該方式建議僅作為測試使用,不推薦作為生產環境使用,且該方式會在組件每次安裝的時候建立一塊產生額外費用的新的雲端硬碟,這些雲端硬碟資源需要使用者自行控制釋放。
重要如果叢集故障或者儲存丟失,可能會導致資料丟失。
雲原生AI套件會使用雲端硬碟的StorageClass來建立一個backend為雲端硬碟的PVC作為MySQL的持久化儲存,ACK叢集會建立一塊新的大小為120 GB的雲端硬碟並進行掛載,該雲端硬碟會產生一定的費用,且該雲端硬碟後續的生命週期管理不屬於ACK,請注意進行雲端硬碟的資源管理,如果不再需要請及時刪除。關於釋放雲端硬碟的操作,請參見釋放雲端硬碟。
阿里雲RDS
說明使用RDS時若出現串連異常的問題,請參見解決無法串連執行個體問題。
如果想要修改資料存放區方式,請卸載雲原生AI套件,再重新進行安裝。如果叢集中有名稱為
kubeai-rds的Secret,請通過kubectl刪除。
單獨購買RDS執行個體並建立資料庫和帳號,操作步驟請參見雲資料庫RDS快速入門,RDS的計費資訊請參見計費概覽。
單擊頁面下方的部署雲原生AI套件,安裝雲原生AI套件。
單擊目的地組群的名稱,在左側導覽列選擇組態管理>保密字典。
在頁面上方的命名空間列表中,選擇
kube-ai。在頁面右上方,單擊使用YAML建立資源。
輸入以下YAML樣本模板,建立名為
kubeai-rds的Secret。apiVersion: v1 kind: Secret metadata: name: kubeai-rds namespace: kube-ai type: Opaque stringData: MYSQL_HOST: "Your RDS URL" MYSQL_DB_NAME: "Database name" MYSQL_USER: "Database username" MYSQL_PASSWORD: "Database password"參數
說明
name
Secret名稱。
namespace
叢集命名空間的名稱。
MYSQL_HOST
MYSQL_DB_NAME
MYSQL_USER
MYSQL_PASSWORD
RDS MySQL的參數配置,請參見(廢棄,重新導向到“第一步”)快速建立RDS MySQL執行個體和(廢棄,重新導向至“第一步”)建立資料庫和帳號。

安裝配置工作流程
當工作流程選中Kubeflow Pipelines後,需要選擇工作流程資料存放區方式。

叢集內建MinIO
如果沒有選擇阿里雲OSS的儲存模式,則預設使用叢集內建MinIO。因為穩定性和SLA保障問題,該方式建議僅作為測試使用,不推薦作為生產環境使用,且該方式會在組件每次安裝的時候建立一塊產生額外費用的新的雲端硬碟,這些雲端硬碟資源需要使用者自行控制釋放。
如果叢集故障或者儲存丟失,可能會導致資料丟失。
雲原生AI套件會使用雲端硬碟的StorageClass來建立一個backend為雲端硬碟的PVC作為MinIO的持久化儲存,ACK叢集會建立一塊新的大小為20 GB的雲端硬碟並進行掛載,該雲端硬碟會產生一定的費用且該雲端硬碟後續的生命週期管理不屬於ACK,請注意進行雲端硬碟的資源管理,如果不再需要請及時刪除。關於釋放雲端硬碟的操作,請參見釋放雲端硬碟。
阿里雲OSS
如果叢集中不存在kube-ai這個命名空間,則需要在叢集中提前建立這個命名空間。
kubectl create ns kube-ai安裝雲原生AI套件中的Kubeflow Pipelines之前,在Container Service管理主控台左側單擊目的地組群的名稱,在左側導覽列選擇組態管理>保密字典。
在控制台頁面上方的命名空間列表中,選擇kube-ai。
在頁面右上方,單擊使用YAML建立資源。
輸入以下YAML樣本模板,點擊建立,叢集會自動執行部署該YAML檔案,並產生名為
kubeai-oss的Secret。apiVersion: v1 kind: Secret metadata: name: kubeai-oss namespace: kube-ai type: Opaque stringData: ENDPOINT: "https://oss-cn-beijing.aliyuncs.com" ACCESS_KEY_ID: "****" ACCESS_KEY_SECRET: "****"參數
說明
name
Secret名稱。
namespace
叢集命名空間名稱。
說明namespace:kube-ai在部署雲原生AI套件時已自動建立,無需再單獨執行建立操作。
ENDPOINT
OSS存取點名稱,樣本中以北京為例,更多存取點資訊請參見OSS地區和訪問網域名稱。
ACCESS_KEY_ID
ACCESS_KEY_SECRET
填寫帳號的AccessKey(AK)資訊。擷取AK的方式,請參見建立AccessKey。
重要為保證資料安全,推薦使用RAM使用者的AK。使用RAM使用者登入之前,需要為RAM使用者配置
AliyunOSSFullAccess的許可權。建立Secret後,耐心等待OSS管理主控台中自動產生一個名稱為
mlpipeline-<clusterid>的Bucket,此時說明已成功配置阿里雲OSS工作流程資料存放區方式。OSS的計費,請參見計費概述。最後再安裝雲原生AI套件中的Kubeflow Pipelines組件即可。